文章目录
- 一、说明
- 二、摘要
- 三、对架构的介绍
- 四、相关工作
- 五、理论推演
- 六、实验
一、说明
对发布于2014年的关于GAN的原始描述,我们精读此文,对原始的GAN网络概念进行追溯,对于概念的原始解读,是grasp该模型的最扎实依据。本文力图尊重原著的意图,适当加入读书笔记。在该文的续文中,将介绍实际用处和结果。
二、摘要
我们引入了一种通过对抗过程估计生成模型的新颖框架,其中同时训练两个模型:生成模型 G 捕获数据分布,判别模型 D 评估样本源自训练数据而不是样本的可能性。 G. G 的训练目标是增加 D 出错的概率。该框架相当于两个玩家之间的极小极大游戏。在任意函数 G 和 D 的范围内,存在一个唯一的解决方案,其中 G 复制训练数据分布,并且 D 处处等于 1/2。当 G 和 D 被构造为多层感知器时,整个系统可以使用反向传播进行训练,而无需在训练或样本生成期间使用马尔可夫链或展开的近似推理网络。该框架的有效性通过对生成的样本的定性和定量评估来展示。
三、对架构的介绍
深度学习旨在揭示复杂的分层模型。表示各种数据类型的概率分布的模型在人工智能应用中至关重要,包括自然图像、语音音频波形和自然语言语料库中的符号。深度学习最重要的成就涉及判别模型,该模型通常将高维感官输入映射到类别标签。这些成功取决于使用分段线性单元的反向传播和丢失算法。具有稳定梯度的模型尤其成功。然而,由于近似最大似然估计和相关方法所需的复杂概率计算的困难,以及在生成框架中利用分段线性单元的优势的挑战,深度生成模型的影响较小。为了应对这些挑战,我们提出了一种新的生成模型估计技术。在对抗网络框架中,生成模型与对手竞争:经过训练以确定样本来自模型分布还是实际数据分布的判别模型。生成模型类似于造假者试图生产和传播无法检测的假币,而判别模型则类似于警察,致力于检测假币。这种竞争促使双方改进方法,直到假币与真币无法区分。
该框架可以为各种模型和优化技术生成特定的训练算法。在本文中,我们研究了一种独特的场景,其中生成模型通过多层感知器引导随机噪声来创建样本,而判别模型同样是多层感知器。我们将这种情况称为对抗网络。在这里,我们可以仅使用经过验证的反向传播和 dropout 算法 [17] 来训练这两个模型,并仅通过前向传播从生成模型生成样本。不需要近似推理或马尔可夫链。
四、相关工作
具有潜在变量的有向图模型的替代方案包括具有潜在变量的无向图模型,例如受限玻尔兹曼机(RBM)、深度玻尔兹曼机(DBM)及其各种衍生物。这些模型将相互作用表示为非标准化潜在函数的乘积,这些函数通过随机变量所有状态的全局求和/积分进行标准化。除了最简单的情况外,配分函数及其梯度通常很难处理,但可以使用马尔可夫链蒙特卡罗 (MCMC) 方法进行估计。然而,由于混合问题,依赖 MCMC 的学习算法面临着重大挑战。
深度置信网络 (DBN) 是具有单个无向层和多个有向层的混合模型。尽管 DBN 具有快速近似逐层训练标准,但它们也遇到了无向和有向模型固有的计算挑战。
其他不近似或限制对数似然的建议标准包括分数匹配和噪声对比估计(NCE)。两种方法都需要通过分析指定学习到的概率密度直至归一化常数。在许多具有多层潜在变量的复杂生成模型中,例如 DBN 和 DBM,导出易于处理的非标准化概率密度是不可行的。去噪自动编码器和收缩自动编码器等模型的学习规则与应用于 RBM 的分数匹配非常相似。 NCE 采用判别性训练标准来拟合生成模型,使用生成模型本身来区分生成的数据和来自固定噪声分布的样本。一旦模型学会了基本模式,这种方法就会导致学习速度显着减慢。
当两个模型都是多层感知器时,对抗网络的应用最为有效。为了了解生成器在数据 x 上的分布 pg,我们在输入噪声变量 pz(z) 上建立先验,然后将到数据空间的映射定义为 G(z; θg),其中 G 是由多层感知器表示的可微函数参数为 θg。此外,我们定义了另一个输出单个标量的多层感知器 D(x; θd)。 D(x)表示x源自数据而不是pg的概率。我们训练 D 以最大化正确标记 G 中的训练样例和样本的概率,同时训练 G 以最小化 log(1 − D(G(z)))。
换句话说,D 和 G 玩以下带有价值函数 V (G, D) 的两人极小极大游戏:
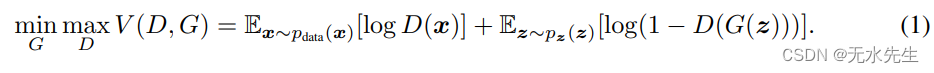
在下一节中,我们对对抗网络进行理论分析,证明只要 G 和 D 具有足够的容量,即在非参数限制下,训练准则就可以恢复数据生成分布。有关此方法的更非正式和指导性的解释,请参阅图 1。实际上,我们应用迭代数值方法来实现此过程。在训练的内循环中完全优化 D 在计算上是不可行的,并且会导致有限数据集的过度拟合。因此,我们选择交替优化 D 的 k 步和优化 G 的一步,确保在 G 逐渐演化的情况下 D 保持接近其最优解。这种方法类似于 SML/PCD 训练如何将马尔可夫链样本从一个学习阶段保留到下一阶段,从而无需在每个学习周期中建立马尔可夫链。算法 1 详细介绍了该方法。
此外,方程 1 可能并不总是为 G 的有效学习提供足够的梯度。在早期阶段,当 G 的性能低于标准时,D 可以轻松地忽略样本,因为它们与训练数据明显不同。在这种情况下,log(1 − D(G(z))) 趋于达到饱和。我们不是指示 G 最小化 log(1 − D(G(z))),而是指示它最大化 log D(G(z))。这个替代目标导致 G 和 D 的动态达到相同的平衡,但在学习过程开始时产生明显更强的梯度。
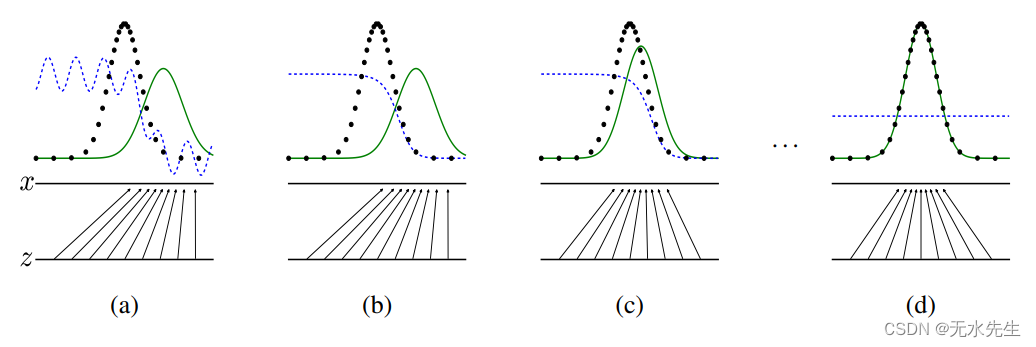
图 1:通过更新判别分布(D,由蓝色虚线表示)来训练生成对抗网络,以区分来自数据生成分布(黑色虚线) p x p_x px 的样本和来自生成分布的样本 p g ( G ) p_g(G) pg(G)(显示为绿色实线)。下面的水平线表示均匀采样的域。上面的水平线对应于 ( x ) 的定义域的一部分。向上的箭头说明了映射 x = G ( z ) x = G(z) x=G(z) 如何将非均匀分布 p g p_g pg 应用到变换后的样本,其中 G 在 p g p_g pg 的高密度区域收缩,在低密度区域扩张。 (a) 接近收敛时,考虑一个对抗对: p g p_g pg 类似于 p d a t a p_{data} pdata 并且 D 是一个稍微准确的分类器。 (b) 在算法的内循环中,D 被训练来区分样本和数据,收敛为 D ∗ ( x ) = p d a t a ( x ) p d a t a ( x ) + p g ( x ) D^*(x) = \frac{p_{data}(x)}{p_{data}(x) + p_g( x)} D∗(x)=pdata(x)+pg(x)pdata(x)。 © 更新 G 后,D 的梯度将 G(z) 引向更有可能被分类为数据的区域。 (d) 经过多个训练步骤后,如果 G 和 D 拥有足够的容量,它们将达到一个两者都无法提高的点,因为 p g = p d a t a p_g = p_{data} pg=pdata。此时,判别器无法区分两个分布,即 D ( x ) = 1 2 D(x) = \frac{1}{2} D(x)=21。
五、理论推演
生成器 G 隐式定义概率分布
p
g
p_g
pg 作为
z
∼
p
z
z \sim p_z
z∼pz 时获得的样本 G(z) 的分布。因此,我们的目标是在提供足够的容量和训练时间的情况下,算法 1 收敛到
p
d
a
t
a
p_{data}
pdata 的准确估计器。本节中的分析是在非参数背景下进行的,这意味着我们通过检查概率密度函数空间内的收敛性来考虑具有无限容量的模型。
在 4.1 节中,我们将证明当
p
g
=
p
d
a
t
a
p_g = p_{data}
pg=pdata 时,极小极大游戏达到全局最优。随后,在4.2节中,我们将确定算法1有效地优化了方程1,从而达到了预期的结果。
算法 1:生成对抗网络的小批量随机梯度下降训练。应用于鉴别器的步骤数 k 是一个超参数。我们在实验中使用了 k = 1,这是最便宜的选择。

5.1 p g = p d a t a p_g = p_{data} pg=pdata的全局最优性
我们首先检查固定生成器 G 的最佳判别器 D。
命题1.当G固定时,最优判别器D为
D
G
∗
(
x
)
=
p
d
a
t
a
(
x
)
p
d
a
t
a
(
x
)
+
p
g
(
x
)
(
2
)
D^∗_G(x) = \frac{p_{data}(x)}{p_{data}(x) + p_g(x)} \;\;(2)
DG∗(x)=pdata(x)+pg(x)pdata(x)(2)
证明。给定任何生成器 G,判别器 D 的训练标准是最大化
数量 V (G, D)
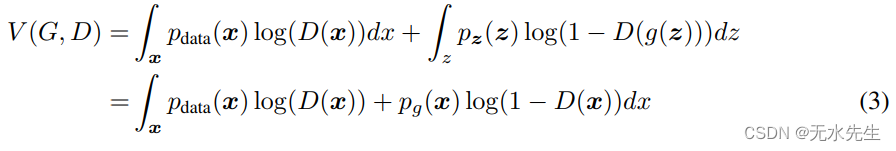
对于任何
(
a
,
b
)
∈
R
2
∖
{
(
0
,
0
)
}
(a, b) \in \mathbb{R}^2 \setminus \{(0, 0)\}
(a,b)∈R2∖{(0,0)},函数
y
映射到
a
log
(
y
)
+
b
log
(
1
−
y
)
y \ 映射到 a \log(y) + b \log(1 - y )
y 映射到alog(y)+blog(1−y) 在
a
a
+
b
\frac{a}{a+b}
a+ba 处达到 [0, 1] 的最大值。判别器不需要在
Supp
(
p
d
a
t
a
)
∪
Supp
(
p
g
)
\text{Supp}(p_{data}) \cup \text{Supp}(p_g)
Supp(pdata)∪Supp(pg) 之外定义,这将得出证明。请注意,D 的训练目标可以解释为最大化估计条件概率
P
(
Y
=
y
∣
x
)
P(Y = y|x)
P(Y=y∣x) 的对数似然,其中 Y 表示 x 是否来自
p
d
a
t
a
p_{data}
pdata(其中 y = 1 )或来自
p
g
p_g
pg (y = 0)。方程中的极小极大游戏。 1 现在可以重新表述为:
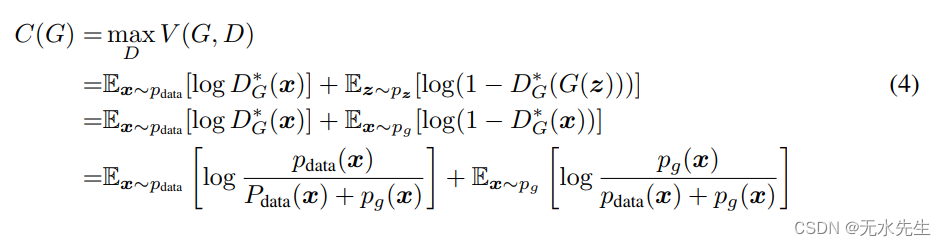
定理 1. 虚拟训练标准 C(G) 的全局最小值达到当且仅当
p
g
=
p
d
a
t
a
p_g = p_{data}
pg=pdata。此时,C(G) 的值达到
−
l
o
g
4
− log 4
−log4。
证明。对于
p
g
=
p
d
a
t
a
p_g = p_{data}
pg=pdata,
D
G
∗
(
x
)
=
1
/
2
D^*_G(x) = 1/2
DG∗(x)=1/2,(考虑方程 2)。因此,通过检查等式 4,当在
D
G
∗
(
x
)
=
1
/
2
D^*_G(x) = 1/2
DG∗(x)=1/2的时候
,我们发现
C
(
G
)
=
l
o
g
1
/
2
+
l
o
g
1
/
2
=
−
l
o
g
4
C(G) = log 1/2 + log 1/2 = − log 4
C(G)=log1/2+log1/2=−log4。要看出这是 C(G) 的最佳可能值(仅在
p
g
=
p
d
a
t
a
p_g = p_{data}
pg=pdata 时达到),请观察
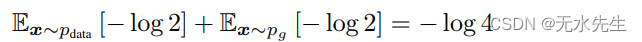
并从
C
(
G
)
=
V
(
D
G
∗
,
G
)
C(G) = V (D^*_G, G)
C(G)=V(DG∗,G),我们得到:
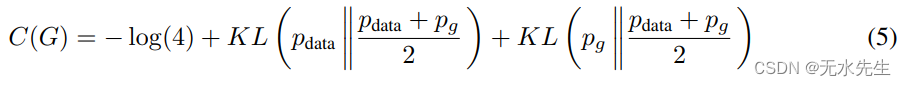
其中 KL 是 Kullback-Leibler 散度。我们在前面的表达中认识到詹森——模型分布与数据生成过程之间的香农散度:
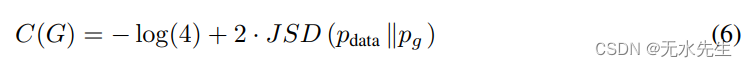
由于两个分布之间的 Jensen-Shannon 散度始终为非负,并且仅当分布相同时才为零,因此已证明
C
∗
=
−
log
(
4
)
C^* = -\log(4)
C∗=−log(4) 是
C
(
G
)
C(G )
C(G),唯一的解决方案是
p
g
=
p
d
a
t
a
p_g = p_{data}
pg=pdata,这意味着生成模型完美地复制了数据生成过程。
5.2 算法1的收敛性
命题2.如果G和D有足够的容量,并且在算法1的每一步,判别器
允许达到给定 G 的最优值,并且更新
p
g
p_g
pg 以改进标准
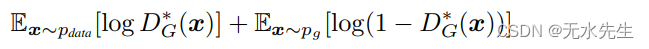
这样,
p
g
p_g
pg收敛于
p
d
a
t
a
p_{data}
pdata
证明。将
V
(
G
,
D
)
=
U
(
p
g
,
D
)
V(G, D) = U(p_g, D)
V(G,D)=U(pg,D) 视为
p
g
p_g
pg 的函数,如上述标准中所建立的。观察
U
(
p
g
,
D
)
U(p_g, D)
U(pg,D) 在
p
g
p_g
pg 中是凸的。凸函数上界的导数包括达到最大值时的导数。换句话说,如果
f
(
x
)
=
sup
α
∈
A
f
α
(
x
)
f(x) = \sup_{\alpha \in A} f_\alpha(x)
f(x)=supα∈Afα(x) 并且每个
f
α
(
x
)
f_\alpha(x)
fα(x) 在 x 上都是凸的,那么
∂
f
β
(
x
)
∈
∂
f
\partial f_\beta( x) \in \partial f
∂fβ(x)∈∂f 如果
β
=
arg
sup
α
∈
A
f
α
(
x
)
\beta = \arg\sup_{\alpha \in A} f_\alpha(x)
β=argsupα∈Afα(x)。这相当于在给定相应的
G
G
G 的情况下,在最优
D
D
D 处对
p
g
p_g
pg 执行梯度下降更新。
sup
D
U
(
p
g
,
D
)
\sup_D U(p_g, D)
supDU(pg,D) 在
p
g
p_g
pg 中是凸的,具有唯一的全局最优值,如定理 1 所示。因此,通过
p
g
p_g
pg 的足够小的更新,它会收敛到
p
x
p_x
px,从而完成证明。
在实际应用中,对抗网络通过函数 G ( z ; θ g ) G(z;\theta_g) G(z;θg)表示一组受约束的 p g p_g pg分布,并且优化的是 θ g \theta_g θg而不是 p g p_g pg本身。使用多层感知器定义 G G G 在参数空间中引入了许多临界点。尽管如此,多层感知器在现实场景中令人印象深刻的性能表明,尽管缺乏理论保证,它们仍然是一个可行的模型。
六、实验
我们使用一系列数据集训练对抗网络,包括 MNIST[23]、多伦多人脸数据库(TFD) [28] 和 CIFAR-10 [21]。发电机网络使用整流器线性激活的混合[19,9] 和 sigmoid 激活,而判别器网络使用 maxout [10] 激活。dropoff [17]应用于训练鉴别器网络。虽然我们的理论框架允许使用生成器中间层的丢失和其他噪声,我们仅使用噪声作为输入生成器网络的最底层。