谷物识别系统,本系统使用Python作为主要编程语言,通过TensorFlow搭建ResNet50卷积神经算法网络模型,通过对11种谷物图片数据集(‘大米’, ‘小米’, ‘燕麦’, ‘玉米渣’, ‘红豆’, ‘绿豆’, ‘花生仁’, ‘荞麦’, ‘黄豆’, ‘黑米’, ‘黑豆’)进行训练,得到一个进度较高的H5格式的模型文件。然后使用Django框架搭建了一个Web网页端可视化操作界面。实现用户上传一张图片识别其名称。
一、课题介绍
基于深度学习的图像识别技术在农业领域的应用已日益增长,尤其是在作物和谷物识别方面。随着计算技术的发展和机器学习算法的进步,利用这些技术对农产品进行快速准确的分类和识别,不仅可以提高农业生产的效率,还可以在食品安全和质量控制方面发挥重要作用。
本系统通过开发一个基于深度学习的谷物识别系统,该系统采用Python作为主要编程语言,并结合TensorFlow框架构建了基于ResNet50的卷积神经网络模型。ResNet50是一种广泛使用的深度残差网络,它通过引入残差学习来解决深度网络中的梯度消失问题,从而能有效地提高网络的训练速度和准确度。通过对11种不同谷物(包括大米、小米、燕麦、玉米渣、红豆、绿豆、花生仁、荞麦、黄豆、黑米和黑豆等)的图片数据集进行训终,本系统成功构建了一个高效识别谷物种类的模型。
为了使得该识别系统更加用户友好,本课题还开发了一个基于Django框架的Web网页端可视化操作界面。Django是一个高级的Python Web框架,它鼓励快速开发并遵循MVC设计。该界面允许用户上传谷物图片,并快速得到识别结果,整个过程既直观又高效。
此外,该系统的实际应用前景广泛,不仅可用于帮助农民和农业企业识别和分类谷物种类,还能在农业科研、质量控制及市场监着等领域中发挥重要作用。通过进一步优化算法和扩展数据库,该系统有潜力进一步提升其准确度和应用范围,从而在全球范围内促进农业现代化和精确化发展。
二、系统效果图片展示
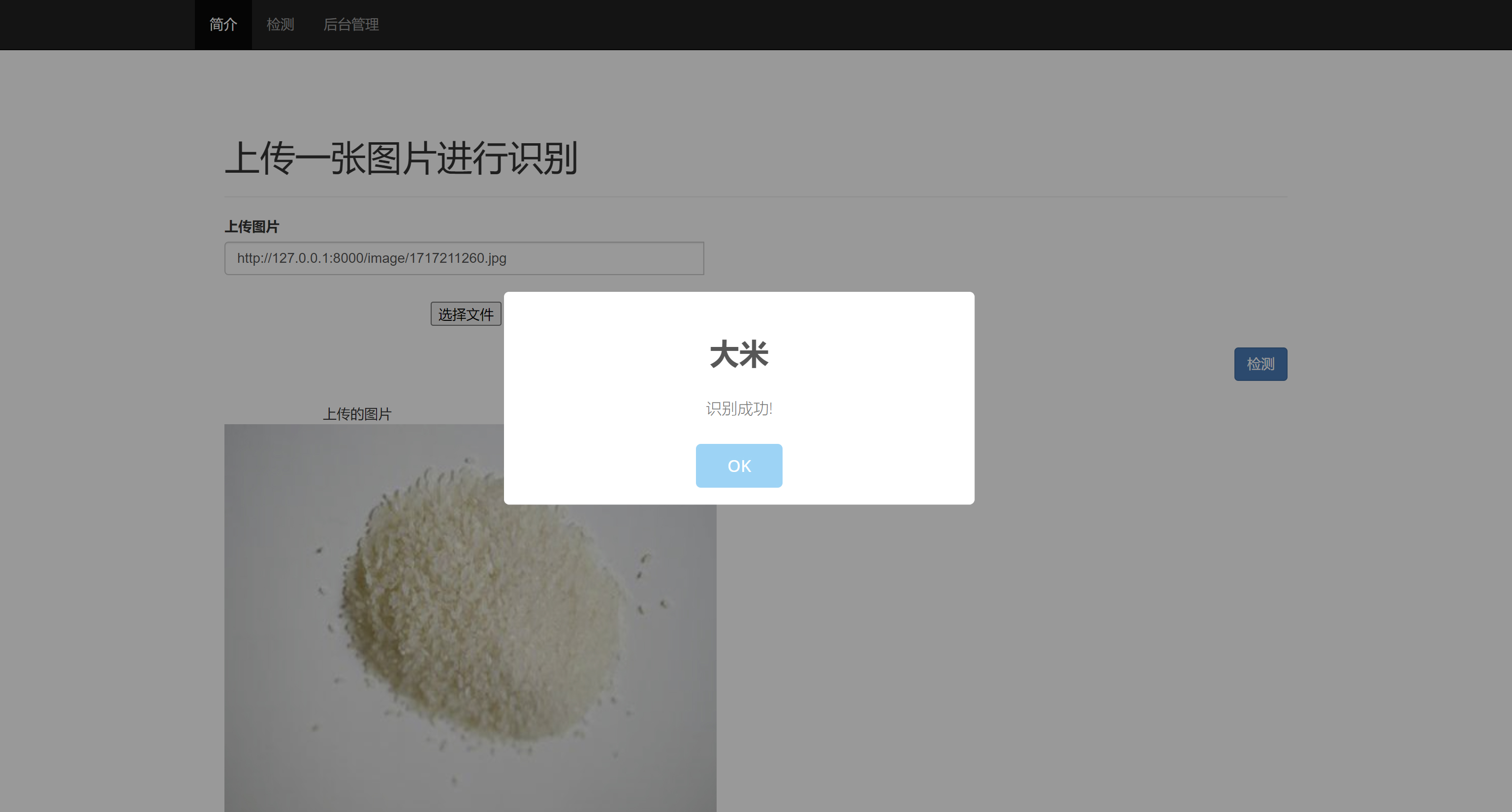

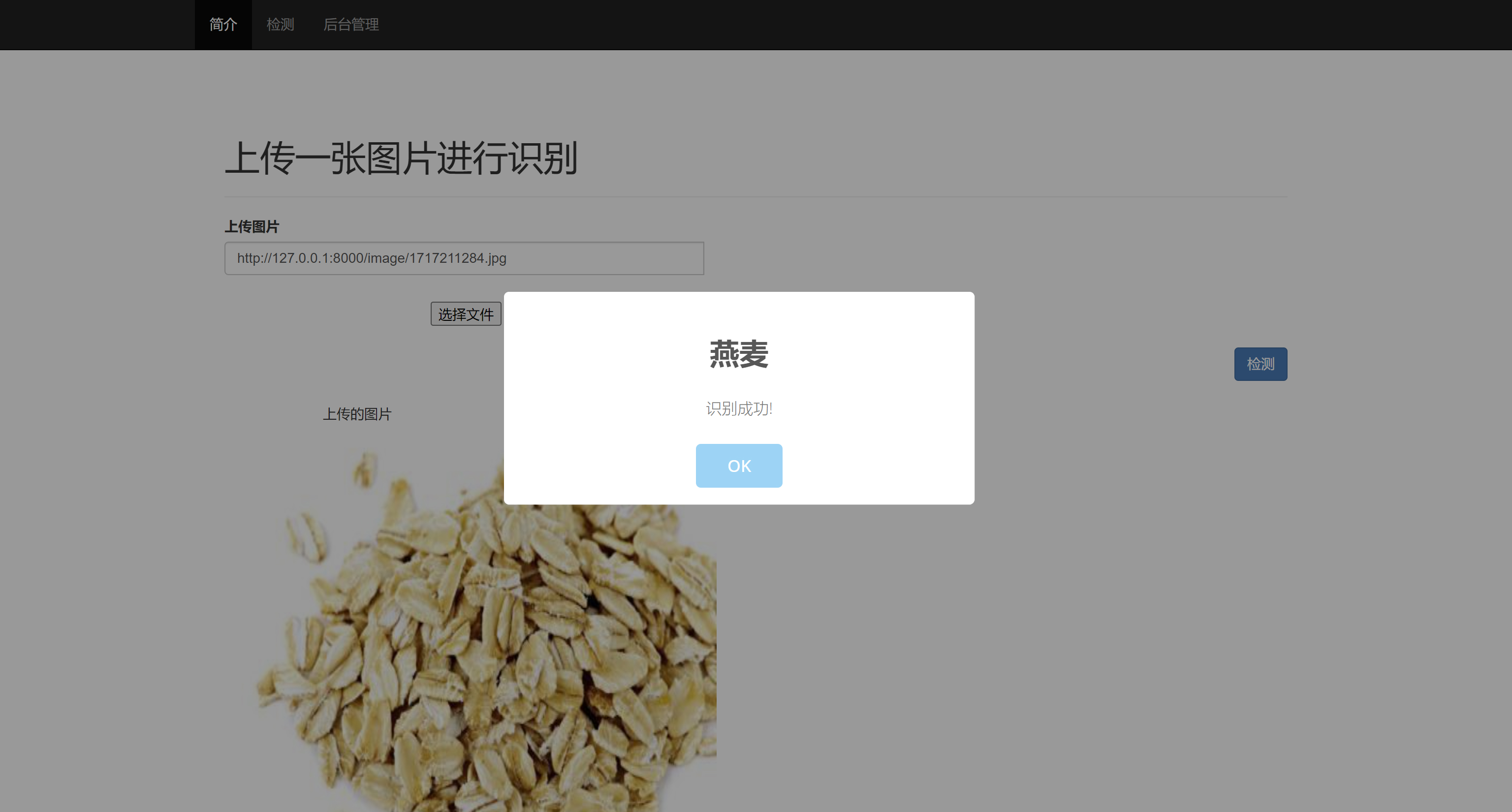

三、演示视频 and 代码 and 安装
地址:https://www.yuque.com/ziwu/yygu3z/as42g6b5h0gwtc1d
四、TensorFlow介绍
TensorFlow是一种开源的机器学习框架,由Google的Google Brain团队开发。它于2015年首次发布,主要用于数据流图的数值计算,广泛应用于各类机器学习和深度学习项目。Tensorsslow支持多种语言,但以Python为主,它提供了丰富的API来设计、训练和部署模型。
TensorFlow的核心是它的数据流图,图中的节点代表数学运算,边则代表在节点间流动的多维数据数组(张量)。这种结构允许TensorFlow高效地进行大规模并行计算,特别适合深度学习网络的训练和推理。
接下来,将提供一个使用TensorFlow搭建卷积神经网络(CNN)进行简单图像识别的示例。这个例子会构建一个小型的CNN来识别MNIST手写数字数据集。TensorFlow CNN 示例代码
使用以下Python脚本搭建并训练一个简单的CNN模型:
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
# 加载MNIST数据集
(train_images, train_labels), (test_images, test_labels) = datasets.mnist.load_data()
# 标准化数据
train_images, test_images = train_images / 255.0, test_images / 255.0
# 调整图像维度,适应模型输入
train_images = train_images.reshape((60000, 28, 28, 1))
test_images = test_images.reshape((10000, 28, 28, 1))
# 构建模型
model = models.Sequential([
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.Flatten(),
layers.Dense(64, activation='relu'),
layers.Dense(10)
])
# 编译模型
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
# 训练模型
model.fit(train_images, train_labels, epochs=10,
validation_data=(test_images, test_labels))
# 评估模型
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
print('\nTest accuracy:', test_acc)
这个例子中,我们首先加载并预处理了MNIST数据集,然后构建了一个包含三层卷积和两层池化的CNN模型。最后,通过训练和评估模型,我们可以看到模型在测试集上的表现。这个简单的CNN模型实现了一个经典的手写数字的识别案例。
![[数据集][目标检测]旋风检测数据集VOC+YOLO格式157张1类别](https://img-blog.csdnimg.cn/direct/83778a7731d64af3bcf2e70a39acf8a0.png)



![[数据集][目标检测]吉他检测数据集VOC+YOLO格式66张1类别](https://img-blog.csdnimg.cn/direct/d033934f06324364b11f40371a9c9705.png)