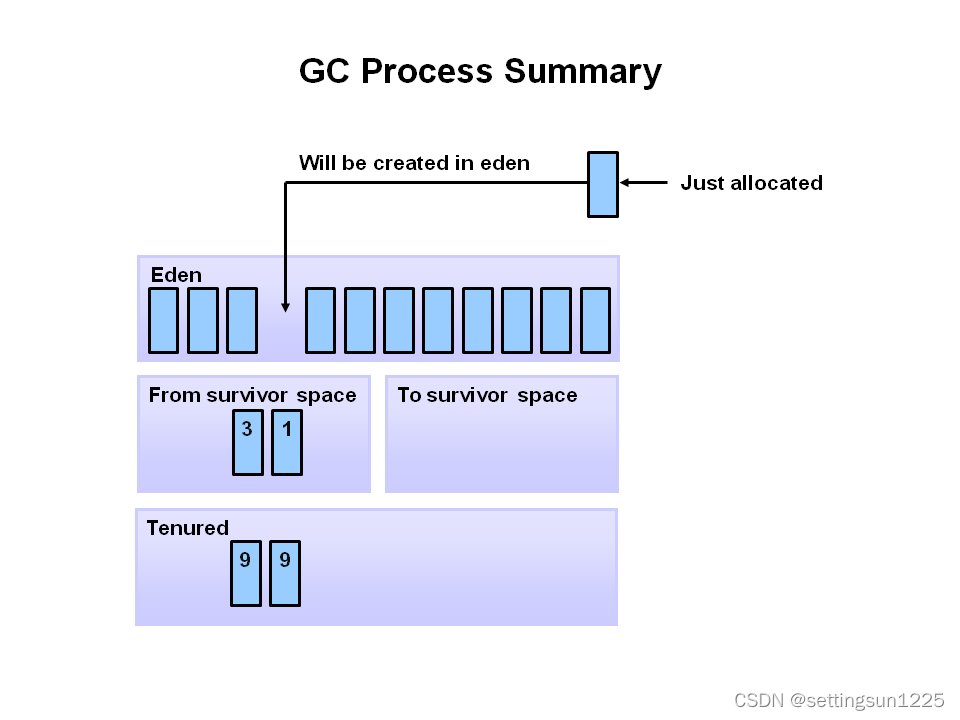
1.大语言模型的基本结构
transfomer block:
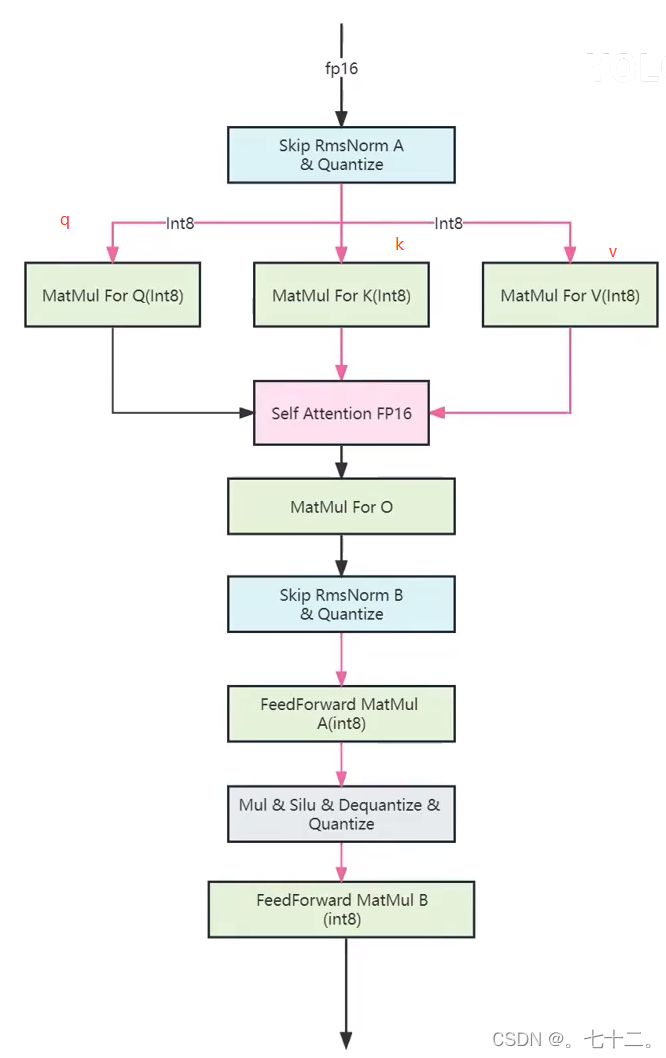
输入--->正则化-->qkv三个矩阵层(映射到三个不同空间中)---->q,k,v之后self attention进行三0合一---->线性映射,正则化。
2.大语言模型的推理
目前主流的语言大模型都采用decoder-only的结构,其推理过程由两部分组成:
(1)prefill阶段
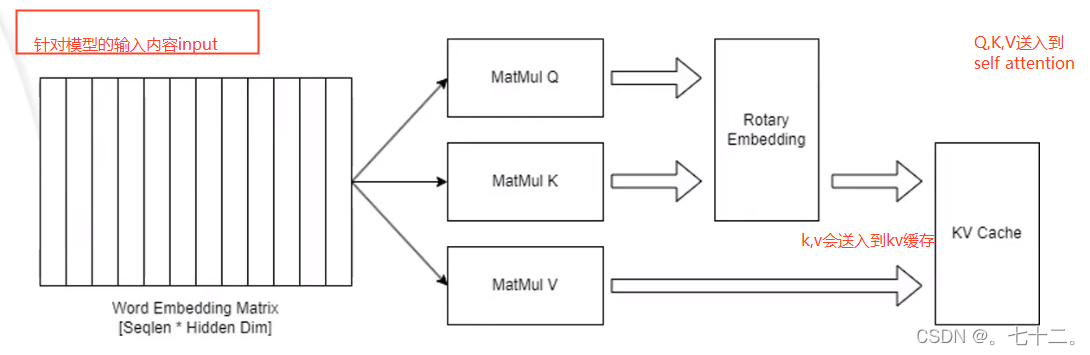
prefill会生成针对这个用户的输入生成缓存。
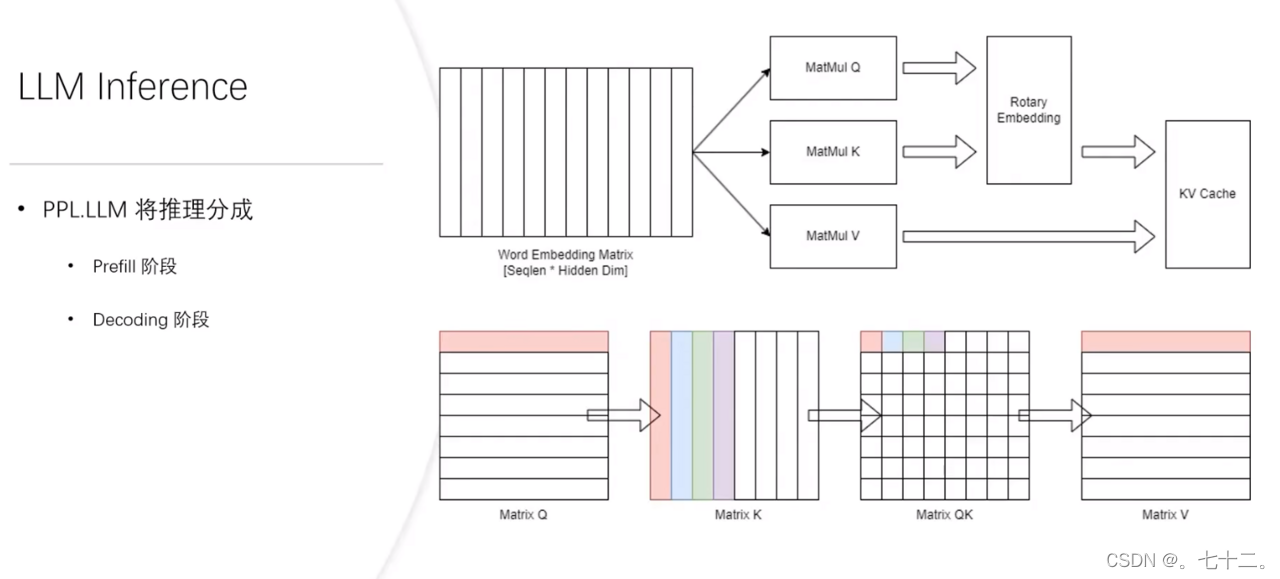
prefill截断推理示意图,一般hidden dim是4096。
q直接送入self atention Matricq指的是矩阵乘k的结果,matrick指矩阵乘k的结果。。。等等(k需要先做转置)。
整个self attention就是两次矩阵乘法和一次softmax。Matrixq和matrixk先做矩阵乘法获得Matrixqk,对Matrixqk做softmax,之后qk矩阵和matrixv做矩阵乘法,最终获得self att