大侠幸会,在下全网同名「算法金」 0 基础转 AI 上岸,多个算法赛 Top 「日更万日,让更多人享受智能乐趣」
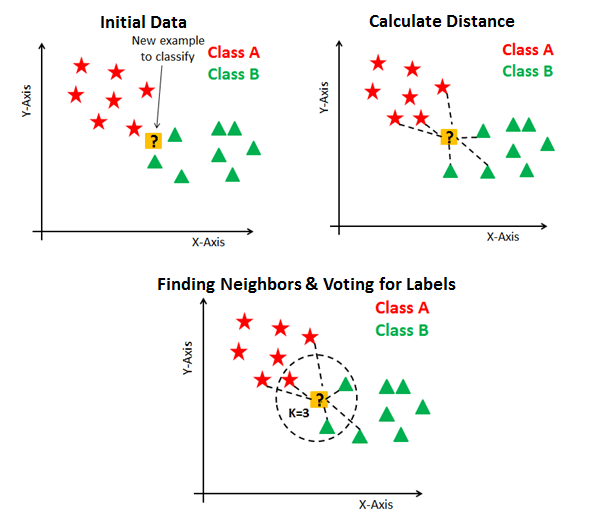
KNN算法的工作原理简单直观,易于理解和实现,这使得它在各种应用场景中备受青睐。
我们将深入探讨KNN算法,从基本概念到实现细节,从算法优化到实际应用,我们都会一一展开。通过本文,你将了解到KNN算法的核心要点,以及如何将这一强大的工具应用到实际问题中。

第一部分:KNN算法的基本概念
定义
KNN算法,全称为K-Nearest Neighbors,是一种基于实例的学习算法,或者说是一种基于记忆的学习方法。它的核心思想是,通过一个样本的K个最近邻居的多数属于某个类别,来预测该样本的类别。
工作原理
KNN算法通过以下步骤进行分类或回归:
- 确定距离度量:首先确定一个距离度量方法,如欧氏距离或曼哈顿距离。
- 寻找最近邻居:计算待分类样本与数据集中每个样本的距离,并找出距离最近的K个样本。
- 决策:在分类任务中,通过多数投票法决定待分类样本的类别;在回归任务中,则通过计算K个最近邻居的属性的平均值来预测。
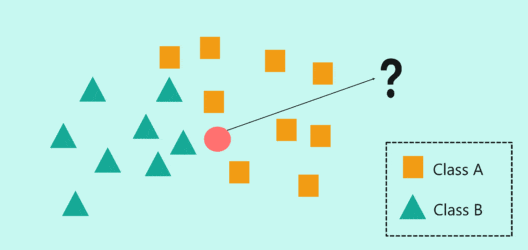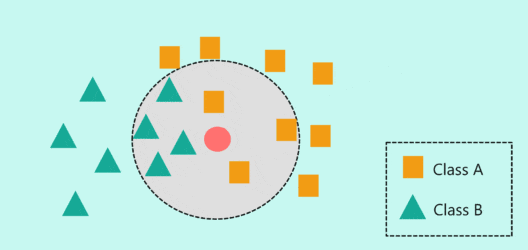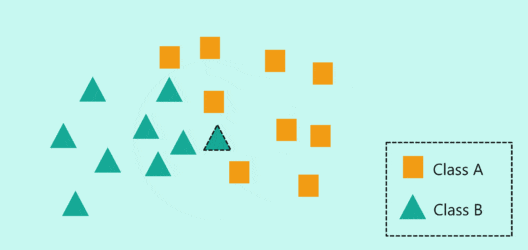
算法特点
KNN算法具有以下显著特点:
- 简单性:算法原理简单,易于理解和实现。
- 无需训练:不需要训练阶段,直接使用整个数据集进行预测。
- 自适应性:随着数据集的变化,KNN算法可以自适应地调整其预测结果。
第二部分:KNN算法的工作原理
距离度量
在KNN算法中,距离度量是确定样本之间相似性的关键。以下是几种常用的距离度量方法:

寻找最近邻居
确定一个样本的K个最近邻居涉及以下步骤:
- 计算距离:对于数据集中的每个点,使用选定的距离度量计算与待分类样本的距离。
- 排序:根据计算出的距离对所有点进行排序。
- 选择邻居:选择距离最小的前K个点作为最近邻居。
多数投票法(分类任务)
在分类任务中,KNN算法通过以下步骤进行决策:
- 收集标签:收集K个最近邻居的类别标签。
- 统计:统计每个类别的出现次数。
- 投票:选择出现次数最多的类别作为待分类样本的预测类别。
平均值法(回归任务)
在回归任务中,KNN算法预测一个连续值,通常通过以下步骤:
- 收集属性值:收集K个最近邻居的属性值。
- 计算平均值:计算这些属性值的平均值。
- 预测:将平均值作为待分类样本的预测结果。

第三部分:KNN算法的优缺点
优点
- 易于理解和实现:KNN算法的原理简单直观,易于理解,且实现起来相对容易。
- 不需要训练阶段:由于KNN算法在预测时直接使用整个数据集,因此它不需要一个专门的训练阶段。
- 自适应性强:KNN算法能够随着数据集的更新而更新,能够适应数据的变化。
- 可用于非线性问题:KNN算法不假设数据的分布,因此可以用于非线性问题的分类和回归。
缺点
- 计算密集型:由于在每次预测时都需要计算新样本与所有训练样本之间的距离,KNN算法在大数据集上可能变得非常慢。
- 存储需求高:KNN算法需要存储全部数据集,因此对内存的需求较高。
- 维数灾难:随着特征维度的增加,距离度量可能会变得不那么有效,导致所谓的“维数灾难”。
- 对不平衡数据敏感:KNN算法对类别不平衡的数据集比较敏感,少数类可能会被多数类所淹没。
- 对噪声敏感:KNN算法对噪声数据点比较敏感,噪声点可能会对预测结果产生较大影响。
第四部分:KNN算法的适用场景与局限性
适用场景
- 小规模数据集:KNN算法在小规模数据集上表现良好,因为它不需要复杂的训练过程。
- 基线模型:作为基线模型,KNN算法可以快速提供一个简单的性能标准,用于与其他更复杂的模型进行比较。
- 实时决策:由于KNN算法不需要预先训练,它可以用于需要快速响应的实时决策场景。
- 低维数据:在特征维度不是非常高的情况下,KNN算法能够很好地工作,因为它依赖于距离度量。
局限性
- 高计算成本:对于大规模数据集,KNN算法在预测时的计算成本非常高。
- 内存消耗:由于需要存储整个数据集,KNN算法对内存的需求可能会很大。
- 数据不平衡问题:当数据集中某些类别的样本数量远多于其他类别时,KNN算法可能会倾向于预测多数类。
- 噪声敏感性:KNN算法对异常值和噪声点比较敏感,这可能会影响其预测的准确性。

第五部分:KNN算法的实现与案例
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import load_iris
# 加载内置的Iris数据集
iris = load_iris()
X = iris.data
y = iris.target
target_names = iris.target_names
# 数据标准化
scaler = StandardScaler()
X = scaler.fit_transform(X)
# 数据可视化(选择前两个特征进行可视化)
plt.figure(figsize=(10, 6))
for i, label in enumerate(target_names):
plt.scatter(X[y == i, 0], X[y == i, 1], label=label)
plt.xlabel('特征 1 (标准化)')
plt.ylabel('特征 2 (标准化)')
plt.title('Iris 数据分布')
plt.legend()
plt.show()
# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 选择最佳K值
best_k = 1
# 使用最佳K值训练模型
best_knn = KNeighborsClassifier(n_neighbors=best_k)
best_knn.fit(X_train, y_train)
accuracy = best_knn.score(X_test, y_test)
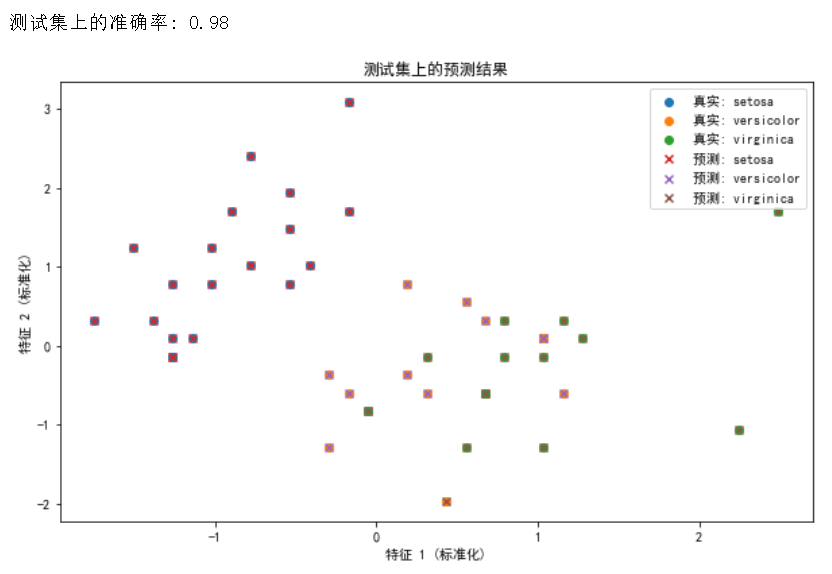
print(f"测试集上的准确率: {accuracy:.2f}")
# 可视化测试结果(选择前两个特征进行可视化)
plt.figure(figsize=(10, 6))
y_pred = best_knn.predict(X_test)
for i, label in enumerate(target_names):
plt.scatter(X_test[y_test == i, 0], X_test[y_test == i, 1], label=f'真实: {label}')
for i, label in enumerate(target_names):
plt.scatter(X_test[y_pred == i, 0], X_test[y_pred == i, 1], marker='x', label=f'预测: {label}')
plt.xlabel('特征 1 (标准化)')
plt.ylabel('特征 2 (标准化)')
plt.title('测试集上的预测结果')
plt.legend()
plt.show()
看运行输出,还是挺强的
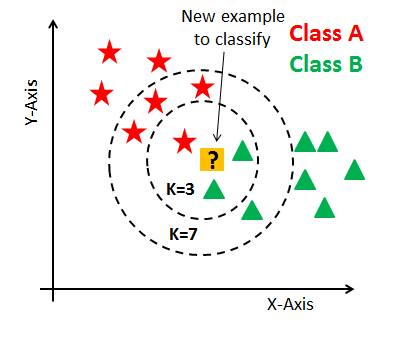
第六部分:如何选择K值
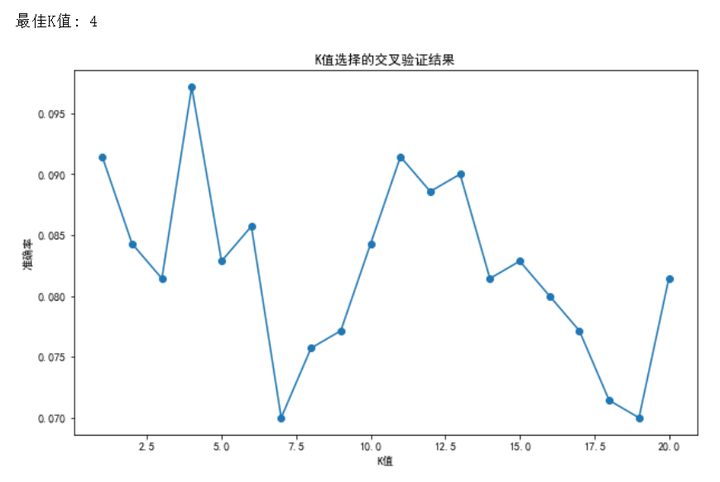
选择合适的K值是KNN算法性能的关键因素之一,如下图不同的 K值,K=3 和 K=7 结果就不一样了。
以下是一些选择K值的策略:
经验法则
选择K值时,可以遵循一些经验法则:
- 对于分类问题,K通常是奇数,以避免平票的情况。
- K值通常小于20,并且与数据集中的样本数量成反比。
交叉验证
交叉验证是一种更系统的方法来确定最佳的K值。以下是步骤:
- 划分数据:将数据集划分为训练集和测试集。
- 循环选择K值:对一系列可能的K值进行循环。
- 训练和评估:对于每个K值,使用训练集训练KNN模型,并在测试集上评估其性能。
- 选择最佳K值:选择在测试集上表现最好的K值。
以下是使用交叉验证选择K值的Python代码示例:
from sklearn.model_selection import cross_val_score
# 可能的K值列表
k_values = list(range(1, 21))
accuracies = []
for k in k_values:
knn = KNeighborsClassifier(n_neighbors=k)
# 使用交叉验证评估模型性能
accuracy = cross_val_score(knn, X, y, cv=10).mean()
accuracies.append(accuracy)
# 找到最佳K值
best_k = k_values[np.argmax(accuracies)]
print(f"最佳K值为:{best_k}")
数据集大小与K值的关系
- 小数据集:选择较小的K值,因为数据点较少,每个点的影响较大。
- 大数据集:可以选择较大的K值,因为数据点较多,每个点的影响较小。
运行后输出
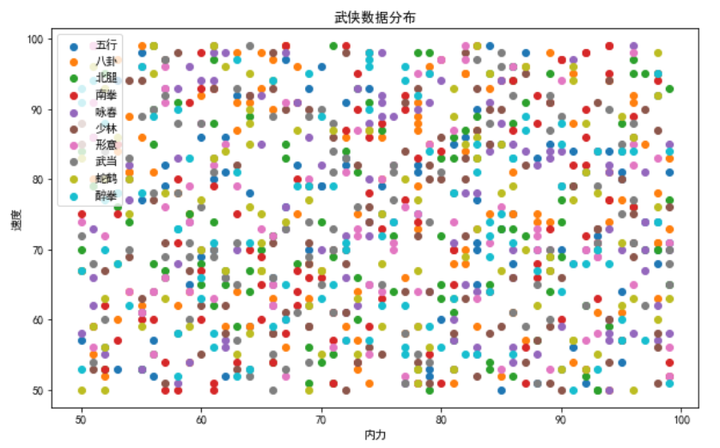
啊这,各种类别交织在一起 看起来密集恐惧症都要犯了
- 这段代码生成了一张散点图,不同门派用不同颜色表示,展示了内力和速度的标准化分布。
- 通过循环选择不同的 K 值进行交叉验证,找到表现最好的 K 值.这张图展示了不同 K 值下的交叉验证准确率,可以看到在 K=4 时准确率最高。
- 我们使用最佳 K 值(K=4)训练模型,并在测试集上进行预测和可视化,这张图展示了测试集上真实标签和预测标签的对比(略)
- 模型的预测准确率较低,这主要是数据集的问题,数据类别见区分度太低了,感兴趣的大侠可以试着调一下,怎么可以获得更高的准确率。期待能在评论区见

第七部分:KNN算法的优化策略
为了提高KNN算法的性能和适用性,我们可以采取以下几种优化策略:
距离度量的选择
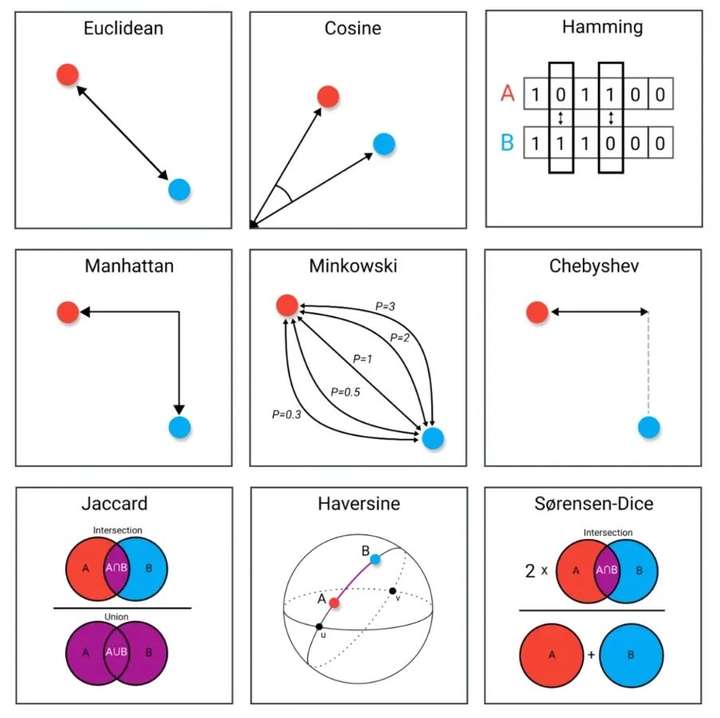
选择适当的距离度量对于KNN算法至关重要。根据数据的特性,可以选择不同的度量方法:


权重分配
在标准KNN中,所有邻居对预测结果的贡献是相等的。然而,我们可以根据距离的远近来分配权重,使得更近的邻居对预测结果有更大的影响。权重可以按照以下公式计算:

降维技术
高维数据会加剧“维数灾难”,导致KNN算法性能下降。使用降维技术如主成分分析(PCA)可以减少特征维度,同时保留数据的主要信息:
from sklearn.decomposition import PCA
# 应用PCA进行降维
pca = PCA(n_components=2) # 假设我们只保留两个主成分
X_pca = pca.fit_transform(X)
# 现在使用降维后的数据训练KNN模型
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(X_pca, y)
其他优化方法
- 使用不同的距离权重:根据问题的特性,可以为不同的特征赋予不同的距离权重。
- 动态选择K值:根据样本的局部密度动态调整K值,以适应数据的不均匀分布。

第八部分:KNN算法与其他算法的比较
在机器学习领域,选择正确的算法对于解决特定问题至关重要。KNN算法因其简单性和直观性而广受欢迎,但与其他算法相比,它也有其局限性。以下是KNN算法与几种常见算法的比较:
与决策树的比较
- 决策树:是一种监督学习算法,可以用于分类和回归。它通过学习简单的决策规则从数据特征中推断出目标值。
- 优点:易于理解和解释,可以处理分类和回归问题,对噪声数据具有一定的鲁棒性。
- 缺点:容易过拟合,对于不平衡的数据集表现不佳。
与支持向量机(SVM)的比较
- 支持向量机:是一种强大的分类器,也可以用于回归问题(称为SVR)。它通过找到数据点之间的最优边界来区分不同的类别。
- 优点:在高维空间中表现良好,对于线性和非线性问题都有解决方案。
- 缺点:参数选择(如惩罚参数C和核函数)对性能影响很大,计算复杂度较高。
与随机森林的比较
- 随机森林:是一种集成学习方法,由多个决策树组成。它通过构建多个树并进行投票来提高模型的准确性和鲁棒性。
- 优点:通常比单个决策树更准确,能够处理高维数据,对过拟合有一定的抵抗力。
- 缺点:模型可解释性较差,训练时间可能较长。
不同场景下算法选择的建议
- 数据集大小:对于小数据集,KNN和决策树可能更合适;对于大数据集,考虑使用SVM或随机森林。
- 数据维度:对于低维数据,KNN可以表现良好;对于高维数据,SVM或随机森林可能更合适。
- 模型解释性:如果需要模型具有较高的解释性,决策树可能是更好的选择。
- 计算资源:如果计算资源有限,应考虑使用计算成本较低的算法,如KNN或决策树。
[ 抱个拳,总个结 ]
在本文中,我们深入探讨了KNN算法的各个方面,从基本概念到实现细节,再到优化策略和与其他算法的比较。KNN算法以其简单直观的原理、易于实现的特点以及在小规模和低维数据集上的良好性能,确立了其在机器学习领域中的重要地位。
核心要点总结:
- 定义:KNN是一种基于实例的分类和回归算法,通过查找测试样本的K个最近邻居来进行预测。
- 工作原理:算法利用距离度量来确定最近邻居,并通过多数投票法或平均值法来进行决策。
- 优点:易于理解和实现,不需要训练阶段,自适应性强。
- 缺点:计算密集型,存储需求高,对不平衡数据和噪声敏感。
- 适用场景:小规模数据集,基线模型,实时决策,低维数据。
- 优化策略:包括选择合适的距离度量,权重分配,以及应用降维技术。
KNN算法虽然简单,但在许多实际应用中表现出色,尤其是在数据集较小且特征维度较低的情况下。然而,它也存在一些局限性,如高计算成本和对噪声的敏感性,这要求我们在应用时需要谨慎考虑。

[ 算法金,碎碎念 ]
全网同名,日更万日,让更多人享受智能乐趣
如过觉得内容有价值,烦请大侠多多 分享、在看、点赞,助力算法金又猛又持久、很黄很 BL 的日更下去;
同时邀请大侠 关注、星标 算法金,围观日更万日,助你功力大增、笑傲江湖