13. 项目接入ES
编写爬虫抓取房源数据
开发搜索房源接口服务
整合前端开发实现搜索功能
优化搜索功能增加高亮和分页功能
热词推荐功能实现
拼音分词
13.1 制作假数据
13.1.1 WebMagic抓取数据
为了丰富我们的房源数据,所以我们采用WebMagic来抓取一些数据,目标网站是上海链家网。

打开it-es项目
<!---引入WebMagic依赖-->
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-core</artifactId>
<version>0.7.3</version>
</dependency>
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-extension</artifactId>
<version>0.7.3</version>
</dependency>
<!---引入commons-io依赖-->
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.6</version>
</dependency>我们先写一个官方demo来快速学习下webmagic.
package cn.itcast.es.wm;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
/**
* 官方实例demo
*/
public class GithubRepoPageProcessor implements PageProcessor {
// 爬虫策略
private Site site = Site.me()
.setRetryTimes(3) // 下次失败后,重试三次
.setSleepTime(1000) // 每隔一秒,请求下一个网页
.setTimeOut(10000); // 下载10s则超时失败.
@Override
public void process(Page page) {
// 新增解析多个目标网址
page.addTargetRequests(page.getHtml().links().regex("(https://github\\.com/[\\w\\-]+/[\\w\\-]+)").all());
page.addTargetRequests(page.getHtml().links().regex("(https://github\\.com/[\\w\\-])").all());
// 目标解析域为 https://github.com/(\\w+)/的所有样式
page.putField("author", page.getUrl().regex("https://github\\.com/(\\w+)/.*").toString());
// 当前页面的h1并且样式为class='entry-title public'下的<strong>标签下的<a>标签里的文字.
page.putField("name", page.getHtml().xpath("//h1[@class='entry-title public']/strong/a/text()").toString());
// 跳过分页列表所在的页(就是分页列表页面没有name属性, 只有详情页才有name属性)
if (page.getResultItems().get("name") == null) {
//skip this page
page.setSkip(true);
}
page.putField("readme", page.getHtml().xpath("//div[@id='readme']/tidyText()"));
}
@Override
public Site getSite() {
return site;
}
// 哦对了, 运行会报错, 是正常现象, 官方demo就这样.
public static void main(String[] args) {
// 指定目标网址
Spider.create(new GithubRepoPageProcessor()).addUrl("https://github.com/code4craft").thread(5).run();
}
}多说无益, 我们直接新增一个LianjiaPageProcessor来解析链家网页吧.
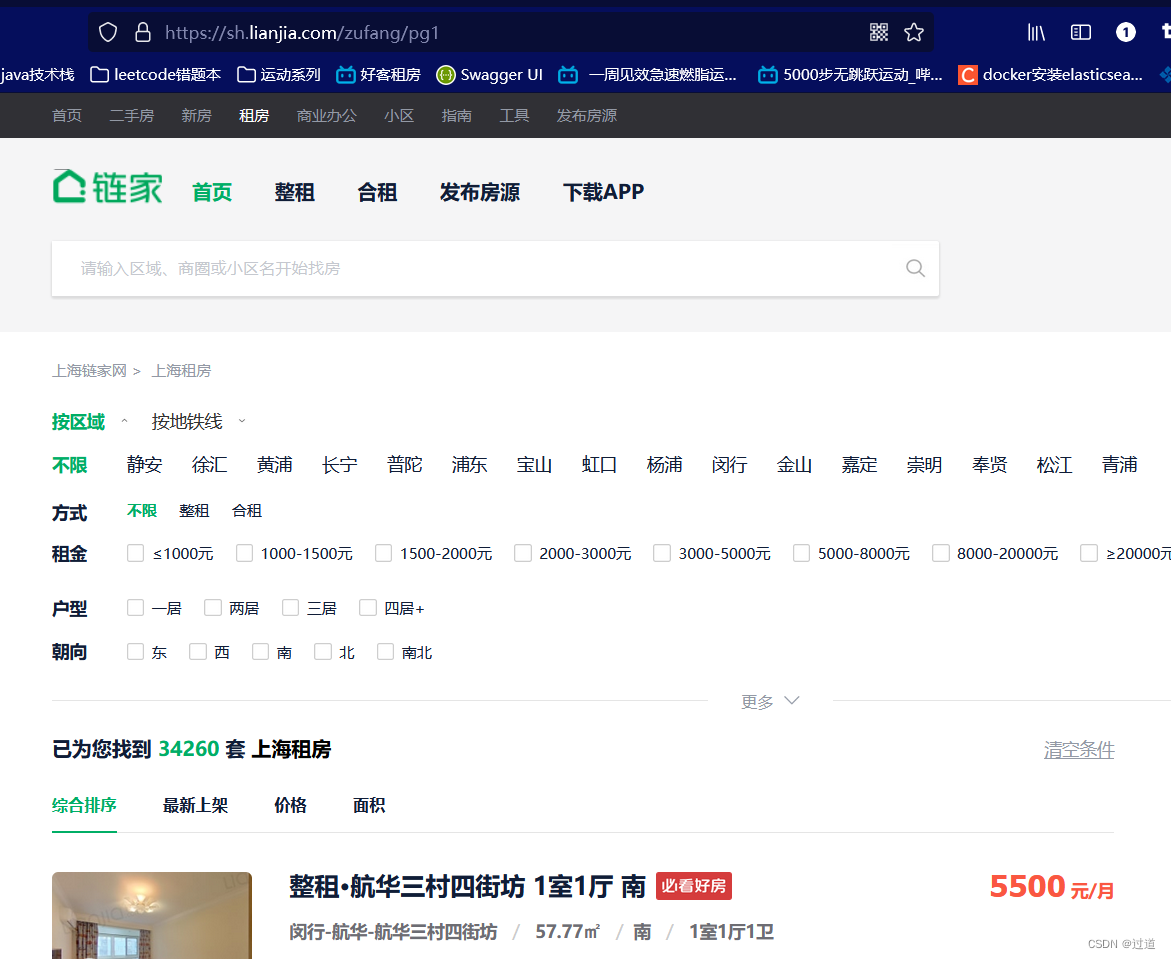
目标网页:
https://sh.lianjia.com/zufang/pg1
pg1是第一页, 所以我们改变1->100就是遍历100页了.
package cn.itcast.es.wm;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
import us.codecraft.webmagic.selector.Html;
import java.util.List;
/**
* 解析上海链家分页租房内容前100页
* https://sh.lianjia.com/zufang/pg{1...100}
*/
public class LianjiaPageProcessor implements PageProcessor {
// 下载失败后重试次数为三次, 每隔200ms发起一次请求.
private Site site = Site.me().setRetryTimes(3).setSleepTime(200);
@Override
public void process(Page page) {
Html html = page.getHtml();
// 得到房源分页列表中所有的详情链接, 根据css选择器进行选择
List<String> all = html.css(".content__list--item--title a").links().all();
// 所有详情的链接被加入到下一次爬取内容中
page.addTargetRequests(all);
// 解析详情页的属性到page中.
toResolveFiled(page, html);
// 只有入口页没有title
if (page.getResultItems().get("title") == null) {
// 不下载本页
page.setSkip(true);
//分页
for (int i = 1; i <= 100; i++) {
page.addTargetRequest("https://sh.lianjia.com/zufang/pg" + i);
}
}
}
private void toResolveFiled(Page page, Html html) {
// 这里采用的统一为css定位解析内容
String title = html.xpath("//div[@class='content clear w1150']/p/text()").toString();
page.putField("title", title);
String rent = html.xpath("//div[@class='content__aside--title']/span/text()").toString();
page.putField("rent", rent);
String type = html.xpath("//ul[@class='content__aside__list']/allText()").toString();
page.putField("type", type);
String info = html.xpath("//div[@class='content__article__info']/allText()").toString();
page.putField("info", info);
String img = html.xpath("//div[@class='content__article__slide__item']/img").toString();
page.putField("img", img);
// String printInfo = page.getRequest().getUrl() + "\ntitle = " + title + "\n" + "rent" + rent + "\n"
// + "type" + type + "\n" + "info" + info + "\n" + "img" + img;
// System.out.println(printInfo);
}
@Override
public Site getSite() {
return site;
}
public static void main(String[] args) {
// 爬虫标记入口页面,五个线程工作.
Spider.create(new LianjiaPageProcessor())
.addUrl("https://sh.lianjia.com/zufang/")
.thread(5)
// 对下载好的页面使用自定义的MyPipeline类进行流处理
.addPipeline(new MyPipeline())
.run();
}
}MyPipeLine类如下:
package cn.itcast.es.wm;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.apache.commons.io.FileUtils;
import org.apache.commons.io.IOUtils;
import org.apache.commons.lang3.StringUtils;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.HttpClientBuilder;
import us.codecraft.webmagic.ResultItems;
import us.codecraft.webmagic.Task;
import us.codecraft.webmagic.pipeline.Pipeline;
import java.io.File;
import java.util.HashMap;
import java.util.Map;
public class MyPipeline implements Pipeline {
private static final ObjectMapper MAPPER = new ObjectMapper();
@Override
public void process(ResultItems resultItems, Task task) {
Map<String, Object> data = new HashMap<>();
data.put("url", resultItems.getRequest().getUrl());
data.put("title", resultItems.get("title"));//标题
data.put("rent", resultItems.get("rent"));//租金
String[] types = StringUtils.split(resultItems.get("type"), ' ');
data.put("rentMethod", types[0]);//租赁方式
data.put("houseType", types[1]);//户型,如:2室1厅1卫
data.put("orientation", types[2]);//朝向
String[] infos = StringUtils.split(resultItems.get("info"), ' ');
for (String info : infos) {
if (StringUtils.startsWith(info, "看房:")) {
data.put("time", StringUtils.split(info, ':')[1]);
} else if (StringUtils.startsWith(info, "楼层:")) {
data.put("floor", StringUtils.split(info, ':')[1]);
}
}
String imageUrl = StringUtils.split(resultItems.get("img"), '"')[3];
String newName = StringUtils
.substringBefore(StringUtils
.substringAfterLast(resultItems.getRequest().getUrl(),
"/"), ".") + ".jpg";
try {
this.downloadFile(imageUrl, new File("F:\\code\\images\\" + newName));
data.put("image", newName);
String json = MAPPER.writeValueAsString(data);
// 写入到F:\code\data.json文件中
// 如果找不到write方法,说明你的FileUtils所在的common-ios版本太低, 注意下是否版本冲突了.
FileUtils.write(new File("F:\\code\\data.json"), json + "\n", "UTF-8", true);
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 下载文件
*
* @param url 文件url
* @param dest 目标目录
* @throws Exception
*/
public void downloadFile(String url, File dest) throws Exception {
HttpGet httpGet = new HttpGet(url);
CloseableHttpResponse response =
HttpClientBuilder.create().build().execute(httpGet);
try {
FileUtils.writeByteArrayToFile(dest,
IOUtils.toByteArray(response.getEntity().getContent()));
} finally {
response.close();
}
}
}运行后, 进入目录, 可以看到data.json已经899kb了.
13.1.2 爬取的数据导入到ES中
然后我们设置ES的文档
PUT http://{ip}:9200/haoke
# 下面的注释不要复制过去哈, 会报错, 删掉注释后再发请求.
{
"settings": {
"index": {
"number_of_shards": 6,
"number_of_replicas": 1
}
},
"mappings": {
"house": {
"dynamic": false, # dynamic 参数来控制字段的新增, false为不允许像js一样新增字段(写入正常,不支持查询)
"properties": {
"title": {
"type": "text",
"analyzer": "ik_max_word" # 选择中文分词器分词后索引
},
"image": {
"type": "keyword",
"index": false # false是不允许被索引的列表
},
"orientation": {
"type": "keyword",
"index": false
},
"houseType": {
"type": "keyword",
"index": false
},
"rentMethod": {
"type": "keyword",
"index": false
},
"time": {
"type": "keyword",
"index": false
},
"rent": {
"type": "keyword",
"index": false
},
"floor": {
"type": "keyword",
"index": false
}
}
}
}
}建好ES的文档后, 我们使用Junit批量导入数据
package cn.itcast.es.rest;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.apache.commons.io.FileUtils;
import org.apache.http.HttpHost;
import org.apache.http.util.EntityUtils;
import org.elasticsearch.client.*;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.io.File;
import java.io.IOException;
import java.util.List;
/**
* 低级别rest风格测试
*/
public class TestESREST {
// object 转 json 的工具
private static final ObjectMapper MAPPER = new ObjectMapper();
// es的rest客户端类
private RestClient restClient;
/**
* 连接ES客户端
*/
@Before
public void init() {
// 这里支持分布式ES, 你可以直接用','分割.
RestClientBuilder restClientBuilder = RestClient.builder(
new HttpHost("134.175.110.184", 9200, "http"));
restClientBuilder.setFailureListener(new RestClient.FailureListener() {
@Override
public void onFailure(Node node) {
System.out.println("出错了 -> " + node);
}
});
this.restClient = restClientBuilder.build();
}
@After
public void after() throws IOException {
restClient.close();
}
@Test
public void tesBulk() throws Exception {
Request request = new Request("POST", "/haoke/house/_bulk");
List<String> lines = FileUtils.readLines(new File("F:\\code\\data.json"),
"UTF-8");
String createStr = "{\"index\": {\"_index\":\"haoke\",\"_type\":\"house\"}}";
StringBuilder sb = new StringBuilder();
int count = 0;
for (String line : lines) {
sb.append(createStr + "\n" + line + "\n");
if (count >= 100) {
request.setJsonEntity(sb.toString());
Response response = this.restClient.performRequest(request);
System.out.println("请求完成 -> " + response.getStatusLine());
System.out.println(EntityUtils.toString(response.getEntity()));
count = 0;
sb = new StringBuilder();
}
count++;
}
}
}测试下
POST http://{ip}:9200/haoke/house/_search
{
"query": {
"match": {
"title": {
"query": "上海"
}
}
},
"highlight": {
"fields": {
"title": {}
}
}
}13.2 提供搜索接口
13.2.1 添加依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>13.2.2 导入配置
# 这个cluster-name是根据你在浏览器{ip}:9200的cluster-name确定的, 不一致的话会报错找不到
spring.data.elasticsearch.cluster-name={通过{ip}:9200查询后可知}
# 9200是RESTful端口,9300是API端口。
spring.data.elasticsearch.cluster-nodes={ip}:930013.2.3 完善java代码
package cn.itcast.haoke.dubbo.api.vo;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
@Data
@AllArgsConstructor
@NoArgsConstructor
@Document(indexName = "haoke", type = "house", createIndex = false)
public class HouseData {
@Id
private String id;
private String title;
private String rent;
private String floor;
private String image;
private String orientation;
private String houseType;
private String rentMethod;
private String time;
}package cn.itcast.haoke.dubbo.api.vo;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.util.List;
import java.util.Set;
@Data
@AllArgsConstructor
@NoArgsConstructor
public class SearchResult {
private Integer totalPage;
private List<HouseData> list;
private Set<String> hotWord;
public SearchResult(Integer totalPage, List<HouseData> list) {
this.totalPage = totalPage;
this.list = list;
}
}package cn.itcast.haoke.dubbo.api.controller;
import cn.itcast.haoke.dubbo.api.service.SearchService;
import cn.itcast.haoke.dubbo.api.vo.SearchResult;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.web.bind.annotation.*;
import java.util.Set;
@RequestMapping("search")
@RestController
@CrossOrigin
public class SearchController {
@Autowired
private SearchService searchService;
@Autowired
private RedisTemplate redisTemplate;
private static final Logger LOGGER = LoggerFactory.getLogger(SearchController.class);
@GetMapping
public SearchResult search(@RequestParam("keyWord") String keyWord,
@RequestParam(value = "page", defaultValue = "1")
Integer page) {
if (page > 100) { // 防止爬虫抓取过多的数据
page = 1;
}
SearchResult search = this.searchService.search(keyWord, page);
Integer count = ((Math.max(search.getTotalPage(), 1) - 1) *
SearchService.ROWS) + search.getList().size();
// 记录日志
LOGGER.info("[Search]搜索关键字为:" + keyWord + ",结果数量为:" + count);
return search;
}
}package cn.itcast.haoke.dubbo.api.service;
import cn.itcast.haoke.dubbo.api.vo.HouseData;
import cn.itcast.haoke.dubbo.api.vo.SearchResult;
import org.elasticsearch.index.query.Operator;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.domain.PageRequest;
import org.springframework.data.elasticsearch.core.ElasticsearchTemplate;
import org.springframework.data.elasticsearch.core.aggregation.AggregatedPage;
import org.springframework.data.elasticsearch.core.query.NativeSearchQueryBuilder;
import org.springframework.data.elasticsearch.core.query.SearchQuery;
import org.springframework.stereotype.Service;
@Service
public class SearchService {
@Autowired
private ElasticsearchTemplate elasticsearchTemplate;
public static final Integer ROWS = 10;
public SearchResult search(String keyWord, Integer page) {
//设置分页参数
PageRequest pageRequest = PageRequest.of(page - 1, ROWS);
SearchQuery searchQuery = new NativeSearchQueryBuilder()
.withQuery(QueryBuilders.matchQuery("title",
keyWord).operator(Operator.AND)) // match查询
.withPageable(pageRequest)
.withHighlightFields(new HighlightBuilder.Field("title")) // 设置高亮
.build();
// 查询内容
AggregatedPage<HouseData> housePage = this.elasticsearchTemplate.queryForPage(searchQuery, HouseData.class);
return new SearchResult(housePage.getTotalPages(), housePage.getContent());
}
}启动,发现报错:整合了Redis后,引发了netty的冲突, 解决方案如下:
package cn.itcast.haoke.dubbo.api;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class DubboApiApplication {
public static void main(String[] args) {
// 指定即可
System.setProperty("es.set.netty.runtime.available.processors","false");
SpringApplication.run(DubboApiApplication.class, args);
}
}测试
http://127.0.0.1:18080/search?keyWord=上海&page=2




![LeetCode[1319]连通网络的操作次数](https://img-blog.csdnimg.cn/img_convert/66d200d112b34fb9a9c783f457a780aa.png)