早在19年5月就在某站上看到sylar的视频了,一直认为这是一个非常不错的视频。
由于本人一直是自学编程,基础不扎实,也没有任何人的督促,没能坚持下去。
每每想起倍感惋惜,遂提笔再续前缘。
为了能更好的看懂sylar,本套笔记会分两步走,每个系统都会分为两篇博客。
分别是【知识储备篇】和【代码分析篇】
(ps:纯粹做笔记的形式给自己记录下,欢迎大家评论,不足之处请多多赐教)
QQ交流群:957100923
ByteArray模块-知识储备篇
一、我们写代码时没有思考的问题
我们在用编辑器或者高级点的IDE编写代码的时候,往往会忽略掉一些问题,潜意识当中认为这是“理所当然”的,比如以下的问题。
问:我们所写的代码(C++)是保存在哪里的?
答:保存在磁盘中,是一些文本文件。
问:我们使用编辑器编写C++代码时,你所编辑的操作会直接修改磁盘中的文件吗?
答:不会,因为编辑器是一个软件,或者说是一个程序,是运行在内存当中的。当我们用编辑器打开一个C++文件时,其实是这个编辑器程序调用文件IO将磁盘中对应C++文件的内容拷贝到了该编辑器程序所在的某段内存中。然后编辑器程序会将加载到的文件内容展现给我们看到。当我们编辑这个C++文件的时候,其实只是对这段内存中的数据进行修改,并不会改动对应磁盘中的文件。只有在特定情况下,编辑器才会触发对磁盘上的文件进行“写”的操作,比如我们按ctrl+s的时候。
问:写一个C++程序,他是怎么运行的呢?
答:这个步骤十分复杂,但是我们可以简单描述一下:首先我们已经知道代码源文件其实就是磁盘中的一些文本文件,那么如果要运行我们写的代码,就需要编译器来将我们写的文本文件编译成可执行文件(注意,这个可执行文件是提供给操作系统看的,可不是直接提供给CPU执行的),然后我们调用操作系统提供的接口或者命令来执行这个可执行文件(注意,可执行文件也是文件,也是存放在磁盘中的哦),此时操作系统就会将可执行文件加载到内存中,并且把可执行文件中的内容当做指令让CPU执行。
问:我们的程序归根结底是在干什么呢?
答:处理数据! 我们的代码分两个部分:第一部分是数据,第二部分是指令。在我们的程序中,数据就是存放在某个内存块中的具体的值,而指令就是对这个内存块的值进行读取或者修改的操作。
问:你可以解释一下 int a = 1; 这行代码吗?
答:首先我们写的代码是给编译器看的,比如C++代码需要通过C++编译器编译,所谓编译就是让编译器将源码文件翻译成可执行文件的过程(编译有很多阶段,我们不再深入)。那么站在编译器的角度我们先来分析这行代码:标记一块内存地址名称为a,这块地址的大小是int类型的大小,其中的内容为1。这里我们说的都是人话,实际上编译器会编译成可执行文件。接下来我们站在操作系统的角度来思考,操作系统会调用CPU来执行这行代码:首先选取一块空闲的内存,大小是4或8个字节(这里不深究是多少),将这块内存的内容设置为1。
问:如果你写了一个结构体,其中记录了一个用户对象的年龄和名称如下:
struct User{
std::string name = "XYZ";
int age = 29;
};
我们知道在程序运行时,这个结构体数据是在内存当中的,假如我们的程序遇到问题了需要停止运行,但是我们又不想丢失掉这部分数据,因为我们下次启动程序时还需要这份数据信息,我们有什么办法吗?
答:我们可以将数据信息存储到磁盘上,这样程序停止运行时虽然内存空间已经释放了,但是磁盘内容是持久化存储的,当我们再次运行程序的时候就可以从对应的磁盘中加载之前保存的那部分数据信息。
问:那我们该如何将数据保存到磁盘中呢?该以什么样的形式保存呢?
答:上述结构体User是写给编译器看的,其中真正的数据只有 “XYZ” 和 29。所以我们只要在磁盘上记录下这两个值就可以了。但是磁盘上存储的信息都是0和1,分不清具体表示什么,考虑到后续我们要从磁盘上读取,我们就需要知道从哪里开始多大的空间算作一个数据信息,那么我们就需要额外的一些信息来对这部分数据进行描述,以便能够后续准确的读取磁盘中的数据。
问:是否可以将以上所说的数据转换过程过程定义一个称呼呢?
答:我想将内存中的数据转化为方便磁盘存储的格式叫做 【序列化】,将磁盘数据加载到内存后转换为方便我们程序操作的格式过程叫做 【反序列化】。注意,这里的格式互相转换称之为【序列化】和【反序列化】,而不是存储到磁盘的过程,【序列化】与【反序列化】不仅仅方便磁盘存储,还可以用来网络通信等等。
二、序列化与反序列化
通过上面的问答,我想大家已经对序列化与反序列化有了一定的了解。那么如果是你,你会怎么做序列化的操作呢?
如果看过 【HOOK模块-知识储备篇】的第三点 编译器的限制(函数重载问题) 应该会有一些想法。我把部分内容搬过来看:
有以下一段代码:
int add(int x, int y){
return x + y;
}
int main(int argc, char** argv){
add(1,2);
}
C++编译器编译后使用 objdump 反汇编看看
g++ -o test test.cc
objdump -S test
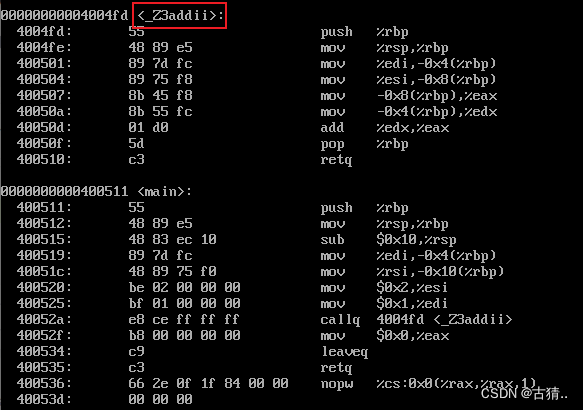
可以看到用C++编译器编译后将函数名称add 改成了 _Z3addii
_Z :表示linux环境下
3 :用接下来的三位表示函数名称
add :函数名称
ii :参数类型是 int int
这里划重点 【3 :用接下来的三位表示函数名称】
哇🤩当时我看到这里时,觉得好(女少口我)!那我们是不是可以把这个方式用在序列化上呢?
假如我们要存储一个int类型的数据值为1,用二进制后我们不就可以这样表示了吗:
00000001 00000001
虽然两段数据一样,但是含义大不相同,第一个00000001意思是从这开始一个字节(8位)表示一个数据信息,也是就是接下来的 00000001 这8位表示一个整体,换算为十进制就是1。
为了避免大家搞混乱,我再举个例子,假如我要存储一个int类型的数据,值为3,我们该如何表示呢?
00000001 00000011
其中 00000001 表示接下来的1字节(8位)表示一个整体,这一个字节是 00000011 ,转为十进制就是 3。
当然有更详细的介绍,这里也只是抛转的作用,具体的可以看一下这一篇文章 【TLV编码通信协议设计】
三、TLV 格式结构
在上诉描述中我们使用的格式是LV格式,但这种格式只能描述最基本的类型,无法描述格式嵌套的结构,所以我们要改进他,增加一个类型标记T,使他更加的灵活。这也就诞生了TLV格式。
TLV:TLV是指由数据的类型Tag,数据的长度Length,数据的值Value组成的结构体,几乎可以描任意数据类型,TLV的Value也可以是一个TLV结构,正因为这种嵌套的特性,可以让我们用来包装协议的实现。
说白了用于描述基本数据的时候都能理解,但是TLV本身就是一种结构,所以为了灵活,也可以套娃的方式描述TLV结构。
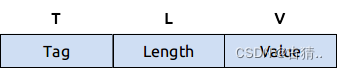
1.Tag说明
Tag 描述Value的数据类型,TLV嵌套时可以用于描述消息的类型(说白了就是value是TLV数据也是支持的)

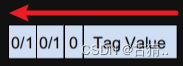
1.1.Tag首字节(注意红色箭头方向,别搞反了)
第6~7位:表示TLV的类型,00表示TLV描述的是基本数据类型(Primitive Frame, int,string,long…),01表示用户自定义类型(Private Frame,常用于描述协议中的消息)。
第5位: 表示Value的编码方式,分别支持Primitive及Constructed两种编码方式, Primitive指以原始数据类型进行编码,Constructed指以TLV方式进行编码,0表示以Primitive方式编码,1表示以Constructed方式编码。也就是说这里是否为1来标记是否 “套娃”。
第0~4位: 当Tag Value小于0x1F(31)时也就是小于全是1的时候,首字节0~4位用来描述Tag Value,否则0~4位全部置1,作为存在后续字节的标志,Tag Value将采用后续字节进行描述。
1.2.Tag后续字节
后续字节采用每个字节的0~6位(即7bit)来存储Tag Value, 第7位用来标识是否还有后续字节。
第7位: 描述是否还有后续字节,1表示有后续字节,0表示没有后续字节,即结束字节。
第0~6位: 填充Tag Value的对应bit(从低位到高位开始填充),如:Tag Value为:0000001 11111111 11111111 (10进制:131071), 填充后实际字节内容为:10000111 11111111 01111111。

2. Length 描述Value的长度
2.1.定长方式(DefiniteForm)
定长方式中,按长度是否超过一个八位,又分为短、长两种形式,编码方式如下:
2.2.1.短形式
短形式: 字节第7位为0,表示Length使用1个字节即可满足Value类型长度的描述,范围在0~127之间的。

2.2.2.长形式
即Value类型的长度大于127时,Length需要多个字节来描述
这时第一个字节的第7位置为1
0~6位用来描述Length值占用的字节数,然后直将Length值转为byte后附在其后
如: Value大小占234个字节(11101010),由于大于127,这时Length需要使用两个字节来描述,10000001 11101010

2.2.不定长方式(IndefiniteForm)
Length所在八位组固定编码为0x80,但在Value编码结束后以两个0x00结尾。
这种方式使得可以在编码没有完全结束的情况下,可以先发送部分数据给对方。

3.Value 描述数据的值
由一个或多个值组成 ,值可以是一个原始数据类型(Primitive Data),也可以是一个TLV结构(Constructed Data)
3.1.原始数据类型(Primitive Data)

3.2.TLV结构(Constructed Data)

如果看完以上的内容还处于有点懵的状态,那么请多阅读几遍,也可以搜索下相关TLV的博客。
特别是 Tag 相关的解释,我想一定会有帮助。这将为接下来的代码分析打下基础。
四、总结
本篇博客其实还差一个demo,由于时间原因没有整理出来,若是关注博主的可以隔几天再来查看
【最后求关注、点赞、转发】
QQ交流群:957100923