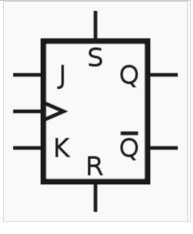
前言
我们在上一卷中了解了顺序读写的函数,现在就让我们从随机读写的函数开始吧。
什么是随机读写?
就是想在哪个位置读或写都行,比较自由。文件打开时光标默认在起始位置。想从后面的某个部分读或写,就得让文件指针来到那个位置:
fseek函数
这个函数就能根据文件指针的位置和偏移量来定位文件指针(文件内容的光标,不是指FILE*类型的文件指针)。

这个函数有3个参数,第一个是文件指针,第二个是偏移量,第三个指的是起始位置。毕竟,要给出从哪开始,偏移量是多少,才能随机读写。

注意,offsetof可以为负数。
最后一个参数origin有三种选项:

第一个是文件的起始位置;第二个是文件指针(光标)当前的位置;第三个是文件的末尾。
请看下面的代码:

可以看到我们用fgetc两次读文件时,第一次结果是a,第二次是b,这说明什么?说明第二次读的时候我们的光标向后一移了一个字符。
光标是一个个移动的,如果我们现在想直接读到e,就不能使用这种方式。
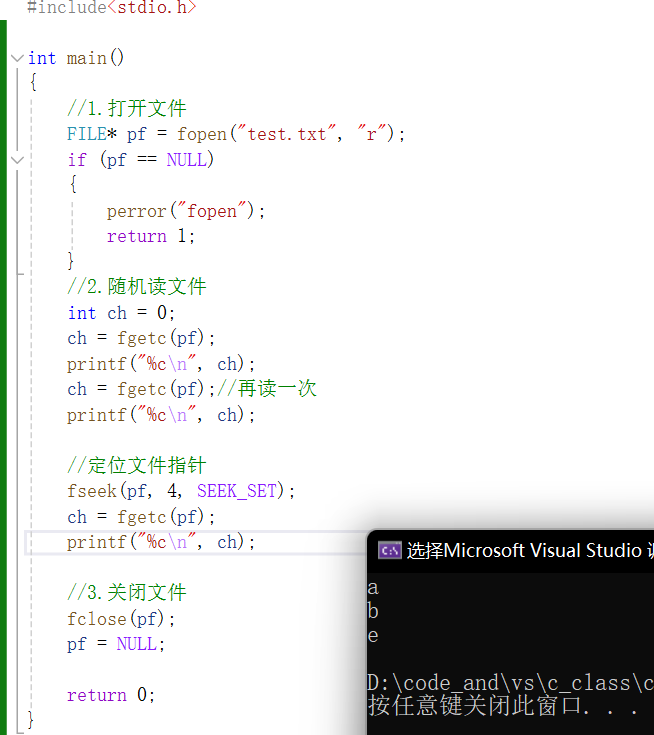
使用fseek定位到起始位置偏移量为4的位置也就是指向e的位置,再读,就得到了e。
或者我们最后一个参数使用SEEK_END:

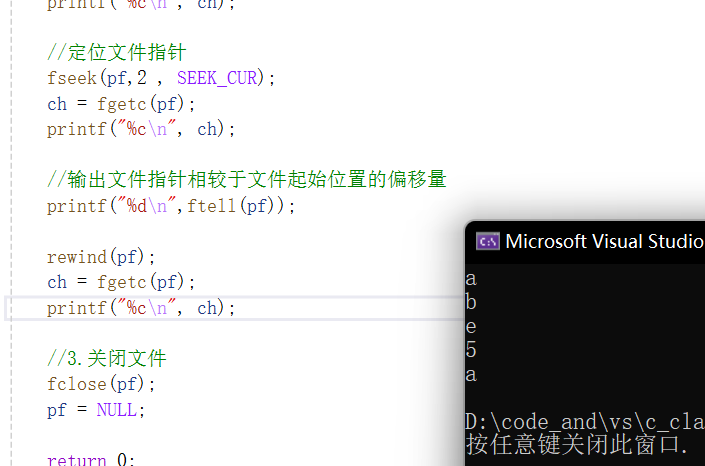
或者SEEK_CUR:

ftell函数
返回文件指针相较于起始位置的偏移量:
当我们读文件不知道读到哪了,偏移量是多少,就可以使用它。

我们分析一下偏移量为5:

e读完后其实光标会移动到e的后一位也就是指向f。所以读完e算偏移量,就是5。
rewind函数
让文件指针的位置回到文件的起始位置。
我们使用完再读就是a:
文件结束的判定
被误解的函数 feof

EOF——end of file 文件结束标志
所以很多人以为feof是用来判断文件是否结束的。
实际上,它的作用是当文件读取结束的时候,判断读取结束的原因是否是遇到文件结尾。
在读取文件的过程中可能读取结束,结束的原因可能是确实遇到了文件末尾(读完了),也可能遇到了错误。那么为了判断,我们就可以使用feof。
feof负责判断是否是因为遇到文件末尾而结束的。而不是判断是否读取结束。
那么怎么判断是否读取结束呢?对于文本文件而言,用fgetc正常读到字符返回的是读到字符的ASCII码值,失败或读取结束会返回EOF;用fgets判断的话(一行一行读),读取失败或者读取结束返回NULL。 所以用fgetc去读判断是否为EOF,用fgets去读判断返回值是否为NULL,就能知道是否读取结束;
而如果是以二进制的形式去读,返回值小于实际要读的个数就是读取结束的标志。(讲fread时提到过:参数count是一次读几个,如果返回值比num小,说明读取结束)
文本文件判定读取结束原因例子:

二进制文件判定读取结束原因的例子:

注意:没有读到文件结尾时,没有任何状态值被设置,feof的返回值会是0;如果读到文件末尾,返回非零值(一般为1)。
那ferror呢?没有错误时返回0,有错误时返回非零值(1)。那么什么时候会错呢?比如要写文件却以"r"打开文件,要读文件却以"w"形式打开,就会ferror返回1(但是这种情况perror打印不了正确的错误信息,可以自己编写一个错误信息)。

可以看到返回值部分的描述和feof是非常相似的。
文件缓冲区
程序数据区和硬盘之间的输入、输出并不是直接进行的,而是在中间还有一个文件缓冲区:
ANSIC标准采用“缓冲文件系统”处理数据⽂件,所谓缓冲文件系统是指系统自动地在内存中为程序中每⼀个正在使用的文件开辟⼀块“文件缓冲区”。
从内存向磁盘输出数据会先送到内存中的缓冲区,装满缓冲区后才⼀起送到磁盘上。如果从磁盘向计算机读入数据,则从磁盘文件中读取数据输入到内存缓冲区(充满缓冲区),然后再从缓冲区逐个地将数据送到程序数据区(程序变量等)。缓冲区的大小是根据C编译系统决定的。
为什么要有文件缓冲区?
这就像你去找老师提问,一遇到一个问题就跑去问老师,一分钟去一次,老师时间就会被你占用,只能给你一个人解答;但如果你攒够多个问题再一起提问,老师就能腾出时间做别的事。
所以我们也不是有一个数据就写到硬盘上的,写数据不是直接就能写上去的,还要调用操作系统的接口,如果我们一有数据就写,总是打断操作系统;现在有了缓冲区,充满了再写入硬盘,操作系统就能做其他事,提高了效率。
观察缓冲区例子:

注意,第二次Sleep是因为文件关闭时也会刷新缓冲区,为了保证缓冲区的刷新不是因为关闭文件,延缓关闭文件。

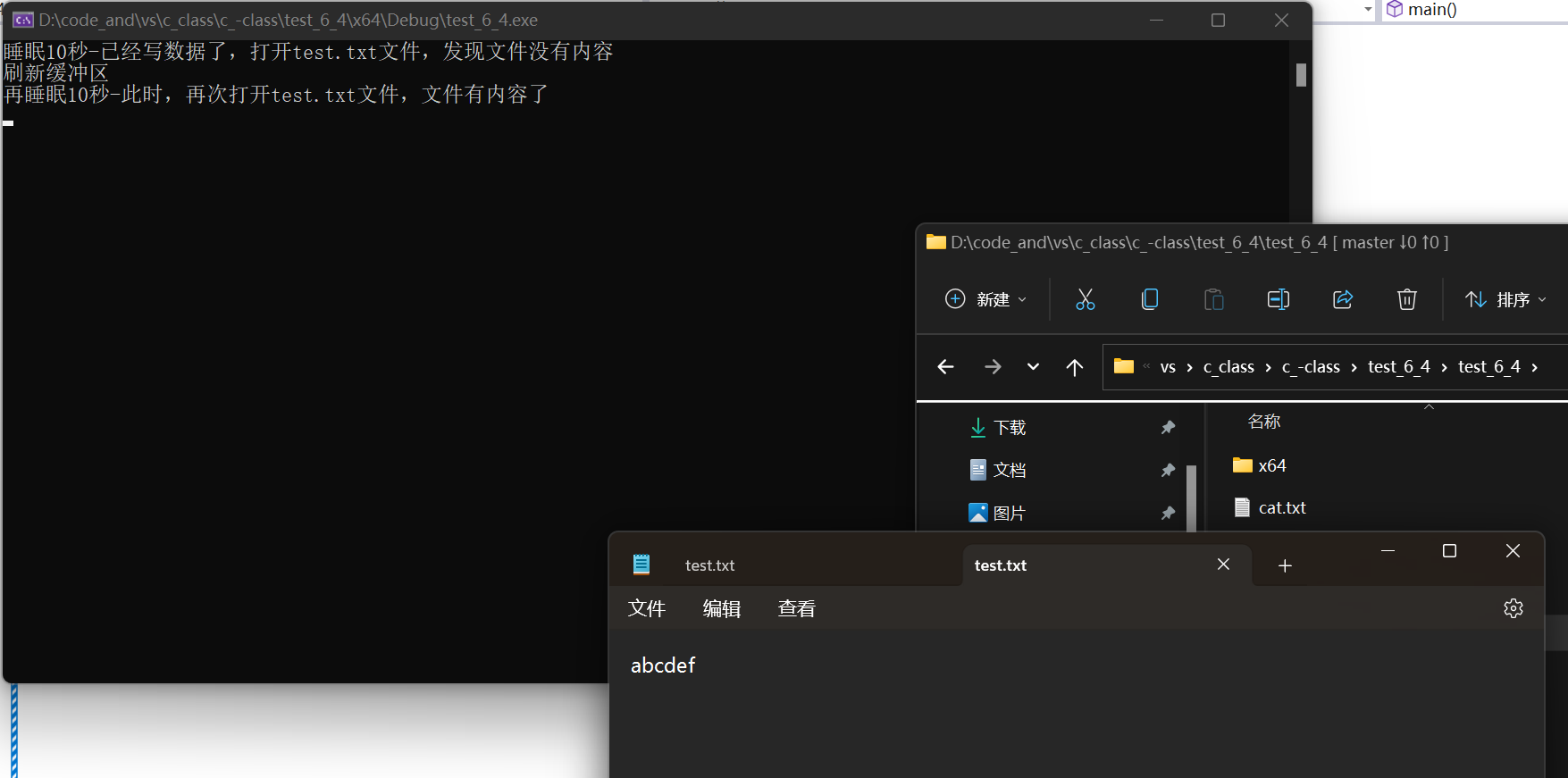
所以我们得出一个结论:
因为有缓冲区的存在,C语言在操作文件时,需要刷新缓冲区或在文件操作结束时关闭文件,如果不这样做,可能导致读写文件的问题。
到此,文件操作的内容就结束了,祝阅读愉快^_^