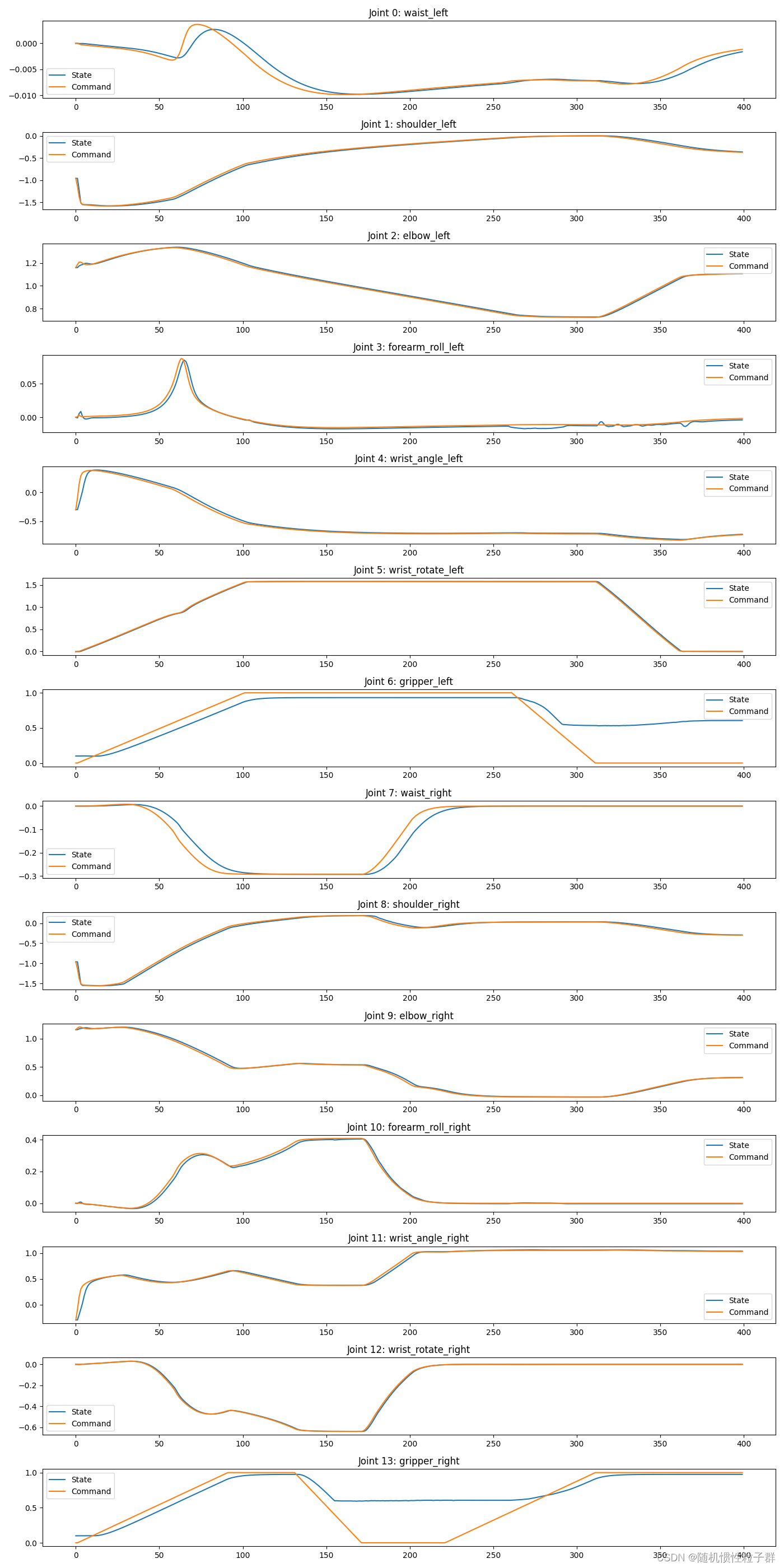
前段时间,在2024年NVIDIA GTC大会上,英伟达不小心透露了GPT-4采用了MoE架构,模型有1.8万亿参数,由8个220B模型组成,与此前的GPT-4泄露的信息一致。
近半年多以来,各类MoE大模型更是层出不穷。在海外,除了GPT-4,谷歌推出Gemini、Mistral AI推出Mistral、连马斯克xAI的最新大模型Grok-1用的也是MoE架构。
在国内,MiniMax在今年年初就全量发布大语言模型abab6,该模型为国内首个MoE模型,直接对标GPT-4。昆仑万维也于今年4月17日正式推出了新版MoE大语言模型「天工3.0」,拥有4000亿参数,超越了3140亿参数的Grok-1,成为全球最大的开源MoE大模型。
在各大模型厂商还在不断卷模型参数规模的今天,无论是互联网巨头,还是独角兽公司,都不约而同地选择了MOE作为大模型后续迭代的方向。
结合近期国内掀起的大模型降价浪潮,让我们不禁猜测模型成本下降的背后是否和采用新的MOE架构有关,毕竟原来一个千亿级别的通用大模型现在可能只需要几个百亿级别的MOE模型就能达到相同的效果,而训练一个千亿大模型和百亿大模型需要的成本却差了一个数量级。
下面,让我们一起来揭开MoE的神秘面纱吧。
1、什么是MoE?
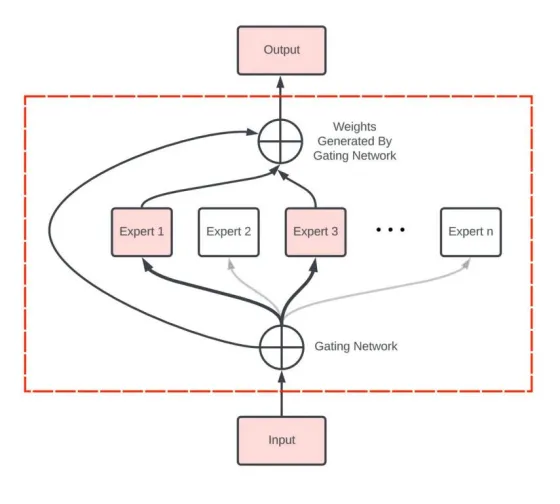
MoE,全称Mixture of Experts,混合专家模型。MoE是大模型架构的一种,其核心工作设计思路是“术业有专攻”,即将任务分门别类,然后分给多个“专家”进行解决。与MoE相对应的概念是稠密(Dense)模型,可以理解为它是一个“通才”模型。一个通才能够处理多个不同的任务,但一群专家能够更高效、更专业地解决多个问题。
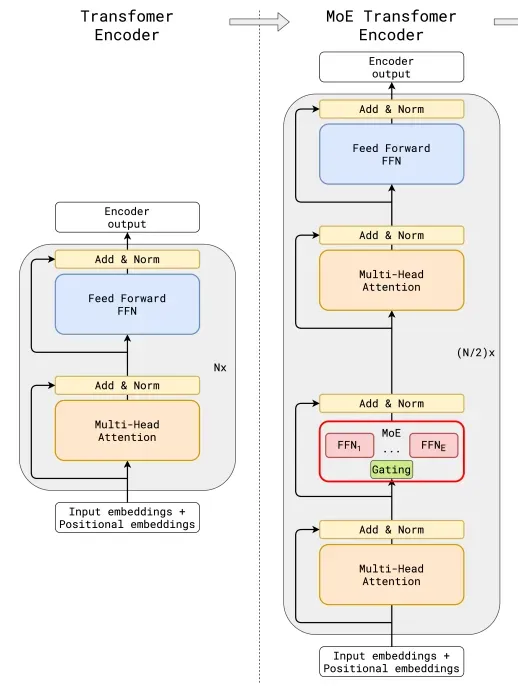
上图中,左侧图为传统大模型架构,右图为MoE大模型架构。两图对比可以看到,与传统大模型架构相比,MoE架构在数据流转过程中集成了一个专家网络层(红框部分)。下图为红框内容的放大展示:
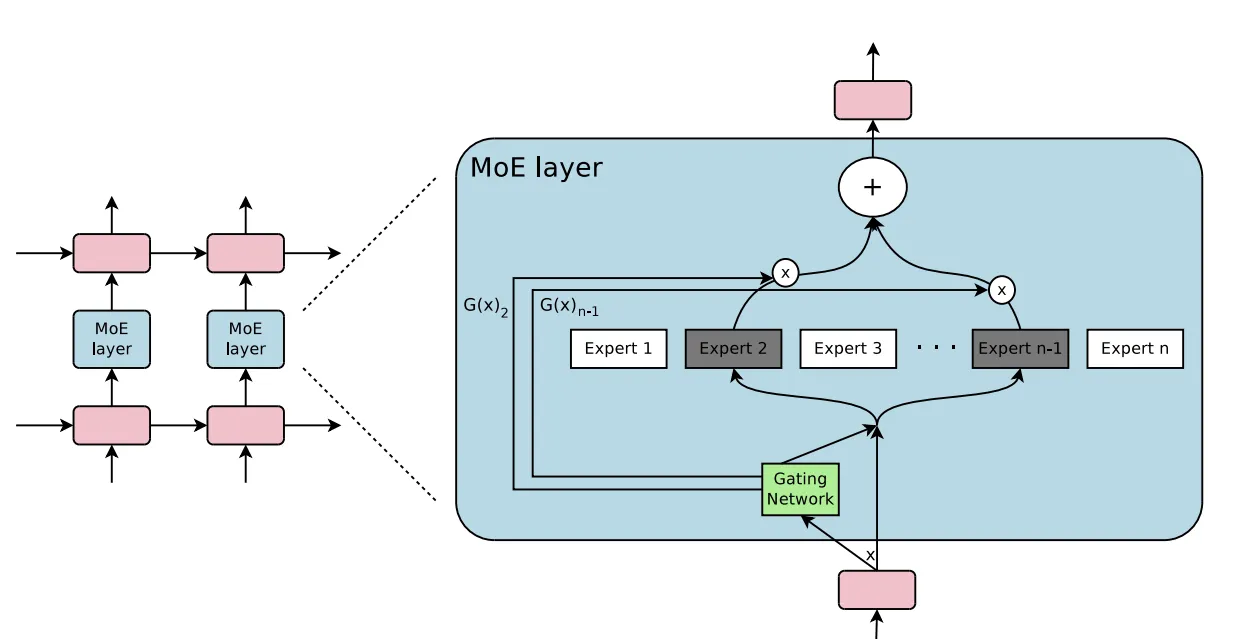
专家网络层的核心由门控网络(Gating Network)和一组专家模型(Experts)构成,其工作流程大致如下:
- 数据首先会被分割多个区块(Token),每组数据进入专家网络层时,首先会进入门控网络;
- 门控网络将每组数据分配给一个或多个专家,每个专家模型可以专注于处理该部分数据,“让专业的人做专业的事”;
- 最终,所有专家的输出结果汇总,系统进行加权融合,得到最终输出。
2、MOE的设计
MoE架构的核心思想是将一个复杂的问题分解成多个更小、更易于管理的子问题,并由不同的专家网络分别处理。这些专家网络专注于解决特定类型的问题,通过组合各自的输出来提供最终的解决方案,提高模型的整体性能和效率。
MOE的设计一般包括以下步骤:
(1)专家模型的选择与训练:
- 每个专家模型通常是针对特定任务或特定数据进行训练的。这些专家模型可以是不同的神经网络,分别在不同的数据集上进行优化,以便在特定领域内具有更好的性能。
- 在训练过程中,专家模型的选择可以基于特定的任务需求或数据特征。例如,可以有专门处理代码数据的专家模型,或者有处理科学论文的专家模型。
(2)门控机制(Gating Mechanism):
- 混合专家模型的核心在于门控机制,它负责在推理过程中动态选择和组合不同的专家模型。门控机制根据输入数据的特征,决定哪些专家模型对当前任务最有效。
- 常见的门控机制包括软门控(Soft Gating)和硬门控(Hard Gating)。软门控会为每个专家分配一个概率权重,所有专家的输出按照这些权重进行加权平均;硬门控则直接选择一个或几个专家进行输出。
(3)专家模型的组合与输出:
- 在推理阶段,混合专家模型会根据门控机制的选择,将多个专家模型的输出进行组合,以生成最终的结果。
- 这种组合可以是简单的加权求和,也可以是更复杂的融合策略,具体取决于任务的要求和门控机制的设计。
(4)优化与训练策略:
- 为了有效训练混合专家模型,通常需要设计特定的优化策略。例如,可以使用分阶段训练的方法,先分别训练每个专家模型,然后在整体框架中进行联合优化。
- 训练过程中还需要考虑专家模型之间的协同和竞争关系,确保每个专家模型能够在其擅长的领域内充分发挥作用,同时避免不必要的冗余和冲突。
总的来说,混合专家模型通过引入多个专门优化的专家模型,并使用门控机制动态选择和组合这些专家模型的输出,能够在处理复杂任务时表现出更高的灵活性和性能。
3、MOE vs. Dense
MoE(专家混合模型)和Dense(稠密)模型在多个方面存在差异,以下是一些关键点:
| 指标 | MOE | Dense |
|---|---|---|
| 模型结构 | 模型由多个专家组成,每次计算时只有一部分专家被激活,从而减少了计算量。 | 所有参数和激活单元都参与每一次前向和后向传播计算。 |
| 计算效率 | 由于只激活部分专家,计算量和内存需求较少,因此在处理并发查询时具有更高的吞吐量。 | 计算量和内存需求随参数规模线性增长。 |
| 性能 | 可以在保持高效计算的同时,达到与大型Dense模型相似的性能。例如,50B的MoE模型在性能上接近34B的Dense模型。 | 性能稳定,但需要大量计算资源。 |
| 时延 | 由于只需加载部分激活的专家,时延较低,尤其是在并发性较低的情况下。 | 由于需要加载所有参数,时延较高。 |
| 应用场景 | 适用于需要高效处理并发查询的任务,如大规模在线服务。 | 适用于需要稳定性能且计算资源充足的任务。 |
综上,MoE相对于Dense模型有以下几个优势:
- 吞吐量更高:MoE模型的激活单元少于密集层,因此在处理许多并发查询时,MoE模型具有更高的吞吐量。
- 时延更低:当并发性较低时,大部分时间用于将两个激活的专家模型加载到内存中,这比密集层需要的内存访问时间更少,从而降低了时延。
- 更高效的计算:对于单个查询,MoE需要从内存中读取的参数更少,因此在计算效率上优于密集层。
- 性能优越:MoE模型可以在保持小型模型的计算效率的同时,提供接近大型密集模型的强大性能。例如,Mistral MoE模型展示了在降低成本的同时,取得与更大模型相当的性能。
- 灵活性:可以将一个已经训练好的大型密集模型转换为MoE模型,使其具有小型模型的高效计算和大型密集模型的强大性能。
同时,MoE同样存在以下挑战:
- 由于MoE需要把所有专家模型都加载在内存中,这一架构对于显存的压力将是巨大的,通常涉及复杂的算法和高昂的通信成本,并且在资源受限设备上部署受到很大限制。
- 此外,随着模型规模的扩大,MoE同样面临着训练不稳定性和过拟合的问题、以及如何确保模型的泛化性和鲁棒性问题、如何平衡模型性能和资源消耗等种种问题,等待着大模型开发者们不断优化提升。
4、MoE化
将一个Dense模型转换为MoE模型的过程被称为MoE化(MoEfication)。这个过程的目标是保留Dense模型的强大性能,同时通过MoE模型的高效结构实现更高的计算效率。以下是MOE化的关键步骤:
- 分解Dense模型:将Dense模型的参数和计算分解为多个专家模块。每个专家模块只处理输入数据的一部分。
- 门控机制:引入门控(gate)机制,以决定每个输入数据应该由哪些专家模块处理。门控机制可以基于输入数据的特征来动态选择专家。
- 训练MoE模型:使用与Dense模型相同的数据和训练方法,训练新的MoE模型。确保训练过程中门控机制能够有效地选择合适的专家模块。
- 优化和调试:通过实验和调试,优化MoE模型的性能和效率。可以调整门控机制、专家数量等参数,以达到最佳效果。
MoE模型是一种基于“分而治之”策略的神经网络架构,它将复杂的问题分解为多个子问题,每个子问题由一个独立的模型进行处理。这些专家模型可以是任意类型的神经网络,如全连接网络、卷积神经网络或循环神经网络等。MoE模型的核心在于如何有效地结合这些专家模型的输出,以得到最终的预测结果。
【推广时间】
有做模型推理、微调、AI绘画出图,需要GPU资源的朋友们,可以试试UCloud云计算旗下的Compshare这家GPU算力云平台,4090性价比高,单卡按时2.6元,免费200G磁盘。单卡一个月价格在1250元,还是很香的。现在通过链接注册联系客服可以获得20元代金券,同时现在还有个内容激励活动,发布分享一些AI绘画。模型微调、推理,大模型相关的文章带上他们平台,还可以拿500元代金券,可以白嫖好久的算力了,大家可以试试。
高性价比4090算力租用,注册就送20元代金券,更有内容激励活动:GPU算力平台 | 面向AI场景的高性价比GPU租用平台
GPU云服务器租用,P40、4090、V100S多种显卡可选:GPU云服务器租用_GPU云主机限时特惠-UCloud中立云计算服务商





![[MySQL最详细的知识点]](https://img-blog.csdnimg.cn/direct/84fbb9e05e994385bc3bb061b7652f32.png)