一、定义
- qwen-moe 代码讲解, 代码qwen-moe与Mixtral-moe 一样, 专家模块
- qwen-moe 开源教程
- Mixture of Experts (MoE) 模型在Transformer结构中如何实现,Gate的实现一般采用什么函数? Sparse MoE的优势有哪些?MoE是如何提高模型容量而不显著增加计算负
担的?
二、实现
- qwen-moe 代码讲解
参考:https://blog.csdn.net/v_JULY_v/article/details/135176583?utm_medium=distribute.pc_relevant.none-task-blog-2defaultbaidujs_baidulandingword~default-0-135176583-blog-135046508.235v43pc_blog_bottom_relevance_base4&spm=1001.2101.3001.4242.1&utm_relevant_index=3
import torch
from torch import nn
from torch.nn import functional as F
from transformers.activations import ACT2FN
class Qwen2MoeMLP(nn.Module):
def __init__(self, config, intermediate_size=None):
super().__init__()
self.config = config
self.hidden_size = config.hidden_size
self.intermediate_size = intermediate_size
self.gate_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
self.up_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
self.down_proj = nn.Linear(self.intermediate_size, self.hidden_size, bias=False)
#self.act_fn = ACT2FN[config.hidden_act]
def forward(self, x):
return self.down_proj(self.gate_proj(x) * self.up_proj(x))
class Qwen2MoeSparseMoeBlock(nn.Module):
def __init__(self, config):
super().__init__()
self.num_experts = config.num_experts
self.top_k = config.num_experts_per_tok
self.norm_topk_prob = config.norm_topk_prob
# gating
self.gate = nn.Linear(config.hidden_size, config.num_experts, bias=False)
self.experts = nn.ModuleList(
[Qwen2MoeMLP(config, intermediate_size=config.moe_intermediate_size) for _ in range(self.num_experts)]
)
self.shared_expert = Qwen2MoeMLP(config, intermediate_size=config.shared_expert_intermediate_size)
self.shared_expert_gate = torch.nn.Linear(config.hidden_size, 1, bias=False)
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
""" """
batch_size, sequence_length, hidden_dim = hidden_states.shape
hidden_states = hidden_states.view(-1, hidden_dim)
# router_logits: (batch * sequence_length, n_experts)
router_logits = self.gate(hidden_states)
routing_weights = F.softmax(router_logits, dim=1, dtype=torch.float)
#选取每个token 对应的前k 个专家
routing_weights, selected_experts = torch.topk(routing_weights, self.top_k, dim=-1)
if self.norm_topk_prob:
routing_weights /= routing_weights.sum(dim=-1, keepdim=True) #权重归一化 确保每个token的专家权重之和为1
# we cast back to the input dtype
routing_weights = routing_weights.to(hidden_states.dtype)
#全为0的张量
final_hidden_states = torch.zeros(
(batch_size * sequence_length, hidden_dim), dtype=hidden_states.dtype, device=hidden_states.device
)
# One hot encode the selected experts to create an expert mask
# this will be used to easily index which expert is going to be sollicitated
expert_mask = torch.nn.functional.one_hot(selected_experts, num_classes=self.num_experts).permute(2, 1, 0) #稀疏矩阵
# Loop over all available experts in the model and perform the computation on each expert
for expert_idx in range(self.num_experts):
expert_layer = self.experts[expert_idx] # 第idx 专家对应的函数
idx, top_x = torch.where(expert_mask[expert_idx]) #idx 专家,关注的token, top_x 对应第x 个token
print(expert_idx,top_x.cpu().tolist() ) #专家,处理的token
# Index the correct hidden states and compute the expert hidden state for
# the current expert. We need to make sure to multiply the output hidden
# states by `routing_weights` on the corresponding tokens (top-1 and top-2) 专家输入信息:
current_state = hidden_states[None, top_x].reshape(-1, hidden_dim) #取出对应的token信息
current_hidden_states = expert_layer(current_state) * routing_weights[top_x, idx, None] #专家输出
# However `index_add_` only support torch tensors for indexing so we'll use
# the `top_x` tensor here. 使用.index_add_函数后在指定位置(top_x)加上了指定值(current_hidden_states)
final_hidden_states.index_add_(0, top_x, current_hidden_states.to(hidden_states.dtype))
shared_expert_output = self.shared_expert(hidden_states)
shared_expert_output = F.sigmoid(self.shared_expert_gate(hidden_states)) * shared_expert_output
final_hidden_states = final_hidden_states + shared_expert_output
final_hidden_states = final_hidden_states.reshape(batch_size, sequence_length, hidden_dim)
return final_hidden_states, router_logits
# 假设的配置
class Config:
def __init__(self):
self.num_experts = 8
self.num_experts_per_tok = 2
self.norm_topk_prob = True
self.hidden_size = 2
self.moe_intermediate_size = 209
self.shared_expert_intermediate_size = 20
# 检查是否有可用的GPU
device = torch.device("cpu")
# 创建模型实例
config = Config()
model = Qwen2MoeSparseMoeBlock(config).to(device)
input_tensor = torch.randn(1,3,2).to(device)
# 前向传播
output = model(input_tensor)
print(output)
注意:1. 常规思路: 每个token 选择2 个专家, 然后每个token 传入2个专家中,进行处理。----->为了加快推理速度----->关注视角由token 转为专家。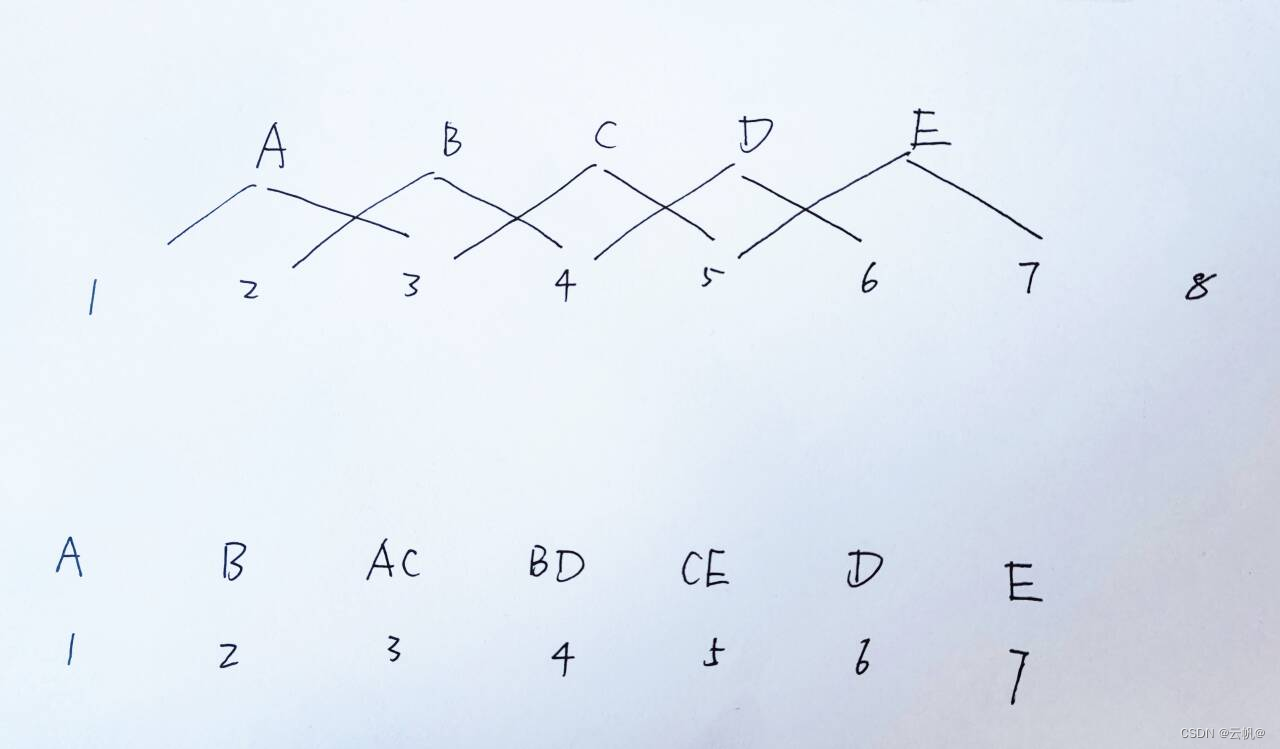
便把关注视角从“各个token”变成了“各个专家”,当然,大部分情况下 token数远远不止下图这5个,而是比专家数多很多。总之,这么一转换,最终可以省掉很多循环。
遍历每个专家,对token 对应的信息整体输入专家模块。
# 【代码块A】routing_weights
# 每行对应1个token,第0列为其对应排位第1的expert、第1列为其对应排位第2的expert,元素值为相应权重
[[0.5310, 0.4690],
[0.5087, 0.4913],
[0.5014, 0.4986],
[0.5239, 0.4761],
[0.5817, 0.4183],
[0.5126, 0.4874]]
# 【代码块B】expert_mask[expert_idx]
# 下述两行例子的物理含义为:
# 第一行是“该expert作为排位1的exert存在时,需要处理第9个token;
# 第二行是“该expert作为排位2的expert存在时,需要处理第10、11个token”
[[0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0]]
# 【代码块C】idx, top_x = torch.where(expert_mask[expert_idx])
# 以上述expert_mask[expert_idx]样例为例,对应的torch.where(expert_mask[expert_idx])结果如下
idx: [0, 1, 1]
top_x: [9, 10, 11]
idx对应行索引,top_x对应列索引,例如张量expert_mask[expert_idx]中,出现元素1的索引为(0, 9)、(1, 10)、(1, 11)
从物理含义来理解,top_x实际上就对应着“关乎当前expert的token索引”,第9、第10、第11个token被“路由”导向了当前所关注的expert,通过top_x可以取到“需要传入该expert的输入”,也即第9、第10、第11个token对应的隐向量
因此top_x将作为索引用于从全部token的隐向量hidden_states中取出对应token的隐向量
而idx和top_x也会组合起来被用于从expert权重张量routing_weights中取出对应的权重
current_state = hidden_states[None, top_x].reshape(-1, hidden_dim) #取出top_x的token信息
current_hidden_states = expert_layer(current_state) * routing_weights[top_x, idx, None] #专家输出
# However `index_add_` only support torch tensors for indexing so we'll use
# the `top_x` tensor here. 使用.index_add_函数后在指定位置(top_x)加上了指定值(current_hidden_states)
final_hidden_states.index_add_(0, top_x, current_hidden_states.to(hidden_states.dtype))
-
开源教程
https://developer.aliyun.com/article/1471903?spm=a2c6h.28954702.blog-index-detail.67.536b4c2d9ZzdBw -
Mixture of Experts (MoE) 模型在Transformer结构中如何实现,Gate的实现一般采用什么函数? Sparse MoE的优势有哪些?MoE是如何提高模型容量而不显著增加计算负担的?
self.gate = nn.Linear(config.hidden_size, config.num_experts, bias=False)