1. mysql的批量写
mysql 批量插入可以用下面这种,在values 之后跟上各种多个值列表。但这种写法可能导致sql长度超长、锁超时等问题。
insert into (`field1`,`field1`,`field1`,) values (value01,value02,value03),(value11,value12,value13),(value21,value22,value23) .....;
在数据量较大的时候,上面这种方式就不太合适。mysql提供了批量写入的方法,将大批量的sql脚本一批次发送到服务端,减少IO次数,然后统一一次执行sql。这种写入效率会高很多。如下所示,先执行statement.addBatch()先将sql添加到statement列表,然后执行statement.executeBatch()统一批量执行sql。mybatis-plus的批量提交的底层实现就是基于此,它默认将1000条sql作为一个批次。
Class.forName("com.mysql.cj.jdbc.Driver");
// 创建连接
conn = DriverManager.getConnection(url, user, password);
// 创建预编译 sql 对象
statement = conn.prepareStatement("UPDATE sku_inventory set stock =stock+1 where id = ?");
long a = System.currentTimeMillis(); // 计时
// 这里添加 100 个批处理参数
for (int i = 1; i <= 10000; i++) {
statement.setInt(1, i);
statement.addBatch(); // 批量添加
}
long b = System.currentTimeMillis(); // 计时
System.out.println("添加参数耗时:" + (b-a)); // 计时
int[] r = statement.executeBatch(); // 批量提交
statement.clearBatch(); // 清空批量添加的 sql 命令列表缓存
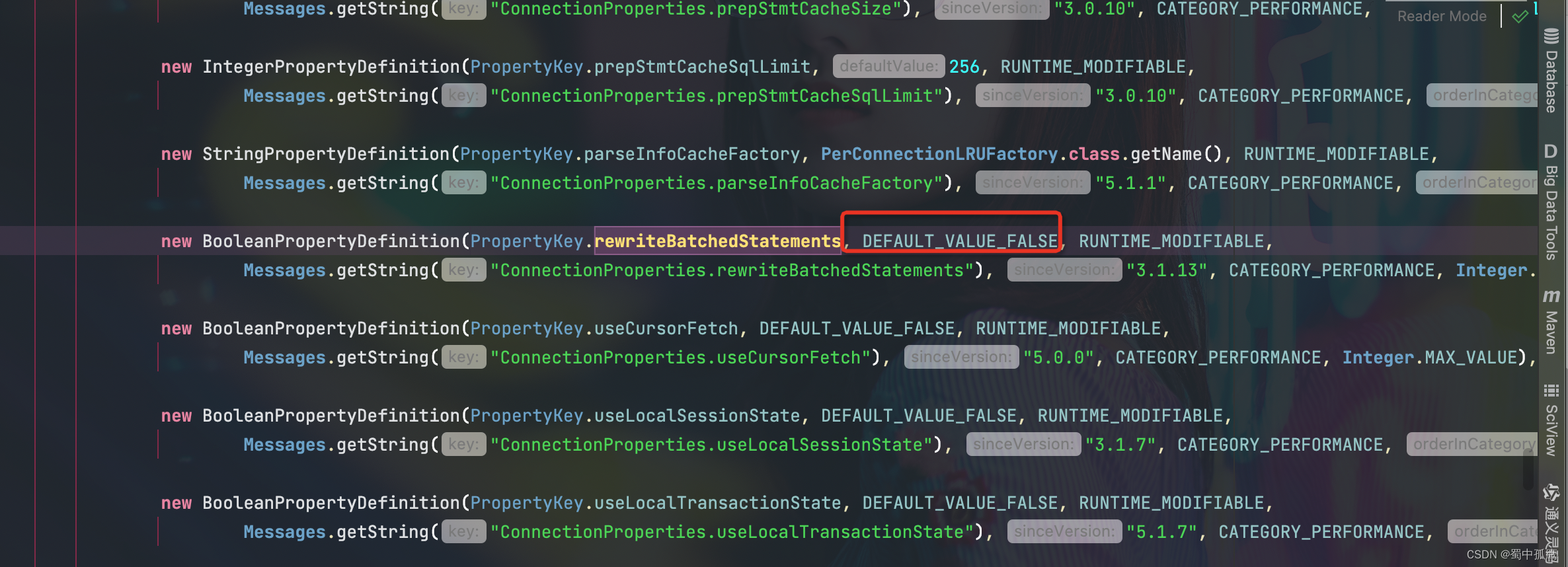
理论上,上面的sql是批量提交到mysql server统一执行的,但在默认情况下实际上它还是一条条执行命令,要真正的批量执行sql,需要在jdbc连接url加上rewriteBatchedStatements=true,这个参数的默认只是false
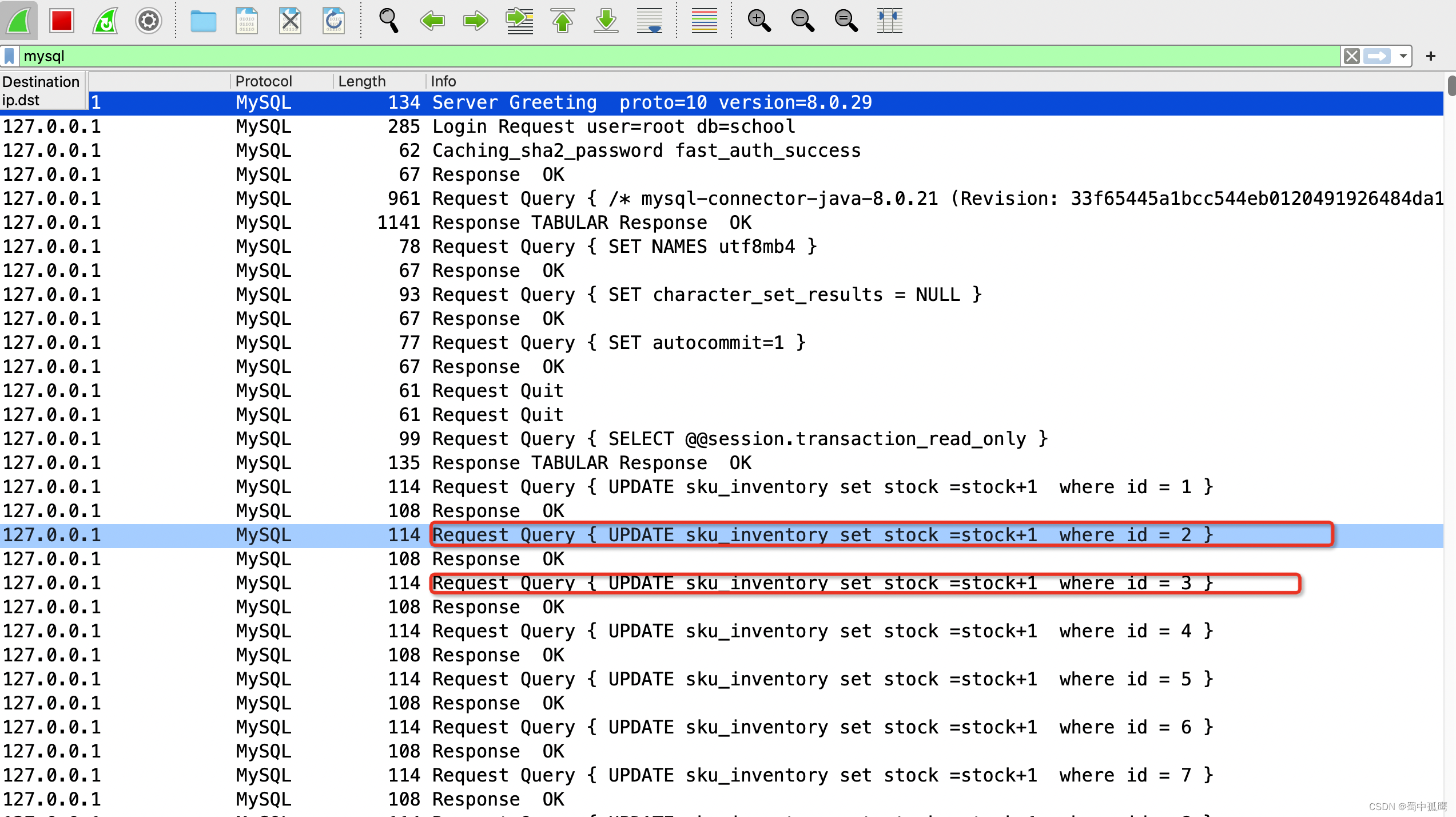
从wireshark抓包的情况来看,在默认配置下,sql批量执行貌似没起作用。这里客户端发送一个sql脚本然后得到一个response响应,发送一个sql得到一个响应,循环万福,就是在串行化执行sql。
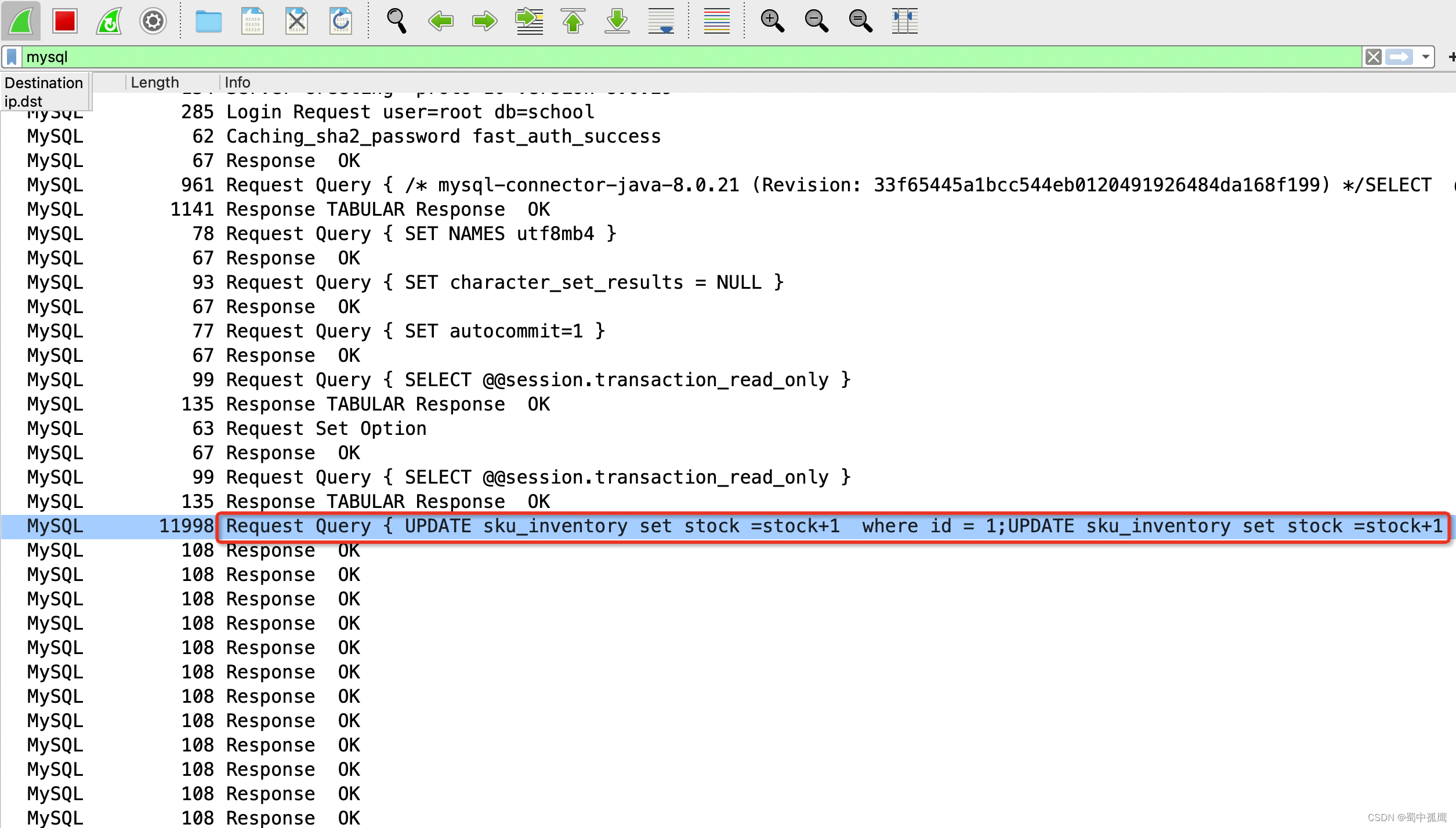
下面是添加了rewriteBatchedStatements=true这个参数后的抓包截图,jdbc客户端重写了sql语句,它把多个sql语句用分号分隔连接在一起,形成一个大sql脚本, 然后将这个sql脚本一次性发送到server端,最后接收到了大量的response响应。这个才是我们想要的接口
rewriteBatchedStatements这个参数不只是对插入数据有效,对update delete语句也有同样的效果。
另外如果有更大批量的结构化数据需要插入,可以使用 load data local infile这个指令,这个指令可以将文本文件中的数据快速导入到mysql,这个指令比普通的语句快20倍以上。本地测试在没有激烈的锁竞争情况下插入100万数据只用了10秒钟,当然在真实环境中要考虑文本文件传输的I/O耗时,这会增加更多的耗时。
这个指令一般和replace into insert into 结合起来使用。
load data local infile {fileName} -- 文本文件名
replace into table sku_inventory -- 表名
CHARACTER SET utf8mb4 -- 文本文件的字符集编码
COLUMNS TERMINATED by ',' -- 文本文件的字段分隔符
IGNORE 1 lines -- 忽略一行,从第二行读数据因为我的csv文件第一行是字段名
(`id`, stock,spu_id,`name`)
这个指令需要指定数据文件名、 字符集编码、文本文件的字段分隔符,数据库的字段名列表(注意和文本文件中字段列的顺序一致)。
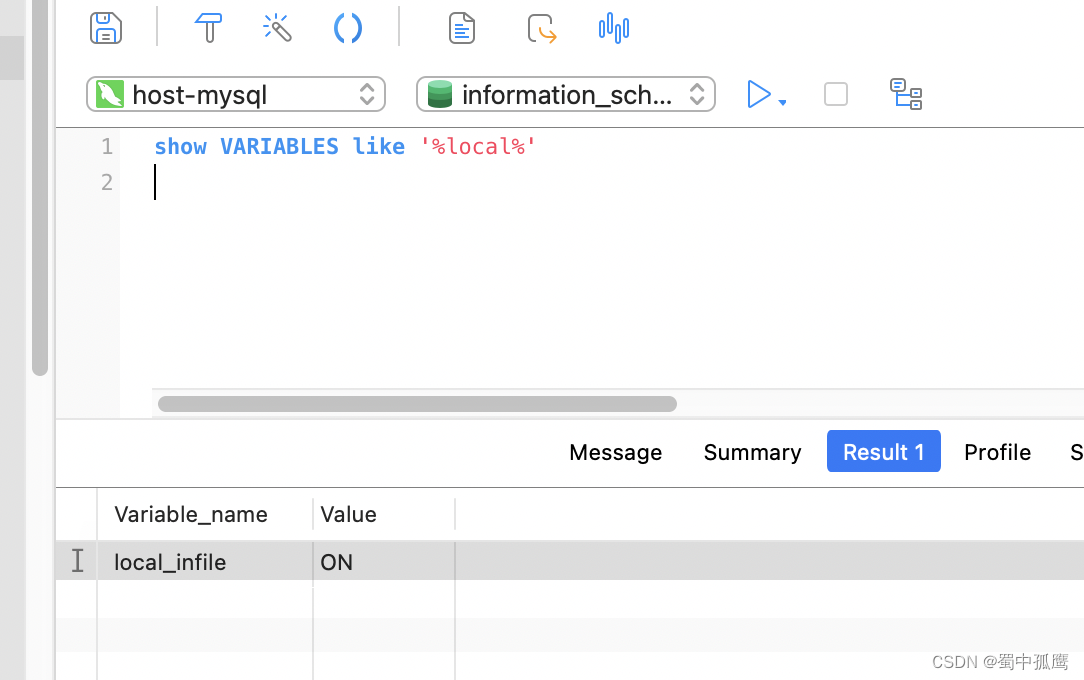
注意:要使用这功能需要先在服务端将环境变量 local_infile为on,表示启用这个特性。另外之外还要在客户端启动这个功能,在jdbc连接url上加上参数allowLoadLocalInfile=true
2. 批量读
大数据的查询需要渐进式查询,如果用普通的查询可能导致mysql数据报文太大、JVM内存溢出等问题。
mysql上有两种解决方案,(1) 游标查询;(2)流式查询。
国内一般都用mybatis做orm框架,现在用mybatis实现这两种功能。
mybatis提供了org.apache.ibatis.cursor.Cursor进行游标查询,但这本质上还是客户端的游标查询,实际上还是一次性从mysql服务器检索出所有数据。不信,请往下看。
1) 游标查询

<select id="fetchAll" fetchSize="10000" resultMap="BaseResultMap">
SELECT <include refid="Base_Column_List" />
FROM sku_inventory WHERE id > #{gtId}
</select>
从上面可以看到我定义了一个游标结果集类型的接口,且定义了fetchSize,
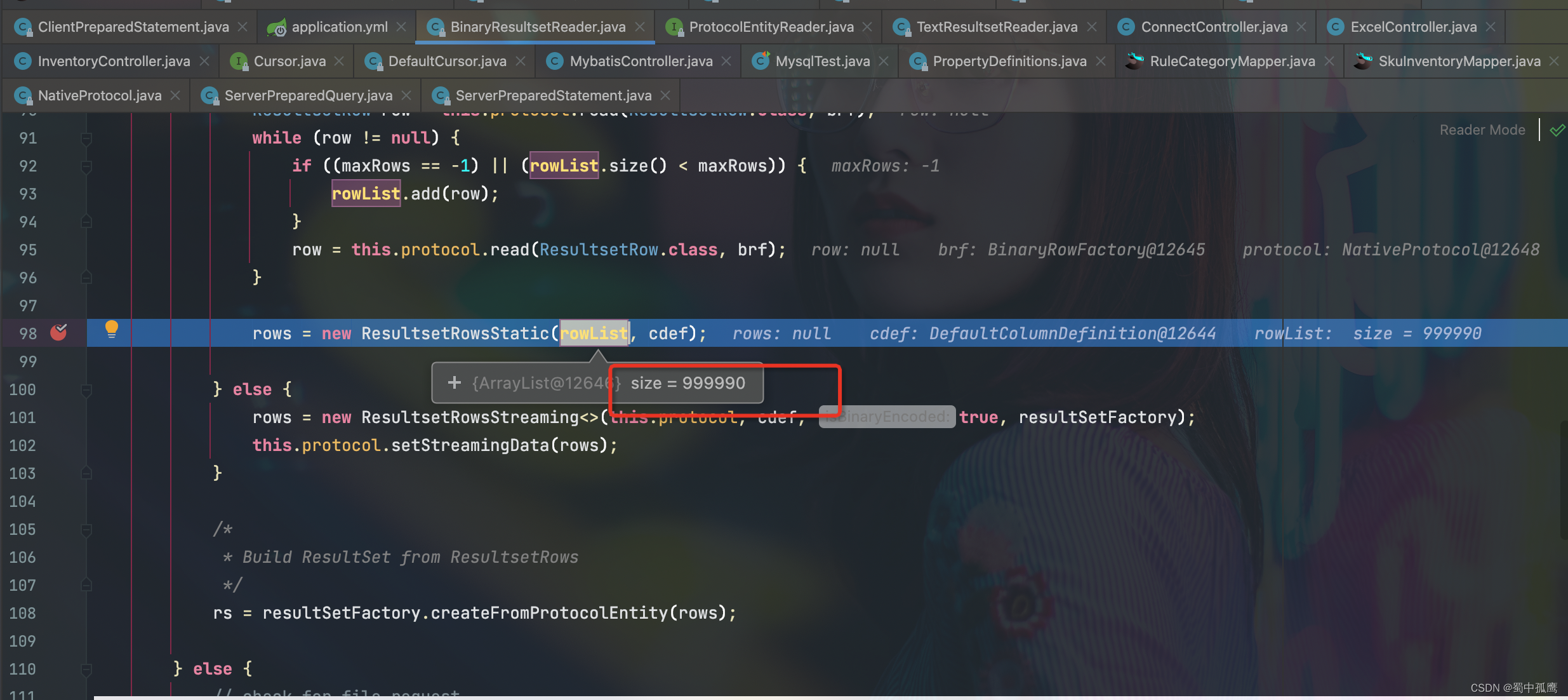
但是从com.mysql.cj.protocol.a.BinaryResultsetReader#read方法可以看到,客户端一次性获取到了所有的数据,它是一个静态结果集,并没有分段渐进获取。
现在我在连接参数上加上useCursorFetch=true,重启项目再执行接口。再看看debug时截图信息,现在结果集是游标类型结果集ResultsetRowsCursor。而且从wirekshar抓包来看,还出现了Fetch Data这个数据报文,这个数据报文内容是10000,这恰好和xml中配置的fetchSize="10000"对应上了。在之前的那个示例中,没加useCursorFetch连接参数,jdbc客户端是没有Fetch Data数据报文的。


2)流式查询
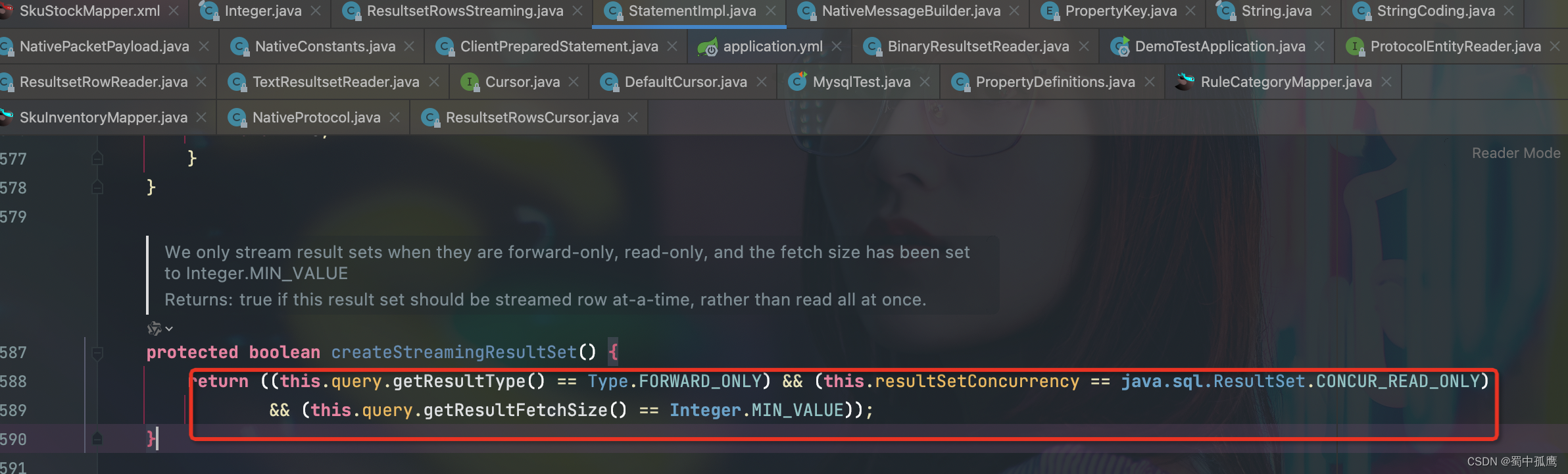
流式查询也可以用org.apache.ibatis.cursor.Cursor实现,只需要将fetchSize设为-2147483648即可启用。为啥是-2147483648尼,因为这个值是Integer的最小值Integer.MIN_VALUE。mysql驱动判断是否是流式查询的方法在com.mysql.cj.jdbc.StatementImpl#createStreamingResultSet中,它的判断逻辑是:
结果集类型是FORWARD_ONLY 、结果集并发类型是CONCUR_READ_ONLY且fetchSize是Integer.MIN_VALUE 就启用流式结果集。其中ResultType默认是FORWARD_ONLY、resultSetConcurrency默认是CONCUR_READ_ONLY,所以我们只要保证fetchSize是Integer.MIN_VALUE ,那么就可以启用流式结果集。
mybatis xml中修改下fetchSize参数,其他的不用变更(这里得先把参数useCursorFetch恢复成默认值false)。
<select id="fetchAll" fetchSize="-2147483648" resultMap="BaseResultMap">
SELECT <include refid="Base_Column_List" />
FROM sku_inventory WHERE id > #{gtId}
</select>
从下面的截图可以看出,此时返回结构是流式结果集ResultsetRowsStreaming