目录
1.前言
2.什么是复杂度
3.如何计算时间复杂度
1.引例
2.二分查找
3.常见的复杂度
4.如何计算空间复杂度
5.关于递归
6.总结
1.前言
我们在做一些算法题时,经常会发现题目会对时间复杂度或者空间复杂度有所要求,如果你不知道什么是复杂度时,你可能就无法正确的完成题目。因此,我们在学习数据结构与算法的第一步,就是要理解什么是复杂度。
2.什么是复杂度
复杂度是衡量算法效率的标准,而算法分析效率分为两种:时间效率和空间效率。由此,复杂度也被分为两种:时间复杂度和空间复杂度。时间效率被称为时间复杂度, 而空间效率被称作空间复杂度。
时间复杂度主要衡量的是一个算法的运行速度。由于在不同的硬件上,程序运行的速度会有所不同,所以时间复杂度代表的并不是一个程序运行的时间,这并没有意义。而一个算法所花费的时间与其中语句的执行次数成正比,因此我们把算法中的基本操作的执行次数,称为算法的时间复杂度。
空间复杂度主要衡量一个算法所需要的额外空间。正如时间复杂度计算的不是时间,空间复杂度也不是计算程序占用了多少bytes的空间,因为这个也没太大意义,空间复杂度算的是变量的个数。
在计算机发展的早期,计算机的存储容量很小。所以对空间复杂度很是在乎。但是经过计算机行业的迅速发展,计算机的存储容量已经达到了很高的程度。 所以我们如今已经不需要再特别关注一个算法的空间复杂度。
3.如何计算时间复杂度
1.引例
我们来看下面一道题目:
// 请计算一下Func1基本操作执行了多少次?
void Func1(int N)
{
int count = 0;
for (int i = 0; i < N; ++i)
{
for (int j = 0; j < N; ++j)
{
++count;
}
}
for (int k = 0; k < 2 * N; ++k)
{
++count;
}
int M = 10;
while (M--)
{
++count;
}
printf("%d\n", count);
}我们通过分析得到Func1 执行的基本操作次数如下:
N = 10 ,F(N) = 130
N = 100 ,F(N) = 10210
N = 1000 ,F(N) = 1002010
显然如果直接用来表示时间复杂度的话会显得太过复杂。实际上我们发现随之N的不断增大,F(N)后续两项对结果的影响越来越小。因此我们在计算时间复杂度时,并不一定要计算精确的执行次数,只需求大概的执行次数,因此,就有了大O渐进表示法。
大O符号(Big O notation):是用于描述函数渐进行为的数学符号。
推导大O阶方法:
1、用常数1取代运行次数中的所有加法常数。
2、在修改后的运行次数函数中,只保留最高阶项。
3、如果最高阶项存在且不是1,则去除与这个项目相乘的常数。得到的结果就是大O阶。
例如上述代码的时间复杂度就是O(
),
几个小例子:
-------------------------------------------------->>> O(
)
---------------------------------------------->>> O(
)
------------------------------>>> O(
2.二分查找
下面是我们常见的一段二分查找代码,你能算出它的时间复杂度吗?
// 计算BinarySearch的时间复杂度?
int BinarySearch(int* a, int n, int x)
{
assert(a);
int begin = 0;
int end = n;
while (begin < end)
{
int mid = begin + ((end - begin) >> 1);
if (a[mid] < x)
begin = mid + 1;
else if (a[mid] > x)
end = mid;
else
return mid;
}
return -1;
}由于二分查找每次都能去掉一半的元素,因此其时间复杂度应是以2为底的对数.
但我们发现,在实际执行过程中,可能有三种情况:
1.运气极好,直接就找到,此时执行次数为1次
2.运气中等,找了一半才找到,此时执行次数为
次
3.运气极差,最后才找到,此时执行次数为
次
那我们是要以那种情况的执行次数作为标准来计算时间复杂度呢?其实我们在实际中一般情况关注的是算法的最坏运行情况,所以此二分查找算法的时间复杂度为O(
3.常见的复杂度
我们常见的复杂度有以下几种:
第一级:O(1),O(logn)
第二级:O(n),O(nlogn)
第三级:O(
),O(
),O(n!)
从上往下,从左到右,算法效率依次降低,下图为各种复杂度对于n的变化曲线:
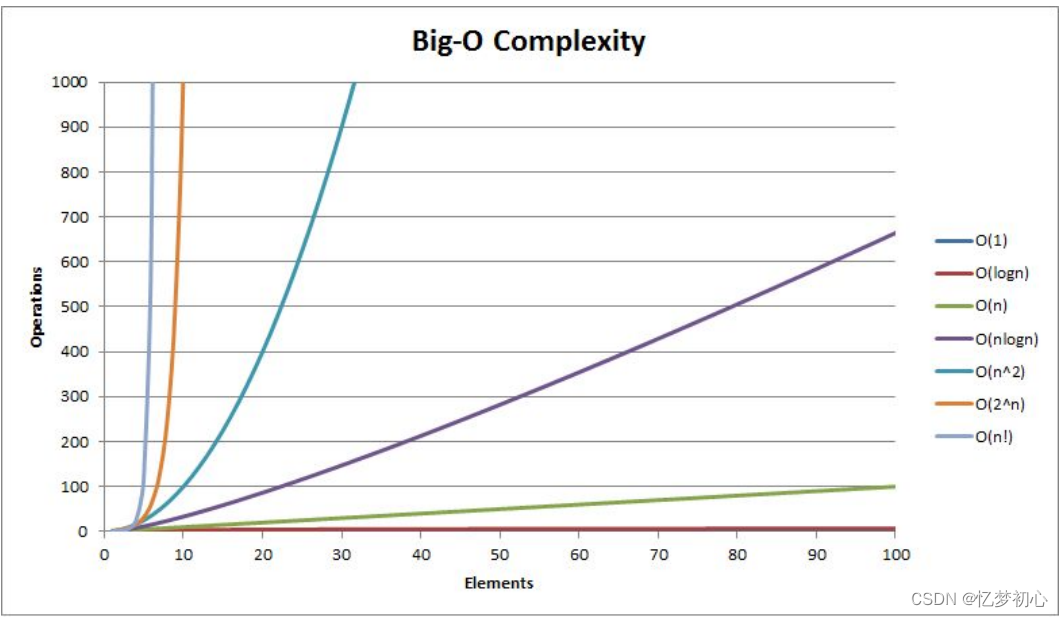
我们发现,O(logn)与O(1)十分的接近,几乎达到了常数级,远超于其他复杂度。
4.如何计算空间复杂度
一样的,我们通过小例题来入手:
// 计算Fibonacci的空间复杂度?
long long* Fibonacci(int n)
{
if (n == 0)
return NULL;
long long* fibArray = (long long*)malloc((n + 1) * sizeof(long long));
fibArray[0] = 0;
fibArray[1] = 1;
for (int i = 2; i <= n; ++i)
{
fibArray[i] = fibArray[i - 1] + fibArray[i - 2];
}
return fibArray;
}上面说到空间复杂度是统计变量的个数,因此通过分析得到Fibonacci() 创建的变量个数为:
其中,n+1为malloc在堆上申请的空间,1为在栈上开辟的空间i(此处我们不考虑形参)。与时间复杂度相同,为了表达方便,空间复杂度同样采用大O的渐进表示法,通过保留最高项,去除常数项,我们得到Fibonacci()函数的空间复杂度为O(n)。
5.关于递归
我们来分析斐波那契数列递归解法的时间复杂度和空间复杂度:
// 计算Fib的时间复杂度和空间复杂度?
int Fib(int n)
{
if (n == 1 || n == 2)
{
return 1;
}
else
{
return Fib(n - 1) + Fib(n - 2);
}
}我们知道,函数调用形成栈帧是需要成本,这个成本就体现在时间与空间上。(有关函数栈帧请点击传送门查看往期:C语言之函数栈帧(动图详解)) 。每一次函数调用,就会开辟空间,形成栈帧,消耗时间。直到函数调用结束返回,才会销毁栈帧,释放空间。我们画出递归树(假设n=6):

对于时间复杂度,Fib每次调用都会进行一次加法操作。因此,我们可以认为每个子结点代表一次基本操作,而高度为k的二叉树最多
个子结点(满二叉树)。于是我们得到基本操作次数
,其中n-1代表二叉树的高度。转化为时间复杂度则为O(
而对于空间复杂度,我们需要知道的是,函数栈帧会在函数调用完毕后销毁,释放空间。所以当其中一个分支到达递归尽头时,就会开始返回,此时空间会被释放。下次再调用函数时,就可以将释放的空间重复利用起来。因此,我们只需找到最长的分支有几个结点(即高度)就可以得到关系式
。转化为空间复杂度即为O(n)。
我们发现,用递归解决斐波那契数列是十分耗时的。其时间复杂度为O(),属于是指数级的时间复杂度,这是因为在递归时会进行多次重复调用计算,造成大量的时间浪费。因此,我们就可以使用动态规划的方法,通过创建一个数组(甚至只需要两个变量)来保存每次计算的结果(详情可见往期:C语言刷题之动态规划入门(二))。这种做法的时间复杂度为O(n),空间复杂度也为O(n),代码如下:
#include<stdio.h>
#include<stdlib.h>
int main()
{
int n = 0;
scanf("%d",&n);
//这里也可以只建立两个变量
int* dp=(int*)malloc(n*sizeof(int));
//对dp数组进行赋初值
dp[0] = 1;
dp[1] = 1;
for (int i = 2; i < n; i++) //遍历dp数组
{
dp[i] = dp[i - 1] + dp[i - 2]; //递推公式
}
printf("%d",dp[n-1]);
free(dp);
dp=NULL;
return 0;
}6.总结
1.时间复杂度计算的是基本操作执行次数,空间复杂度计算的是变量的个数,二者都采用大O渐进表示法。
2.时间/空间复杂度都是在最坏情况下所得到的。
3.时间一去不复返,是累积的;而空间是可以释放并重复利用的,是不累积的。
以上,就是本期的全部内容。
制作不易,能否点个赞再走呢qwq