CSDN 的研发团队每隔一段时间会和大家分享团队的进展,请看:
2021 年年底的汇报
2022 年上半年的汇报
2022 年下半年的汇报
从上面的报告中大家可以看到,我们在取得进展的同时, 也碰到了很多问题,也有一些困惑。 我写了软件开发中的感性和理性决定,也写了如何对待错误,用正确的方法来分析问题,改进产品。 理论讲了很多,来点实际的例子吧! 这篇博客,就讲讲我们 CSDN 目前是如何处理故障的。
用户感性的诉求
在这个博客中,我就把我们质量管理的内部总结中关于 故障处理 的典型事例分享一下。 首先,CSDN 服务的可用性还是非常高的,但是,作为一个有众多业务,流量名列全世界 top 30 的网站,时不时我们就能看到用户着急忙慌的抱怨:
用户在声情并茂地投诉,我们技术人员怎么办?用户说 ‘崩了’, 是什么原因? 用户联网问题,DNS 问题,网站收到黑客攻击 (这发生了好几次),还是CSDN 内部的问题? 要快速解决问题, 还是要依靠理性的、系统化的流程,和技术人员过硬的技术和冷静的头脑。
理性的处理流程
首先,是定义故障的等级。 CSDN 面向用户的业务真不少,一个“故障” 有哪些方面?我们如何综合评价一个故障的的严重程度? 我们定义了下面的权重体系: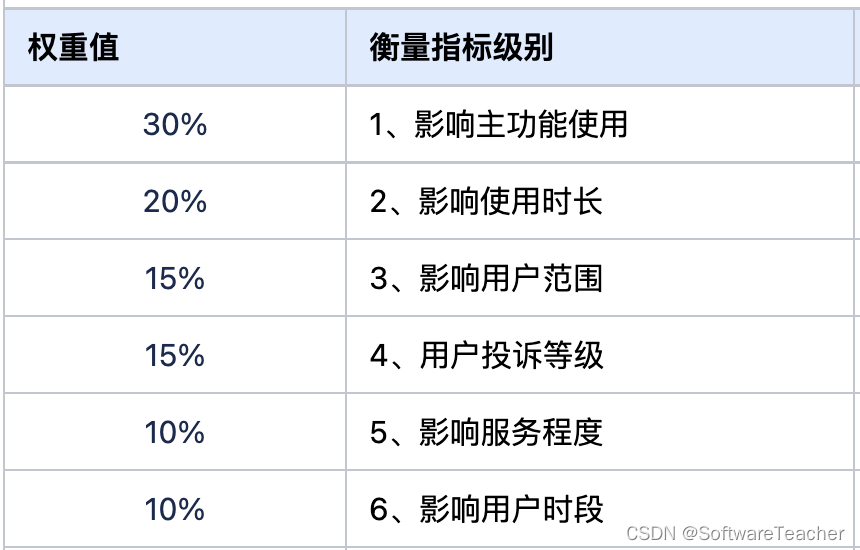
一个故障发生并被解决后,我们会收集数据,算出这个故障的危害等级,从最严重的P1 到 最不严重的P5。
线上故障
2022年全年故障数总计17个,无 P1 故障,5个 P2 故障,7个 P3 故障,2个 P4 故障,3个 P5 故障。
总结:最短故障恢复时间为 10 分钟,最长为 9 天,大部分情况下故障都能很快得到处理。
和云服务迁移相关的故障有 2 个,这提醒我们,要关注不同云平台之间产品差异化。
在预发环境验证而遗漏到生产导致的故障有 2 个,这促使我们重视发布流程规范以及梳理合规的预发环境。
由于线上流量激增而造成的故障有 2 个,这需要我们持续完备相应的监控,以及后续需推动线上故障演练。
一个具体的故障例子
我们用一个具体的例子来看我们的故障处理:
故障现象
1、故障描述:某业务线的 mongoDB CPU 飙升,导致主站服务可用性降低
2、异常时间:16:50–18:19; 解决时间:18:19; 持续时间:1小时29分钟
3、发现方式:内部人员 (事后发现客服团队收到了 9 个相关的用户查询和投诉)
4、解决方式:drop 一个阻塞的 mongo表
故障时间线
16:42 运营人员通知开始进行某功能改版的资源切量
16:50 开始对切量资源进行跑数。单次批量插入mongoDB 20条,休眠10ms。
16:52 开始观察到 mongoDB CPU 负载过高
16:52 开始联系运维去 kill 掉跑数据的 服务。
16:54 跑数据的任务 kill 成功
16:55 mongoDB cpu 一直还处于高点。主站服务的可用性在下降。
16:55 开始联系 云服务商 技术协助,进行 mongoDB 的恢复。
16:56 云服务商 建议,对 mongoDB 进行 hidden 切换。
…
17:01 切换完成,可是 cpu 负载还是无明显改善。
17:04 运维开始重启 mongoDB 实例
17:08 重启完了,并且开始 kill 掉一些进行中的会话。但是立马 cpu 负载飙高。
17:10 运维开始重启服务,发现服务连不上 mongoDB。
17:11 运维开始执行。还原mongoDB的主备切换。
17:14 主备切换完成,服务可以连上mongoDB 但是在2分钟后 cpu 负载升高。
17:15 运维开始从 graylog 分析是否有攻击。发现此时间点 爬虫的流量比较高。
17:20 尝试先降级 pc/get 接口,然后重启mongoDB。
17:25 执行完成,然后打开pc/get 接口,跑了5分钟后 cpu 再次飙高。
17:30 重试该策略,并且重启了服务所在容器。
17:35 大概10分钟 mongoDB 再次 cpu 负载飙升。
17:45 开始联系运维同学 临时提升 mongoDB的配置。
17:50 mongoDB 升配置成功 服务暂时正常。
18:10 cpu再次飙升,
18:15 这时候运维找了 连接数的NameSpace的监控, 发现链接数多数卡在 某个数据表,这个表是 pc/get 详情页的逻辑会走到的表。而且这个表 也是跑数据插入的表。 但是,表里数据逻辑非核心。
18:29 把这个表drop掉,重新创建了空表
18:29 服务完全恢复
故障影响和定级
- 影响的用户数量:按事故时段的用户量估算
- 用户咨询和投诉量: 9 例
- 对收入的影响:按影响时间和平时的成交量估算
根据我们的事故顶级规则,这个事故定义为 P3
问题剖析
我们用的是 5WHY 方法,一环扣一环,希望找出核心的因果关系。
- 为什么 mongoDB 负载会变高?(分析略)
- 为什么 mongoDB 重启之后cpu 还是会立马飙高?(不同业务竞争同一个资源)
- 为什么 完全恢复 花了1个半小时?(只关注现象和解决问题的症状,没有发现核心问题:
哪个 session 出现阻塞,阻塞具体在哪个数据表中) - 为什么在业务高峰期操作资源圈选? (不同需求都要上线,导致此任务挪到流量高峰期,对此次批量插入数据的风险性预估过低)
- 为什么drop表之后故障恢复了? (略)
解决方案
- 临时方案: drop 了阻塞的 数据库表,新建了空表,在晚上用户使用低谷期,低速写入原计划写入的数据
- 长期方案 (这些方案都有 jira 跟踪)
-
- 故障流程处理 - 【故障处理】— 梳理出一版故障处理流程
-
- 故障演练和故障处理方案 - 【故障处理】–梳理故障处理流程文档(故障不可怕,但是故障后的快速恢复能力很重要)
-
- 对生产操作的规范化 - 【技术优化】—梳理这个业务所有涉及生产操作的规范化 (从故障中学到了经验,个人和团队得到了成长)
后记
为了支撑 CSDN 这样体量的业务,各个业务内部的代码,业务之间的API,微服务,各种数据库,以及各个云平台的支撑服务形成了一个巨大而复杂的系统。 当每天超过百万的用户在使用 web/App/WAP 等界面访问 CSDN 的各个功能的时候,如果出了一下问题,用户的反应都是很情绪化的,例如:

在这种情况下, 我们的研发小伙伴,特别是运维人员,都在忙碌地工作,处理各种大大小小的问题。我们的故障处理流程,能帮助大家理性地分析问题、解决问题、让团队成长。
当我们解决了问题之后,用户的感性表白,是对我们最好的奖赏,下面的截屏就是例子; 当我们全面收集了海量的感性表达,我们就能通过分析得到对 CSDN 服务的理性衡量,例如这个情感数据分析的博客。 感性也好,理性也好,希望大家不断使用 CSDN,给我们反馈,让我们有学习的机会,不断提高。

![SAPIEN PrimalSQL 2023.1[x64] Crack](https://img-blog.csdnimg.cn/d15737840f144b6798e9c2d6b1bfd54a.png)