说明
很久没有关注这方面的问题了,平时大部分时候还是做批量操作 。在这种情况下(CPU密集),异步、协程这些意义就不大了,甚至可能进一步拖慢处理时间。
但是在IO这一块的零碎处理是比较重要的,可以更快,且更省资源。很早的时候,曾经在执行规则引擎之前要分布的从mysql取数,结果处理时间特别慢;后来改用了asyncio和aiomysql,速度大幅提升,这给我了很深的印象:什么资源都没加,速度就是快了。
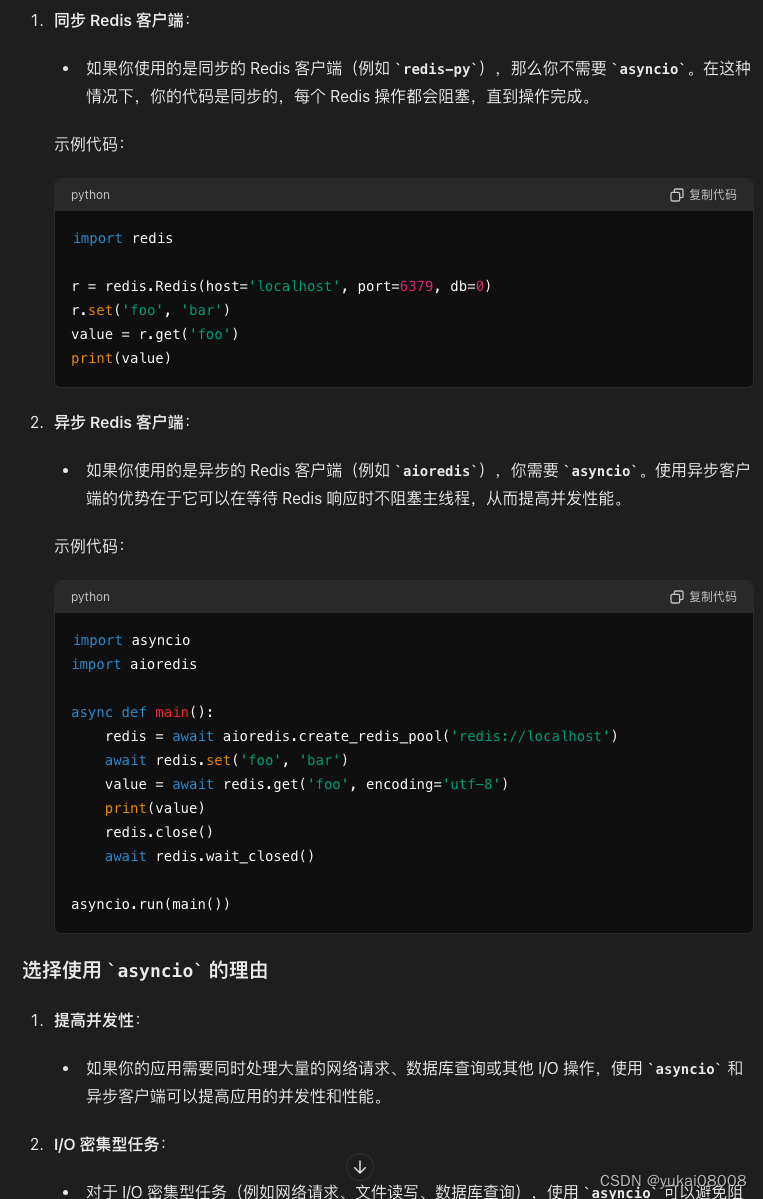
后来我主要还是集中在批次处理数据下,每次都是万条的密集操作,这时候主要就用数据库本身的功能;而面对大量零散需求的时候用了redis,这样看起来也不存在瓶颈。
事实上,主要是由于一些零碎的请求实在是太少了,完全没有达到redis-py处理的上线,所以我也忽略了,其实在应对大量请求上,还是可以使用aioredis的。
内容
1 基本概念
进程、线程与协程。chatgpt说的又快又好
进程、线程与协程是三种常见的计算机并发执行模型。它们各自有不同的特点和应用场景。下面对它们进行详细解释:
进程(Process)
定义
进程是操作系统分配资源的基本单位,每个进程都有独立的内存空间、数据段、代码段和系统资源。
特点
隔离性:进程之间是相互独立的,一个进程崩溃不会影响其他进程。
开销大:由于进程间资源独立,创建和切换进程的开销较大。
并行性:在多核系统上,不同进程可以真正并行运行。
应用场景
适用于需要高隔离性和稳定性的场景,如不同服务模块的隔离运行。
使用多进程来充分利用多核 CPU 的性能。
import multiprocessing
def worker(num):
print(f'Worker: {num}')
if __name__ == '__main__':
for i in range(5):
p = multiprocessing.Process(target=worker, args=(i,))
p.start()
p.join()
线程(Thread)
定义
线程是进程的子单元,是 CPU 调度和执行的基本单位。一个进程可以包含多个线程,这些线程共享进程的内存空间和系统资源。
特点
共享资源:同一进程内的线程共享内存和文件等资源,线程之间通信和切换的开销较小。
并发执行:在单核 CPU 上,线程通过时间片轮转并发执行;在多核 CPU 上,线程可以并行执行。
同步问题:由于线程共享资源,需要考虑线程同步和互斥问题,避免竞态条件。
应用场景
适用于需要高效并发处理和共享资源的场景,如 Web 服务器处理并发请求、后台任务调度等。
import threading
def worker(num):
print(f'Worker: {num}')
threads = []
for i in range(5):
t = threading.Thread(target=worker, args=(i,))
threads.append(t)
t.start()
for t in threads:
t.join()
协程(Coroutine)
定义
协程是比线程更加轻量级的执行单元。协程在用户态进行调度和切换,不依赖于操作系统提供的线程调度机制。
特点
轻量级:协程创建和切换的开销极小,因为它们不需要进行系统调用。
协作式调度:协程通过显式的让出控制权来实现调度,不同于线程的抢占式调度。即,协程在执行过程中需要显式地调用挂起操作,才能切换到其他协程。
不适合多核并行:由于协程是单线程运行的,无法利用多核 CPU 的并行能力。
应用场景
适用于大量 I/O 密集型任务,如网络编程、异步 I/O 操作等。
使用协程可以避免线程同步问题,简化并发编程模型。
比较与总结
进程:独立性强,隔离性好,但创建和切换开销大,适合多核并行。
线程:共享资源,创建和切换开销小,但需要解决同步问题,适合高并发和资源共享的场景。
协程:轻量级,无需系统调用,调度开销极小,但无法利用多核并行,适合大量 I/O 密集型任务。
import asyncio
async def worker(num):
print(f'Worker: {num}')
await asyncio.sleep(1)
async def main():
tasks = [worker(i) for i in range(5)]
await asyncio.gather(*tasks)
asyncio.run(main())
关于进程,我的理解和体会。进程就是CPU的核,就是一个jupyter服务,就是一个容器,虽然这么说不严密,但是挺容易记的。在这个级别并行的方法太多了,multiprocessing没啥大用。
- 1 服务级别,采用nginx发挥多核作用。
- 2 单服务,tornado之类的可以直接发挥多核
- 3 程序级,pandas的apply可以发挥多核作用(对于可向量化的操作)
还有就是采用GPU那种根本性的并行器件。
关于线程,刚好有个实际的体会。我有一个tornado,里面允许临时给一个参数字典加参数,然后我就发现调用过程失灵时不灵。原因是我启动了多核,这个参数字典其实给了某一个线程,在python里,线程也就是进程。然后进程间是隔离的,所以对于很多进程,根本没有参数。
所以从整体性能上,在核/线程基本我还算利用的可以,底下的IO密集并发还做的很不够。现在虽然有了celery,不过那种是偏异步的利用。
最后,协程在IO并发上的性价比应该是远高于线程的,所以这点我看到java的多线程就感觉太浪费了。
2 简单梳理
我把chatpt给我的一些有用的示例记一下,其实也就是这些写的比价有用,才快速攒这篇文章。
首先,我用了大量的微服务,特别是很多的agent: MongoAgent, RedisAgent, MysqlAgent… 这些服务都采用了同步的包,因为我原来处理的核心就是大批量数据:在CPU已经密集的情况下,IO并发也就没有意义了。
考虑到现在越来越多的轻处理(sniffer),所以突然间感觉异步就变得越来越重要了。
2.1 在服务端异步
这个可以参考这篇文章
用sleep模拟了耗时操作,实测是蛮好用的。tornado本身也是基于asyncio做的。
import time
from concurrent.futures.thread import ThreadPoolExecutor
from tornado import web, ioloop
from tornado.concurrent import run_on_executor
class SyncToAsyncThreadHandler(web.RequestHandler):
executor = ThreadPoolExecutor(max_workers=2)
@run_on_executor
def sleep(self):
print("休息1...start")
time.sleep(5)
print("休息1...end")
return 'ok'
async def get(self):
res = await self.sleep()
self.write(res)
url_map = [
("/?", SyncToAsyncThreadHandler)
]
if __name__ == '__main__':
app = web.Application(url_map, debug=True)
app.listen(8888)
print('started...')
ioloop.IOLoop.current().start()
2.2 在客户端请求
用线程池发起并发,虽然效率不那么搞,但看着是同步方式,比较简单。
import requests
from concurrent.futures import ThreadPoolExecutor
def make_request():
response = requests.get('http://localhost:8888')
print(response.text)
with ThreadPoolExecutor(max_workers=5) as executor:
futures = [executor.submit(make_request) for _ in range(5)]
for future in futures:
future.result()
这是另一个变体,同时发起多个url的请求。
import time
import logging
import requests
from concurrent.futures import ThreadPoolExecutor, as_completed
logging.basicConfig(level=logging.INFO)
def fetch_url(url):
logging.info(f"Fetching {url}...")
response = requests.get(url)
logging.info(f"Completed {url}")
return response.text
urls = [
"https://httpbin.org/get",
"https://httpbin.org/ip",
"https://httpbin.org/user-agent",
"https://httpbin.org/uuid",
"https://httpbin.org/headers",
]
def main():
max_workers = 10 # 可以根据需要调整 max_workers 的数量
with ThreadPoolExecutor(max_workers=max_workers) as executor:
future_to_url = {executor.submit(fetch_url, url): url for url in urls}
for future in as_completed(future_to_url):
url = future_to_url[future]
try:
data = future.result()
logging.info(f"Result from {url}: {data[:60]}...")
except Exception as exc:
logging.error(f"{url} generated an exception: {exc}")
if __name__ == "__main__":
main()
线程与协程
在我问这个问题的时候,chat又了我例子

线程
from concurrent.futures import ThreadPoolExecutor
import time
def task(n):
print(f"Task {n} start")
time.sleep(2)
print(f"Task {n} end")
return n
def main():
with ThreadPoolExecutor(max_workers=3) as executor:
futures = [executor.submit(task, i) for i in range(5)]
for future in futures:
print(f"Result: {future.result()}")
if __name__ == "__main__":
main()
协程
import asyncio
async def task(n):
print(f"Task {n} start")
await asyncio.sleep(2)
print(f"Task {n} end")
return n
async def main():
tasks = [task(i) for i in range(5)]
results = await asyncio.gather(*tasks)
for result in results:
print(f"Result: {result}")
if __name__ == "__main__":
asyncio.run(main())
然后还给了一个混合版,我就不知道是不是它有点幻觉+过敏了。
import asyncio
from concurrent.futures import ThreadPoolExecutor
def blocking_io(n):
print(f"Blocking IO {n} start")
time.sleep(2)
print(f"Blocking IO {n} end")
return n
async def main():
loop = asyncio.get_running_loop()
with ThreadPoolExecutor() as pool:
results = await asyncio.gather(
loop.run_in_executor(pool, blocking_io, 1),
loop.run_in_executor(pool, blocking_io, 2),
loop.run_in_executor(pool, blocking_io, 3),
)
for result in results:
print(f"Result: {result}")
if __name__ == "__main__":
asyncio.run(main())
最后再附一个我自己的协程版,在eventloop方面我有点没搞明白,不过反正不是get loop就是new loop,是在不行再叠一个nest_asyncio,反正只要有那么一个协调组织者在就行(loop)。
import nest_asyncio
nest_asyncio.apply()
import json
import asyncio, aiohttp
async def json_query_worker(task_id = None , url = None , json_params = None,time_out = 60, semaphore = None):
async with semaphore:
async with aiohttp.ClientSession() as session:
async with session.post(url, json = {**json_params},timeout=aiohttp.ClientTimeout(total=time_out)) as response:
res = await response.text()
return {task_id: json.loads(res)}
async def json_player(task_list , concurrent = 3):
semaphore = asyncio.Semaphore(concurrent) # 并发限制
tasks = [asyncio.ensure_future(json_query_worker(**x, semaphore = semaphore)) for x in task_list]
return await asyncio.gather(*tasks)
loop = asyncio.new_event_loop()
# loop = asyncio.get_event_loop()
tick1 = time.time()
res = loop.run_until_complete(json_player(para_dict['task_rec_list'], concurrent=10))
tick2 = time.time()
print(tick2- tick1)