Xgboost简介
XGBoost是陈天奇等人开发的一个开源机器学习项目,高效地实现了GBDT算法并进行了算法和工程上的许多改进,被广泛应用在Kaggle竞赛及其他许多机器学习竞赛中并取得了不错的成绩。XGBoost本质上还是一个GBDT,但是力争把速度和效率发挥到极致,所以叫X (Extreme) GBoosted。XGBoost是一个优化的分布式梯度增强库,旨在实现高效,灵活和便携。 它在Gradient Boosting框架下实现机器学习算法。 XGBoost提供了并行树提升(也称为GBDT,GBM),可以快速准确地解决许多数据科学问题。在数据科学方面,有大量的Kaggle选手选用XGBoost进行数据挖掘比赛,是各大数据科学比赛的必杀武器;在工业界大规模数据方面,XGBoost的分布式版本有广泛的可移植性,支持在Kubernetes、Hadoop、SGE、MPI、 Dask等各个分布式环境上运行,使得它可以很好地解决工业界大规模数据的问题。XGBoost利用了核外计算并且能够使数据科学家在一个主机上处理数亿的样本数据。最终,将这些技术进行结合来做一个端到端的系统以最少的集群系统来扩展到更大的数据集上。Xgboost以CART决策树为子模型,通过Gradient Tree Boosting实现多棵CART树的集成学习,得到最终模型。
Xgboost原理
从目标函数生成一颗树
XGBoost和GBDT两者都是boosting方法,boosting方法实际采用加法模型,(基函数线性组合)与前向分布算法,XGBoost与GBDT除了工程上的实现,解决问题上的一些差异外,最大的不同都是目标函数的定义,因此,我们从目标函数开始研究Xgboost的基本原理:
学习第t棵树
XGBoost由K个基模型组成的一个加法模型,假设我们第
t
t
t次迭代要训练的树模型是
f
t
(
x
)
f_t(x)
ft(x),则有:L

Xgboost的目标函数
损失函数可有预测值
y
i
^
\hat{y_i}
yi^与真实值
y
i
y_i
yi进行比较:
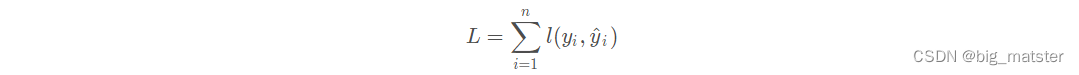
其中
n
n
n为样本数量。
模型的预测精度有模型的偏差和方差共同决定。损失函数代表了模型的偏差,想要方差小则需要在目标函数中添加正则项,用于防止过拟合。
所以,目标函数由模型的损失函数
L
L
L与抑制模型复杂度的
Ω
Ω
Ω组成,目标函数定义如下:
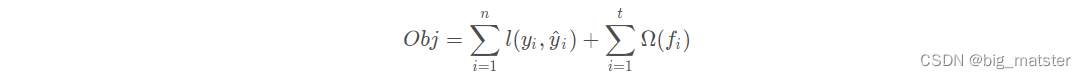
其中
∑
i
=
1
t
Ω
(
f
i
)
\sum^t_{i = 1}Ω(f_i)
∑i=1tΩ(fi)是将全部
t
t
t棵树的复杂度进行求和。添加到目标函数作为正则项,用于防止模型过拟合。
由于xgboost是boosting方法,实际上采用了加法模型和前方分布算法,以第
t
t
t个模型为例,模型对第
i
i
i个样本的
x
i
x_i
xi的预测值为:
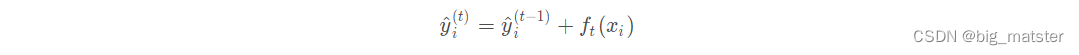
其中
y
i
t
−
1
^
\hat{y^{t - 1}_i}
yit−1^是
t
−
1
t - 1
t−1个模型给出的预测值,是已知常数,
f
t
(
x
i
)
f_t(x_i)
ft(xi)是第
t
t
t个模型的预测值,此时,目标函数写成:
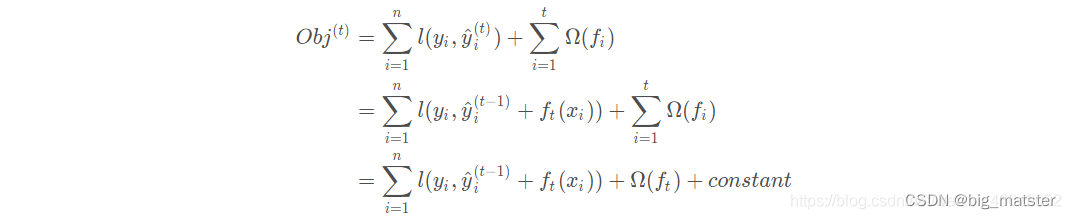

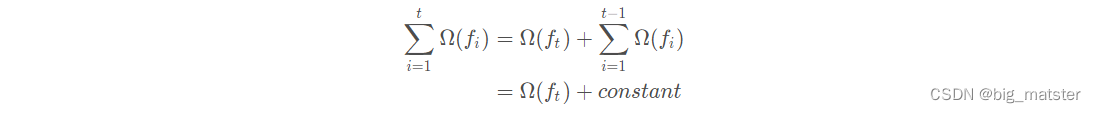
泰勒公式展开




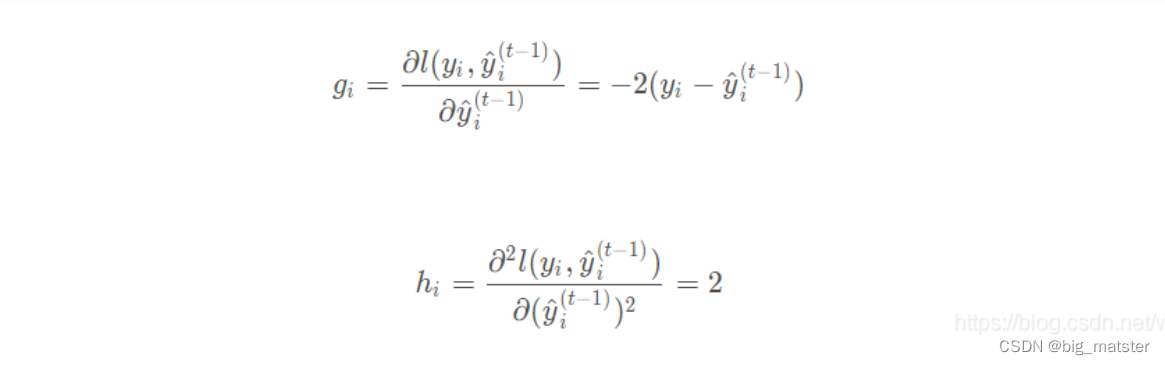


定义一颗树
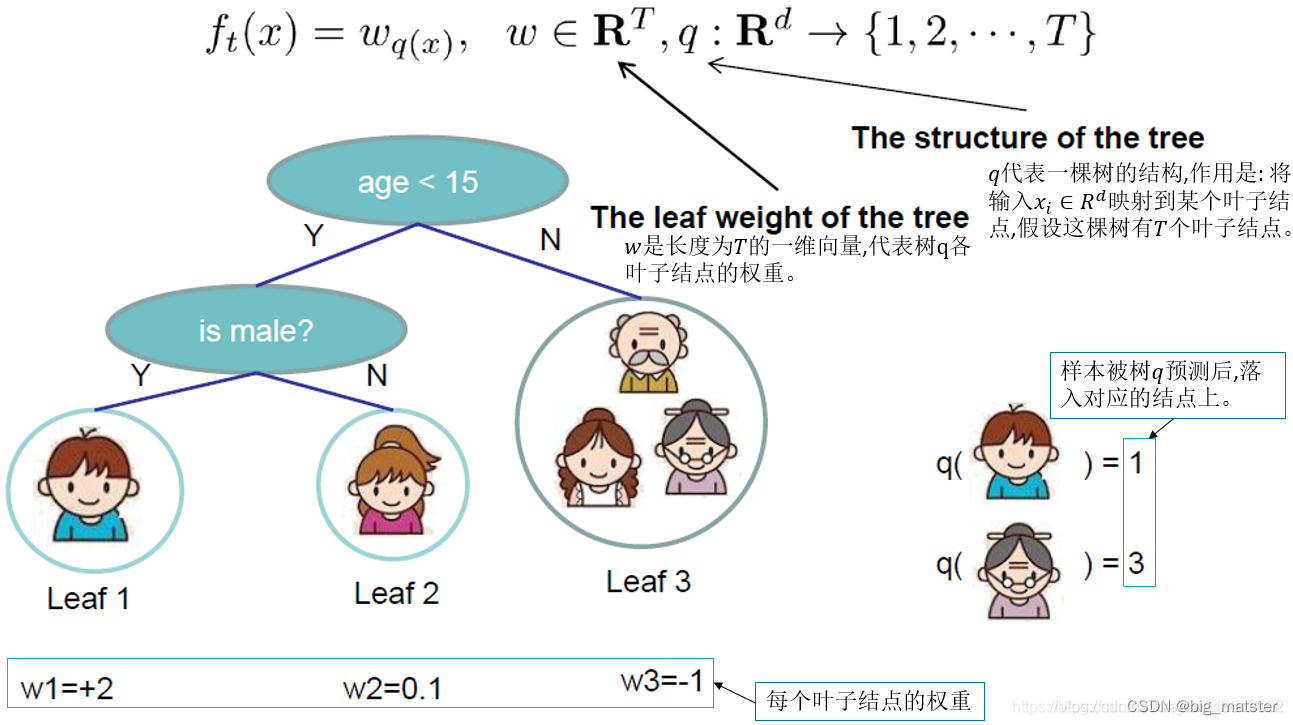
我们清楚XGBoost基模型不仅支持决策树,还支持线性模型,本章主要介绍基于决策树的目标函数,我们可以重新定义一颗决策树,其包含两个部分:
- 叶子节点的权重向量 w w w
- 实例(样本)到叶子节点的映射关系
q
q
q(本质是数的分支结构)
-
总结
- 几个弱分类器进行堆叠,然后利用泰勒展开公式进行求导,求出梯度值都行啦的回事与打算。
-
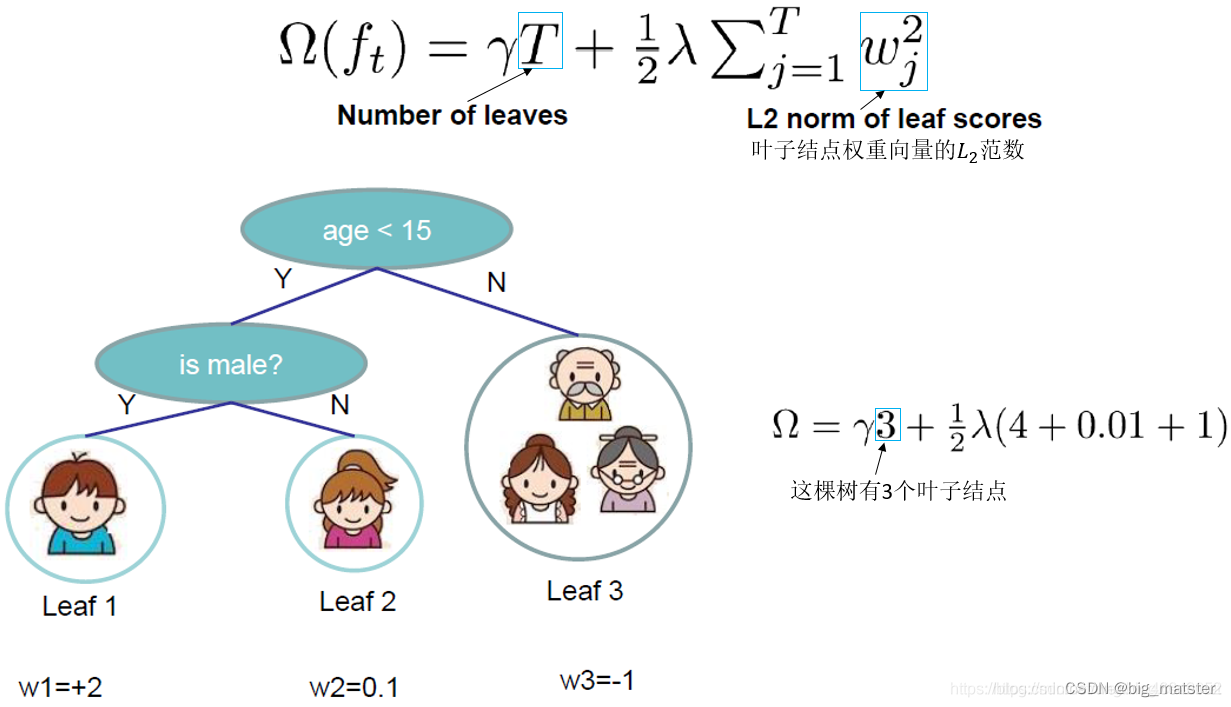
定义树的复杂度
- 决策树的复杂度
Ω
\Omega
Ω 可由叶子数
T
T
T 组成,叶子节点越少模型越简单,此外叶子节点也不应该含有过高的权重
w
w
w(类比 LR 的每个变量的权重),所以目标函数的正则项由生成的所有决策树的叶子节点数量,和所有节点权重所组成的向量的
L
2
L 2
L2范式共同决定。
叶子节点归组

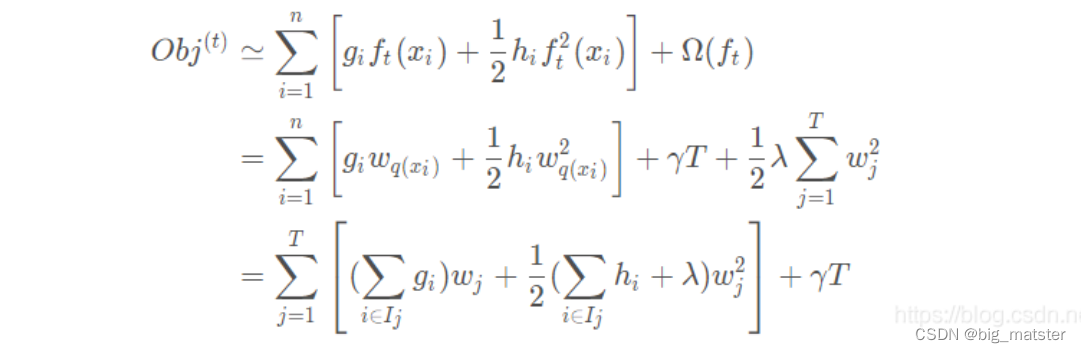



贪心算法
从树的深度为0开始:
- 对每个叶结点枚举所有可用特征。
- 针对每个特征,把属于该结点的训练样本根据该特征值进行升序排列,通过线性扫描的方法来决定该特征的最佳分裂点,并记录该特征的分裂收益。
- 选择受益最大的特征作为分裂特征**,用改特征的最佳分裂点作为分裂位置**。在改结点上分类出左右两个新结点,并为每个新结点关联对应的样本集。
- 回到第一步,递归执行直到满足特定条件为止。

总结
-
慢慢的将各种的算法全部搞定,先根据项目进行学习Xgboost算法,后续在继续深入研究其他的 算法。
-
后续其他算法,以后再开始学习,都行啦的样子与打算,慢慢的将各种算法都搞定,全部都研究透彻。
-
先大致了解,后续再根据项目深入研究。