在上面篇文章中已经对flink进行了简单的介绍以及了解了Flink API 层级划分,这一章内容我们主要介绍DataStream API
流程图解:
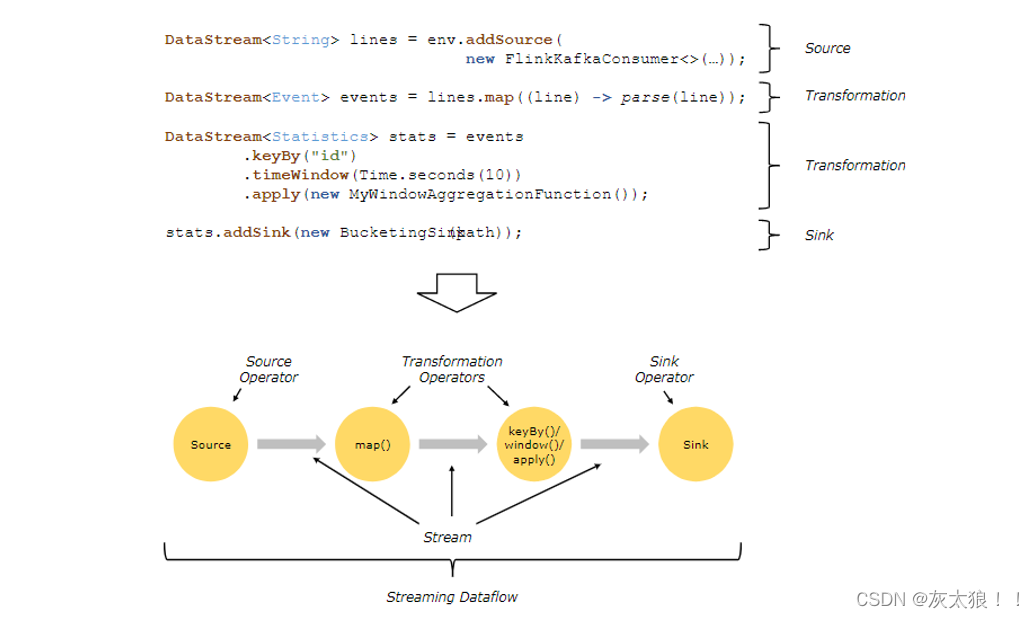
一、DataStream API Source
Flink 在流处理和批处理上的 source 大概有 4 类:
(1)基于本地集合的 source
(2)基于文件的 source
(3)基于网络套接字的 source,具体来说就是从远程服务器或本地端口上的套接字连接中接收数据,比如上一篇文章中的入门案例就属于这一种。
(4)自定义的 source。自定义的 source 常见的有 Apache kafka、Amazon Kinesis Streams、RabbitMQ、Twitter Streaming API、Apache NiFi 等,当然你也可以定义自己的 source,灵活度较高,看个人需求。
下面就是纯代码演示了,具体细节会在注释中说明
1、本地集合的source
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.util.ArrayList;
public class Demo1ListSource {
public static void main(String[] args) throws Exception{
//创建flink执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//创建集合
ArrayList<String> arrayList = new ArrayList<>();
arrayList.add("java");
arrayList.add("java");
arrayList.add("java");
arrayList.add("java");
arrayList.add("java");
/*
*基于集合的Source ----- 属于有界流
*/
DataStream<String> listDS = env.fromCollection(arrayList);
listDS.print();
//启动Flink作业执行
env.execute();
}
}结果:
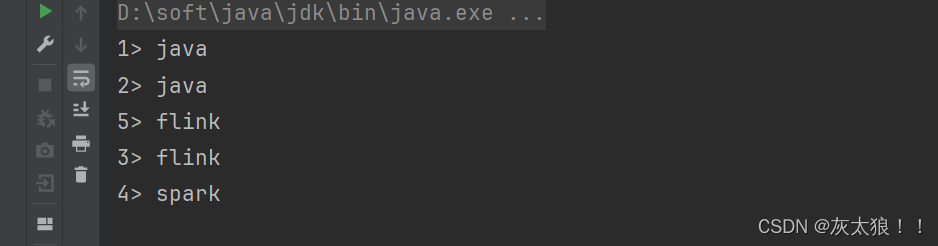
在这解释一下结果图中的数字前缀,这个前缀的主要目的是不同并行实例的输出。什么都不设置的话取决于你电脑的内存了,比如我电脑是16G的内存,那么当数据较多时默认分配给该作业分了16个task。
2、本地文件的source
注意:同一个File数据源,既能有界读取,也能无界读取
2.1 有界读取
/*
*流批统一:
* 1、同一套算子代码既能作流处理也能做批处理
* 2、同一个File数据源,既能有界读取,也能无界读取
*/
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.connector.file.src.FileSource;
import org.apache.flink.connector.file.src.reader.TextLineInputFormat;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class Demo2FileSource1 {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
/*
*有界读取
*/
//老版本方式:简单但不灵活
DataStream<String> lineDS = env.readTextFile("flink/data/student.csv");
// lineDS.print();
//新版本方式:复杂一点但更灵活,使用这种既能有界读取,也能无界读取
//构建fileSource
FileSource<String> fileSource = FileSource.forRecordStreamFormat(
//指定编码
new TextLineInputFormat("UTF-8")
//指定路径
, new Path("flink/data/student.csv")
).build();
//使用fileSource
DataStream<String> fileDS = env.fromSource(fileSource, WatermarkStrategy.noWatermarks(), "fileSource");
fileDS.print();
env.execute();
}
}
2.1 无界读取
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.connector.file.src.FileSource;
import org.apache.flink.connector.file.src.reader.TextLineInputFormat;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class Demo2FileSource2 {
public static void main(String[] args) throws Exception {
/*
*使用无界流读取文件数,很简单,其实就是对上面的代码修改运行模式并加个参数就可以了
*/
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//修改运行模式
env.setRuntimeMode(RuntimeExecutionMode.STREAMING);
//构建fileSource
FileSource<String> fileSource = FileSource.forRecordStreamFormat(new TextLineInputFormat("UTF-8"),
new Path("spark/data/student.csv")).build();
//使用fileSource
DataStreamSource<String> linesDS = env.fromSource(fileSource, WatermarkStrategy.noWatermarks(), "fileSource");
linesDS.print();
env.execute();
}
}3、本地端口的source
上一篇文章中的入门案例就属于这一种,后面在代码中也会用到,在此不在赘述了。
4、自定义的 source
举例:使用自定义source读取mysql中的数据
/*实现方式:
* 1、实现SourceFunction或ParallelSourceFunction接口来创建自定义的数据源。
* 2、然后使用env.addSource(new CustomSourceFunction())或DataStreamSource.fromSource添加你自定义的数据源。
*/
import lombok.AllArgsConstructor;
import lombok.Data;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
public class Demo3MysqlSource {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//使用自定义的source
DataStream<Student> studentDSSource = env.addSource(new MysqlSource());
//统计学生表每个班级的人数
//取出每一行的班级列并加上人数后缀1
DataStream<Tuple2<String, Integer>> clazzKvDS = studentDSSource.map(line -> Tuple2.of(line.getClazz(), 1), Types.TUPLE(Types.STRING, Types.INT));
//分组,将相同的键发送给同一个task中
KeyedStream<Tuple2<String, Integer>, String> keyByDS = clazzKvDS.keyBy(kv -> kv.f0);
//求和
SingleOutputStreamOperator<Tuple2<String, Integer>> clazzSum = keyByDS.sum(1);
//输出
clazzSum.print();
env.execute();
}
}
/**
* 自定义source读取mysql中的数据
*/
class MysqlSource implements SourceFunction<Student> {
/**
* run()方法会在任务启动的时候执行一次
*/
@Override
public void run(SourceContext ctx) throws Exception {
//1、加载mysq驱动
Class.forName("com.mysql.jdbc.Driver");
//2、创建数据库连接
//注意:如果报连不上的错误,将参数补全(useUnicode=true&allowPublicKeyRetrieval=true&characterEncoding=utf8&useSSL=false)
Connection conn = DriverManager.getConnection("jdbc:mysql://master:3306/bigdata29?useSSL=false", "root", "123456");
//3、编写sql查询
PreparedStatement sql = conn.prepareStatement("select * from students");
//4、执行查询
ResultSet resultSet = sql.executeQuery();
//5、遍历查询出的数据
while (resultSet.next()) {
int id = resultSet.getInt("id");
String name = resultSet.getString("name");
int age = resultSet.getInt("age");
String gender = resultSet.getString("gender");
String clazz = resultSet.getString("clazz");
//将数据发送到下游
/*
* collect():从 DataStream 收集所有的元素,并将它们作为列表或其他集合类型返回给客户端
*/
ctx.collect(new Student(id, name, age, gender, clazz));
}
//6、释放资源
sql.close();
conn.close();
}
@Override
public void cancel() {
/*
* cancel(),它用于在任务完成后执行清理操作
*/
}
}
/**
* 这里使用了lombok插件(小辣椒)
* 这个插件的作用可以在代码编译的时候增加方法(相当于scala中的case class),就不用我们自己手动添加get、set、toString等方法了。
* 使用方法:加@就行了
*/
@Data
@AllArgsConstructor
class Student {
private int id;
private String name;
private int age;
private String gender;
private String clazz;
}
二、DataStream API Transformation
Transformation:数据流转换。
常见算子有 Map / FlatMap / Filter /KeyBy / Reduce / Fold / Aggregations / Window / WindowAll / Union / Window join / Split / Select / Project 等,操作很多,可以将数据转换计算成你想要的数据形式。
其实这些算子在功能上与scala或spark中的基本相同,只是形式和细节上会有些差别。
1、map
DataStream → DataStream 输入一个元素同时输出一个元素
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class Demo1Map {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//使用nc -lk 8888 模拟实时数据的产生
DataStreamSource<String> source = env.socketTextStream("master", 8888);
//方式1:匿名内部类形式
/*
* 观察源码map发现:
* MapFunction<T, O> 是一个函数接口,用于对流中的每个元素的处理
* 这个接口定义了一个 map 方法,该方法接受一个输入元素(类型为 T)并返回一个输出元素(类型为 O)。
*/
DataStream<String> map1DS = source.map(new MapFunction<String, String>() {
@Override
public String map(String word) throws Exception {
return word.toUpperCase();
}
});
// map1DS.print();
//方式2:lambda表达式形式(更简洁常用)
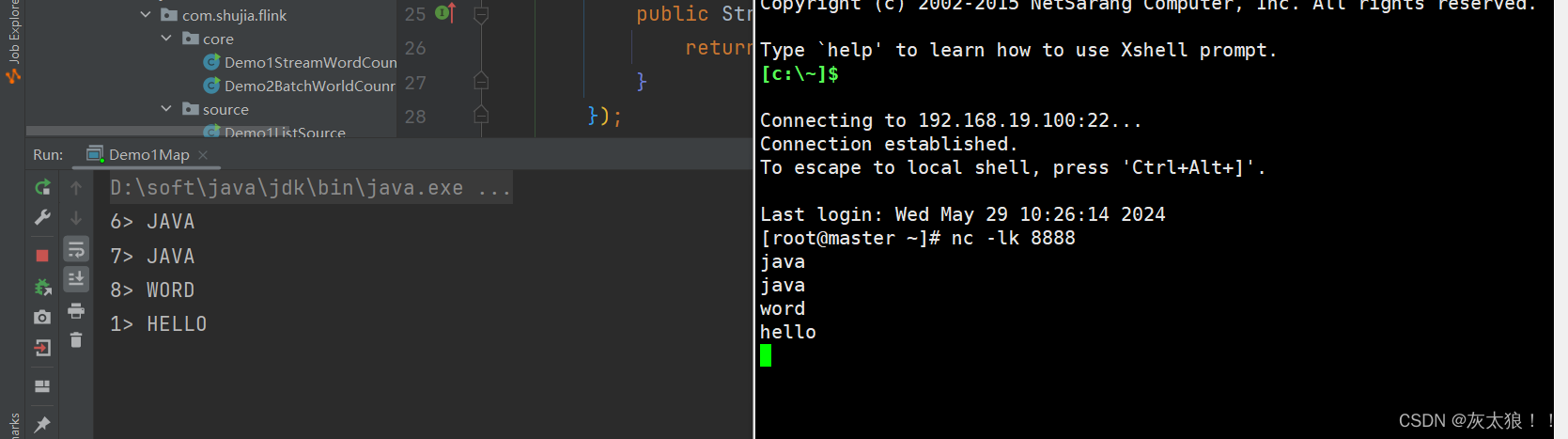
source.map(String::toUpperCase).print(); //是对source.map(word -> word.toUpperCase())的更简写
env.execute();
}
}结果:
2、flatMap
DataStream → DataStream
输入一个元素转换为一个或多个元素输出
/*
*flatMap 方法用于将输入流中的每个元素转换成一个或多个输出元素
*/
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class Demo2FaltMap {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<String> source = env.socketTextStream("master", 8888);
//方式1:匿名内部类
//看源码,这个方法接受一个FlatMapFunction<T, R>类型的参数,其中T是输入元素的类型,R是输出元素的类型
DataStream<String> out2DS = source.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String line, Collector<String> out) throws Exception {
for (String word : line.split(",")) {
//循环将数据发送到下游
out.collect(word);
}
}
});
// out2DS.print();
//方式2:lambda表达式
DataStream<String> out1DS = source.flatMap((line, out) -> {
for (String word : line.split(",")) {
//循环将数据发送到下游
out.collect(word);
}
}, Types.STRING);
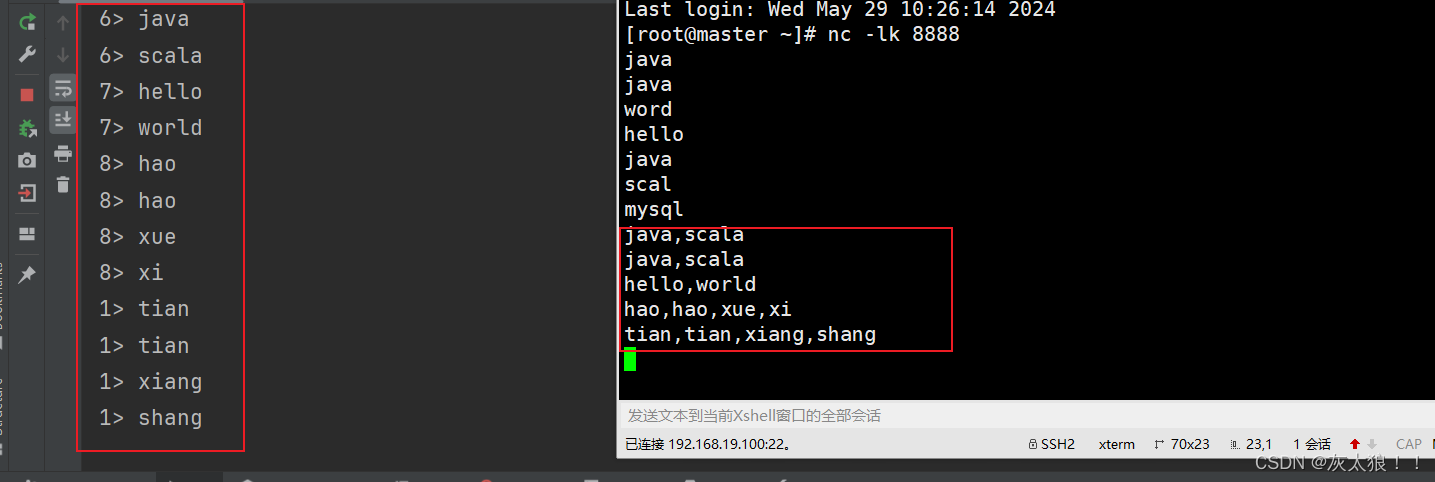
out1DS.print();
env.execute();
}
}
结果:
3、filter
DataStream → DataStream
为每个元素执行一个布尔 function,并保留那些 function 输出值为 true 的元素
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class Demo3Filter {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<String> source = env.readTextFile("spark/data/student.csv");
//需求:过滤出文科一班的学生的信息
//方式一:匿名内部类
source.filter(new FilterFunction<String>() {
@Override
public boolean filter(String lines) throws Exception {
return "文科一班".equals(lines.split(",")[4]);
}
}); //.print();
//方式2:lambda表达式
source.filter(lines->"文科一班".equals(lines.split(",")[4])).print();
env.execute();
}
}
结果:

4、keyBy
作用为:分组
DataStream → KeyedStream
在逻辑层面将流划分为不相交的分区。具有相同 key 的记录都分配到同一个分区。在内部, keyBy() 是通过哈希分区实现的。有多种指定 key 的方式。

import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class Demo4KeyBy {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> source = env.socketTextStream("master", 8888);
//方式1:匿名内部类
/*
* public <K> KeyedStream<T, K> keyBy(KeySelector<T, K> key)
* 其中 T 是输入元素的类型,K 是键的类型
*/
source.map(word-> Tuple2.of(word,1), Types.TUPLE(Types.STRING,Types.INT))
.keyBy(new KeySelector<Tuple2<String, Integer>, String>() {
@Override
public String getKey(Tuple2<String, Integer> kv) throws Exception {
return kv.f0;
}
});//.print();
//方式2:lambda表达式
source.map(word-> Tuple2.of(word,1), Types.TUPLE(Types.STRING,Types.INT))
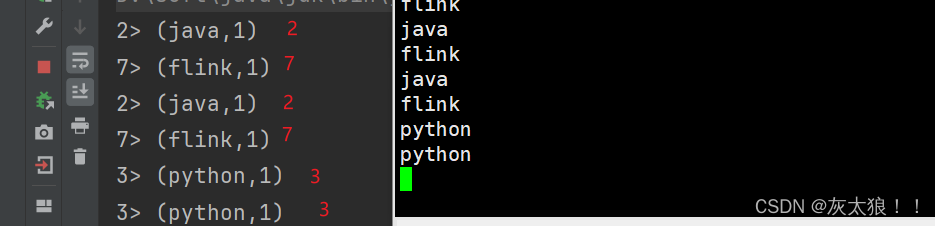
.keyBy(kv->kv.f0).print();
env.execute();
}
}结果: 可以看出的确作了分区
5、reduce
作用为:聚合
KeyedStream → DataStream
在相同 key 的数据流上“滚动”执行 reduce。将当前元素与最后一次 reduce 得到的值组合然后输出新值。
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class Demo5Reduce {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<String> source = env.socketTextStream("master", 8888);
//方式1:匿名内部类
source.map(word -> Tuple2.of(word, 1), Types.TUPLE(Types.STRING, Types.INT))
.keyBy(kv -> kv.f0)
.reduce(new ReduceFunction<Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> reduce(Tuple2<String, Integer> kv1,
Tuple2<String, Integer> kv2) throws Exception {
//kv1和kv2的key是一样的
String word = kv1.f0;
int counts = kv1.f1 + kv2.f1;
return Tuple2.of(word,counts);
}
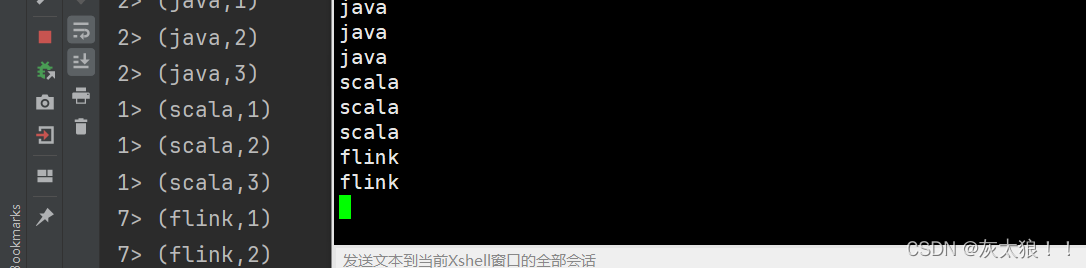
}).print();
env.execute();
}
}结果:从结果来看说明reduce是一个有状态算子。
6、Window
KeyedStream → WindowedStream
可以在已经分区的 KeyedStreams 上定义 Window,Window 根据某些特征(例如,最近 5 秒内到达的数据)对每个 key Stream 中的数据进行分组。
窗口算子有很多,以后会专门出一章具体说明,下面写一个滑动窗口的案例。
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.*;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.SlidingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
public class Demo6Window {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
/*
* 每隔5秒统计最近15秒每个单词的数量 --- 滑动窗口
*/
DataStream<String> wordsDS = env.socketTextStream("master", 8888);
//转换成kv
DataStream<Tuple2<String, Integer>> kvDS = wordsDS
.map(word -> Tuple2.of(word, 1), Types.TUPLE(Types.STRING, Types.INT));
//按照单词分组
KeyedStream<Tuple2<String, Integer>, String> keyByDS = kvDS.keyBy(kv -> kv.f0);
//划分窗口
//SlidingEventTimeWindows:滑动的处理时间窗口
//前一个参数为窗口大小(window size),后一个参数为滑动大小(window slide)
WindowedStream<Tuple2<String, Integer>, String, TimeWindow> windowDS = keyByDS
.window(SlidingProcessingTimeWindows.of(Time.seconds(30), Time.seconds(10)));
//统计单词的数量
DataStream<Tuple2<String, Integer>> countDS = windowDS.sum(1);
countDS.print();
env.execute();
}
}
7、Union
DataStream→ DataStream
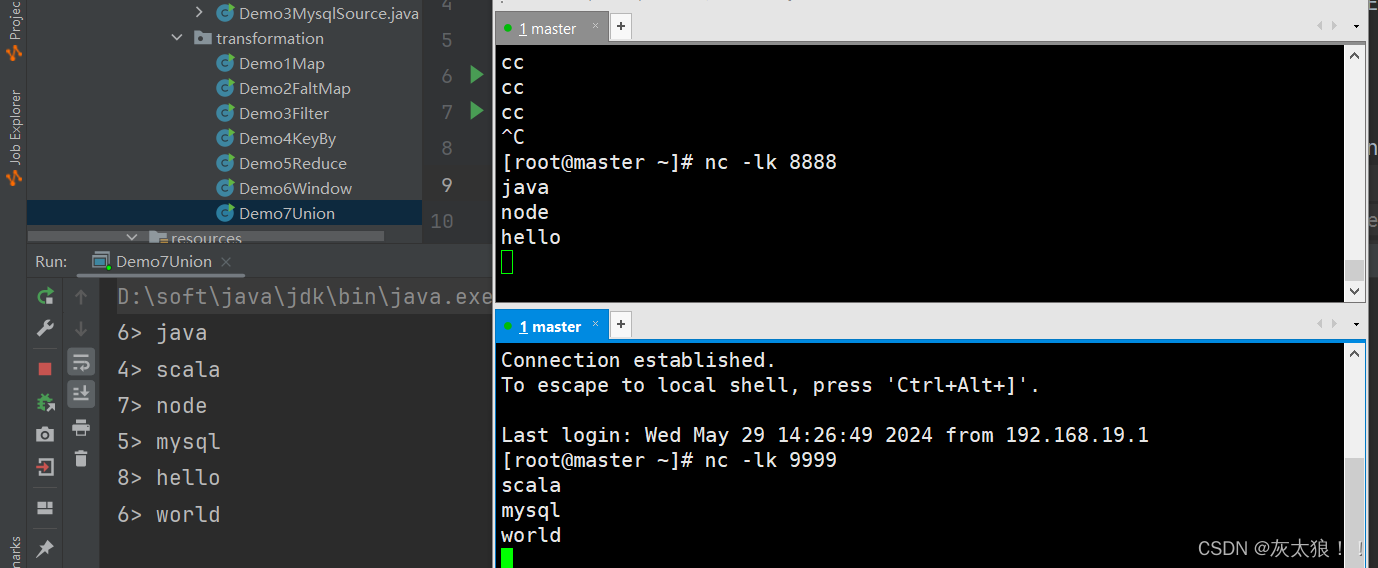
将两个或多个数据流联合来创建一个包含所有流中数据的新流。注意:如果一个数据流和自身进行联合,这个流中的每个数据将在合并后的流中出现两次。
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class Demo7Union {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<String> source1 = env.socketTextStream("master", 8888);
DataStream<String> source2 = env.socketTextStream("master", 9999);
/*
* 合并两个DataStream
* 注意:在数据层面并没有合并,只是在逻辑层面合并了
*/
DataStream<String> unionDS = source1.union(source2);
unionDS.print();
env.execute();
}
}结果:
8、process
DataStream→ DataStream
process算子是flink的底层算子,可以用来代替map、faltMap、filter等算子
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.util.Collector;
public class Demo8Process {
public static void main(String[] args) throws Exception {
/*
* process算子是flink的底层算子,可以用来代替map、faltMap、filter等算子
*
* public <R> SingleOutputStreamOperator<R> process(ProcessFunction<T, R> processFunction)
* 其中 T 是输入数据的类型,R 是输出数据的类型
*/
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<String> source = env.socketTextStream("master", 8888);
DataStream<Tuple2<String, Integer>> processDS = source.process(new ProcessFunction<String, Tuple2<String, Integer>>() {
/*
* processElement:在当前代码中相当于flatMap,每一条数据执行一次,可以返回一条或多条数据
* ctx:上下文对象(代表flink执行环境)
* out:输出,用于将数据发送到下游
*/
@Override
public void processElement(String line, ProcessFunction<String, Tuple2<String, Integer>>.Context ctx,
Collector<Tuple2<String, Integer>> out) throws Exception {
//这里的逻辑与flatMap的逻辑相同
for (String word : line.split(",")) {
out.collect(Tuple2.of(word, 1));
}
}
});
env.execute();
/*
* 注意:该算子不能用lambda表达式改写,因为ProcessFunction它包含了一些生命周期方法和状态管理的方法,
* 这些方法使得它不适合直接简化为lambda表达式的形式。
*
* 在底层代码层面来说,ProcessFunction是一个抽象类,该类还有许多复杂的方法,使得它无法直接用lambda表达式来改写
* 因为 lambda 表达式只能表示简单的函数接口(即那些只包含一个抽象方法的接口)
* public abstract class ProcessFunction<I, O> extends AbstractRichFunction
*/
}
}
三、DataStream API Sink
Flink 将转换计算后的数据发送的地点 。
Flink 常见的 Sink 大概有如下几类:
(1)打印在控制台、写入文件。
(2)写入 socket(具体指的是将数据发送到网络套接字(例如端口))。
(3)自定义的 sink :常见的有 Apache kafka、RabbitMQ、MySQL、ElasticSearch、Apache Cassandra、Hadoop FileSystem 等,当然你也可以根据需求定义自己的 sink。
1、写入文件
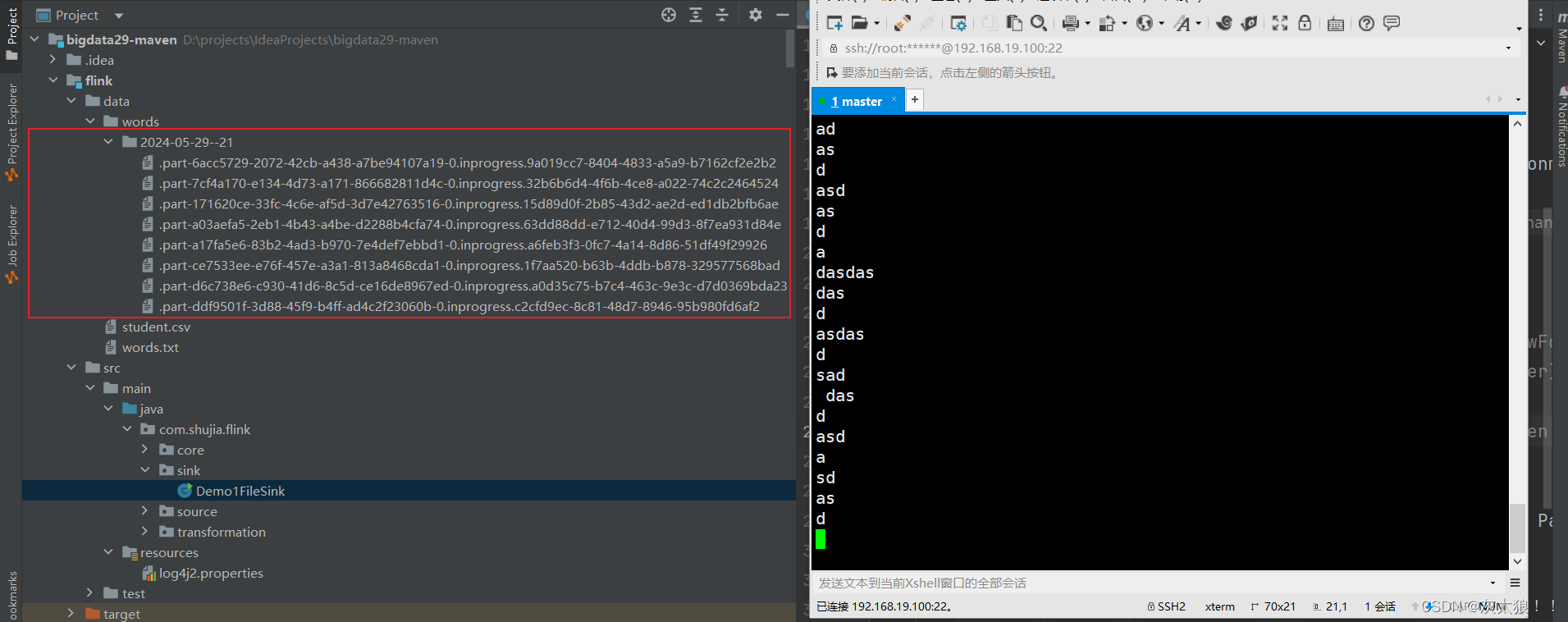
对于写入文件,是否要将所有数据写入同一个文件?由于是流式写入,该文件就一直处于正在写入的状态,而且可能会造成文件过大的问题,所以DataStream API提供了滚动策略的方式来解决这样的问题。

import org.apache.flink.api.common.serialization.SimpleStringEncoder;
import org.apache.flink.configuration.MemorySize;
import org.apache.flink.connector.file.sink.FileSink;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.filesystem.rollingpolicies.DefaultRollingPolicy;
import java.time.Duration;
public class Demo1FileSink {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<String> source = env.socketTextStream("master", 8888);
//创建fileSink
/*
*public static <IN> DefaultRowFormatBuilder<IN> forRowFormat(
* final Path basePath, final Encoder<IN> encoder)}
*
*<IN> : The type of the elements that are being written by the sink.
*/
FileSink<String> fileSink = FileSink.forRowFormat(new Path("flink/data/words"), new SimpleStringEncoder<String>("UTF-8"))
.withRollingPolicy(
DefaultRollingPolicy.builder()
//每10秒进行一次滚动(生成文件)
.withRolloverInterval(Duration.ofSeconds(10))
//当延迟超过10秒进行一次滚动
.withInactivityInterval(Duration.ofSeconds(5))
//文件大小达到1MB进行一次滚动
.withMaxPartSize(MemorySize.ofMebiBytes(1))
.build())
.build();
//使用fileSink,将读取的数据写入另一到文件夹中
source.sinkTo(fileSink);
env.execute();
}
}结果:
2、自定义的 sink
举例:使用自定义sink将数据存到mysql中
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;
import org.apache.flink.streaming.api.functions.sink.SinkFunction;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
public class Demo3MySqlSInk {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<String> wordsDS = env.socketTextStream("master", 8888);
//统计单词的数量
DataStream<Tuple2<String, Integer>> countDS = wordsDS
.map(word -> Tuple2.of(word, 1), Types.TUPLE(Types.STRING, Types.INT))
.keyBy(kv -> kv.f0)
.sum(1);
//将统计结果保存到数据
countDS.addSink(new MySQlSink());
env.execute();
}
}
/**
* 自定义sink将数据保存到mysql
* RichSinkFunction:多了open和close方法,用于打开和关闭连接
* SinkFunction
*/
class MySQlSink extends RichSinkFunction<Tuple2<String, Integer>> {
Connection con;
PreparedStatement stat;
/**
* invoke方法每一条数据执行一次
*/
@Override
public void invoke(Tuple2<String, Integer> kv, Context context) throws Exception {
stat.setString(1, kv.f0);
stat.setInt(2, kv.f1);
//执行sql
stat.execute();
}
/**
* open方法会在任务启动的时候,每一个task中执行一次
*/
@Override
public void open(Configuration parameters) throws Exception {
System.out.println("创建数据库连接");
//1、加载启动
Class.forName("com.mysql.jdbc.Driver");
//2、创建数据库连接
con = DriverManager.getConnection("jdbc:mysql://master:3306/bigdata29", "root", "123456");
//3、编写保存数据的sql
//replace into 替换插入,如果没有就插入,如果有就更新,表需要有主键
stat = con.prepareStatement("replace into word_count values(?,?)");
}
/**
* close方法会在任务取消的时候,每一个task中执行一次
*/
@Override
public void close() throws Exception {
//4、关闭数据库连接
stat.close();
con.close();
}
---------------------------------------------------------------------------------------------------------------------------------
代码注意提示:
如果在写flink代码的过程中出现了以下错误,大概率就是有些算子使用没有写数据类型,与spark不同,spaark底层由scala编写,scala提供了自动类型推断机制,所以不写参数类型也不会报错,但是flink底层是java编写的,java没有这种机制。

基础的算子到这结束,其他算子后续也会写,以上内容具体详情皆参考apache flink官网,官网详细说明了各种算子的使用,网址贴在下面了:
https://nightlies.apache.org/flink/flink-docs-release-1.19/zh/docs/dev/datastream/operators/overview/
个人感觉写的很详细了,看不懂建议直接打死作者(^_^)