墨天轮于5月29日正式发布 《2023年中国数据库年度行业分析报告》,总结梳理了中国数据库行业的技术演进及趋势。作为云上数据库和数据计算领域的领先者,拓数派受邀参与创作,联合编写了《AI 时代下新一代数据仓库的演进》《从数据库到数据计算系统》、《传统数仓的痛点》等多个章节,本文为精华内容节选。
随着科学技术的发展,特别是信息技术的发展,人类获取数据、存储数据、分析数据的能力有了划时代的进步。近年来,移动互联网、物联网、5G 等技术持续发展,全球数据圈(Global Datasphere)呈指数级递增, IDC 预测全球数据圈将于 2025 年增长值 175ZB,而中国的数据圈有望于 2025 年爆炸式增长为世界第一。众多围绕数据获取、数据存储、数据分析的应用也如同雨后春笋般地涌现出来。这些事实说明,数据很有可能成为人类科技和经济进步的下一个引爆点。 因此人们提出了“数据要素”的概念,把数据列为和“人力”、“资源”等并列的生产要素,由此可见人们已经对数据的定位产生了本质的变化。
2023 年国家正式成立了国家数据局,负责协调推进数据基础制度建设,统筹数据资源整合共享和开发利用,统筹推进数字中国、数字经济、数字社会规划和建设等,不仅体现了对数据资源的战略性管理和规范化利用的需求,也体现了国家层面对数字经济发展和数据治理的重视。
此外,云平台的快速发展也为数据系统带来了新的发展机遇。云平台代表了目前最大的计算能力、存储能力和水平扩展能力。云平台为数据系统提供了近乎无限的存储资源和算力资源, 使得类似 ChatGPT 这样的应用成为可能。因此越来越多的企业将应用向云上迁移,而越来越多的数据也流向云上。
1 AI 时代下新一代数据仓库
为了助力企业优化计算瓶颈,充分利用和发挥数据规模优势,构建核心技术壁垒,更好地赋能业务发展,新一代数据仓库需要能够整合企业所有多模态数据资源,提供多模态大模型下数据计算支撑,更贴近数据科学家的需求和使用。
1.1 数据仓库上云虚拟化的核心价值
新一代数据仓库需要能够采用领先的数仓虚拟化技术,将多个数仓统一整合到一个高可用的云虚拟数仓,打通多云的数据管道,数据计算资源按需扩缩容,提升数仓的敏捷性和弹性,助力企业降低数仓管理复杂度,具有可扩展性、灵活性和可靠性等优点。典型产品包括拓数派的云原生虚拟数仓 PieCloudDB Database 产品。
- 降低数仓硬件和管理成本
通过云原生存算分离架构,物理数仓被整合到云原生数据计算平台,支持根据数据授权动态创建虚拟数仓,打破数据孤岛,解决数据多副本问题,帮助企业降低数仓管理复杂度,以更低的成本实现存算资源在云上更灵活的配置。
- 提升数据计算资源利用效益
数据计算资源按需扩缩容,实现计算资源配置最优化,提升数仓的敏捷性和弹性,打开无限数据计算空间,支撑更大模型所需的数据和计算。更好地赋能业务发展并走向绿色。
新一代数据仓库天然支持云环境,无需进行额外的定制。企业可根据对资源的需求,灵活地以低成本和高效的方式,单独地进行存储或计算资源的弹性扩展,提高了资源的利用率,节省空间成本和能耗开销。并支持随着负载的变化实现高效的伸缩,轻松应对 PB 级海量数据,具有高容错性、易于管理和便于观察等特性。结合可靠的自动化⼿段,能够轻松地对系统做出频繁和可预测的重⼤变更。
云原生的“即开即用”特性为企业节省了大量运维开支。由于其计算节点部署于云端,摆脱了物理限制和潜在的延迟,可随时随地通过互联网轻松管理,无需任何硬件。数据随时随地可用,无需处理任何后端技术问题,为企业进行跨部门、跨区域的数据共享和协作开辟了捷径,保证了企业的全球化进程。
- 高在线、高安全、高可靠
数据仓库上云,用户最关注的一点就是数据安全问题。传统数据平台将文件和资源存储在同一主机中,以主备节点数据方式补偿节点宕机时间,严重影响数据时效性,增加了运维的成本和难度。云时代下的数据仓库通过数据透明加密(TDE)等技术保证所有数据在落盘前完成加密,服务器无感知技术 (Serverless) 利用云上无限计算资源和弹性保证了计算永远在线可用,S3 存储和跨云灾备能力保证了永不丢数,确保业务连续性。
1.2 数据仓库上云虚拟化的技术突破
为了实现数据仓库上云虚拟化,为企业提供全新基于云数仓数字化解决方案,助力企业建立以数据资产为核心的竞争壁垒,以云资源最优化配置实现无限数据计算可能,新一代数据仓库需要实现以下技术突破:
- 打造云原生存算分离架构,云上资源弹性分配
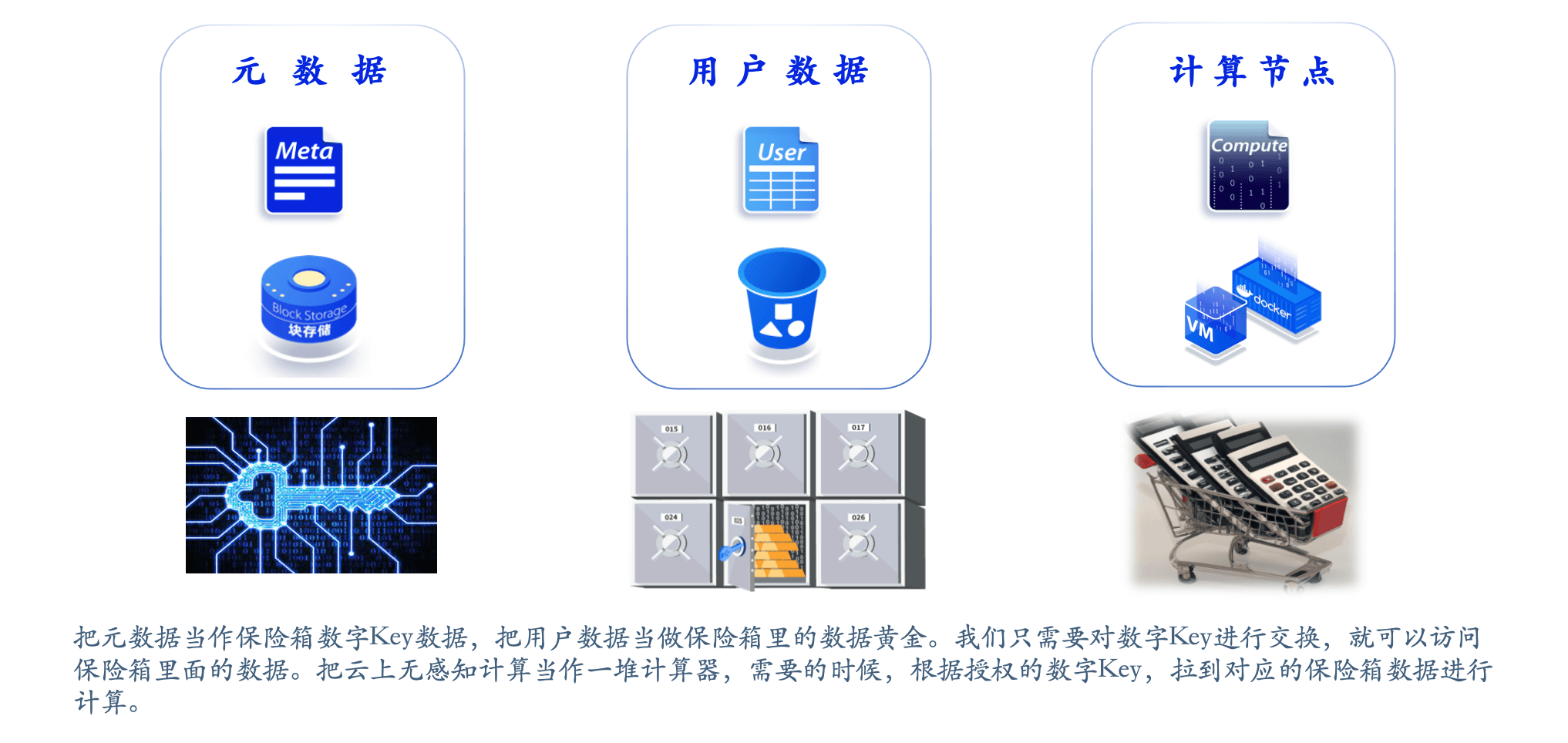
云时代下的数据仓库在设计与实现的过程中,需要充分考虑云平台的弹性和分布式特性,实现元数据、用户数据和计算资源的解耦分离。通过把元数据,用户数据和计算资源进⾏解耦,元数据可以被当作保险箱数字 Key 数据,用户数据可以被当作保险箱里的数据黄⾦。用户只需要对数字 Key 进⾏交换,就可以访问保险箱里面的数据。把云上⽆感知计算当作⼀堆计算器,需要的时候,根据授权的数字 Key,拉到对应的保险箱数据即可进⾏计算。
新一代的数据仓库需采用高效并行的方式进行数据加载和处理,处理速度随节点增加而提升,支持流数据快速加载。通过云原生虚拟数仓的存算分离架构,实现多集群并发执行任务,企业可灵活进行扩缩容,随着负载的变化实现高效的伸缩,轻松应对 PB 级海量数据,具有高容错性、易于管理和便于观察等特性。并结合可靠的自动化⼿段,轻松地对系统做出频繁和可预测的重⼤变更。
- 打造云原生交互存储与缓存架构设计
对象存储天然适应云原生环境,与云计算平台、容器编排技术等其他云原生技术无缝集成。此外,相对于传统的存储方式,对象存储通常具有更低的成本,成为数据仓库更有优势的一种存储选择。然而,由于对象存储通常是基于分布式系统和网络存储的,数据的传输和检索通常需要网络进行,因此相对于本地存储,会存在一定的延迟。这一缺陷也对云时代的数据仓库底层的存储和存储引擎也提出了新的挑战。
新一代数据仓库需要能够具备强大的存储适配接口能力,确保支持各种类型存储,保证和不同云环境的兼容性。此外,各个计算节点需针对元数据和用户数据均设计多层缓存结构,避免网络延迟和数据移动,提高计算效率,保证用户的实时性需求。针对底层对象存储,新一代数据仓库需设计高效的文件格式,在节省网络请求的同时提高计算效率。
- 云原生优化器的设计与打造
优化器作为数据库管理系统中的关键技术,对数据库性能和效率具有重要影响。针对云原生和分布式场景,优化器需要实现包括聚集下推、预计算、Block Skipping 等高级特性,全面满足各种复杂的分析查询需求。
- 向量化执行器的设计与打造
数据分析和应用的重要性日益增长,对于数据平台来说,极致的性能是关键需求之一。为实现更高效的数据并行计算,新一代数据仓库优秀的执行器需要能够充分利用硬件资源,如 CPU 的并行计算能力和 SIMD 指令集,充分利用了数据并行计算的优势,通过将多个数据元素打包成向量,并同时对其执行相同的操作,提高了计算效率和吞吐量。
- 大模型时代 AI 的支持与集成
新一代数据仓库是大模型时代的分析型数据库升维。对于大模型而言,模型所需的数据都经过了向量化过程,经过向量化的数据可以大幅提升模型的查找效率,降低训练成本。大模型时代下的数据仓库需要能够进一步实现海量向量数据存储与高效查询,助力多模态大模型 AI 应用,支持和配合大模型的 Embeddings,提供对向量的高效存储、索引和查询功能,具备高效存储和检索向量数据、相似性搜索、向量索引、向量聚类和分类、高性能并行计算、强大可扩展性和容错性等特性,帮助基础模型在场景 AI 的快速适配和二次开发。
- 对新硬件的支持和兼容
为了加速大数据处理和计算的性能,云时代下新一代数据仓库需要能够充分依赖新的硬件来进行异步计算,例如 GPU、FPGA 等。通过充分利用新一代硬件加速器,数据仓库可以实现更高的计算性能、更低的延迟和更好的扩展性。这将使得大数据处理和计算变得更加高效和可靠,推动云时代下数据分析和决策支持能力的进一步发展。
2 从数据库到数据计算系统
云计算技术、人工智能(AI)等多种技术的快速发展,数据系统也展现出云原生和智能化的趋势。数据分析技术也在从传统的 BI 向支撑深度学习、大语言模型等新型应用演进。数据系统的走向云原生化和 AI 化是数据系统发展的新趋势。
人们通常说的数据库是指关系型数据库管理系统(Relational Database Management System,RDBMS)。除了关系型数据库之外,还有针对各种非结构化数据的数据库,例如文档(Document)数据库、图(Graph)数据库、流式(Streaming)数据库等。
企业的数据平台一般由多种数据库联合组成,不同种类的数据库分别处理不同的数据。为了统一管理,人们提出了“企业数据湖”的概念,一般来说,多种数据源和针对不同数据源的处理工具组成了企业数据湖。在数据湖中,数据根据使用的频率分为“冷-温-热”数据,“热”数据一般存储在数据仓库中,在处理“温”数据或者“冷”数据时,一般需要有一个“由湖入仓”的“数据抽取-数据转换-数据加载”(ETL)操作,把数据加载到数据仓库中。
为了打破各种数据种类的边界,降低移动数据的 ETL 操作的代价,人们提出了“湖仓一体”架构,来解决例如事务支持、数据模型化、数据治理等问题。云原生技术和人工智能技术的发展,对数据库、数据湖的架构带来了潜移默化的影响。
一种新型的数据架构“数据计算系统(data computing system)”被业界提出。 数据和计算是数据计算系统的两个独立子系统,其中数据是核心,计算是产生数据价值的手段。
2.1 数据子系统
-
元数据(metadata)从用户数据中分离,各个计算任务提供数据的发现、授权、使用等服务。
-
用户数据打破数据类型和数据模式的边界,使用统一的格式存储。
2.2 计算子系统
针对不同种类的数据使用不同的计算引擎:
-
SQL 引擎用来执行关系型数据的计算任务;
-
向量引擎用来执行与向量数据相关的计算任务;
-
图数据引擎用来执行与图数据相关的计算任务;
-
Python/R 等引擎用来执行 BI/AI 相关的 Python/R 的计算任务。
除此之外,数据计算系统还有如下特点:
- 事务支持
对事务的 ACID 支持,可确保数据并发访问的一致性、正确性。
- 数据治理
保证数据完整性,并且具有健全的治理和审计机制。
- BI 支持
支持直接在源数据上使用 BI 工具,这样可以加快分析效率,降低数据延时。
- 开放性
采用开放、标准化的存储格式提供丰富的 API 支持,因此,各种工具和引擎(包括机器学习和 Python/R 库)可以高效地对数据进行直接访问。
- 支持多种数据类型
具备多模态数据支持能力,支持包括结构化数据、半结构化数据、非结构化数据及二进制数据等数据类型。
- 支持各种工作负载
支持包括数据科学、机器学习、SQL 查询、分析等多种负载类型。