(学习笔记)数据基建-元数据管理
- 什么是元数据
- 元数据该如何管理
- 工具化
- 规范化
- 数据血缘
什么是元数据
简单来说就是描述数据的数据,更直白来说就是描述表名、表制作者、表字段、表生命周期、表存粗等信息的数据
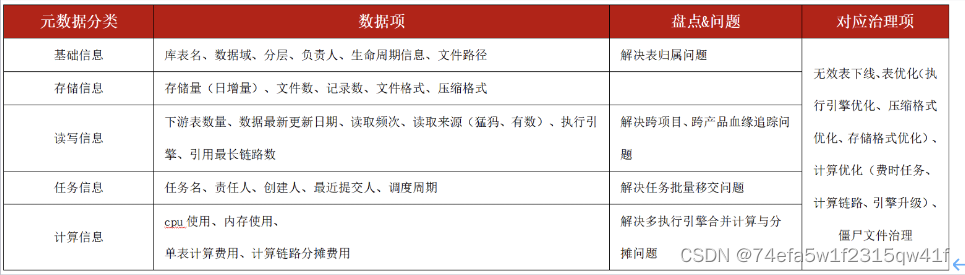

元数据该如何管理
工具化
开源:可通过atlas获取表依赖及信息做二次开发,或者完成可视化界面
平台化:
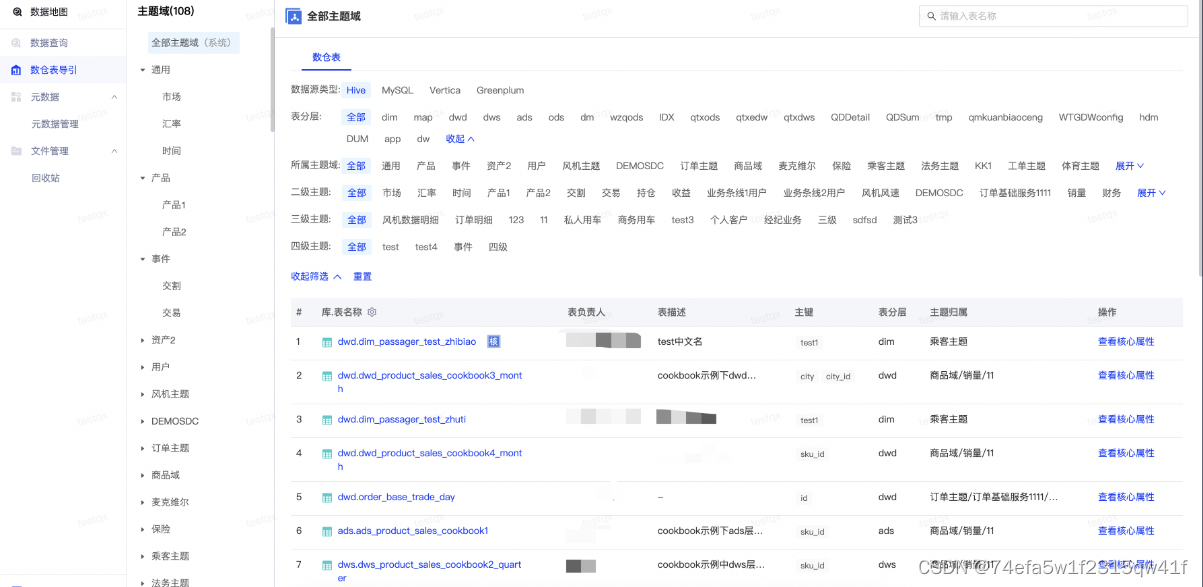
通过数据地图可完成元数据一站式管理
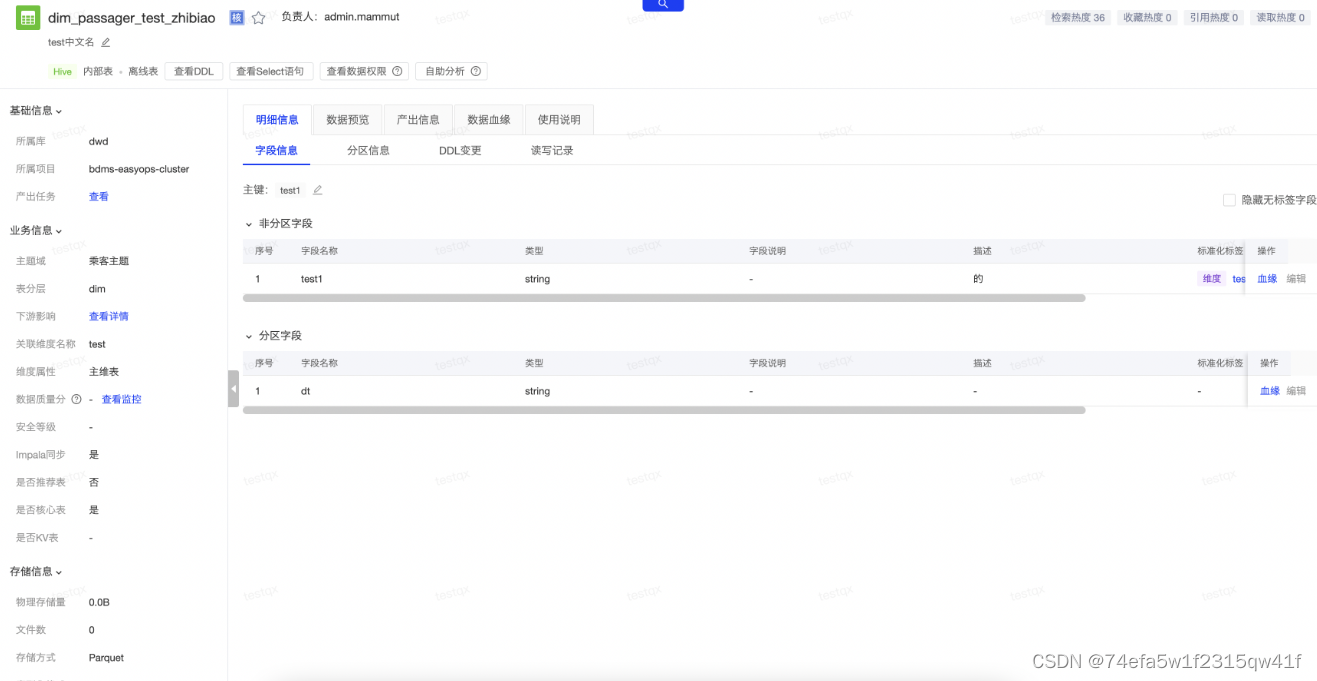
数据资产门户(对主题域、数据表、归纳、提升下游使用效率)
规范化
表/字段
表/字段注释:
字段(文本 文本类型标记清楚内容,枚举值 写清枚举值内容 ,日期 写清楚日期内容yyyy-mm-dd)表(写清具体数据域,颗粒度,用途)
表/字段命名 :符合第二讲的命名体系
字段主键注释:主键,联合主键
字段类型统一:数值类型,文本类型
表/字段血缘:表数据链路模型,字段全链路模型
模型/字段热度:
读取热度:该热度包含两部分,针对离线读取,计算的是昨日该表被离线开发任务和Query任务访问的总次数,针对实时读取,是定时请求获取读取该表的实时任务的数量。
引用热度:该热度包含两部分,针对离线引用,计算的是昨日该表被离线开发任务和Query任务引用数,针对实时引用,是定时请求获取读取该表的实时任务的数量。
收藏热度:该表被收藏的人数
检索热度:被用户查看的搜索并点击的次数
是否核心表
表属性:维度表,事实表
模型使用说明
存储规范:
分区合理化
小文件处理(使用spark3自动小文件合并
key打散减少reduce聚合
where过滤少量的key
map join
参数调优shew join(跳过热点key)
从源头解决小文件合并问题)
存储类型(orc
parquet (spark))
模型评分:
模型质量评分-模型建设内容考量
模型监控评分-根据最近X天规则触发情况给模型数据质量评分
owner:表持有人,表使用者权限
数据血缘
数据血缘功能:清晰知道表/任务上下游,方便排查问题,知道下游哪个模块在使用,提升开发效率及后期管理维护
数据血缘类型:
活跃血缘:指离线开发线上调度产出的血缘,且调度持续生效
静默血缘:指离线开发中,开发模式运行、线上调度已运行过但是已取消调度、线上模式严重逾期执行等。静默血缘在图中用虚线连线表示
数据血缘项目中使用:
数仓中表/字段上下游查询、发送字段变更通知、
探查除数仓外其他场景使用例如报表、olap库等等
如何开发血缘功能
团队合作搭建:与前端配合,数仓出血缘链路模型,前端完成数据填充可视化
使用现成组件/二次开发:openmetadata




![[XYCTF新生赛]-Reverse:ez_rand解析(爆破时间戳,汇编结合反汇编)](https://img-blog.csdnimg.cn/direct/2e9fed157b584297a4b3e815e4a4dcf2.png)