来源:投稿 作者:LSC
编辑:学姐
本篇文章将讲述作者对opencv和dlib基础操作的学习笔记。
首先来看opencv的11种基础操作
(1)imread 读取图片
(2)resize 图片缩放
(3)cvtColor 灰度化
(4)threshold 阈值化
(5)bitwise_not 图像取反
(6)add 按位加
(7)抠图操作
(8)rectangle 绘制方框
(9)Text 绘制文字
(10)circle 画圆
(11)VideoCapture 读取视频
其中抠图操作比较奇怪:
因为opencv读取图像像素的顺序,是先行后列,通过上面的操作,先把行找出来,再找列(这是请教了江大白大佬的),所以是img_crop = img[20:100,50:400] #[y1:y2,x1:x2]。
我猜测可能是opencv和dlib里面的坐标系有点不一样,和平时我们矩阵的坐标系是反过来的。
然后学习dlib包的安装
这个包安装了好久,一开始一直报错,先是缺了CMake这个包,安装完后还是一直报错,尝试各种办法,换国内镜像也不行,最终找到解决方案,Python 3.7 两步安装dlib(超简单!亲测有效)。https://blog.csdn.net/sinat_32857543/article/details/107396022
接着学习dlib的基础使用方法,对图像和视频分别人脸检测+关键点定位,感觉好厉害!
实战作业1
直接抠图,在原图上的左上角把抠的图直接复制上去。代码如下:
import cv2import dlib
img = cv2.imread('task1.jpg')
print(type(img))
# img = cv2.resize(img, (500, 600))
print(img.shape)
detector = dlib.get_frontal_face_detector()
faceRets = detector(img)
x_min, y_min, x_max, y_max = faceRets[0].left(), faceRets[0].top(), faceRets[0].right(), faceRets[0].bottom()
print(x_min, y_min, x_max, y_max)
cv2.rectangle(img, (x_min, y_min), (x_max, y_max), (0, 255, 0), 2)
x_text, y_text = (x_max + x_min) // 2, y_min - 15
cv2.putText(img, "face", (x_text - 30, y_text), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 1)
# print(x_max - x_min)
face = img[y_min: y_max, x_min: x_max]
print(face.shape)
lenx, leny = x_max - x_min, y_max - y_min
# 也可以写出face.shape[0], face.shape[1]#
# 令 img[0: lenx, 0:leny]这个区域与face一一对应
# for i in range(lenx):
# for j in range(leny):
# img[i, j] = face[i, j]
img[0: leny, 0: lenx] = face #也可以写成这样
cv2.imshow('homework_tesk1', img)
cv2.imwrite('homework_task1.jpg', img)
cv2.waitKey(0)
最终的结果图片是

还有一种方法,按位加也是可以的,把原图左上角的元素先赋值为0,然后在原图上的那块区域内加上截取出的人脸部分,我试了,但是结果是全黑的:
import cv2
import dlib
img = cv2.imread('task1.jpg')
print(type(img))
# img = cv2.resize(img, (500, 600))
print(img.shape)
detector = dlib.get_frontal_face_detector()
faceRets = detector(img)
x_min, y_min, x_max, y_max = faceRets[0].left(), faceRets[0].top(), faceRets[0].right(), faceRets[0].bottom()
print(x_min, y_min, x_max, y_max)
cv2.rectangle(img, (x_min, y_min), (x_max, y_max), (0, 255, 0), 2)
x_text, y_text = (x_max + x_min) // 2, y_min - 15
cv2.putText(img, "face", (x_text - 30, y_text), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 1)
# print(x_max - x_min)
face = img[y_min: y_max, x_min: x_max]
print(face.shape)
lenx, leny = x_max - x_min, y_max - y_min # 也可以写出face.shape[0], face.shape[1]
# 令 img[0: lenx, 0:leny]这个区域全为0
for i in range(lenx):
for j in range(leny):
img[i, j] = 0
img[0:leny, 0:lenx] = cv2.add(img[0:leny, 0:lenx], face)
cv2.imshow('homework_task1', img)
cv2.imwrite('homework_task1.jpg', img)
cv2.waitKey(0)
实战作业二
同理的,但是有3张图,加一个循环逐一操作:
import cv2
import dlib
img = cv2.imread('task2.jpg')
detector = dlib.get_frontal_face_detector()
faceRets = detector(img)
num = 0
x_start, y_start = 0, 0
for box_info in faceRets:
x_min, y_min, x_max, y_max = box_info.left(), box_info.top(), box_info.right(), box_info.bottom()
num += 1
face = img[y_min: y_max, x_min: x_max]
cv2.rectangle(img, (x_min, y_min), (x_max, y_max), (255, 0, 0), 3)
cv2.putText(img, "face"+str(num), ((x_min + x_max) // 2 - 30, y_min - 15), cv2.FONT_HERSHEY_SIMPLEX, 1,
(255, 0, 0), 1)
img[y_start: y_start + y_max - y_min, x_start: x_start + x_max - x_min] = face
# y_start += y_max - y_min
x_start += x_max - x_min
cv2.imshow("homeword_task2", img)
cv2.imwrite('homework_task2.jpg', img)
cv2.waitKey(0)
最终结果图片是:

人脸检测添加特效实战
下文中的代码先是介绍了对图像中的人脸添加墨镜的特效的原理、步骤和实现代码,注释非常详细,再是进阶介绍对视频中的人脸添加墨镜的特效,最后是对图像中的人脸添加兔耳帽子的特效。
实现对视频中的人脸添加兔耳帽子的特效代码和详细注释、步骤,这些都是在借鉴大白大佬的代码的基础上:
# 本文件代码目的: 读取视频,对视频中的人脸进行检测,并添加兔子耳朵的特效# 作者: lsc
import cv2 # 图像处理的opencv库import math # 数学运算库import dlib # 加载dlib算法模块import argparse # 加载解析模块
def hat_face(opt):
# 加载dlib自带的人脸检测模型
detector = dlib.get_frontal_face_detector()
# 读取兔子帽子的图片
img_hat = cv2.imread(opt.hat_path)
# 使用opencv中的VideoCapture函数,读取视频
cap = cv2.VideoCapture(opt.video_path)
# 初始化定义frame_id,便于后面跳帧
frame_id = 0
# 判断cap是否读取成功
while cap.isOpened():
# 因为视频采集,每秒可能会采集N帧图片,因此使用read函数,逐帧读取图片
# ret 返回True或Fasle,表示是否读取到图片
# frame 返回读取的图片信息
ret, frame = cap.read()
# 如果ok为false,则采集结束
if not ret:
# 打印输出,提示信息
print("Camera cap over!")
break
# frame_id加1,便于跳帧
frame_id += 1
# 如果frame_id除以10,不等于0,则不断循环,只有等于0时,才进行到下面的显示步骤,这样可以达到跳帧的效果
# 因为在算法处理中,比如一秒有25帧图像,为了提升项目速度,没有必要对每一帧都进行算法处理
# 注意:这里的10可以自行设置,如觉得跳帧太慢,可以设置大一些,比如15
if not int(frame_id) % 10 == 0:
continue
# 对读取的原始图像,进行人脸检测
faceRects = detector(frame)
# 如果len(faces)>0,则说明图片上存在人脸
if len(faceRects) > 0:
# 图片中可能存在多张人脸,依次遍历输出每张人脸的位置信息,并在特定位置,添加兔子帽子特效
for box_info in faceRects:
# 对读取的原始图像,进行人脸特征点定位
x0, y0, width_face, height_face = box_info.left(), box_info.top(), box_info.right() - box_info.left(), box_info.bottom() - box_info.top()
# 获得帽子图片的高height_hat,宽width_hat,便于后面控制帽子显示的大小
height_hat, width_hat = img_hat.shape[0], img_hat.shape[1]
# 将帽子的高度变成,适合检测到的脸型的大小
imgComposeSizeH = int(height_hat / width_hat * width_face)
# 因为帽子在脸部上方,当脸部靠近视频顶部,为了保证帽子能显示出来,帽子的高度默认为脸部到视频上方的距离
if imgComposeSizeH > (y0 - 20):
imgComposeSizeH = (y0 - 20)
# 将帽子的图片归一化到适合的宽和高大小,宽度为人脸的宽度,高度为上面调整后的帽子高度
imgComposeSize = cv2.resize(img_hat, (width_face, imgComposeSizeH), interpolation=cv2.INTER_NEAREST)
# 为了实现在人脸上方的额头,添加兔子帽子特效,只需要将兔子帽子贴到额头处即可
# 注意:y0是人脸检测框左上方顶点的y坐标,y0-20,则差不多定位到额头处,再减去imgComposeSizeH,调整后兔子帽子的高度
# 即从这个位置开始贴合兔子帽子,可以实现人脸帽子特效
top = (y0 - 20 - imgComposeSizeH)
# 当人脸太靠近图片上方,通过前一行的计算,有可能为负数,所以当出现这样的情况时,top设置为0
if top <= 0:
top = 0
# 获得调整尺寸后,帽子新的高height_hat_new,新的宽width_hat_new
height_hat_new, width_hat_new = imgComposeSize.shape[0], imgComposeSize.shape[1]
# 将额头上方,对应的帽子区域截取出来
# 注意:通常从大图中抠取小图的方式,比如待截取小图的坐标是[x0,y0,x1,y1],则使用img[y0:y1,x0:x1即可]即可。
small_img_hat = frame[top:top + height_hat_new, x0:x0 + width_hat_new]
# 如需查看,上一行的效果,可将cv2.imwrite前面的#取消,运行后,保存到本目录查看
cv2.imwrite("1.jpg",small_img_hat)
# 将帽子图像,从RGB彩色图像转换为灰度图像
small_img_hat_gray = cv2.cvtColor(imgComposeSize, cv2.COLOR_RGB2GRAY)
# 如需查看,上一行的效果,可将cv2.imwrite前面的#取消,运行后,保存到本目录查看
cv2.imwrite("2.jpg", small_img_hat_gray)
# 阈值化处理,将10<像素<255区间的图像抠出来
# 因为背景为黑色,所以阈值设置10到255,即可将帽子区域提取出来
ret, mask_hat = cv2.threshold(small_img_hat_gray, 10, 255, cv2.THRESH_BINARY)
# 如需查看,上一行的效果,可将cv2.imwrite前面的#取消,运行后,保存到本目录查看
cv2.imwrite("3.jpg", mask_hat)
# 使用取反操作,将帽子的图像从黑色0变为白色255,将白色255变成黑色0
mask_hat_inv = cv2.bitwise_not(mask_hat)
# 如需查看,上一行的效果,可将cv2.imwrite前面的#取消,运行后,保存到本目录查看
cv2.imwrite("4.jpg", mask_hat_inv)
# 使用按位与操作,将抠出的帽子区域和取反后的帽子图像相加
img1_bg = cv2.bitwise_and(small_img_hat, small_img_hat, mask=mask_hat_inv)
# 如需查看,上一行的效果,可将cv2.imwrite前面的#取消,运行后,保存到本目录查看
cv2.imwrite("5.jpg", img1_bg)
# 使用按位与操作,将像素值在[10,255]之间的帽子RGB区域抠取出来
img2_fg = cv2.bitwise_and(imgComposeSize, imgComposeSize, mask=mask_hat)
# 如需查看,上一行的效果,可将cv2.imwrite前面的#取消,运行后,保存到本目录查看
cv2.imwrite("6.jpg", img2_fg)
# 将img1_bg和img2_fg相加,等于戴了帽子的区域图像
dst = cv2.add(img1_bg, img2_fg)
# 如需查看,上一行的效果,可将cv2.imwrite前面的#取消,运行后,保存到本目录查看
cv2.imwrite("7.jpg", dst)
# 将带了帽子的局部区域,贴合到原始图像上
frame[top:top + height_hat_new, x0:x0 + width_hat_new] = dst
# 如需查看,上一行的效果,可将cv2.imwrite前面的#取消,运行后,保存到本目录查看
# cv2.imwrite("8.jpg", img)
# 很多时候,图片的长宽太大,屏幕显示不全
# 为了便于查看图片,可以将图片的大小,缩放到某一尺寸,比如(800,600),即宽800像素,高600像素
img = cv2.resize(frame, (800, 600))
# 显示图片
cv2.imshow("image", img)
# 显示图片停顿的时间,如果是0,则一直显示。如果是100,则显示100ms
cv2.waitKey(10)
# 函数主入口if __name__ == '__main__':
# 新建一个解析器
parser = argparse.ArgumentParser()
# 为解析器添加选项,比如image_path,添加图片地址,可以更换其他图片尝试。(在default后面,添加需要读取的图片路径)
# 注意:不同的图片,宽高大小可能不同,大家可以根据自己的图片比例,调试前面的的cv2.resize中的数值,修改显示窗口的大小。
parser.add_argument('--video_path', default="video.mov", help='path of read vedio')
# 为解析器添加选项,比如hat_path,添加帽子图片地址。(在default后面,添加需要读取的帽子图片路径)
parser.add_argument('--hat_path', default="maozi.png", help='path of hat image')
# 解析选项的参数
opt = parser.parse_args()
# 调用hat_face函数,对人脸进行检测,添加兔子帽子特效
hat_face(opt)
效果如下:
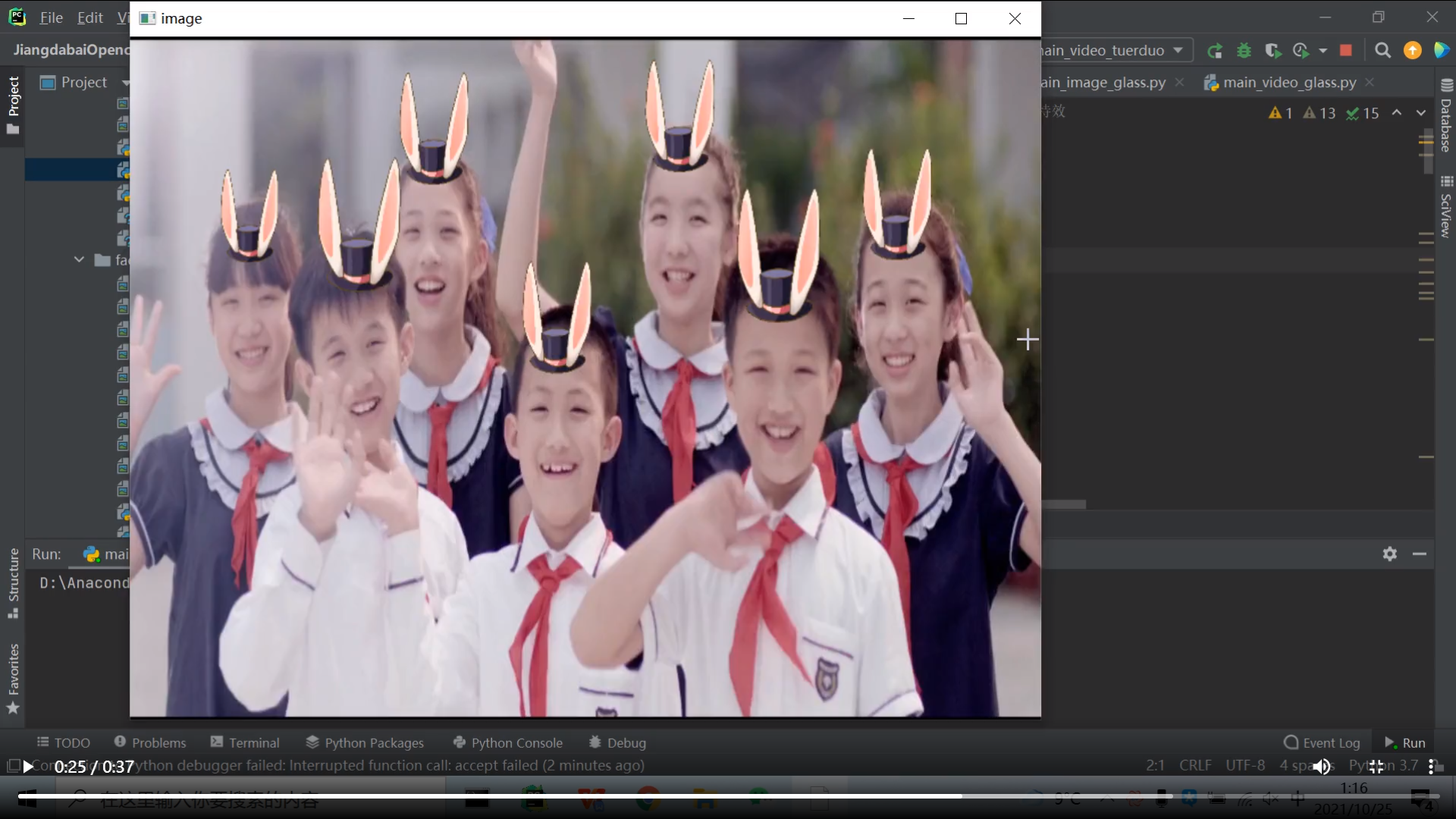
整个兔耳朵帽子特效的流程拆解
(1)读取兔耳朵帽子图片和要加特性的原视频。
(2)检测每帧视频中人脸(这里是每10帧读取一次,这样运行比较快),进行人脸特征点定位。
(3)然后基本步骤和对图像添加兔耳帽子的特效一样,先将帽子的宽度高度变成适合检测到的脸型的大小,然后将兔子帽子贴到额头处即可。
具体通过把额头上对应的帽子区域截取出来、把帽子图片转为灰度图、二值化处理、再取反、把取反后的帽子图片和截取的帽子图片按位与、按位与操作把原来帽子为彩色的区域(这里设为像素值>=10)抠取出来、把前面两个按位与的图片按位相加得到新图,最后把这个新图赋值给对应的原图区域。
(4)对于人脸特效的处理,第一步都是先检测人脸,然后根据人脸调整处理特效图片,再把人脸和特效图片贴合,通过抠图、二值化、取反、按位与、按位加等基础操作完成,最后将原图的对应区域替换成特效图片。
我终于初步体会和理解了opencv的强悍和完善,只需要人脸检测模型的配合,就能做出这么多好看的特效,对抖音快手等app里面特效功能的原理有了初步了解啦,果然是cv领域必备技能啊。
CVPR500+篇论文已打包🚀🚀🚀
关注下方《学姐带你玩AI》回复“CVPR”领取
码字不易,欢迎大家点赞评论收藏!