目录
一:Stream流中的结果到集合中
二:Stream流中的结果到数组中
三:对流中数据进行聚合计算
四:对流中数据进行分组
五:对流中数据进行多级分组
六:对流中数据进行分区
七:对流中数据进行拼接
小结:
对流操作完成之后,如果需要将流的结果保存到数组或集合中,可以收集流中的数据
一:Stream流中的结果到集合中
Stream
流提供
collect
方法,其参数需要一个
java.util.stream.Collector<T,A, R>
接口对象来指定收集到哪种集合中。java.util.stream.Collectors
类提供一些方法,可以作为
Collector`
接口的实例:
- public static <T> Collector<T, ?, List<T>> toList() :转换为 List 集合。
- public static <T> Collector<T, ?, Set<T>> toSet() :转换为 Set 集合。
下面是这两个方法的基本使用代码:
// 将流中数据收集到集合中
@Test
public void testStreamToCollection() {
Stream<String> stream = Stream.of("aa", "bb", "cc", "bb");
// 将流中数据收集到集合中
// collect收集流中的数据到集合中
// List<String> list = stream.collect(Collectors.toList());
// System.out.println("list = " + list);
// Set<String> set = stream.collect(Collectors.toSet());
// System.out.println("set = " + set);
// 收集到指定的集合中ArrayList
// ArrayList<String> arrayList = stream.collect(Collectors.toCollection(ArrayList::new));
// System.out.println("arrayList = " + arrayList);
HashSet<String> hashSet = stream.collect(Collectors.toCollection(HashSet::new));
System.out.println("hashSet = " + hashSet);
}
二:Stream流中的结果到数组中
Stream
提供
toArray
方法来将结果放到一个数组中,返回值类型是
Object[]
的:
Object[] toArray();
其使用场景如:
// 将流中数据收集到数组中
@Test
public void testStreamToArray() {
Stream<String> stream = Stream.of("aa", "bb", "cc");
// 转成Object数组不方便
// Object[] objects = stream.toArray();
// for (Object o : objects) {
// System.out.println("o = " + o);
// }
// String[]
String[] strings = stream.toArray(String[]::new);
for (String string : strings) {
System.out.println("string = " + string + ", 长度: " + string.length());
}
}
三:对流中数据进行聚合计算
当我们使用
Stream
流处理数据后,可以像数据库的聚合函数一样对某个字段进行操作。比如获取最大值,获取最小值,求总和,平均值,统计数量。
// 其他收集流中数据的方式(相当于数据库中的聚合函数)
@Test
public void testStreamToOther() {
Stream<Student> studentStream = Stream.of(
new Student("赵丽颖", 58, 95),
new Student("杨颖", 56, 88),
new Student("迪丽热巴", 56, 99),
new Student("柳岩", 52, 77));
// 获取最大值
// Optional<Student> max = studentStream.collect(Collectors.maxBy((s1, s2) -> s1.getSocre() - s2.getSocre()));
// System.out.println("最大值: " + max.get());
// 获取最小值
// Optional<Student> min = studentStream.collect(Collectors.minBy((s1, s2) -> s1.getSocre() - s2.getSocre()));
// System.out.println("最小值: " + min.get());
// 求总和
// Integer sum = studentStream.collect(Collectors.summingInt(s -> s.getAge()));
// System.out.println("总和: " + sum);
// 平均值
// Double avg = studentStream.collect(Collectors.averagingInt(s -> s.getSocre()));
// Double avg = studentStream.collect(Collectors.averagingInt(Student::getSocre));
// System.out.println("平均值: " + avg);
// 统计数量
Long count = studentStream.collect(Collectors.counting());
System.out.println("统计数量: " + count);
}四:对流中数据进行分组
当我们使用
Stream
流处理数据后,可以根据某个属性将数据分组:
// 分组
@Test
public void testGroup() {
Stream<Student> studentStream = Stream.of(
new Student("赵丽颖", 52, 95),
new Student("杨颖", 56, 88),
new Student("迪丽热巴", 56, 55),
new Student("柳岩", 52, 33));
// Map<Integer, List<Student>> map = studentStream.collect(Collectors.groupingBy(Student::getAge));
// 将分数大于60的分为一组,小于60分成另一组
Map<String, List<Student>> map = studentStream.collect(Collectors.groupingBy((s) -> {
if (s.getSocre() > 60) {
return "及格";
} else {
return "不及格";
}
}));
map.forEach((k, v) -> {
System.out.println(k + "::" + v);
});
}输出结果:

不及格::[Student{name='迪丽热巴', age=56, socre=55}, Student{name='柳岩', age=52, socre=33}]
及格::[Student{name='赵丽颖', age=52, socre=95}, Student{name='杨颖', age=56, socre=88}]五:对流中数据进行多级分组
还可以对数据进行多级分组:
// 多级分组
@Test
public void testCustomGroup() {
Stream<Student> studentStream = Stream.of(
new Student("赵丽颖", 52, 95),
new Student("杨颖", 56, 88),
new Student("迪丽热巴", 56, 55),
new Student("柳岩", 52, 33));
// 先根据年龄分组,每组中在根据成绩分组
// groupingBy(Function<? super T, ? extends K> classifier, Collector<? super T, A, D> downstream)
Map<Integer, Map<String, List<Student>>> map = studentStream.collect(Collectors.groupingBy(Student::getAge, Collectors.groupingBy((s) -> {
if (s.getSocre() > 60) {
return "及格";
} else {
return "不及格";
}
})));
// 遍历
map.forEach((k, v) -> {
System.out.println(k);
// v还是一个map,再次遍历
v.forEach((k2, v2) -> {
System.out.println("\t" + k2 + " == " + v2);
});
});
}
效果:
52 == {不及格=[Student{name='柳岩', age=52, socre=77}], 优秀=[Student{name='赵丽颖', age=52,
socre=95}]}
56 == {优秀=[Student{name='迪丽热巴', age=56, socre=99}], 良好=[Student{name='杨颖', age=56,
socre=88}]}六:对流中数据进行分区
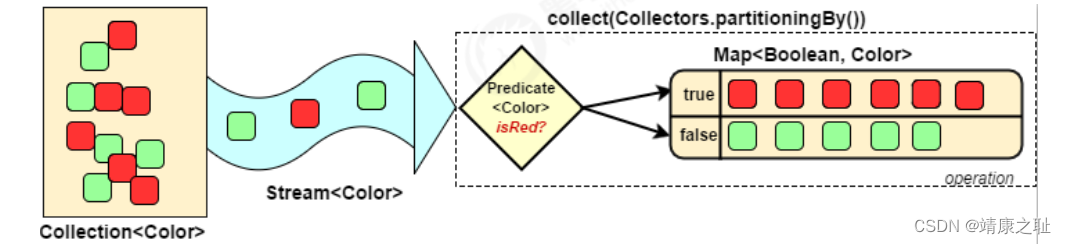
Collectors.partitioningBy
会根据值是否为
true
,把集合分割为两个列表,一个
true
列表,一个
false
列表。
// 分区
@Test
public void testPartition() {
Stream<Student> studentStream = Stream.of(
new Student("赵丽颖", 52, 95),
new Student("杨颖", 56, 88),
new Student("迪丽热巴", 56, 55),
new Student("柳岩", 52, 33));
Map<Boolean, List<Student>> map = studentStream.collect(Collectors.partitioningBy(s -> {
return s.getSocre() > 60;
}));
map.forEach((k , v) -> {
System.out.println(k + " :: " + v);
});
}
效果:
false == [Student{name='杨颖', age=56, socre=88}, Student{name='柳岩', age=52, socre=77}]
true == [Student{name='赵丽颖', age=52, socre=95}, Student{name='迪丽热巴', age=56, socre=99}]七:对流中数据进行拼接
Collectors.joining
会根据指定的连接符,将所有元素连接成一个字符串。
// 拼接
@Test
public void testJoining() {
Stream<Student> studentStream = Stream.of(
new Student("赵丽颖", 52, 95),
new Student("杨颖", 56, 88),
new Student("迪丽热巴", 56, 99),
new Student("柳岩", 52, 77));
// 根据一个字符串拼接: 赵丽颖__杨颖__迪丽热巴__柳岩
// String names = studentStream.map(Student::getName).collect(Collectors.joining("__"));
// 根据三个字符串拼接
String names = studentStream.map(Student::getName).collect(Collectors.joining("__", "^_^", "V_V"));
System.out.println("names = " + names);
}
效果:
^_^赵丽颖>_<杨颖>_<迪丽热巴>_<柳岩^v^小结:
- 收集Stream流中的结果
- 到集合中: Collectors.toList()/Collectors.toSet()/Collectors.toCollection()
- 到数组中: toArray()/toArray(int[]::new)
- 聚合计算:
- Collectors.maxBy/Collectors.minBy/Collectors.counting/Collectors.summingInt/Collectors.averagingInt
- 分组: Collectors.groupingBy
- 分区: Collectors.partitionBy
- 拼接: Collectors.joinging