网络原理 HTTP/HTTPS
HTTP,全称为"超文本传输协议"

HTTP 诞⽣与1991年. ⽬前已经发展为最主流使⽤的⼀种应⽤层协议.

实际上,HTTP最新已经发展到 3.0
但是当前行业中主要使用的HTTP版本还是 1.1
应用场景
(1)网页与服务器之间的交互
(2)手机APP 与 服务器 之间的交互
虽然HTTP作用很大,应用很广,但是在实际开发里面,不一定真正直接使用HTTP,更大的概率是使用HTTPS
HTTPS,本质上还是HTTP,但是引入了额外的加密层(此处的s => 安全)
抓包工具
进一步理解HTTP协议的工作流程,以及理解 HTTP协议的报文格式,需要用到 “抓包工具”
所谓抓包,即使能够把网络上传输的HTTP数据获取到,并且显示出来
而抓包工具就是一个代理程序
我们常使用的HTTP抓包工具就是 Fiddler
我们使用fiddler 并且用浏览器打开 搜狗的网页:

这些都是给搜狗服务器发送的请求数据
(浏览器访问一个网站的时候,往往不是只发送一个请求,很可能是发送很多个请求)
我们关注的是蓝色的 ,并且body这一列数据比较多的请求
(蓝色的是服务器返回的HTML数据,黑色的就是返回的普通的数据,同时还会存在其他不同的颜色区分 => css js 图片等)
此时用fiddler抓取请求的时,右边就会有两部分

这个就是请求的详情(右上角)

这个是响应的详情
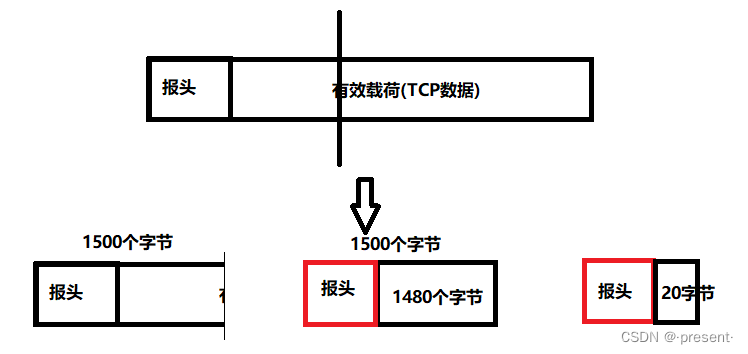
实际上HTTP本来是 文本协议,但是如果需要返回的响应比较大,就可能需要将响应数据压缩再返回
服务器里面就宝贵的硬件资源就是 网络带宽
经过压缩就是用cpu资源,置换贷款资源
对于浏览器来说,解压缩就是 自动完成的
对于fiddler来说,就需要手动解压缩

http请求报文

我们来理解一下请求报文里面涉及的主要内容
首行
首行又包括3部分,分别是
(a)请求的方法
就是用来表示,当前这个请求要做什么,这里是get,就是表示要从服务器获取某个数据
(b)请求的URL
表示请求对方的网址
©版本号
表示http协议的版本
在首行里面,是使用空格来区分三部分的
请求(header)
Host: sogou.com
Connection: keep-alive
sec-ch-ua: "Google Chrome";v="125", "Chromium";v="125", "Not.A/Brand";v="24"
sec-ch-ua-mobile: ?0
sec-ch-ua-platform: "Windows"
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7
Sec-Fetch-Site: none
Sec-Fetch-Mode: navigate
Sec-Fetch-User: ?1
Sec-Fetch-Dest: document
Accept-Encoding: gzip, deflate, br, zstd
Accept-Language: zh-CN,zh;q=0.9
Cookie: SUID=B2F2E6B75019870A0000000065E83505; cuid=AAEhDK3JSgAAAAqHS15V8gEASQU=; SUV=1709716740486165; SMYUV=1712055327421647; ABTEST=3|1716650944|v17; SNUID=7E584C1EAAAFB3E158142029AA686AC3
header里面可以包含若干行数据
此处本质上是一个 "键值对"结构
每一行就是一个键值对,键和值之间是通过 : 分割的
这里的键,都是标准已经规定好了的
空行
最后一个header后面,存在一个空格,就是用来标识 header什么时候结束
正文body
可选的,有些情况下有正文,有些情况下则没有

这里的内容是任意的,可以是 完整的HTML,也可以是完整的css / js,或者json数据 / 文件 / 字体…
响应报文
http响应这里也是有4部分的

首行
首行也分成3部分
(a)HTTP版本
(b)状态码
©状态码描述
状态码和 状态码描述,就是用来表示当前这个请求,是一个成功的现响应还是一个失败的响应
如果失败,具体是什么原因
响应的报头header
Content-Security-Policy: script-src 'report-sample' 'nonce-DZQj_AIZgPzZ8U3IlRD6Rg' 'unsafe-inline' 'strict-dynamic' https: http:;object-src 'none';base-uri 'self';report-uri https://csp.withgoogle.com/csp/clientupdate-aus/1
Cache-Control: no-cache, no-store, max-age=0, must-revalidate
Pragma: no-cache
Expires: Mon, 01 Jan 1990 00:00:00 GMT
Date: Sat, 25 May 2024 16:07:58 GMT
X-Cup-Server-Proof: 3045022053fcd15abefbd905af6aec3d7b1d8e22d568cfaef94045db64c55c6d360911760221009c9723e72e9aac45564bbe973b9a2d5d770605694f39c1d49c849f53c7a6609b:04476c6afa69f5b08dd45f8ea917d5749db193b1f2b53cd712a033d88b4545a0
ETag: W/"3045022053fcd15abefbd905af6aec3d7b1d8e22d568cfaef94045db64c55c6d360911760221009c9723e72e9aac45564bbe973b9a2d5d770605694f39c1d49c849f53c7a6609b:04476c6afa69f5b08dd45f8ea917d5749db193b1f2b53cd712a033d88b4545a0"
Content-Type: application/json; charset=utf-8
X-Daynum: 6354
X-Daystart: 32878
X-Content-Type-Options: nosniff
X-Frame-Options: SAMEORIGIN
X-XSS-Protection: 1; mode=block
Server: GSE
Alt-Svc: h3=":443"; ma=2592000,h3-29=":443"; ma=2592000
Content-Length: 461
这里和请求的报头一样,键都是标准规定好的
空行
响应头的结束标记
正文

这些就是我请求搜狗的网页时,返回的响应正文
http请求
认识URL
平时我们俗称的 “⽹址” 其实就是说的 URL (Uniform Resource Locator 统⼀资源定位符).

协议方案名
协议⽅案名. 常见的有 http 和 https, 也有其他的类型. (例如访问 mysql 时⽤的jdbc:mysql)
登录信息
这是很久之前的方式,就是描述了你登录的时候的信息,现在基本不这么干了,都是搞一个登录页面
服务器地址
描述了要访问的服务器的IP / 域名
服务器端口号
如果这里我们自己不写的话,浏览器就会自己这个URL设置一个默认的端口,这个端口号指的就是访问的服务器的端口号
如果是http协议端口号使用80,如果是https协议,端口号就是443
如果服务器的端口号不是默认的80 / 443,那么我们就必须在url里面显示写出来端口号
但是实际上一般来说,一个网站都会使用默认的端口,大部分网站还是通过80/ 443来进行部署的
带层级的文件路径
指定了要访问服务器的哪些资源
一个服务器,可以提供很多的资源供外界访问
比如,web服务器(网站),就可能包含很多的不同的资源,就可以通过这里的路径区分不同的网页资源了
此时通过Ip 确定主机
结合端口号 确定主机上的程序
结合路径确定程序里的哪个资源
结合这三部分,就能够确定互联网上的唯一网址了
查询字符串
就是浏览器传输给服务器的时候,携带的一些参数
通过参数,将客户端想传给服务器的信息告知过去
查询字符串也是键值对的格式

使用& 来进行多对键值对之间的分割
使用 = 来进行键和值之间的分割
片段标识符
是用来区分页面中不同部分的目录 / 导航
比如我们访问https://v2.cn.vuejs.org/v2/guide/#%E8%B5%B7%E6%AD%A5这个网站的时候,点击不同的导航,实际上还是在同一个页面,但是是不同的内容
关于url encode

实际上,在url里面存在很多的特殊含义的符号,比如: / ? = & 等等
而在query string里面的value部分,一旦也包含这些符号,那不就乱套了吗,就会使得url的解析出现问题
而encode就是针对value进行转移
而也会触发不仅仅是符号,中文汉字也会触发转义
为什么不直接使用汉字?? 实际上,汉字是utf8 / gbk编码
如果某个汉字的恰好某个字节,就和某个特殊符号的ascii码值重复了,此时就可能会导致解析的时候出现问题
那么具体是怎么转码的呢??
实际上就是,遇到需要转码的字符,就显示出这个字符原始的编码的十六进制,在这个基础上,加上%

就比如上面的c++,+的ascii码值的十六进制就是2B,那么转移后就是 %2B
如果是汉字,就把utf8编码结果,每个字节前面,加上 % ,按照16进制的方式来表示
在解析URL的时候,见到带 % 就知道特殊的转码后的是数据了,就可以很容易的和特殊符号区分开来
认识方法

方法就是动作/意图,在http请求首行里,就包含了方法,语义就是,这次请求我要干啥
get方法 和 post方法
get的语义是从服务器获取某个数据
post的语义是往服务器提交某个数据
但是实际上这是最初设计出来的目的
现如今使用这两个方法的时候已经很少区分开了
即get也可能用来提交数据,post也可能用来获取某个数据
但是在习惯上的差别是
get请求报文里面通常不会 携带body,有要传输的传输,就是使用url的query string
详细请访问关于http方法中get和post的区别
而post通常使用的是body传输数据
现实网络上大部分请求都是get
至于post就比get少很多,就是登录 / 上传文件
其他方法
put方法:也是用来给服务器提交数据的,和post非常类似,不一定用来提交文件
delete是用来删除文件的,与get类似,没有body,使用的是query string
构造不同的方法请求
对于get方法
(1)在浏览器地址栏直接输入 url,此时就是get请求
(2)网页html中会有一些特殊的标签,img / a /link 这些标签,会带有一个url属性,页面被 浏览器加载之后,解析到这些标签,就会根据url构造出新的http请求
(3)表单 通过html中特殊的标签form
(4)通过js构造
比如用原生的 ajax api / jquery 的 ajax api / 第三方库 axios ,fetch…
post
(1)表单
(2)js