BBR 与 CUBIC 共存时的收敛图,理论情况:
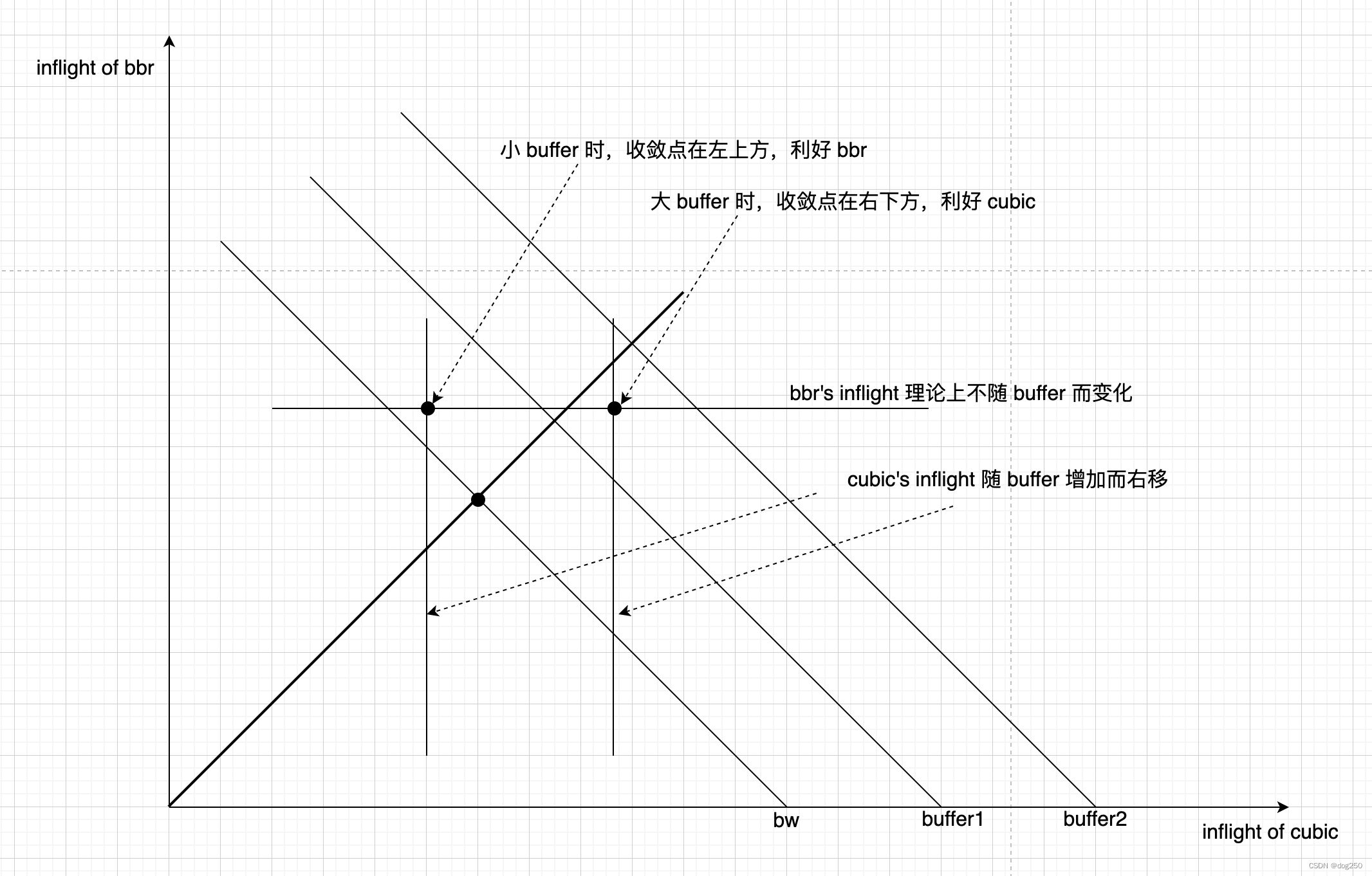
理论上 BBR 不会挤占 buffer,inflight 保持为恒定的 BDP。 但 BBR 的 inflight 做不到恒定,多流共存时,依然会 “主动占用 buffer” 而相互挤兑带宽,而该行为是必须的。
BBR 的本意用 gain = 125% 去 probe,若带宽没增加,说明已挤占 buffer,然后以 gain = 0.75 将 queue 给 drain 回去。但现实中,多流共存时,只要以 gain > 1 执行 probe,就一定能挤兑出带宽,该更大的带宽会被 max-filter 记住作为新的 bw。
该行为乃 BBR 多流公平性所必须:带宽占比越大,MI(Multiplicative-Increase)加速比越小。
不利用 buffer 就无法收敛到公平,在实际中,由于带宽固定,buffer 无需大量占用即可收敛到公平,尚可。
BBR 和 BBR 共存时,靠 125% probe 挤兑 buffer 可公平收敛,但问题是,BBR 和 CUBIC 共存时,同样的行为反而破坏公平性:CUBIC 以 AI 增加 inflight,BBR 以 MI 增加 inflight,CUBIC 靠 buffer overflow 丢包 MD 收敛,可 BBR 呢?二者使用不同的策略。
即使在众所周知 AIMD 占绝对优势的深队列场景,BBR 的 125% probe 行为依然具有一定的抢占力:只要以 gain > 1 执行 probe,就一定能挤兑出带宽。
如果此次 probe 挤兑力依然大于 CUBIC 的 AI 挤兑力,BBR 的带宽就会增加,直到其带宽加速比小于一定的绝对值,该绝对值不足以对抗 CUBIC 的 AI 增益时,BBR 带宽才会下降。
好在 CUBIC 的 AI probe 曲线和 BBR 公平收敛的预设一致:AI 开始时 cwnd 很小,曲线上凸,达到 Last Max-cwnd 附近转为下凸,AI 变缓。与之配合,BBR 带宽很小时,加速比很大,带宽占比很大时,加速比变小,其变化曲线与 CUBIC 相一致。
综上分析,在深队列场景,CUBIC 并没有压倒性的优势,只是不那么糟糕。在实际中,无论哪种过多占用 buffer 的行为均会受到惩罚,BBR 自身采用 cwnd <= 2*BDP 作为约束,明示 buffer 不能占用超过 1 个 BDP(这已经够多了,Reno 也不过如此,是为上限)。在交换机侧,RED 和多异步流效果相当,参考多异步流平方反比律,这很明显减少了 buffer 的实际使用总量,等效于将深队列削减为中浅队列,从而让公平性更容易得到保障。
最近搜集混部公平性数据,实际网络测试,20Gbps,RTT=80us,4 BBR vs. 4 CUBIC,交换机 10MB buffer,远大于 BDP,属深队列,配置尾丢时并没有展示出 CUBIC 压倒性优势,发现是 gain=125% probe 作祟,改经过 25MB buffer,问题消除,CUBIC 力压 BBR,配置 wRED,无论多大的 buffer,CUBIC 均无优势。得此分析。
浙江温州皮鞋湿,下雨进水不会胖。