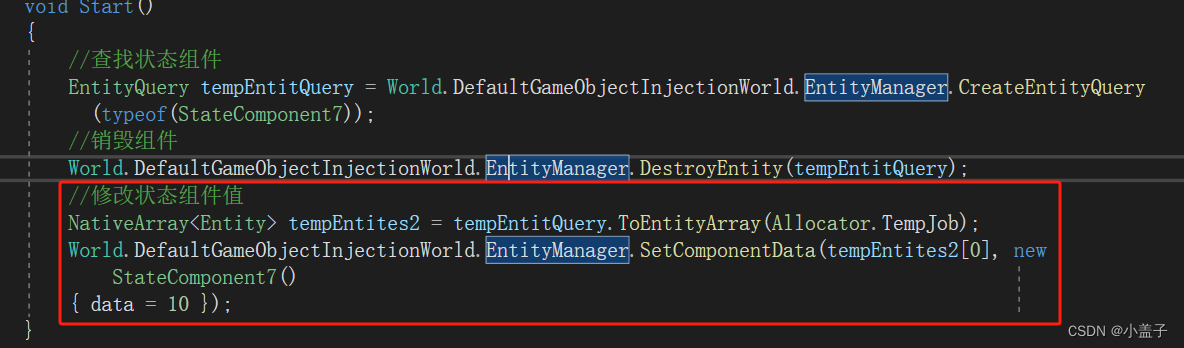
大数据产业创新服务媒体
——聚焦数据 · 改变商业
2024年6月5日,仅仅用了一上午的功夫,智谱就连发了三个产品,分别是智谱清言、GLM4-9B、智谱MaaS平台。
在这次的发布会与智谱在2024年1月16日开的发布会不太一样,后者更注重技术分享。而本次发布会,与其说是发布产品和技术,更不如说是智谱在展示他们通过对大模型技术的应用,展示了他们在理解“大模型落地”这个关键词上的态度和思路。
在当下的存量市场,智谱越来越明白一个道理,企业没有办法长期依靠光环、补贴、融资这些事物。唯一能帮助企业实现增长,是企业的战略眼光和发展方向。
智谱清言,表面是“APP”实际是“工作台”
智谱清言是一个智能体助手,客户可以与上面的智能体对话,智能体则会执行用户的命令。乍一看可能看不出什么,但是智谱清言属于是一种比较独特的APP。
首先,用户并非是点击某智能体窗口再进行对话,而是直接在对话框里“@”,让整个对话更加便捷。其次,智谱清言各种智能体提供的功能更偏向于实际业务,比如绘制思维导图、搜索关键词分析等等。最后,智谱清言可以@多个智能体,并让这些智能体进行协作,以“群聊”的方式执行用户的命令。
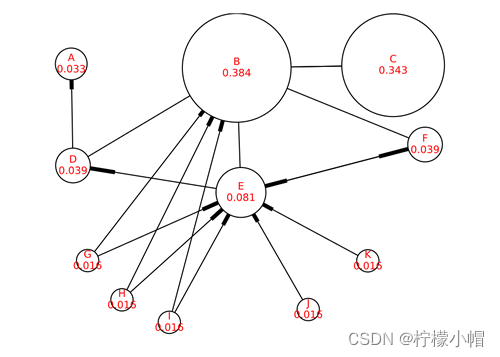
下方这张图,是智谱清言搜索关键词“数据猿”,根据数据猿的业务分析,最后由智谱清言生成的数据猿业务思维导图。
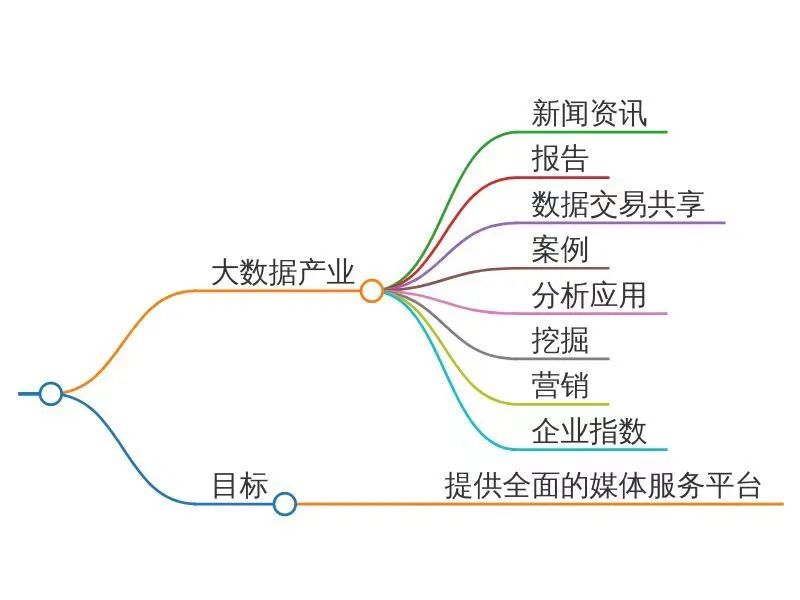
图:数据猿的业务分析
从结果来看,智谱清言对数据猿的分析较为准确,同时还能绘制出非常清晰的思维导图。证明智谱清言的确具备了替代一些常见办公软件的能力。
以往来看,智能体偏向于情感陪伴和疑问解答,却鲜有触及办公软件这条赛道的。这是一个细分赛道,智谱很清楚一件事,和过去的大模型APP相比,清言肯定是极其独特的。
正是这种独特给了智谱清言一个完全不同的发展方向:虽然是C端产品,但是会向B端销售,类似于企业微信的获客逻辑。
设想一个场景,在一个营销活动中,团队所有任务,比如创意设计、预览展示、活动导图等等都可以用智谱清言来完成。至此,智谱清言就不再是一个APP,更像是一个工作台。
智谱在考虑用户体验
2023年3月14日的时候,智谱曾推出过GLM的量化版本——GLM3--6B。这个版本的参数量仅为62亿,使得用户可以在消费级的显卡上进行本地部署。一年过后的今天,智谱则推出了GLM-4的FP8量化版本,GLM-4-9B。
在预训练方面,智谱引入了大语言模型进入数据筛选流程,最终获得了 10T 高质量多语言数据,数据量是 GLM-3-6B 模型的 3 倍以上。相较于第三代模型,训练效率提高了 3.5 倍。
相较于2023年流行的INT8,FP8量化方法是现阶段更为前沿的量化方式。通过增加尾数位数,FP8在表示范围内既有较高的精度(E4M3),又有较宽的动态范围(E5M2),这使得FP8在处理具有不同数值分布的数据时具有优势。
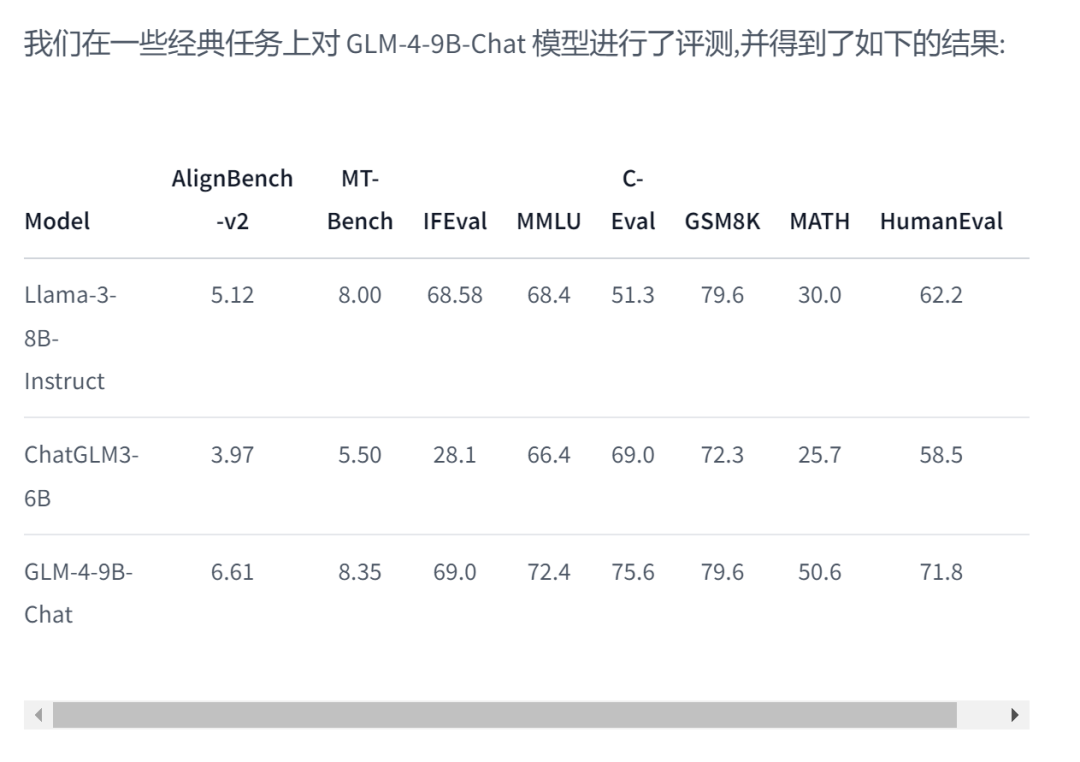
图:GLM4-9B的性能
不过和市面上大多数大模型不同,GLM-4-9B是没有当下最火的MoE架构的。智谱的观点是,MoE会消耗过多显存来替代算力,但是消费级显卡的显存是比较有限的,因此这种取舍是“划不来”的。
而在有限显存的情况下,6B模型性能有限,不满足当下需求。因此,智谱最终将量化后的模型规模提升至9B,并将预训练计算量增加了5倍。
量化是端侧模型部署中常用的一种技术,通过减少数据表示的位数来提高计算吞吐和降低存储需求,从而提升模型在端侧设备上的运行效率。也不难看出,智谱在量化的过程中,他们在寻找显存和算力之间的平衡点,以确保模型可以部署在绝大多数设备的本地。
此前推出量化模型的时候,智谱可能并未想过落地后的事宜,更多的是技术分享。而这次的GLM-4-9B,智谱在思考的并非技术,而是用户体验,即GLM-4-9B在部署到消费级设备的本地后,用户使用起来是否会出现等待时间过长、回答不理想等等问题。
正是这种平衡,给了GLM-4-9B在端侧部署上更多的可能性。鉴于这个量化模型是开源的,智谱应该是用这个模型对市场进行测试,看看各类型端侧用户的实际使用状况是怎样的,再依据反馈,为今后量化谋求一个新的平衡点,直至发布端侧大模型产品。
MaaS平台
智谱在当天还发布了一个平台叫做MaaS,也就是智谱的大模型开放平台。这个平台上可以使用GLM-4-Flash、GLM-4-Air,以及GLM-4。价格也是比较美丽的,比如说普通版的GLM-4-Air,每100万个tokens只需要花1块钱。
在各大厂商都在大打价格战的今天,价格反而失去了其意义,因为各种大模型的价格差距没办法拉开。所以,如果大模型厂商想要不依靠补贴、融资而生存下去,如何获客永远是头号难题。
智谱MaaS平台的获客方式属于是回归初心,他们用的是软件公司最原始的办法:拉长战线拼“一站式”。
所谓拉长战线,就是指平台提供多种套餐给客户选择。预算少、需求低,可以购买GLM-4-Flash或者是GLM-4-Air,预算高、需求大,可以购买GLM-4-Air极速版和LM-4-0520。
此外,大模型在落地过程中,最接近实际商业使用效果的步骤就是微调。MaaS可以允许客户以一个很方便快捷的方式进行“一站式”微调:1.按照模板收集数据,导入数据集以训练模型;2.使用平台的微调工具,对模型进行微调;3.将训练好的模型部署到私有云服务器。
也就是说,这个平台还包含了Toolkit属性,这就让一些开发能力较弱的开发者,依然能够完美驾驭大模型。
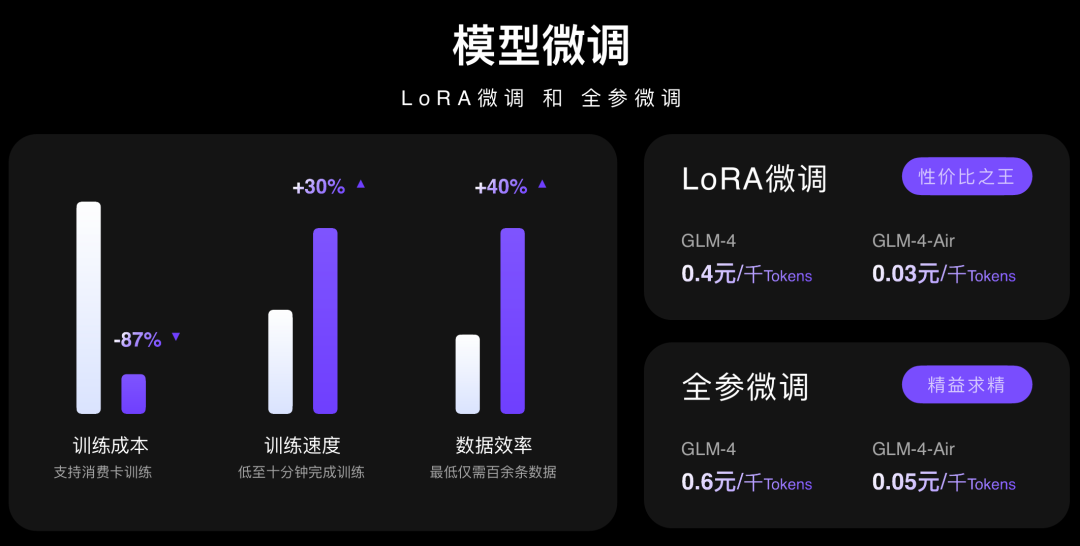
图:智谱微调的性能和价格
MaaS是智谱对大模型在B端落地的认知,他们认为,To B生意的收入来源在于能为客户提供多少价值。所以智谱选择拉长战线,把模型以性能、生成速度进行划分,推翻名为”价格战“的文字游戏,把选择的权力价格客户。
同时MaaS的一站式也为智谱增加了更多获客的可能性。
文:火焰翼人 / 数据猿
责编:凝视深空 / 数据猿