前言
首先我们看一下产品的需求背景,这个产品为了解决招聘面试的过程中,线下面试管理效率低,面试过程和结果不方便跟踪的痛点
招聘管理的系统几乎是每一家中小公司都需要的产品
我们以校园招聘的面试为例子来做 MVP 产品迭代
首先我们来看一下线下的面试流程,线下面试流程分成三个步骤:
第一个步骤,hr 发出面试评估表,到一面面试官
这个评估表是word格式的模板,hr 通过邮箱发出来到面试官,然后一面面试官登录到邮箱,下载word模板,为每个学生拷贝一份模板文件,使用学生的名字来重命名面试评估表,在评估表里面录入学生的名字,学校电话学历等等
第二个步骤,进行第一轮面试,由一面的面试官来面试
每面完一个候选人,面试官把面试的结论填写到word格式的评估表中,一名面试官在面完一批学生之后,批量把 word 格式的评估表发送给hr,hr查收下载评估表,汇总结果到 excel,然后发送到技术二面的面试官做复试,通知二面面试官继续做二面
第三个步骤,二面面试官查收并下载 word 格式的评估记录,开始二面
二面结束后,同样的把面试结论追加到 word 格式的面试评估表中,然后再邮件通知hr哪些候选人通过了二面,接下来hr继续重复前面的操作,做第三轮面试
最后,用Excel汇总,哪些人过了三面,需要通知候选人已经被录取

面试评估表里面有候选人的基础信息,包括姓名、手机号、应聘职位、毕业院校,专业笔试的成绩,综合能力测评的成绩
也有一面的初始成绩,这一轮评估候选人的学习能力和专业能力
然后还有第二轮复试,这一轮评估候选人的追求卓越的能力,沟通能力和抗压能力等等
以及最终的 hr 复试,hr 复试会评估软性的数字,包括责任心、沟通能力、逻辑思维,给出最终复试的结论,分成4个等级,最后择优录取
MVP 产品迭代思想
看起来面试流程蛮复杂的,要能够管理候选人有不同的角色,需要录入不同内容,还要根据状态来判断要不要继续后续面试,这么多的功能怎么样能够在一天之内交付可以使用的面试招聘系统
这个就需要使用到产品的迭代思维,我们一起来学习迭代的思维,一起思考怎么样做 MVP 产品的迭代划分

MVP 包含了产品的轮廓,核心的功能,能够让业务运转起来的最小功能子集,这个版本我们可以叫它内裤版本
所以如果我们规划一个版本,开发半年或者一年以上交付一个大而全的产品,往往到最后开发出来的都不是用户想要的
同时经过了这么长的时间,用户市场需求都已经变化了很多,我们还在原地踏步
抱着最初认为正确的产品方案在开发,所以长迭代非常可怕,尽量把你的迭代周期控制在周的单位,甚至是天或者小时为单位
MVP 版本开发出来之后,再开始下一个迭代,继续下一个 MVP 版本,同样是找出对于当前版本的需求来说最核心最重要的功能放在迭代交付,然后再交付下一个迭代,这个是产品的迭代思维,迭代思维是最强大的产品思维逻辑,也是互联网唯快不破的秘密
MVP 迭代思想应用
接下来我们一起来看看怎么样把 MVP 迭代的思想,应用到我们的招聘面试的系统里面来
我们先来看一下产品的用户场景和功能有哪些:

我们把产品 MVP 迭代的思维应用到了我们面试招聘的系统里面来,帮我们找出系统里面最核心的两个功能:
一个功能是能够维护候选人的信息
另外一个功能是能够去做面试评估,去反馈在系统里面录入面试评估的结论
数据库设计原则
现在对我们的系统进行建模,并且讲解企业级数据库设计的10个原则
数据建模图如下:

我们来讲企业级数据库设计的10个原则:



我们将创建面试评估的应用,然后创建数据库模型,创建数据库模型的时候,记得要遵循这些设计原则
创建 interview 应用
实现候选人面试评估表的增删改功能,并且按照页面分组来展示不同的内容,如候选人基础信息,一面,二面的面试结果,HR 的面试结果
我们可以使用 pycharm 上面菜单栏中 Tools 里的 Run manage.py task,这样就不用每次都输入前面的命令了
输入命令 startapp interview

创建完应用后,打开 models.py 文件,开始编写数据建模代码
from django.db import models
# 第一论面试结果
FIRST_INTERVIEW_RESULT_TYPE = (('建议复试','建议复试'),('待定','待定'),('放弃','放弃'))
# 复试面试建议
INTERVIEW_RESULT_TYPE = (('建议录用','建议录用'),('待定','待定'),('放弃','放弃'))
# 候选人学历
DEGREE_TYPE = (('本科','本科'),('硕士','硕士'),('博士','博士'))
# HR终面结论
HR_SCORE_TYPE = (('S','S'),('A','A'),('B','B'),('C','C'))
class Candidate(models.Model):
# 基础信息
userid = models.IntegerField(unique=True, blank=True, null=True, verbose_name='应聘者ID')
username = models.CharField(max_length=135, verbose_name='姓名')
city = models.CharField(max_length=135, verbose_name='城市')
phone = models.CharField(max_length=135, verbose_name='手机号码')
email = models.EmailField(max_length=135, blank=True, verbose_name='邮箱')
apply_position = models.CharField(max_length=135, blank=True, verbose_name='应聘职位')
born_address = models.CharField(max_length=135, blank=True, verbose_name='生源地')
gender = models.CharField(max_length=135, blank=True, verbose_name='性别')
candidate_remark = models.CharField(max_length=135, blank=True, verbose_name='候选人信息备注')
# 学校与学历信息
bachelor_school = models.CharField(max_length=135, blank=True, verbose_name=' 本科学校')
master_school = models.CharField(max_length=135, blank=True, verbose_name='研究生学校')
doctor_school = models.CharField(max_length=135, blank=True, verbose_name='博士生学校')
major = models.CharField(max_length=135, blank=True, verbose_name='专业')
degree = models.CharField(max_length=135, choices=DEGREE_TYPE, blank=True, verbose_name='学历')
# 综合能力测评成绩,笔试测评成绩
test_score_of_general_ability = models.DecimalField(decimal_places=1,null=True,max_digits=3,blank=True,
verbose_name='综合能力测评成绩')
paper_score = models.DecimalField(decimal_places=1, null=True, max_digits=3, blank=True, verbose_name='笔试成绩')
# 第一轮面试记录
first_score = models.DecimalField(decimal_places=1, null=True, max_digits=2, blank=True, verbose_name='初始分')
first_learning_ability = models.DecimalField(decimal_places=1, null=True, max_digits=2, blank=True, verbose_name='学习能力得分')
first_professional_competency = models.DecimalField(decimal_places=1, null=True, max_digits=2, blank=True, verbose_name='专业能力得分')
first_advantage = models.TextField(max_length=1024, blank=True, verbose_name='优势')
first_disadvantage = models.TextField(max_length=1024, blank=True, verbose_name='顾虑和不足')
first_result = models.CharField(max_length=256, choices=FIRST_INTERVIEW_RESULT_TYPE, blank=True,
verbose_name='初试结果')
first_recommend_position = models.CharField(max_length=256, blank=True, verbose_name='推荐部门')
first_interviewer = models.CharField(max_length=256, blank=True, verbose_name='初试面试官')
first_remark = models.CharField(max_length=135, blank=True, verbose_name='初试备注')
# 第二轮面试记录
second_score = models.DecimalField(decimal_places=1, null=True, max_digits=2, blank=True, verbose_name='专业复试得分')
second_learning_ability = models.DecimalField(decimal_places=1, null=True, max_digits=2, blank=True,
verbose_name='学习能力得分')
second_professional_competency = models.DecimalField(decimal_places=1, null=True, max_digits=2, blank=True,
verbose_name='专业能力得分')
second_pursue_of_excellence = models.DecimalField(decimal_places=1, null=True, max_digits=2, blank=True,
verbose_name='追求卓越得分')
second_communication_ability = models.DecimalField(decimal_places=1, null=True, max_digits=2, blank=True,
verbose_name='沟通能力得分')
second_pressure_score = models.DecimalField(decimal_places=1, null=True, max_digits=2, blank=True,
verbose_name='抗压能力得分')
second_advantage = models.TextField(max_length=1024, blank=True, verbose_name='优势')
second_disadvantage = models.TextField(max_length=1024, blank=True, verbose_name='顾虑和不足')
second_result = models.CharField(max_length=256, choices=INTERVIEW_RESULT_TYPE, blank=True,
verbose_name='专业复试结果')
second_recommend_position = models.CharField(max_length=256, blank=True, verbose_name='建议方向或推荐部门')
second_interviewer = models.CharField(max_length=256, blank=True, verbose_name='专业复试面试官')
second_remark = models.CharField(max_length=135, blank=True, verbose_name='专业复试备注')
# HR终面
hr_score = models.CharField(max_length=10, choices=HR_SCORE_TYPE, blank=True,
verbose_name='HR复试综合等级')
hr_responsibility = models.CharField(max_length=10, choices=HR_SCORE_TYPE, blank=True,
verbose_name='HR责任心')
hr_communication_ability = models.CharField(max_length=10, choices=HR_SCORE_TYPE, blank=True,
verbose_name='HR坦诚沟通')
hr_logic_ability = models.CharField(max_length=10, choices=HR_SCORE_TYPE, blank=True,
verbose_name='HR逻辑思维')
hr_potential = models.CharField(max_length=10, choices=HR_SCORE_TYPE, blank=True,
verbose_name='HR发展潜力')
hr_stability = models.CharField(max_length=10, choices=HR_SCORE_TYPE, blank=True,
verbose_name='HR稳定性')
hr_advantage = models.TextField(max_length=1024, blank=True, verbose_name='优势')
hr_disadvantage = models.TextField(max_length=1024, blank=True, verbose_name='顾虑和不足')
hr_result = models.CharField(max_length=256, choices=INTERVIEW_RESULT_TYPE, blank=True,
verbose_name='HR面试结果')
hr_interviewer = models.CharField(max_length=256, blank=True, verbose_name='HR面试官')
hr_remark = models.CharField(max_length=135, blank=True, verbose_name='HR复试备注')
creator = models.CharField(max_length=256, blank=True, verbose_name='候选人数据的创建人')
created_date = models.DateTimeField(auto_now_add=True, verbose_name="创建时间")
modified_date = models.DateTimeField(auto_now_add=True, null=True, blank=True, verbose_name="更新时间")
last_editor = models.CharField(max_length=256, blank=True, verbose_name='最后编辑者')
class Meta:
db_table = 'candidate'
verbose_name = '应聘者'
verbose_name_plural = '应聘者'
def __str__(self):
return self.username然后在 admin.py 文件注册数据模型,并且展示时隐藏一些字段
from django.contrib import admin
from interview.models import Candidate
class CandidateAdmin(admin.ModelAdmin):
exclude = ('creator','created_date','modified_date')
list_display = ('username','city','bachelor_school','first_score','first_result','first_interviewer',
'second_result','second_interviewer','hr_score','hr_result','last_editor')
admin.site.register(Candidate,CandidateAdmin)再到 setting.py 文件注册应用
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'jobs',
'interview'
]最后执行数据库迁移,还是那两个命令
makemigrations
migrate效果图如下:

页面分组展示
大家看到这个页面其实非常长,因为我们的字段实在是太多了,用起来很复杂,所以面试官也好,还是hr也好,他们其实不太清楚哪些内容是他需要填的,所以我们对这个页面进行优化,把这个页面的内容分组展示
为了方便,我们使用 pycharm 的代码编辑器,新建一个文本文档,把 models.py 里面的字段粘贴过来,然后在这个文件里面去做批量编辑。
首先 ctrl r 来做一个正则表达式的替换,输入 =.*$
然后点击星号匹配,再点击 replace all ,替换掉所有,再删除一些多余的字段

然后再输入一个空格,再点击 replace all ,替换掉所有的空格
然后再输入 ^ 和 '' ,再点击 replace all ,替换开头为 "

然后再输入 $ 和 '' ,再点击 replace all ,替换结尾为 "

然后再输入 $ 和 , ,再点击 replace all ,替换结尾为 ,

最后点 edit 这里有个 join line,可以把字段都连起来

再删除一些多余的标点,最后的成果如下
#基础信息,学校与学历信息,综合能力测评成绩,笔试测评成绩,
"userid", "username", "city", "phone", "email", "apply_position", "born_address", "gender", "candidate_remark", "bachelor_school", "master_school", "doctor_school", "major", "degree", "test_score_of_general_ability", "paper_score",
#第一轮面试记录,
"first_score", "first_learning_ability", "first_professional_competency", "first_advantage", "first_disadvantage", "first_result", "first_recommend_position", "first_interviewer", "first_remark",
#第二轮面试记录,
"second_score", "second_learning_ability", "second_professional_competency", "second_pursue_of_excellence", "second_communication_ability", "second_pressure_score", "second_advantage", "second_disadvantage", "second_result", "second_recommend_position", "second_interviewer", "second_remark",
#HR终面,
"hr_score", "hr_responsibility", "hr_communication_ability", "hr_logic_ability", "hr_potential", "hr_stability", "hr_advantage", "hr_disadvantage", "hr_result", "hr_interviewer", "hr_remark",
然后把这些字段添加到 admin.py 文件的函数里,同时在字段之前添加小括号来分小组,让一行可以展示多个数据
class CandidateAdmin(admin.ModelAdmin):
...
fieldsets = (
(None,{'fields':("userid", ("username", "city"), ("phone", "email"), ("apply_position", "born_address"), ("gender", "candidate_remark"), ("bachelor_school", "master_school", "doctor_school"), ("major", "degree"), ("test_score_of_general_ability", "paper_score"))}),
('第一轮面试记录', {'fields': (("first_score", "first_learning_ability", "first_professional_competency"), "first_advantage", "first_disadvantage", "first_result", "first_recommend_position", "first_interviewer", "first_remark")}),
('第二轮专业复试记录', {'fields': (("second_score", "second_learning_ability", "second_professional_competency"), ("second_pursue_of_excellence", "second_communication_ability", "second_pressure_score"), "second_advantage", "second_disadvantage", "second_result", "second_recommend_position", "second_interviewer", "second_remark")}),
('HR复试记录', {'fields': (("hr_score", "hr_responsibility", "hr_communication_ability"), ("hr_logic_ability", "hr_potential", "hr_stability"), "hr_advantage", "hr_disadvantage", "hr_result", "hr_interviewer", "hr_remark")})
)刷新界面,发现已经分好组了。这里我就不截图了,太长。
导入候选人 csv 文件
接下来我们再做进一步优化,一般我们都不会自己去输入候选人的基本信息,而是会拿到候选人的 excel 表,或者 csv 文件,那么如何导入候选人 csv 文件呢?
我们在 interview 应用下创建文件夹目录 management/commands ,创建 import_candidates.py 文件,添加如下代码
import csv
from django.core.management import BaseCommand
from interview.models import Candidate
class Command(BaseCommand):
help = "从csv导入候选人基本信息"
def add_arguments(self, parser):
parser.add_argument('--path', type=str)
def handle(self, *args, **options):
path = options['path']
#编码格式选择合适的
with open(path, 'rt',encoding='gbk') as f:
#csv分割符选择合适的,不选默认为','分割
#reader = csv.reader(f,dialect='excel',delimiter=';')
reader = csv.reader(f, dialect='excel')
for row in reader:
candidate = Candidate.objects.create(
username=row[0],
city=row[1],
phone=row[2],
bachelor_school=row[3],
major=row[4],
degree=row[5],
test_score_of_general_ability=row[6],
paper_score=row[7]
)展示一下 excel 的内容
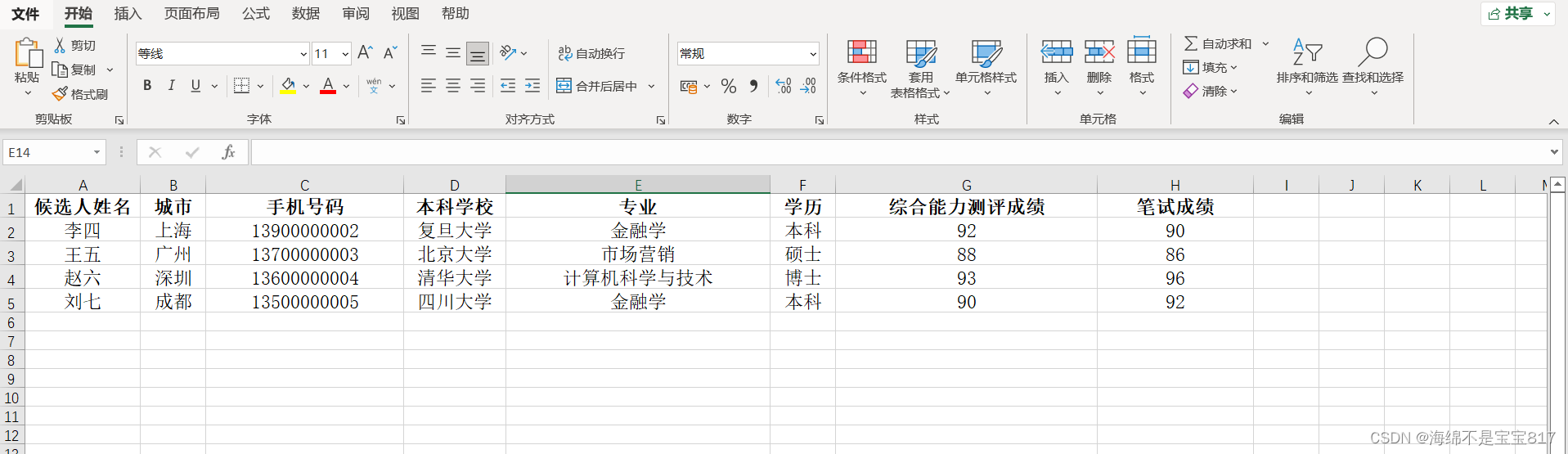
然后把 excel 文件导出为 csv 格式文件,并删除第一行,如下图

在 pycharm 的 run manage.py task 输入命令
import_candidates --path C:/Users/ASUS/Desktop/candidates.csv刷新界面,发现导入成功

提高查询效率
这个时候系统里面有很多简历了,成百上千的简历里面要查找特定候选人的简历,或者按照状态来查询待面试,或者已经面试通过的候选人查找的效率比较低,希望能够快速查询跟筛选,接下来我们实现下面的两个功能。
第一个能够按照名字、手机号码学校来查询候选人
第二个能够按照初试的结果,HR 复试的结果面试官来筛选,然后也能够按照复试结果来排序,复试通过的优先排在前面
修改 admin.py 文件为下面的代码
from django.contrib import admin
from interview.models import Candidate
from datetime import datetime
class CandidateAdmin(admin.ModelAdmin):
exclude = ('creator','created_date','modified_date')
list_display = ('username','city','bachelor_school','first_score','first_result','first_interviewer',
'second_result','second_interviewer','hr_score','hr_result','last_editor')
# 筛选条件
list_filter = ('city','first_result','second_result','hr_result',
'first_interviewer','second_interviewer','hr_interviewer')
# 查询字段
search_fields = ('username','phone','email','bachelor_school')
# 自动排序字段
ordering = ('hr_result','second_result','first_result')
# 分组展示字段
fieldsets = (
(None,{'fields':("userid", ("username", "city"), ("phone", "email"), ("apply_position", "born_address"), ("gender", "candidate_remark"), ("bachelor_school", "master_school", "doctor_school"), ("major", "degree"), ("test_score_of_general_ability", "paper_score"))}),
('第一轮面试记录', {'fields': (("first_score", "first_learning_ability", "first_professional_competency"), "first_advantage", "first_disadvantage", "first_result", "first_recommend_position", "first_interviewer", "first_remark")}),
('第二轮专业复试记录', {'fields': (("second_score", "second_learning_ability", "second_professional_competency"), ("second_pursue_of_excellence", "second_communication_ability", "second_pressure_score"), "second_advantage", "second_disadvantage", "second_result", "second_recommend_position", "second_interviewer", "second_remark")}),
('HR复试记录', {'fields': (("hr_score", "hr_responsibility", "hr_communication_ability"), ("hr_logic_ability", "hr_potential", "hr_stability"), "hr_advantage", "hr_disadvantage", "hr_result", "hr_interviewer", "hr_remark")})
)
def save_model(self, request, obj, form, change):
obj.last_editor = request.user.username
if not obj.creator:
obj.creator = request.user.username
obj.modified_date = datetime.now()
obj.save()
admin.site.register(Candidate,CandidateAdmin)效果图:

分配权限
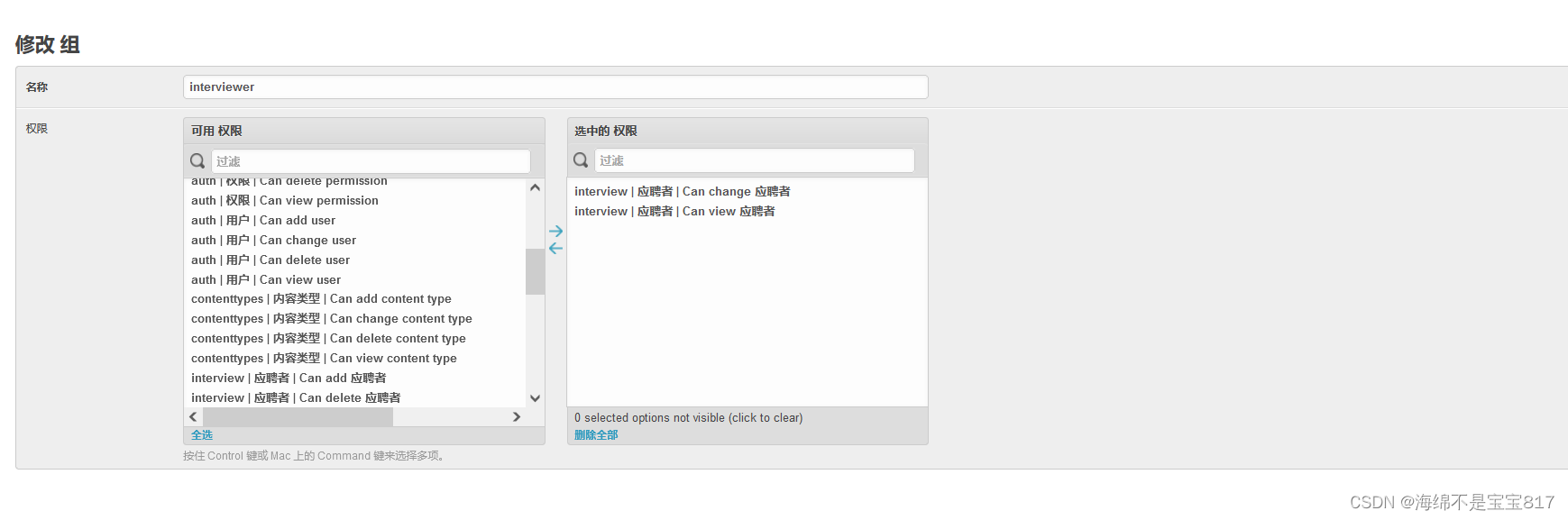
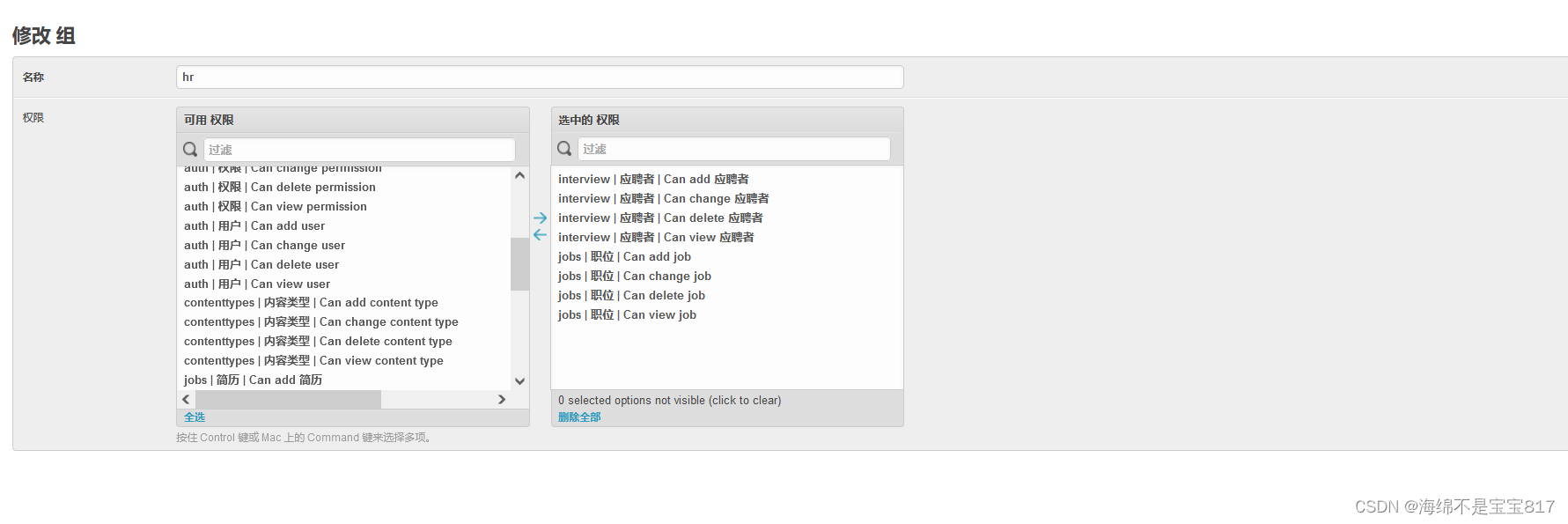
添加 hr 和 interviewer 用户组,分别给 hr 和 面试官不同的权限

导出候选人面试结果 csv 文件
现在我们再加一个功能,将数据导出为 csv 文件,修改 admin.py 文件如下
from django.contrib import admin
from interview.models import Candidate
from datetime import datetime
from django.http import HttpResponse
import csv
exportable_fields = ('username','city',"phone",'bachelor_school','degree','first_result','first_interviewer',
'second_result','second_interviewer','hr_score','hr_result')
def export_model_as_csv(modeladmin,request,queryset):
response = HttpResponse(content_type='text/csv')
field_list = exportable_fields
#可以使用 request 中的 User-Agent 进行客户端系统判断,如果用户的系统是 Windows,那么给导出的文件编码设置为带有 BOM 的 UTF-8,否则使用 UTF-8
response.charset = 'utf-8-sig' if "Windows" in request.headers.get('User-Agent') else 'utf-8'
#Content-Disposition 响应标头指示回复的内容该以何种形式展示,是以内联的形式(即网页或者页面的一部分),还是以附件的形式下载并保存到本地
response['Context-Disposition'] = 'attachment;filename="recruitment-candidates-list-%s.csv"' %(
datetime.now().strftime('%Y-%m-%d-%H-%M-%S')
)
# 写入表头
print(response['Context-Disposition'])
writer = csv.writer(response)
writer.writerow(
[queryset.model._meta.get_field(f).verbose_name.title() for f in field_list]
)
for obj in queryset:
# 单行的记录(各个字段的值),写入csv文件
csv_line_values = []
for field in field_list:
field_object = queryset.model._meta.get_field(field)
field_value = field_object.value_from_object(obj)
csv_line_values.append(field_value)
writer.writerow(csv_line_values)
return response
#国际化文本
export_model_as_csv.short_description = '导出为CSV文件'
class CandidateAdmin(admin.ModelAdmin):
actions = [export_model_as_csv]
exclude = ('creator','created_date','modified_date')
list_display = ('username','city','bachelor_school','first_score','first_result','first_interviewer',
'second_result','second_interviewer','hr_score','hr_result','last_editor')
# 筛选条件
list_filter = ('city','first_result','second_result','hr_result',
'first_interviewer','second_interviewer','hr_interviewer')
# 查询字段
search_fields = ('username','phone','email','bachelor_school')
# 自动排序字段
ordering = ('hr_result','second_result','first_result')
# 分组展示字段
fieldsets = (
(None,{'fields':("userid", ("username", "city"), ("phone", "email"), ("apply_position", "born_address"), ("gender", "candidate_remark"), ("bachelor_school", "master_school", "doctor_school"), ("major", "degree"), ("test_score_of_general_ability", "paper_score"))}),
('第一轮面试记录', {'fields': (("first_score", "first_learning_ability", "first_professional_competency"), "first_advantage", "first_disadvantage", "first_result", "first_recommend_position", "first_interviewer", "first_remark")}),
('第二轮专业复试记录', {'fields': (("second_score", "second_learning_ability", "second_professional_competency"), ("second_pursue_of_excellence", "second_communication_ability", "second_pressure_score"), "second_advantage", "second_disadvantage", "second_result", "second_recommend_position", "second_interviewer", "second_remark")}),
('HR复试记录', {'fields': (("hr_score", "hr_responsibility", "hr_communication_ability"), ("hr_logic_ability", "hr_potential", "hr_stability"), "hr_advantage", "hr_disadvantage", "hr_result", "hr_interviewer", "hr_remark")})
)
def save_model(self, request, obj, form, change):
obj.last_editor = request.user.username
if not obj.creator:
obj.creator = request.user.username
obj.modified_date = datetime.now()
obj.save()
admin.site.register(Candidate,CandidateAdmin)效果图:

点击执行成功下载,打开文件效果如下
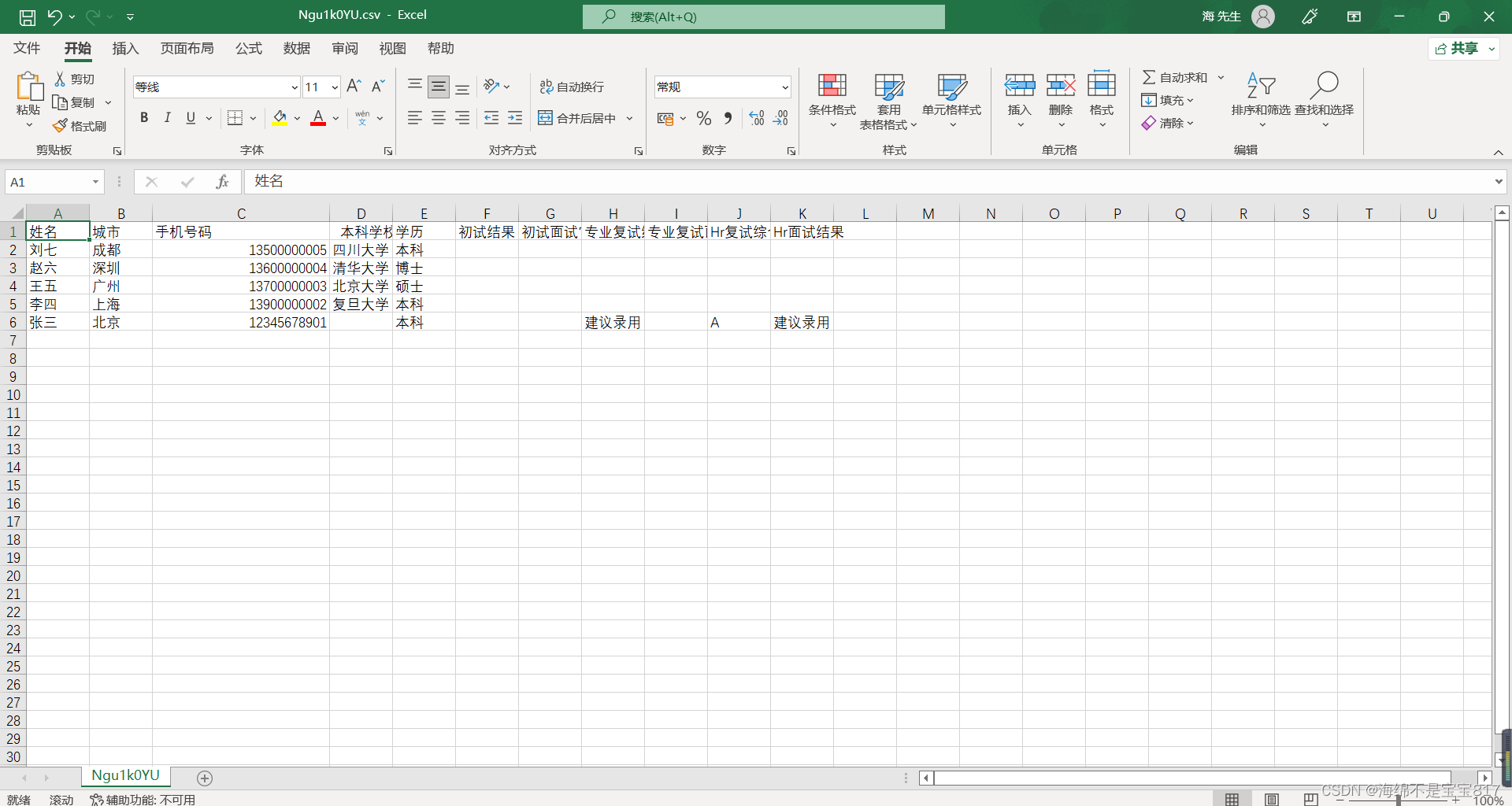
目前这个导出 csv 文件的文件名会显示乱码,并不能输出我们期望的文件名,暂时我并没有找到解决方法,如果有写出来的大佬,务必私信我,感谢!!!
第四阶段完成!