序列模型
定义
序列模型是自然语言处理(NLP)和机器学习领域中一类重要的模型,它们特别适合处理具有时间顺序或序列结构的数据,例如文本、语音信号或时间序列数据。
举个例子:一部电影的评分在不同时间段的评分可能是不一样的,锚定效应:当一部电影获得某项大奖后,该电影的评分可能会上升。季节性:新年贺岁电影和圣诞电影在相应时间会更受欢迎。电影评分不是不变的,和时间是有相关性的。
统计工具
处理序列数据需要统计工具和新的深度神经网络架构。我们通常使用
x
t
x_t
xt 表示模型在时间
t
t
t 的输出,
t
t
t 代表时间步,通过以下公式进行预测:
x
t
∼
P
(
x
t
∣
x
t
−
1
,
…
,
x
1
)
x_t\sim P(x_t|x_{t-1},\dots,x_1)
xt∼P(xt∣xt−1,…,x1)
使用条件概率展开:
P
(
a
,
b
)
=
P
(
a
)
P
(
b
∣
a
)
=
P
(
b
)
P
(
a
∣
b
)
P(a,b)=P(a)P(b|a)=P(b)P(a|b)
P(a,b)=P(a)P(b∣a)=P(b)P(a∣b)
根据条件概率的链式法则有:
P
(
x
)
=
P
(
x
1
)
⋅
P
(
x
2
∣
x
1
)
⋅
P
(
x
3
∣
x
1
,
x
2
)
⋅
⋯
P
(
x
t
∣
x
1
,
⋯
,
x
t
−
1
)
P(x)=P(x_1)\cdot P(x_2|x_1)\cdot P(x_3|x_1,x_2)\cdot \cdots P(x_t|x_1,\cdots,x_{t-1})
P(x)=P(x1)⋅P(x2∣x1)⋅P(x3∣x1,x2)⋅⋯P(xt∣x1,⋯,xt−1)
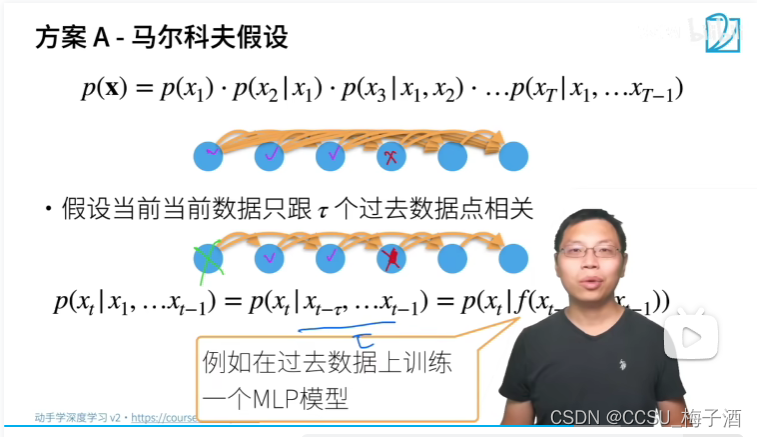
对条件概率建模, P ( x t ∣ x 1 , ⋯ , x t − 1 ) = P ( x t ∣ f ( x 1 , ⋯ , x t − 1 ) ) P(x_t|x_1,\cdots,x_{t-1})=P(x_t|f(x_1,\cdots,x_{t-1})) P(xt∣x1,⋯,xt−1)=P(xt∣f(x1,⋯,xt−1)),这里的 f f f 函数可以看作对之前的数据进行建模,来预测序列中的下一个元素。(这正是序列模型如循环神经网络(RNN)、长短时记忆网络(LSTM)、门控循环单元(GRU)和最近的Transformer模型所做的事情)
举个序列预测的例子(文本生成):输入一段文本,根据该文本的数据训练好一个模型,现在有一句话“今天天气……”,要求对之后的话进行续写,续写其实就是预测下一个最可能的字(这也是GPT系列模型的原理),这里每个字就可以看作在时间 t t t 的输出。 根据之前的文本,可能之前出现很多次“今天天气真好”,那么“真”字在“今天天气”已经存在的情况下的概率就会比较高 P ( 真 ∣ 今天天气 ) > P ( 不 ∣ 今天天气 ) P(真|今天天气) >P(不|今天天气) P(真∣今天天气)>P(不∣今天天气)。再根据“真”,预测出“好”。
自回归模型
自回归模型:根据自己之前的序列数据建模进行之后元素的预测,所以叫自回归。
输入数据的数量, 输入
x
t
−
1
,
…
,
x
1
x_{t-1},\dots,x_1
xt−1,…,x1 本身因
t
t
t而异。 也就是说,输入数据的数量这个数字将会随着我们遇到的数据量的增加而增加(计算量甚至是指数级的增长), 因此需要一个近似方法来使这个计算变得容易处理。有以下两种策略。
马尔可夫模型
马尔可夫假设认为现实情况下相当长的序列
x
t
−
1
,
⋯
,
x
1
x_{t-1},\cdots,x_1
xt−1,⋯,x1 可能是不必要的, 因此我们只需要满足某个长度为
τ
\tau
τ 的时间跨度, 即使用观测序列
x
t
−
1
⋯
,
x
t
−
τ
x_{t-1}\cdots,x_{t-\tau}
xt−1⋯,xt−τ 来进行
x
t
x_t
xt 的预测。 这样当
t
>
τ
t>\tau
t>τ 时参数的数量总是不变的。
隐变量自回归模型
在序列模型中,隐变量(Latent Variable)是指那些在时间序列数据中不可直接观测,但却对序列的产生及其动态变化有着重要影响的变量。在这里隐变量可以看作对过去序列观测的总结
h
t
=
f
(
x
1
,
⋯
,
x
t
−
1
)
h_t = f(x_1,\cdots,x_{t-1})
ht=f(x1,⋯,xt−1).
这样模型需要同时预测
x
t
x_t
xt 和更新
h
t
h_t
ht,于是模型形式上就变成:
h
t
=
g
(
h
t
−
1
,
x
t
−
1
)
h_t=g(h_{t-1},x_{t-1})
ht=g(ht−1,xt−1)
x
t
=
P
(
x
t
∣
h
t
)
x_t=P(x_t|h_t)
xt=P(xt∣ht) 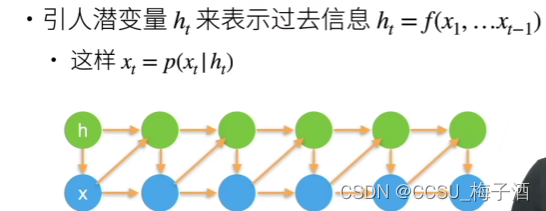
总结

本专栏用于记录学习笔记和理解,其内容都是基于李沐老师的课程:动手学深度学习。
可以在b站学习老师的课程:动手学深度学习 PyTorch版
教材:教材