SQL查询语句的执行过程

连接器
- 连接器会对用户身份和访问权限进行校验。
- 会先连接到数据库上,通过连接器跟客户端建立连接、获取权限、维持和管理连接。在建立连接之后,不会立即执行语句,而是将SQL语句同时传给分析器和缓存。
缓存
- 如果能在缓存中匹配到该语句,则直接将value返回给客户端,执行器的该语句停止运行。如果缓存中没有匹配到该语句,则分析器继续执行。缓存中的数据key/value的形式存储,key是查询的语句,value是查询的结果。注:MySQL 8.0 版本之后直接将查询缓存的整块功能删掉了。
缓存清空
- 查询缓存的实效非常频繁,当你对一张表进行更新时,就会将表上所有的查询缓存清空。对于更新压力大的数据来说,查询缓存的命中率非常低。如果一张表长时间不更新,则推荐使用缓存。
分析器
如果没有命中缓存,就开始真正执行语句了。
- 词法分析、语法分析、语义分析。
优化器
- 优化器在表里面有多个索引的时候,决定使用哪个索引。
- 在一个语句有多表关联的时候,可能会有不同的执行顺序,此时优化器会决定最优的执行顺序。
执行器
- 执行器对表的权限进行校验(增、删、改、查)。
- 在执行查询时,执行器会调用存储引擎的接口来读取表数据,执行器每次调用只会获取表的第一行数据进行匹配。例如(以下SQL语句):判断id值是不是10,不是则跳过,是则保存,直到遍历完所有数据。如果存在索引则从符合条件的结果中进行查询。
- 我们可以在慢SQL语句中通过查看rows_examined字段来确定扫描了多少行数据。在某些场景下,执行器调用一次,在引擎内部扫描了多行因此引擎扫描行数跟 rows_examined 并不是完全相同的。
select * from T where ID=10;SQL更新语句的执行过程
- 用redo log和bin log 实现数据的持久化。具体参考下面 MySQL日志笔记中的内容。

MySQL 日志
Binlog 归档日志
- binlog 是MySQL 的 Server 层实现的,所有引擎都可以使用。
- 属于逻辑日志,记录的是这个语句的原始逻辑。binlog日志是持续追加写入的,不存在被覆盖一说。
写入原理
- 实现原理是在事务执行过程中,先把日志写到 binlog cache,事务提交的时候,再把 binlog cache 写到 binlog 文件中。
- 系统给 binlog cache 分配了一片内存,每个线程一个,参数 binlog_cache_size 用于控制单个线程内 binlog cache 所占内存的大小。如果超过了这个参数规定的大小,就要暂存到磁盘。
- 事务提交的时候,执行器把 binlog cache 里的完整事务写入到 binlog 中,并清空 binlog cache。

写入方式
write 和 fsync 的时机,是由参数 sync_binlog 控制的:
- sync_binlog=0 的时候,表示每次提交事务都只 write,不 fsync;
- sync_binlog=1 的时候,表示每次提交事务都会执行 fsync;
- sync_binlog=N(N>1) 的时候,表示每次提交事务都 write,但累积 N 个事务后才 fsync。
优点
- 因此,在出现 IO 瓶颈的场景里,将 sync_binlog 设置成一个比较大的值,可以提升性能。在实际的业务场景中,考虑到丢失日志量的可控性,一般不建议将这个参数设成 0,比较常见的是将其设置为 100~1000 中的某个数值。
缺点
- 但是,将 sync_binlog 设置为 N,对应的风险是:如果主机发生异常重启,会丢失最近 N 个事务的 binlog 日志。
三种同步方式
Statement
- 记录的是执行的SQL语句,会把整个字段都就录上。假设 A表有5个字段a b c d e ,我现在执行 upate A set a=1 where b=2 , 而binlog 记录的是 update set a=1,b,c ,d,e where b=2 。会把整个表的字段数据都记录上。
UPDATE A SET a=1 WHERE b=2
<!-- statment 记录 -->
UPDATE A SET a=1, b=?, c=?, d=?, e=? WHERE b=2
<!-- delete示例 -->
delete from table where id in(1,2,3,4,5)缺陷
- 当主备使用的索引不一致时,最终导致执行删除时删除的数据不一致。因为在主/备库上同一张表内会出现使用的字段索引不一样,例如:主库用a字段做索引,备库用b字段做索引。
Row
- 记录每一行记录的每个字段变化前后的值,记录的更为明细,只会修改对应的值。
UPDATE A SET a=1 WHERE b=2
<!-- statment 记录 -->
UPDATE A SET a=1 WHERE b=2
<!-- delete示例 -->
delete from table where id in(1)
delete from table where id in(2)
delete from table where id in(3)
Mixed
- mixed 格式是指MySQL在复制过程中自动选择使用row或statement。MySQL 会判断所执行的 SQL 语句是否可能引起主备不一致,如果有可能,则使用 "row" 格式,否则使用 "statement" 格式。
如何提升 binlog 组提交的效果
可以通过设置 binlog_group_commit_sync_delay 和 binlog_group_commit_sync_no_delay_count 来实现。
- binlog_group_commit_sync_delay 参数,表示延迟多少微秒后才调用fsync。
- binlog_group_commit_sync_no_delay_count 参数,表示累积多少次以后才调用 fsync。
WAL机制的好处
- redo log 和 binlog 都是顺序写,磁盘的顺序写比随机写速度要快。
- 组提交机制,可以大幅度降低磁盘的 IOPS 消耗。
Redolog 重做日志
- redo log 是 InnoDB 引擎独有的日志。
- 属于物理日志,固定大小,数据循环写入,会被覆盖。
- redo log 采用了WAL技术(Write-Ahead Logging)既先写日志,再写磁盘。MySQL每执行一条DML语句,先将记录写入内存分配的redo log buffer中,后续再一次性将redo log buffer中的内容写到redo log文件中,而被修改的数据页由checkpoint机制保证最终落盘。
为什么MySQL要使用Redo log而不选择直接刷盘?
- 如果每次修改都直接刷新到硬盘上,会导致大量的随机I/O操作从而影响系统性能。
- 而redo log可以将修改操作先写入内存中的日志缓冲区,再批量刷新到磁盘,减少磁盘I/O操作,提高性能。同时,redo log还能保证事务持久性,即使系统崩溃或重启,也能保证数据的一致性。
刷盘策略
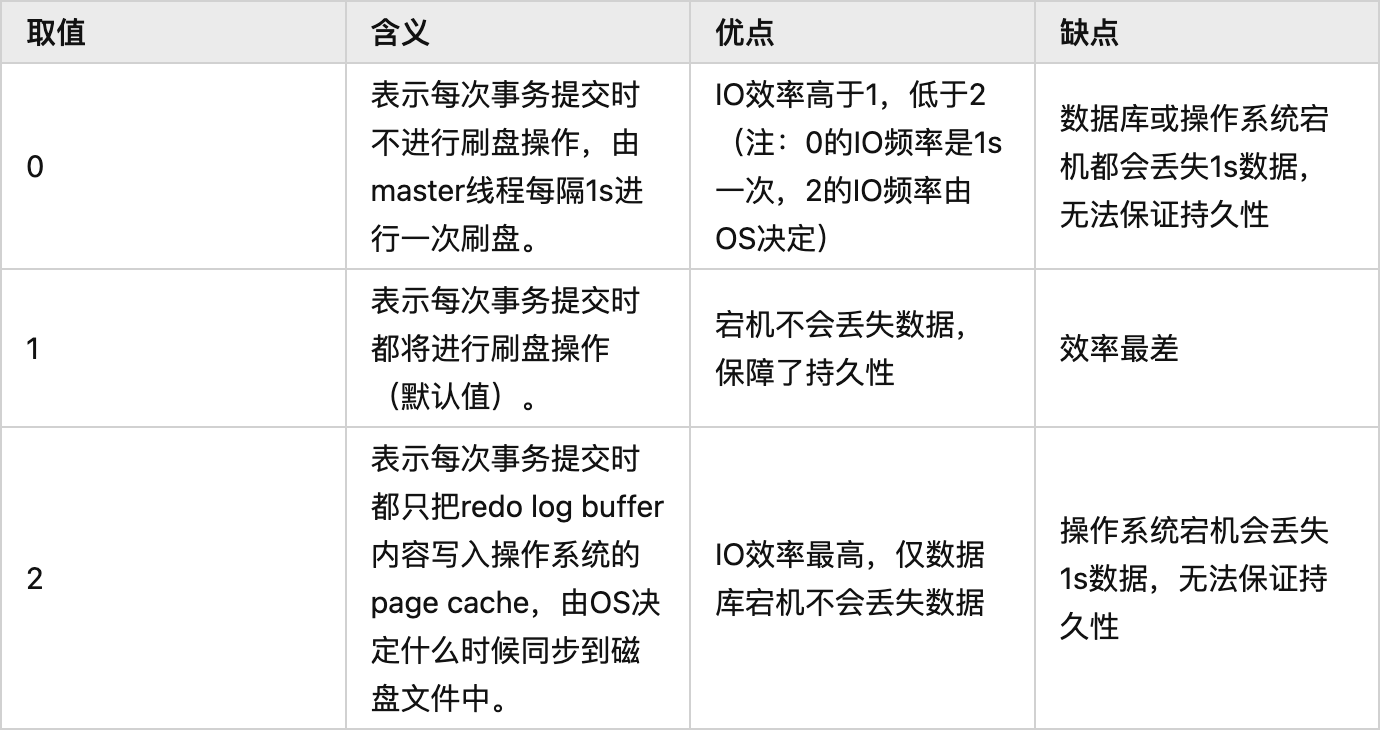
- InnoDB 存储引擎为 redo log 的刷盘策略提供了三种策略,使用innodb_flush_log_at_trx_commit 参数配置,有以下三种取值:
redolog 的大小
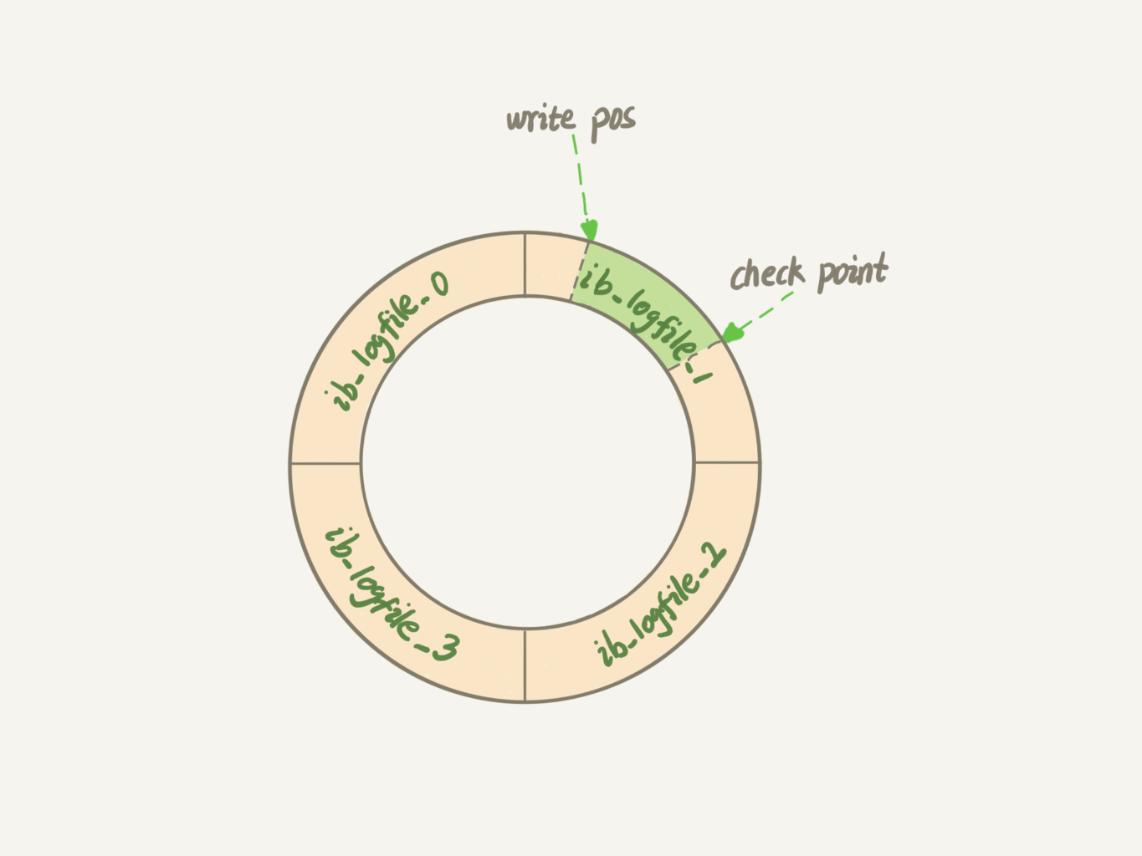
- 首先InnoDB 的 redo log 是固定大小的,如果写满了则要擦除最开始记录的数据。可通过innodb_log_file_isze配置修改大小。
- write pos和check point之间的部分可以用来写入新的数据,当write pos追上check point时,此时无法写入新的日志。check point前的记录会被写入磁盘并从日志中擦除,为新的日志腾出空间。
redolog的两个重要属性
- write pos是当前记录的位置,一边写一边后移。
- checkpoint是当前要擦除的位置,也是往后推移。
为什么会有binlog、redolog两份日志?
- 因为最开始 MySQL 里并没有 InnoDB 引擎。MySQL 自带的引擎是 MyISAM,但是 MyISAM 没有 crash-safe 的能力,Bin log 日志只能用于归档。而 InnoDB 是另一个公司以插件形式引入 MySQL 的,既然只依靠 binlog 是没有 crash-safe 能力的,所以 InnoDB 使用另外一套日志系统——也就是 redo log 来实现 crash-safe 能力。
crash-safe的概念
- crash-safe 指在系统突然宕机或崩溃的情况下,对数据的安全性进行保护。具体来说,MySQL的某些存储引擎(如InnoDB)使用了一种叫做Write-Ahead Logging(预写式日志)的技术,确保在系统宕机或异常终止时,数据的一致性和完整性。
binlog为什么没有crash_safe的能力
- 写入方式的问题,binlog是追加写,crash时不能判定binlog中哪些内容是已经写入到磁盘,哪些还没被写入。而redolog是循环写,从check point到write pos间的内容都是未写入到磁盘的。
2PC保证redolog和binlog 的数据一致性
- 在Redo log写入完成后,会进入prepare阶段。2PC 由prepare阶段、写Binlog、commit三个步骤来完成。
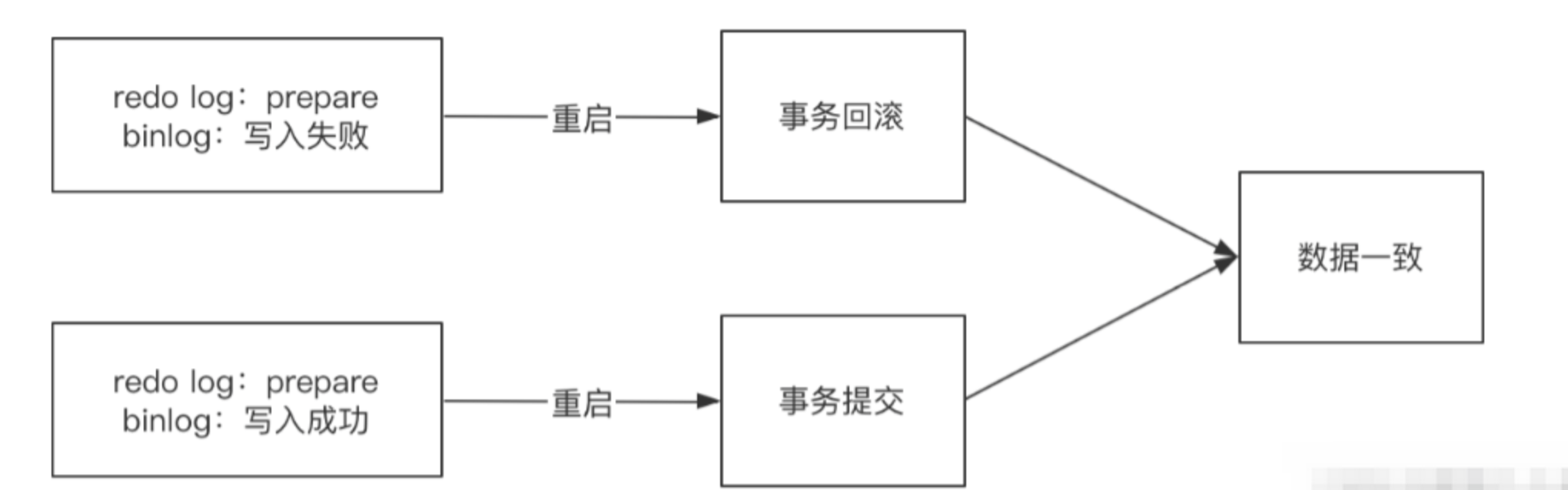
- 如果是在写入Binlog之前数据库崩溃,当数据库重启时会检查Redolog和Binlog日志,事务处于prepase且Bin log中没有写入记录,会进行回滚。
- 如果是在commit之前数据库崩溃,当数据库重启后会检查Redolog和Binlog日志,如果事务满足prepare阶段且Bin log中存在记录,那么会自动将事务提交。
事务日志什么时候写入redolog和binlog中?
- 事务开始时:当一个事务开始执行时,MySQL会将一条记录写入Redolog/Binlog,记录该事务的ID和其他相关信息。这条记录被称为事务的开始记录。
- 事务提交时:在事务提交之前,MySQL会将该事务的所有修改操作记录到Redolog/Binlog中。这些记录被称为事务的变更记录。
redolog和Binlog怎么关联起来?
- redolog和binlog的对应关系是通过对XID(事务ID)进行关联来实现的。在MySQL中,每个事务都有一个唯一的ID,redolog和binlog中都记录了该事务的ID。
- 通过将redolog和binlog中的事务ID进行关联,MySQL可以确定哪些redolog和binlog记录属于同一个事务,从而保证数据的一致性和可靠性。
MySQL 怎么知道 binlog 是完整的?
- statement 格式的 binlog,最后会有 COMMIT。
- row 格式的 binlog,最后会有一个 XID event。
undolog 回滚日志
- 可以回滚行记录到某个特定版本,用来保证事务的原子性、一致性。
日志什么时候删除?
- 当进行insert操作的时候,产生的undolog只在事务回滚的时候需要,并且在事务提交之后可以被立刻丢弃。
- 当进行update和delete操作的时候,产生的undolog不仅仅在事务回滚的时候需要,在快照读的时候也需要,所以不能随便删除,只有在快照读或事务回滚不涉及该日志时,对应的日志才会被purge线程统一清除。
原理
- 当进行insert时会直接在undolog中写入一条记录。回滚时会删除插入的数据行。
- 当进行update/delete时,会先把该行数据拷贝到undolog中,作为旧记录。拷贝完毕后便修改该行数据,并且修改隐藏字段的事务id为当前事务2的id,回滚指针指向拷贝到undolog的副本记录中。
- 回滚时直接根据回滚指针找到数据进行数据恢复。

双"1"配置
- 通常我们说 MySQL 的“双 1”配置,指的就是 sync_binlog 和 innodb_flush_log_at_trx_commit 都设置成 1。也就是说,一个事务完整提交前,需要等待两次刷盘,一次是 redo log(prepare 阶段),一次是 binlog。