Python信用卡欺诈检测 [TensorFlow]
提示:前言
Python ·信用卡欺诈检测
提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- Python信用卡欺诈检测 [TensorFlow]
- 前言
- 一、导入包
- 二、加载数据
- 三、加载数据
- 四、 定义模型架构和适当的损失函数和指标
- 五、使用 validation_split = 0.26 训练模型
- 六、获取特征重要性
- 七、对 X_test 的预测
前言
提示:大概内容:
觉得有用请不要忘记点赞👆 😃
重要的是,信用卡公司能够识别欺诈性信用卡交易,这样客户就不会为他们没有购买的商品付费。
关于数据集
该数据集包含 2013 年 9 月欧洲持卡人使用信用卡进行的交易。
该数据集显示了两天内发生的交易,其中 284,807 笔交易中有 492 笔欺诈。
数据集高度不平衡,正类(欺诈)占所有交易的 0.172%。
它仅包含作为 PCA 转换结果的数字输入变量。
特征 V1、V2、… V28 是通过 PCA 获得的主成分
唯一没有用 PCA 转换的特征是时间和数量。
特征时间包含每个事务与数据集中第一个事务之间经过的秒数。
特征金额为交易金额,该特征可用于依赖实例的成本敏感学习。
要素类是响应变量,在欺诈情况下取值 1,否则取 0。
提示:以下是本篇文章正文内容,下面案例可供参考
一、导入包
import tensorflow as tf
from keras.models import Sequential
from keras.layers import Dense,Dropout, BatchNormalization
from keras import regularizers
import numpy as np
import pandas as pd
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OneHotEncoder
from sklearn.preprocessing import RobustScaler
二、加载数据
阅读此链接上可用的原始数据集(作为数据框)
https://www.kaggle.com/datasets/mlg-ulb/creditcardfraud.
original_df = pd.read_csv('/kaggle/input/creditcardfraud/creditcard.csv')
original_df.info()
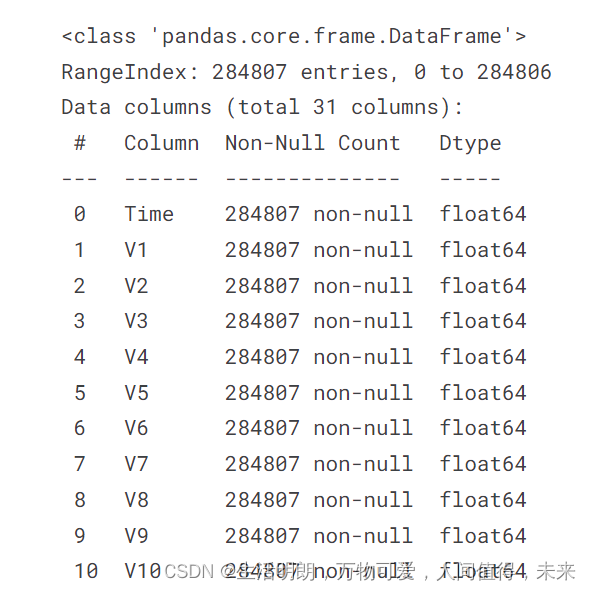
为比赛提供的数据集在 train_df 和 test_df 数据框中导入
train_df = pd.read_csv('/kaggle/input/playground-series-s3e4/train.csv')
train_df = pd.concat([train_df,original_df])
train_df = train_df.sample(frac=1)
train_df = train_df.reset_index(drop=True)
y_train = train_df['Class']
train_df.head()

test_df = pd.read_csv('/kaggle/input/playground-series-s3e4/test.csv')
test_df_id = test_df['id']
test_df.head()

train_df.columns

train_df.describe()

三、加载数据
存储用于缩放各个值的数字列
train_to_scale = train_df[['Time', 'V1', 'V2', 'V3', 'V4', 'V5', 'V6', 'V7', 'V8', 'V9',
'V10', 'V11', 'V12', 'V13', 'V14', 'V15', 'V16', 'V17', 'V18', 'V19',
'V20', 'V21', 'V22', 'V23', 'V24', 'V25', 'V26', 'V27', 'V28', 'Amount']]
test_to_scale = test_df[['Time', 'V1', 'V2', 'V3', 'V4', 'V5', 'V6', 'V7', 'V8', 'V9',
'V10', 'V11', 'V12', 'V13', 'V14', 'V15', 'V16', 'V17', 'V18', 'V19',
'V20', 'V21', 'V22', 'V23', 'V24', 'V25', 'V26', 'V27', 'V28', 'Amount']]
scaler = RobustScaler()
scaled_train = pd.DataFrame(scaler.fit_transform(train_to_scale),columns = train_to_scale.columns)
scaled_test = pd.DataFrame(scaler.transform(test_to_scale),columns = test_to_scale.columns)
X_train = scaled_train
X_test = scaled_test
四、 定义模型架构和适当的损失函数和指标
model = Sequential()
# Add layers to the model
model.add(Dense(8116, input_dim=30, activation='selu')) #input layer with 64 neurons
model.add(Dropout(0.5))
model.add(Dense(2048,activation= 'relu'))
model.add(Dropout(0.5))
model.add(Dense(1024,activation= 'selu'))
model.add(Dropout(0.5))
model.add(Dense(256,activation = 'relu'))
model.add(Dropout(0.5))
model.add(Dense(128,activation = 'selu'))
model.add(Dense(8,activation= 'relu'))
model.add(Dense(1, activation='sigmoid')) #output layer with 1 neuron
model.compile(loss=['binary_crossentropy'], optimizer= tf.keras.optimizers.Adam(4e-5),metrics = [tf.keras.metrics.AUC(num_thresholds=700000,curve='ROC')])
model.summary()

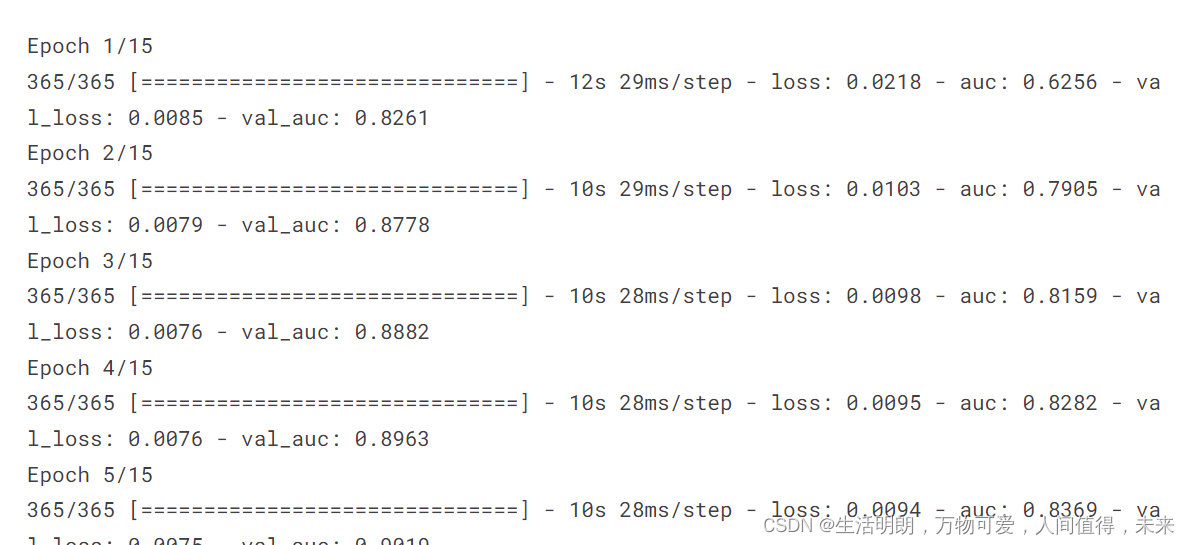
五、使用 validation_split = 0.26 训练模型
model.fit(X_train,y_train,validation_split = 0.26,batch_size = 1024,epochs = 15)#,callbacks=[callbacks])
六、获取特征重要性
# Get the weights of the first layer
weights = model.layers[0].get_weights()[0]
# Get the absolute values of the weights
importances = np.abs(weights)
# Normalize the importances
importances = importances / importances.sum(axis=0)
# Print the importances of each feature
for i, importance in enumerate(importances):
print("Feature", i, "Importance", np.median(importance))
七、对 X_test 的预测
y_pred = model.predict(X_test)
print(y_pred)
以要求的格式转换 DataFrame 以提交给比赛
y_pred = pd.DataFrame(y_pred)
y_pred.columns = ['Class']
submissions_df = pd.DataFrame(pd.concat([test_df_id,y_pred],axis = 1))
submissions_df = submissions_df.reset_index(drop = True)
submissions_df.to_csv('submission.csv', index=False)
submissions_df.head()
提示:这里对文章进行总结:
以上就是今天要讲的内容





![LeetCode[990]等式方程式的可满足性](https://img-blog.csdnimg.cn/img_convert/4824c9e643c94d0badf9160c454866a8.png)



![LeetCode[200]岛屿数量](https://img-blog.csdnimg.cn/img_convert/75f3b89e5c8442b8aaecf9bd66673039.png)