【风控】可解释机器学习之InterpretML
在金融风控领域,机器学习模型因其强大的预测能力而备受青睐。然而,随着模型复杂性的增加,模型的可解释性逐渐成为一个挑战。监管要求、业务逻辑的透明度以及对模型决策的信任度,都迫切需要我们能够清晰地解释模型的每一个预测。这就是InterpretML发挥作用的地方——一个专注于提高机器学习模型可解释性的开源工具包。
InterpretML,作为微软推出的可解释人工智能(XAI)工具集的一部分,提供了一套全面的框架,帮助开发者理解和解释任何机器学习模型的决策过程。它通过可视化和模型无关的方法,使得即使是最复杂的模型也能变得透明和易于理解。在本篇博客中,我们将深入探索InterpretML的核心功能,演示如何使用它来增强风控模型的可解释性,并讨论它在金融领域风控建模中的应用价值。通过本篇博客,你将了解到如何借助InterpretML,让机器学习模型在风控领域更加可靠和透明。
文章目录
- 【风控】可解释机器学习之InterpretML
- 一、InterpretML是什么
- 1.多种解释模型:
- 2.支持不同类型的解释器:
- 3.易用性和可视化:
- 4.模型无关性:
- 5.集成和易用性:
- 二、Glassbox 与 Blackbox
- 1.Glassbox 模型
- 2.Blackbox 模型
- 三、实现代码
- 1.Glassbox 模型
- 2.Blackbox 模型
- 总结
一、InterpretML是什么
InterpretML官网
InterpretML是一个开源库,用于训练和解释机器学习模型。其核心目标是提供易于使用的接口和可视化工具,帮助用户理解模型的预测原因和行为。这种透明度尤其对于在高风险和监管环境中运用机器学习模型的场景非常重要。以下是InterpretML的一些主要特性和功能:
1.多种解释模型:
InterpretML提供了多种模型解释工具,支持从简单的线性模型到复杂的集成模型等多种类型。这包括全局解释(整个模型的解释)和局部解释(单个预测的解释)。
2.支持不同类型的解释器:
包括但不限于以下解释器:
- EBM (Explainable Boosting Machine):这是interpret包的核心,是一种基于梯度提升机的模型,设计为高度可解释。
- SHAP (SHapley Additive exPlanations):利用博弈论的概念,将每个特征对预测的贡献分解开来。
- LIME (Local Interpretable Model-agnostic Explanations):通过在预测点附近采样生成局部模型,解释复杂模型的预测。
- Partial Dependence Plot (PDP):显示一个或两个特征变化时模型预测的平均变化情况。
- Decision Tree Surrogate:构建一个决策树来近似模仿黑箱模型的行为。
3.易用性和可视化:
InterpretML包含了丰富的可视化功能,允许用户直观地看到模型的工作原理和每个特征如何影响预测结果。这包括数据探索、模型性能评估和特征影响的可视化。
4.模型无关性:
一部分解释器支持模型无关性,意味着它们可以用于任何类型的机器学习模型。例如,SHAP和LIME就可以应用于任何黑箱模型,提供预测的解释。
5.集成和易用性:
InterpretML可以与常用的机器学习框架如scikit-learn、TensorFlow等无缝集成,
二、Glassbox 与 Blackbox
在InterpretML库中,术语"Glassbox"和"Blackbox"模型表示两种不同类型的机器学习模型和解释方法。这两者在透明度、可解释性和使用方式上有明显区别。
1.Glassbox 模型
"Glassbox"模型指的是内在可解释的模型,即模型的结构和预测逻辑本身就是透明的。这类模型允许直接查看和理解决策过程,而无需额外的解释层。interpret提供了一些内置的Glassbox模型,
例如:
- Decision Tree:决策树通过树状结构展示决策过程,每个决策节点都很直观。
- Linear/Logistic Regression:线性和逻辑回归模型通过权重和系数直接展示了每个特征对预测的贡献。
- Explainable Boosting Machine (EBM):EBM是一种基于梯度提升的可解释模型,它为每个特征生成单独的加法模型,每个模型都是简单、可解释的。
2.Blackbox 模型
"Blackbox"模型是指那些本身结构复杂、难以直接解释的模型,如深度神经网络或复杂的集成方法(如随机森林)。这些模型的决策逻辑不直观,通常需要借助额外的工具和方法来理解模型的行为。在interpret中,Blackbox解释通常是通过后置的解释方法实现的,如SHAP和LIME。
三、实现代码
1.Glassbox 模型
# pip install interpret
# 结果可视化
from interpret import set_visualize_provider
from interpret.provider import InlineProvider
set_visualize_provider(InlineProvider())
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
# 逻辑回归建模
from interpret.glassbox import LogisticRegression
from interpret import show
seed = 1
# 加载乳腺癌数据集
data = load_breast_cancer()
# 特征矩阵
X = data.data
# 目标向量
y = data.target
# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
lr = LogisticRegression(random_state=seed,fit_intercept=False)
lr.fit(X_train, y_train)
lr_global = lr.explain_global()
show(lr_global)
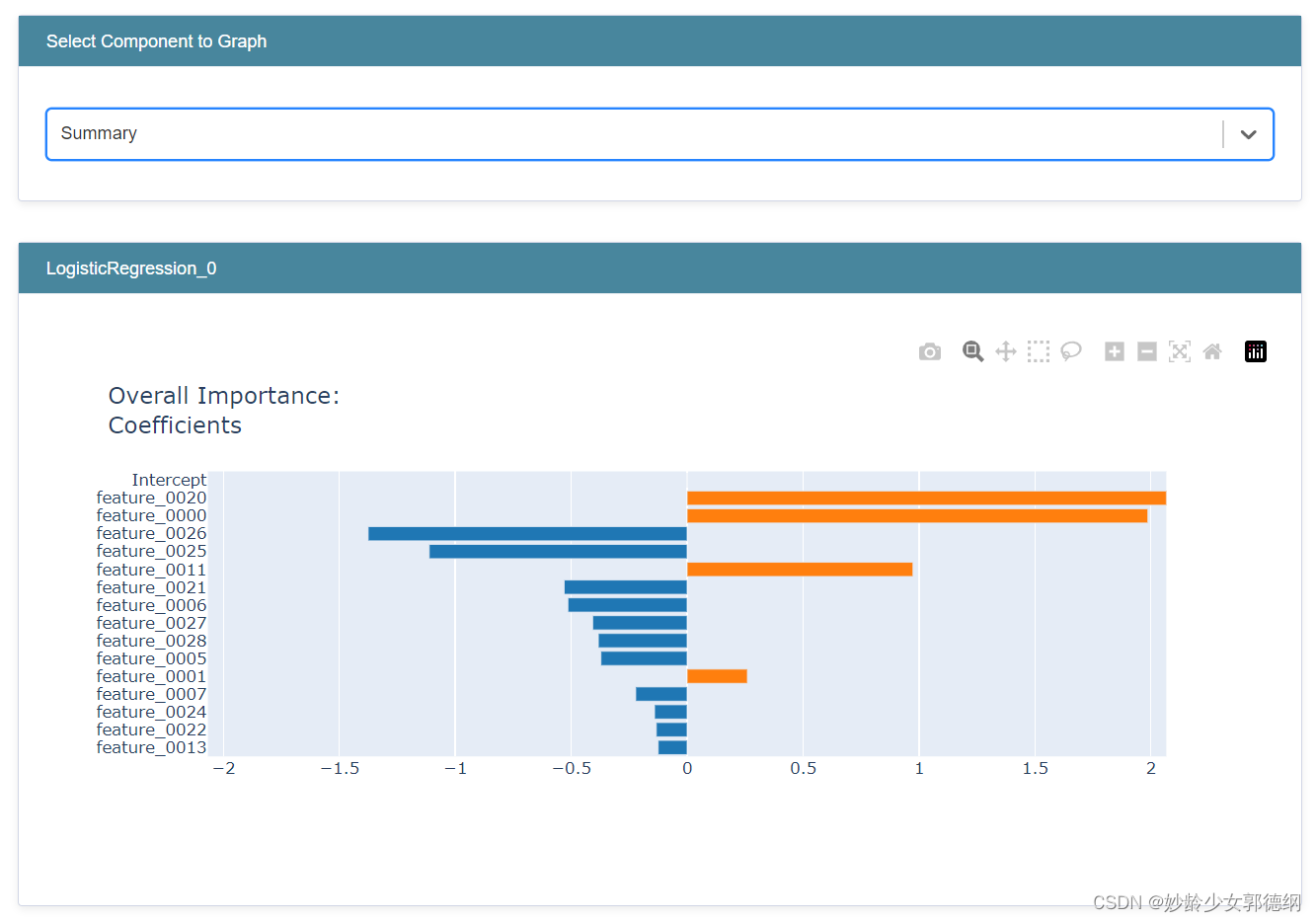
特征重要性与影响方向
- 特征重要性:图表中特征的重要性通常通过条形图的长度来表示,条形图越长,表示该特征在模型决策中的作用越大。特征重要性反映了该特征在预测模型输出中的权重和影响力。
- 影响方向:
- 正值:如果一个特征的SHAP值或影响值为正,意味着该特征的增加通常会导致预测结果的增加(对于回归模型)或者增加某一类别的预测概率(对于分类模型)。例如,在信用评分模型中,收入较高可能会增加获得贷款的预测概率。
- 负值:反之,如果SHAP值为负,表示该特征的增加会导致预测结果的减少或者降低某一类别的预测概率。例如,在同样的信用评分模型中,负债较多可能会降低获得贷款的预测概率。
2.Blackbox 模型
import shap
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
# 加载数据并创建模型
data = load_iris()
X_train, X_test, y_train, y_test = train_test_split(data.data, data.target, test_size=0.2, random_state=42)
model = RandomForestClassifier()
model.fit(X_train, y_train)
# 创建SHAP解释器
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(X_test)
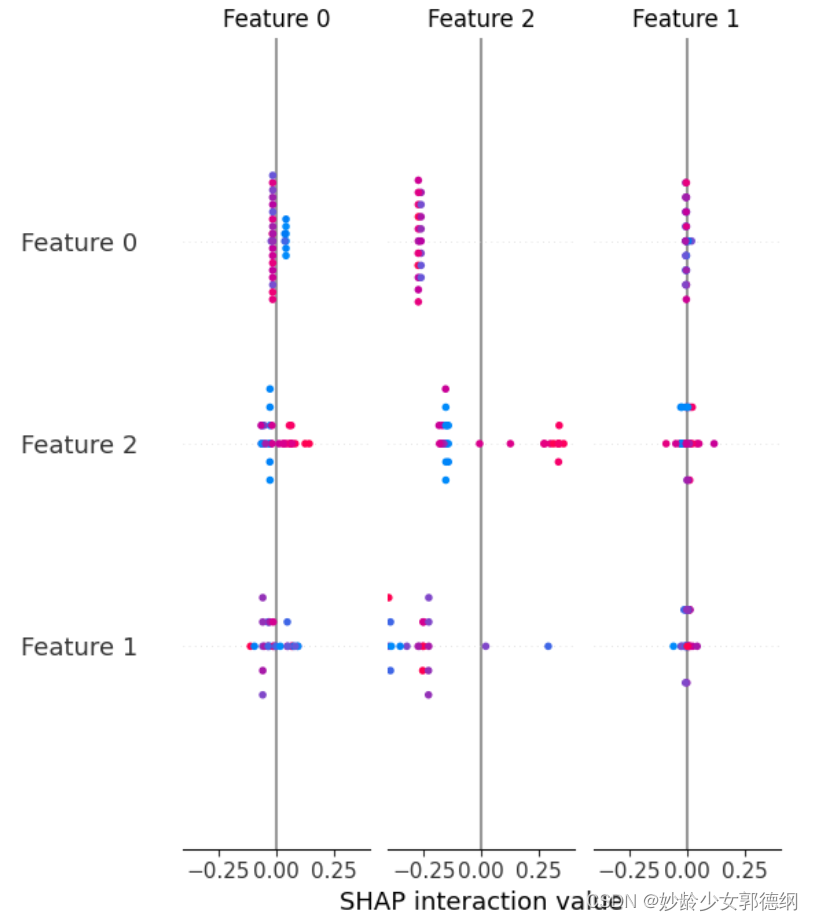
# 可视化解释
shap.summary_plot(shap_values, X_test, plot_type="bar")
总结