一、函数数据处理
1.在dataframe中使用apply方法,调用自定义函数对数据进行处理
2.可以使用astype函数对数据进行转换
3.可以使用map函数进行数据转换

二、数据分组运算
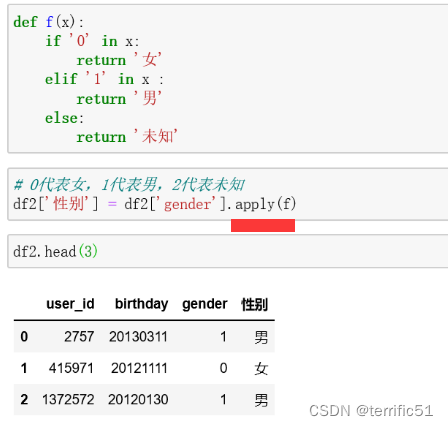
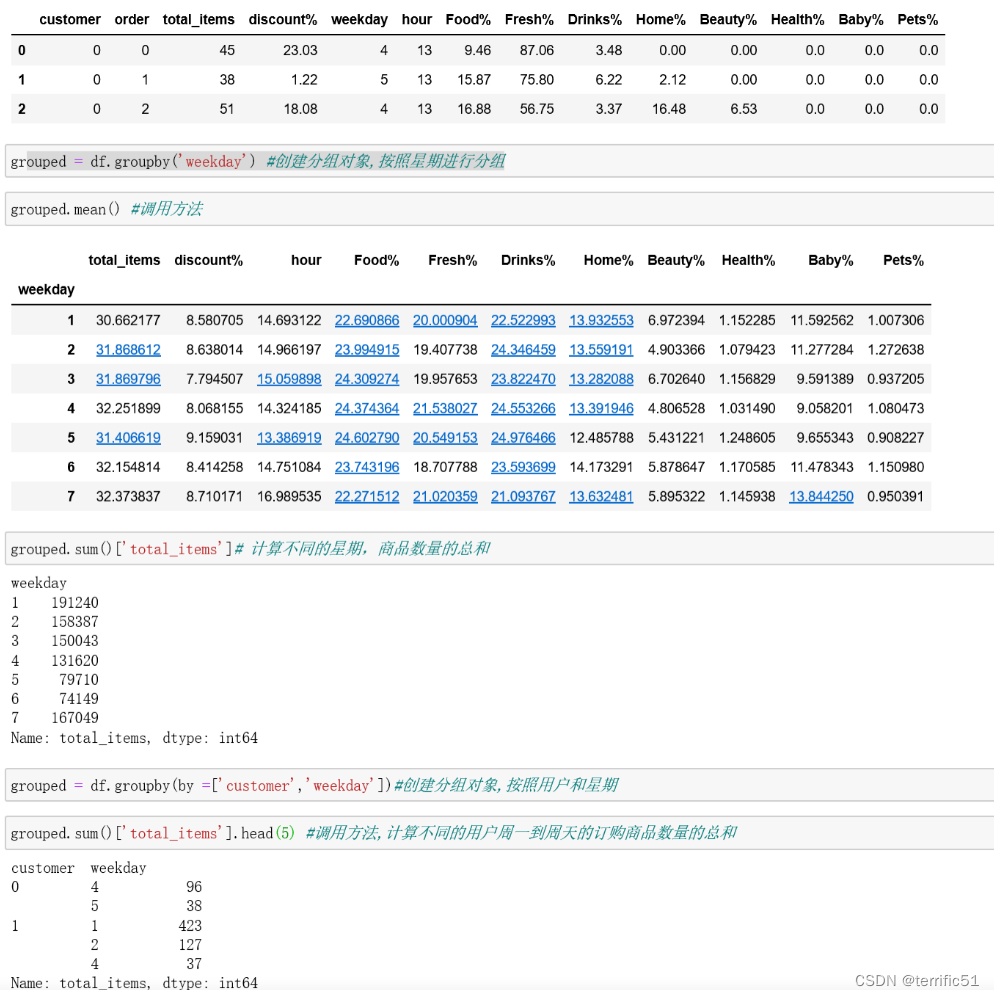
1.使用groupby方法进行分组计算,得到分组对象GroupBy

2.语法为df.groupby(by=)

3.分组对象GroupBy可以运用描述性统计方法, 如count、mean 、median 、max和min等
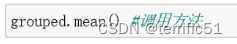
三、聚合函数使用
1.对分组对象使用agg聚合函数
2.Groupby.agg(func)
3.针对不同的变量使用不同的统计方法

四、透视表与交叉表
1.数据透视表
pivot_table( data, index, columns,values, aggfunc, fill_value,margins, margins_name=)
Index : 行分组键
columns: 列分组键
values: 分组的字段,只能为数值型变量
aggfunc: 聚合函数
margins: 是否需要总计

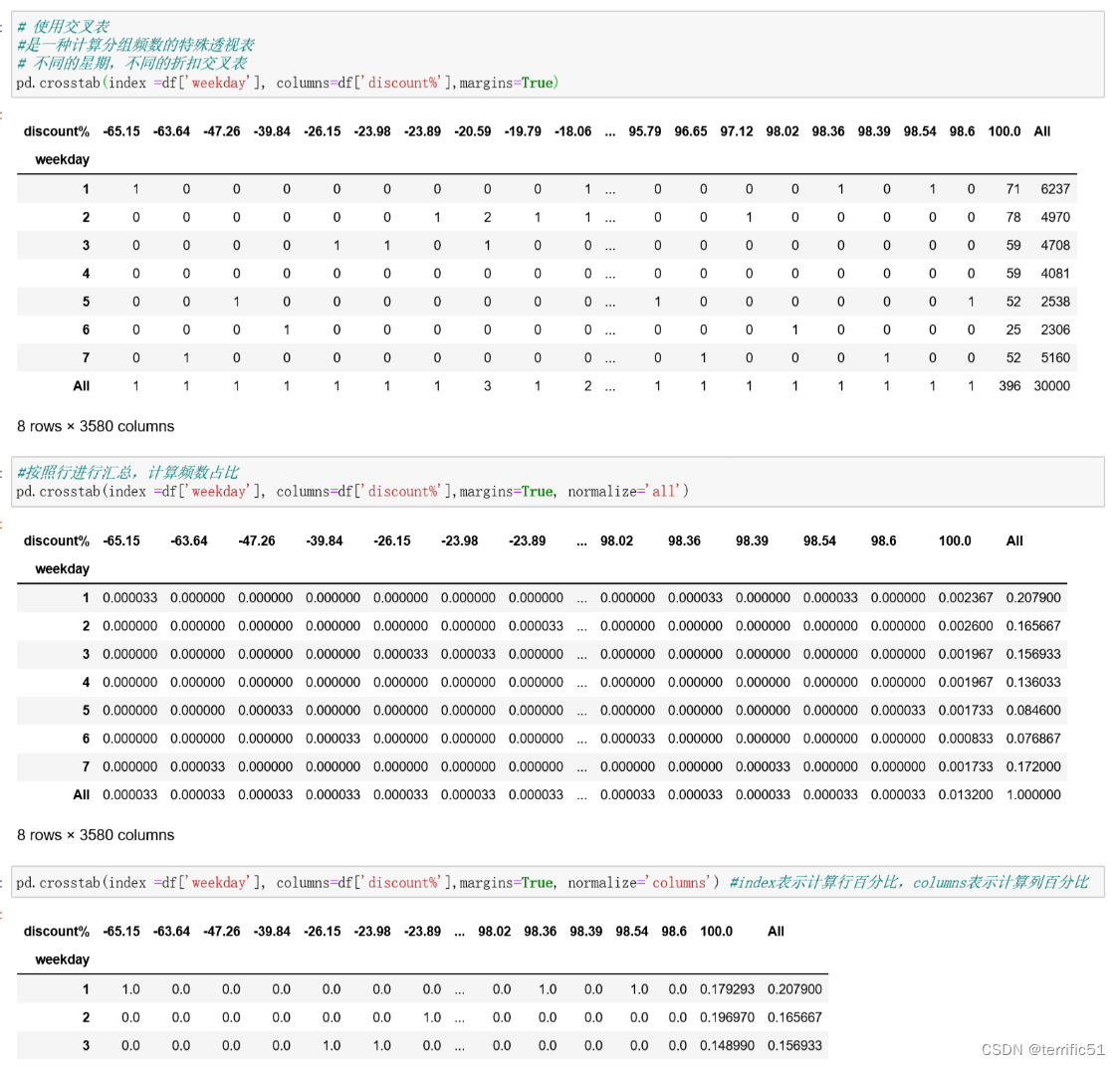
2.交叉表
pd.crosstab(index,columns,normalize)
Index: 行索引
Columns: 列索引
Normalize: 数据对数据进行标准化,index表示行,column表示列
五、数据预处理
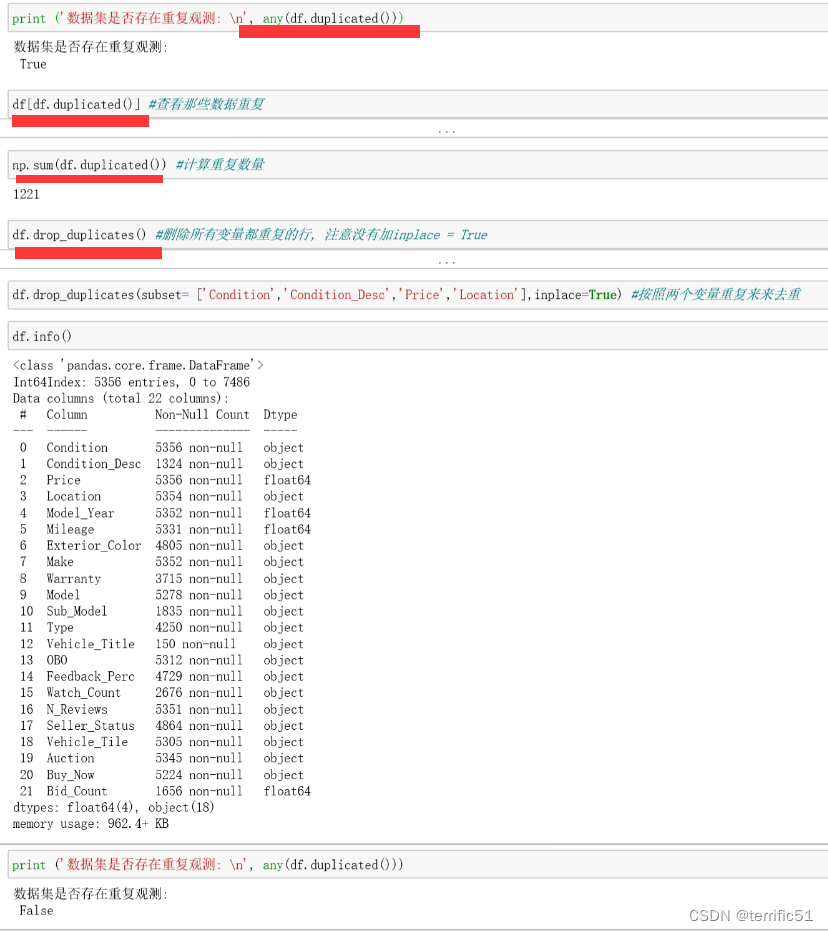
5.1重复值处理
数据清洗一般先从重复值和缺失值开始处理,重复值一般采取删除法来处理。但有些重复值不能删除,例如订单明细数据或交易明细数据等。
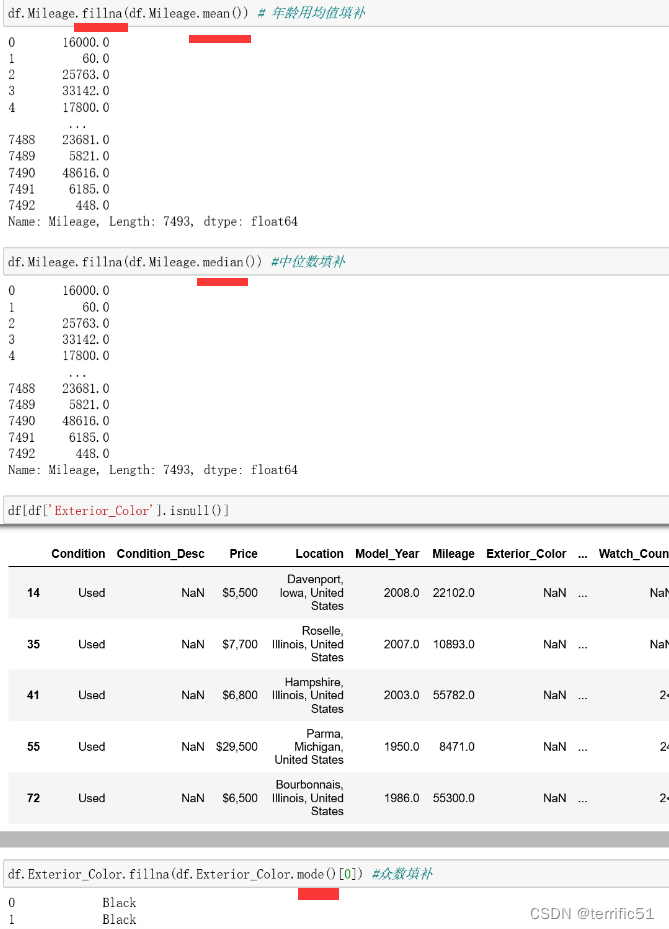
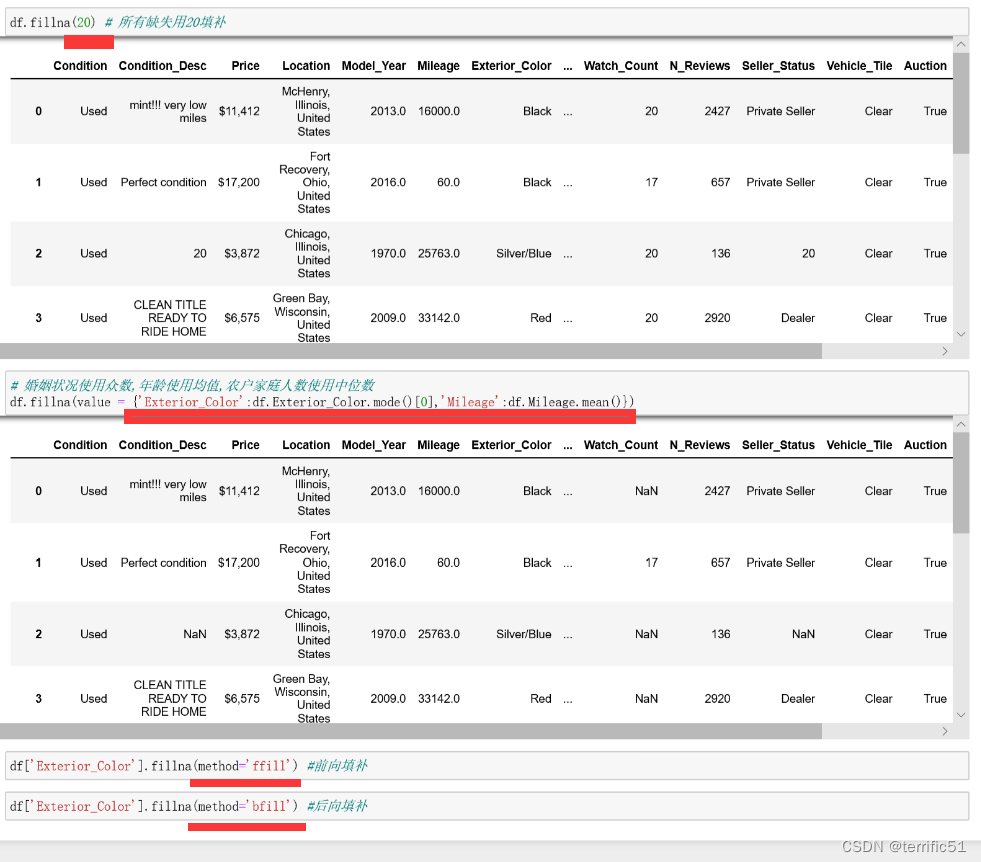
5.2缺失值处理
缺失值首先需要根据实际情况定义,可以采取直接删除法;有时候需要使用替换法或者插值法;常用的替换法有均值替换、前向、后向替换和常数替换。
- 删除

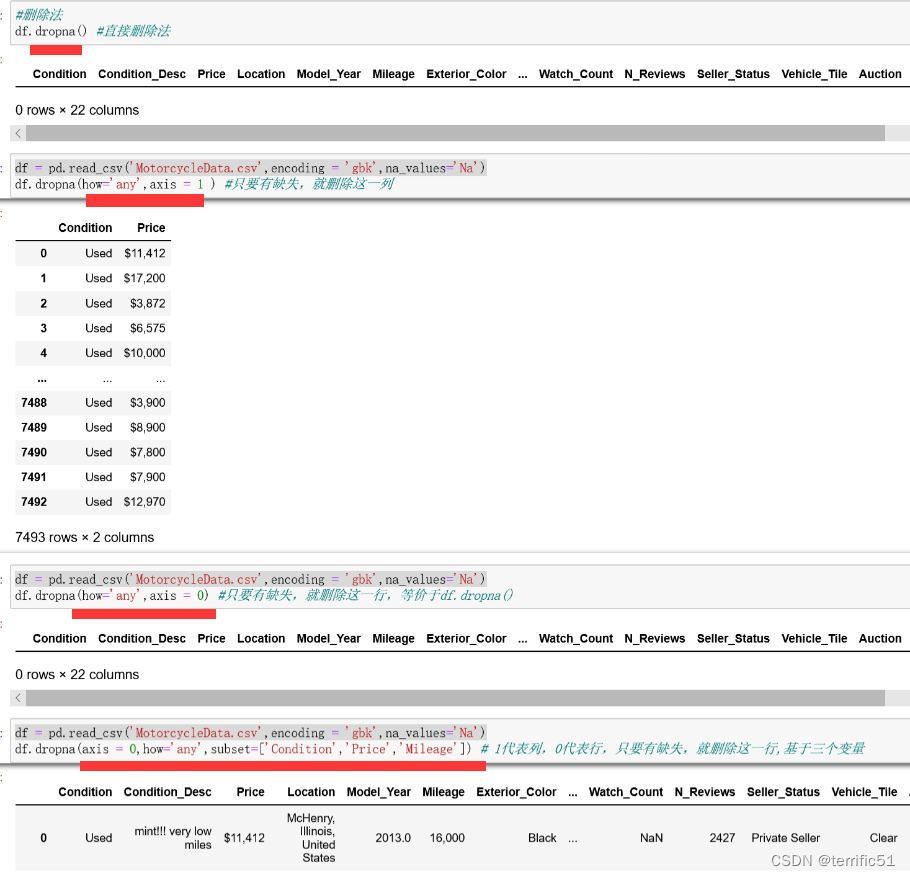
- 替换
5.3异常值处理
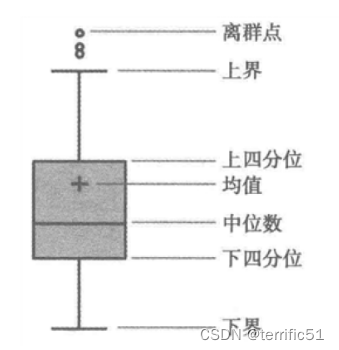
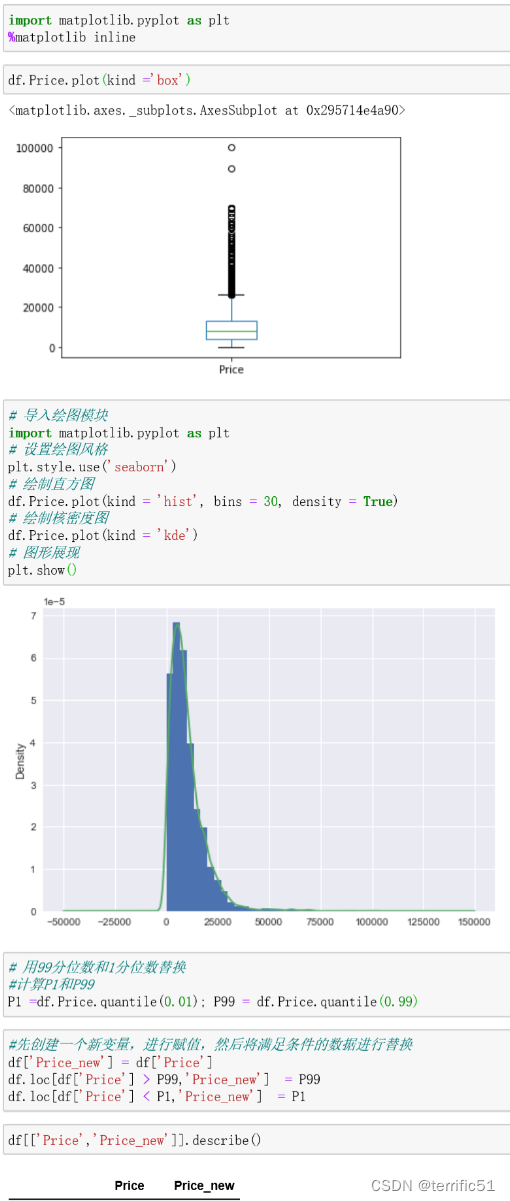
指那些偏离正常范围的值,不是错误值;异常值一般用**过箱线图法(分位差法)**或者分布图(标准差法)来判断;异常值往往采取盖帽法或者数据离散化。

六、数据离散化处理
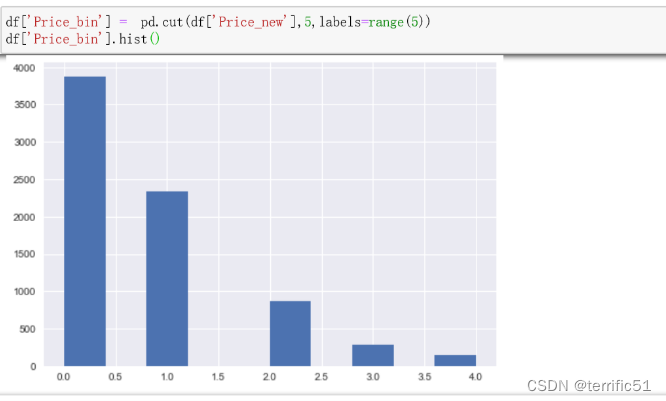
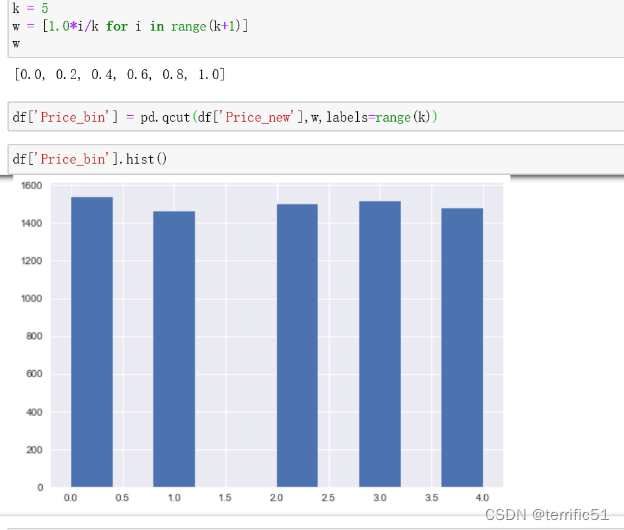
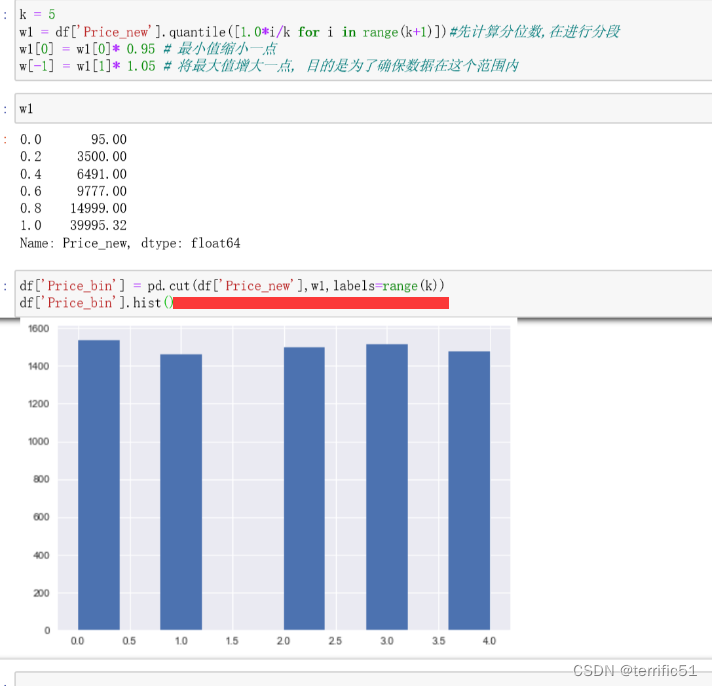
数据离散化就是分箱,一般常用分箱方法是等频分箱或者等宽分箱,一般使用pd.cut或者pd.qcut函数。
- pandas.cut(x, bins, right=True, labels=None, retbins=False, precision=3, include_lowest=False)
x,类array对象,且必须为一维,待切割的原形式
bins, 整数、序列尺度、或间隔索引。如果bins是一个整数,它定义了x宽度范围内的等宽面元数量,
但是在这种情况下,x的范围在每个边上被延长1%,以保证包括x的最小值或最大值。
如果bin是序列,它定义了允许非均匀bin宽度的bin边缘。在这种情况下没有x的范围的扩展。
right,布尔值。是否是左开右闭区间,right=True,左开右闭,right=False,左闭右开
labels,用作结果箱的标签。必须与结果箱相同长度。如果FALSE,只返回整数指标面元。
retbins,布尔值。是否返回面元
precision,整数。返回面元的小数点几位
include_lowest,布尔值。第一个区间的左端点是否包含
- pandas.qcut(x, q, labels=None, retbins=False, precision=3, duplicates=’raise’)
x
q,整数或分位数组成的数组。
q, 整数 或分位数数组 整数比如 4 代表 按照4分位数 进行切割
labels, 用作结果箱的标签。必须与结果箱相同长度。如果FALSE,只返回整数指标面元。

七、总结
- 步骤
1.数据获取,使用read_csv或者read_excel
2.数据探索,使用shape,describe或者info函数
3.行列操作,使用loc或者iloc函数
4.数据整合,对不同数据源进行整理
5.数据类型转换,对不同字段数据类型进行转换
6.分组汇总,对数据进行各个维度的计算
7.处理重复值、缺失值和异常值以及数据离散化 - 函数
1.merge,concat函数常常用于数据整合
2.pd.to_datetime常常用于日期格式转换
3.str函数用于字符串操作
4.函数astype用于数据类型转换
5.函数apply和map用于更加高级的数据处理
6.Groupby用于创建分组对象
7.透视表函数pd.pivot_table和交叉表pd.crosstab
8.分组对象和agg结合使用,统计需要的信息