文章目录
- 一、说明
- 二、强化学习:特征选择的马尔可夫决策问题
- 三、用于使用强化学习进行特征选择的 python 库
- 3.1. 数据预处理
- 3.2. 安装和导入FSRLearning库
- 四、结论和参考文献
一、说明
了解强化学习如何改变机器学习模型的特征选择。通过实际示例和专用的 Python 库了解这种创新方法的过程、实现和好处。
特征选择是构建机器学习模型过程中的决定性步骤。为模型和我们想要实现的任务选择好的功能绝对可以提高性能。事实上,一个特征可能会增加一些噪声,然后干扰模型。
此外,如果我们要处理高维数据集,选择特征尤其重要。它使模型能够更快、更好地学习。然后,我们的想法是找到最佳数量的功能和最有意义的功能。
在本文中,我将解决这个问题,并通过介绍一种新实现的特征选择方法来解决这个问题。尽管它存在许多不同的功能选择过程,但这里不会介绍它们,因为很多文章已经在处理它们。我将重点介绍使用强化学习策略的特征选择。
首先,将讨论强化学习,尤其是马尔可夫决策过程。这是数据科学领域的一种非常新的方法,尤其是对于特征选择目的。之后,我将介绍它的实现以及如何安装和使用 python 库 (FSRLearning)。最后,我将证明这种实现的效率。在包装器或过滤等可能的特征选择方法中,强化学习是最强大和最有效的。
本文的目的是强调具体和面向实际问题的利用的实现。这个问题的理论方面将通过示例进行简化,尽管最后将提供一些参考资料。
二、强化学习:特征选择的马尔可夫决策问题
已经证明,强化学习 (RL) 技术对于解决游戏等问题非常有效。RL的概念基于马尔可夫决策过程(MDP)。这里的重点不是要深入定义 MDP,而是要大致了解它是如何工作的,以及它如何对我们的问题有用。
RL 背后的天真想法是代理从未知环境中开始。此代理必须执行操作才能完成任务。根据智能体的当前状态和他之前选择的动作,智能体会更倾向于选择一些动作。在达到每个新状态并采取任何行动时,代理都会获得奖励。以下是我们需要为特征选择目的定义的主要参数:
- 什么是状态?
- 什么是动作?
- 奖励是什么?
- 我们如何选择一个动作?
首先,状态只是数据集中存在的特征的子集。例如,如果数据集具有三个特征(年龄、性别、身高)和一个标签,则可能是以下状态:
[] --> Empty set
[Age], [Gender], [Height] --> 1-feature set
[Age, Gender], [Gender, Height], [Age, Height] --> 2-feature set
[Age, Gender, Height] --> All-feature set
在某种状态下,特征的顺序无关紧要,本文稍后将解释为什么。我们必须将其视为一个集合,而不是一个功能列表。
关于操作,我们可以从一个子集转到任何其他子集,其特征尚未探索的特征比当前状态多。在要素选择问题中,操作是在当前状态下选择尚未探索的要素,并将其添加到下一个状态。下面是可能操作的示例:
[Age] -> [Age, Gender]
[Gender, Height] -> [Age, Gender, Height]
下面是一个不可能的操作示例:
[Age] -> [Age, Gender, Height]
[Age, Gender] -> [Age]
[Gender] -> [Gender, Gender]
我们已经定义了状态和行动,但没有定义奖励。奖励是用于评估状态质量的实数。例如,如果一个机器人试图到达迷宫的出口,并决定去出口作为他的下一个动作,那么与这个动作相关的奖励将是“好的”。如果他选择进入陷阱作为下一步行动,那么奖励将是“不好的”。奖励是一个值,它带来了有关先前所采取的行动的信息。
在特征选择问题中,一个有趣的奖励可能是通过添加新特征添加到模型中的准确性值。以下是奖励计算方法的示例:
[Age] --> Accuracy = 0.65
[Age, Gender] --> Accuracy = 0.76
Reward(Gender) = 0.76 - 0.65 = 0.11
对于我们第一次访问的每个州,分类器都将使用特征集进行训练。此值存储在状态中,即使稍后再次达到该状态,分类器的训练也只会发生一次,这非常昂贵。分类器不考虑特征的顺序。这就是为什么我们可以把这个问题看作是一个图,而不是一棵树。在此示例中,选择“性别”作为模型的新特征的操作的奖励是当前状态与下一状态的准确性之间的差值。
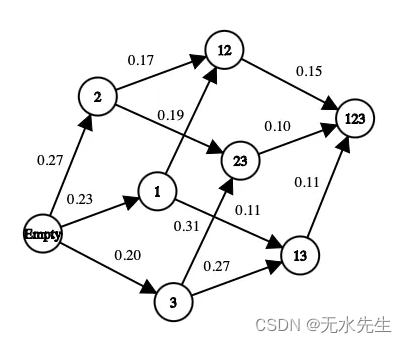
每个状态都有几个可能的行动和奖励(图片由作者提供)
在上图中,每个特征都映射到一个数字(即“年龄”是 1,“性别”是 2,“身高”是 3)。完全可以采用其他指标来最大化以找到最佳集。在许多业务应用中,召回率比准确性更重要。
下一个重要的问题是我们如何从当前状态中选择下一个状态,或者我们如何探索我们的环境。我们必须找到最佳方法来做到这一点,因为它很快就会成为一个非常复杂的问题。事实上,如果我们天真地探索一个有 10 个特征的问题中所有可能的特征集,那么状态的数量将是
10! + 2 = 3 628 802 possible states
+2 是因为我们考虑了一个空状态和一个包含所有可能特征的状态。在这个问题上,我们必须在所有状态上训练相同的模型,以获得最大化准确性的特征集。在 RL 方法中,我们不必进入所有状态,也不必每次进入已经访问过的州时都训练模型。
我们必须为这个问题确定一些停止条件,稍后将详细介绍。目前,已经选择了 epsilon-greedy 状态选择。这个想法是从当前状态开始,我们随机选择下一个动作,概率为 epsilon(介于 0 和 1 之间,通常在 0.2 左右),否则选择使函数最大化的动作。对于特征选择,函数是每个特征为模型精度带来的奖励的平均值。
epsilon-greedy 算法包含两个步骤:
随机相位:使用概率 epsilon,我们在当前状态的可能邻居中随机选择下一个状态(我们可以想象均匀或 softmax 选择)
贪婪阶段:我们选择下一个状态,使添加到当前状态的特征对模型的精度贡献最大。为了降低时间复杂性,我们初始化了一个包含每个特征的此值的列表。每次选择功能时,此列表都会更新。由于以下公式,更新非常优化:

更新每个功能的平均奖励列表(图片由作者提供)
AORf : 功能“f”带来的平均奖励
k : 选择“f”的次数
V(F) :特征集 F 的状态值(出于清晰起见,本文未详述)
全局的想法是找出哪个特征为模型带来了最大的准确性。这就是为什么我们需要浏览不同的状态,以便在许多不同的环境中评估模型特征的最全局准确值。
最后,我将详细介绍两个停止条件。由于目标是最小化算法访问的状态数量,因此我们需要小心它们。我们访问的从未访问过的州越少,我们必须使用不同特征集训练的模型数量就越少。就时间和计算能力而言,训练模型以获得准确性是最昂贵的阶段。
在任何情况下,该算法都会在最终状态(包含所有特征的集合)中停止。我们希望避免达到这种状态,因为它是训练模型最昂贵的。
此外,如果一系列访问状态的值连续下降,它会停止浏览图形。设置了一个阈值,使得数据集中总要素数的平方根之后,该阈值将停止探索。
现在已经解释了问题的建模,我们将详细介绍 python 中的实现。
三、用于使用强化学习进行特征选择的 python 库
可以使用解决此问题的 python 库。我将在这一部分中解释它是如何工作的,并证明它是一种有效的策略。此外,本文作为文档,您将能够在本部分结束时将此库用于您的项目。
3.1. 数据预处理
由于我们需要评估所访问状态的准确性,因此我们需要为模型提供用于此特征选择任务的特征和数据。数据必须经过归一化,分类变量必须编码,并且行数尽可能少(行越小,算法越快)。此外,如上一部分所述,在要素和一些整数之间创建映射非常重要。此步骤不是强制性的,但非常推荐。此步骤的最终结果是获取一个包含所有特征的 DataFrame,以及另一个包含要预测的标签的 DataFrame。下面是一个使用数据集作为基准的示例(可以在此处找到
#Get the pandas DataFrame from the csv file (15 features, 690 rows)
australian_data = pd.read_csv('australian_data.csv', header=None)
#DataFrame with the features
X = australian_data.drop(14, axis=1)
#DataFrame with the labels
y = australian_data[14]
3.2. 安装和导入FSRLearning库
第二步是使用 pip 安装库。以下是安装它的命令:
pip install FSRLearning
若要导入库,可以使用以下代码:
from FSRLearning import Feature_Selector_RL
只需创建对象Feature_Selector_RL即可创建功能选择器。需要填写一些参数。
- feature_number (integer) : DataFrame X 中的要素数
- feature_structure (dictionary) : 图实现的字典
- eps (float [0; 1]) : 选择随机下一个状态的概率,0 是唯一贪婪算法,1 是唯一随机算法
- alpha (float [0; 1]):控制更新速率,0 表示非常不更新状态,1 表示非常更新
- gamma (浮点 [0, 1]):观察下一个状态的调节因子,0 表示近视条件,1 表示远视行为
- nb_iter (int):要通过图形的序列数
- starting_state (“empty” or “random”) : 如果 “empty”,则算法从空状态开始,如果 “random”,则算法从图中的随机状态开始
所有参数都可以调整,但对于大多数问题来说,只有少数迭代可以是好的(大约 100 次),而 0.2 左右的 epsilon 值通常就足够了。起始状态对于更有效地浏览图形很有用,但它可能非常依赖于数据集,并且可以测试这两个值。
最后,我们可以非常简单地使用以下代码初始化选择器:
fsrl_obj = Feature_Selector_RL(feature_number=14, nb_iter=100)
选择器对象初始化与大多数 ML 库一样,训练算法非常容易:
results = fsrl_obj.fit_predict(X, y)
下面是输出的示例:

选择器的输出(图片由作者提供)
输出是一个 5 元组,如下所示:
- DataFrame X 中特征的索引(如映射)
- 观察到该特征的次数或次数
- 所有迭代后功能带来的平均奖励
- 功能从最不重要到最重要的排名(这里 2 是最少的,7 是最重要的功能)
- 全局可访问的状态数
此选择器的另一个重要方法是与 Scikit-Learn 的 RFE 选择器进行比较。它以输入 X、y 和选择器的结果为输入。
fsrl_obj.compare_with_benchmark(X, y, results)
输出是在选择 RFE 和 FSRLearning 的全局指标的每个步骤之后的打印。它还输出模型精度的可视化比较,在 x 轴上是选择的特征数量,在 y 轴上是精度。两条水平线是每种方法的精度中位数。下面是一个示例:

RL和RFE方法的比较(图片由作者提供)
Average benchmark accuracy : 0.854251012145749, rl accuracy : 0.8674089068825909
Median benchmark accuracy : 0.8552631578947368, rl accuracy : 0.868421052631579
Probability to get a set of variable with a better metric than RFE : 1.0
Area between the two curves : 0.17105263157894512
在此示例中,RL 方法始终为模型提供比 RFE 更好的特征集。然后,我们可以在排序的特征集中确定地选择任何子集,这将为模型提供更好的准确性。我们可以多次运行模型和比较器以获得非常准确的估计,但 RL 方法总是更好。
另一个有趣的方法是get_plot_ratio_exploration。它绘制一个图表,比较已访问节点的数量和按顺序访问的节点的数量,以便进行精确迭代。

每次迭代时访问和未访问状态的比较(图片由作者提供)
此外,由于第二个停止条件,算法的时间复杂度呈指数级降低。那么即使特征的数量很大,也会很快找到收敛点。下面的图是访问一定大小的集合的次数。

访问状态的数量与其大小的函数关系
在所有迭代中,该算法访问了包含 6 个或更少变量的状态。除了 6 个变量之外,我们可以看到达到的状态数量正在减少。这是一种很好的行为,因为训练具有小特征集的模型比训练大特征集的模型更快。
四、结论和参考文献
总的来说,我们可以看到RL方法对于最大化模型的指标非常有效。它总是快速收敛到一个有趣的特征子集。此外,此方法在具有 FSRLearning 库的 ML 项目中非常容易和快速实现。
![[Linux]重定向](https://img-blog.csdnimg.cn/direct/b0e37cf2cfb145daaed2b0fffaaf81a4.png)