技术背景
最近和大模型一起爆火的,还有大模型的微调方法。
这类方法只用很少的数据,就能让大模型在原本表现没那么好的下游任务中“脱颖而出”,成为这个任务的专家。
而其中最火的大模型微调方法,又要属LoRA。
增加数据量和模型的参数量是公认的提升神经网络性能最直接的方法。目前主流的大模型的参数量已扩展至千亿级别,「大模型」越来越大的趋势还将愈演愈烈。
这种趋势带来了多方面的算力挑战。想要微调参数量达千亿级别的大语言模型,不仅训练时间长,还需占用大量高性能的内存资源。
为了让大模型微调的成本「打下来」,微软的研究人员开发了低秩自适应(LoRA)技术。LoRA 的精妙之处在于,它相当于在原有大模型的基础上增加了一个可拆卸的插件,模型主体保持不变。LoRA 随插随用,轻巧方便。
对于高效微调出一个定制版的大语言模型或者大视觉、大多模态模型来说,LoRA 是最为广泛运用的方法之一,同时也是最有效的方法之一。
LoRA微调原理是对预训练模型进行冻结,并在冻结的前提下,向模型中加入额外的网络层,然后只训练这些新增网络层的参数。因为新增参数数量较少,所以finetune的成本显著下降,同时也能获得和全模型微调类似的效果。
LoRA方法的核心思想是,这些大型模型其实是过度参数化的,其中的参数变化可以视为一个低秩矩阵。因此,可以将这个参数矩阵分解成两个较小的矩阵的乘积。在微调过程中,不需要调整整个大型模型的参数,只需要调整低秩矩阵的参数。
有了LoRA这类型的微调方法,可以使得大模型平易近人,可以让更多小公司或个人使用者能简单的在我们自己的数据集中调优模型,微调得到我们期望的输出。
LoRA 简介
LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGEMODELS 该文章在ICLR2022中提出,说的是利用低秩适配(low-rankadaptation)的方法,可以在使用大模型适配下游任务时只需要训练少量的参数即可达到一个很好的效果。
由于 GPU 内存的限制,在训练过程中更新模型权重成本高昂。
例如,假设我们有一个 7B 参数的语言模型,用一个权重矩阵 W 表示。在反向传播期间,模型需要学习一个 ΔW 矩阵,旨在更新原始权重,让损失函数值最小。
权重更新如下:W_updated = W + ΔW。
如果权重矩阵 W 包含 7B 个参数,则权重更新矩阵 ΔW 也包含 7B 个参数,计算矩阵 ΔW 非常耗费计算和内存。
由 Edward Hu 等人提出的 LoRA 将权重变化的部分 ΔW 分解为低秩表示。确切地说,它不需要显示计算 ΔW。相反,LoRA 在训练期间学习 ΔW 的分解表示,如下图所示,这就是 LoRA 节省计算资源的奥秘。
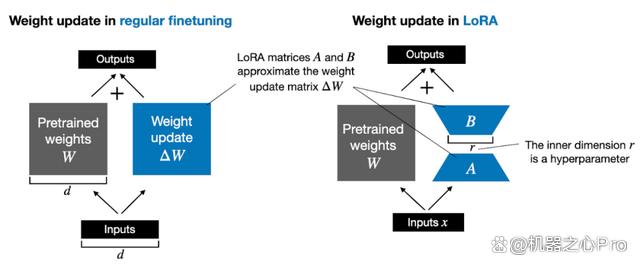
如上所示,ΔW 的分解意味着我们需要用两个较小的 LoRA 矩阵 A 和 B 来表示较大的矩阵 ΔW。如果 A 的行数与 ΔW 相同,B 的列数与 ΔW 相同,我们可以将以上的分解记为 ΔW = AB。(AB 是矩阵 A 和 B 之间的矩阵乘法结果。)
这种方法节省了多少内存呢?还需要取决于秩 r,秩 r 是一个超参数。例如,如果 ΔW 有 10,000 行和 20,000 列,则需存储 200,000,000 个参数。如果我们选择 r=8 的 A 和 B,则 A 有 10,000 行和 8 列,B 有 8 行和 20,000 列,即 10,000×8 + 8×20,000 = 240,000 个参数,比 200,000,000 个参数少约 830 倍。
当然,A 和 B 无法捕捉到 ΔW 涵盖的所有信息,但这是 LoRA 的设计所决定的。在使用 LoRA 时,我们假设模型 W 是一个具有全秩的大矩阵,以收集预训练数据集中的所有知识。当我们微调 LLM 时,不需要更新所有权重,只需要更新比 ΔW 更少的权重来捕捉核心信息,低秩更新就是这么通过 AB 矩阵实现的。
LoRA是怎么去微调适配下游任务的?
流程很简单,LoRA利用对应下游任务的数据,只通过训练新加部分参数来适配下游任务。
而当训练好新的参数后,利用重参的方式,将新参数和老的模型参数合并,这样既能在新任务上到达fine-tune整个模型的效果,又不会在推断的时候增加推断的耗时。
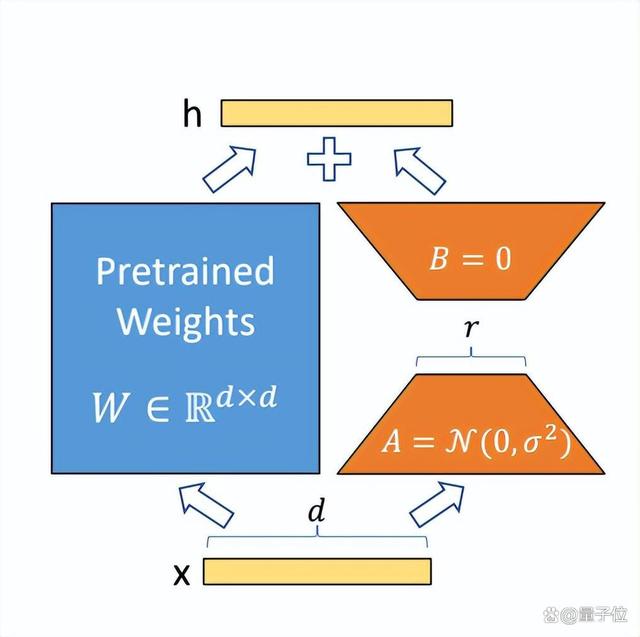
图中蓝色部分为预训练好的模型参数,LoRA在预训练好的模型结构旁边加入了A和B两个结构,这两个结构的参数分别初始化为高斯分布和0,那么在训练刚开始时附加的参数就是0。
A的输入维度和B的输出维度分别与原始模型的输入输出维度相同,而A的输出维度和B的输入维度是一个远小于原始模型输入输出维度的值,这也就是low-rank的体现(有点类似Resnet的结构),这样做就可以极大地减少待训练的参数了。
在训练时只更新A、B的参数,预训练好的模型参数是固定不变的。在推断时可以利用重参数(reparametrization)思想,将AB与W合并,这样就不会在推断时引入额外的计算了。
而且对于不同的下游任务,只需要在预训练模型基础上重新训练AB就可以了,这样也能加快大模型的训练节奏。
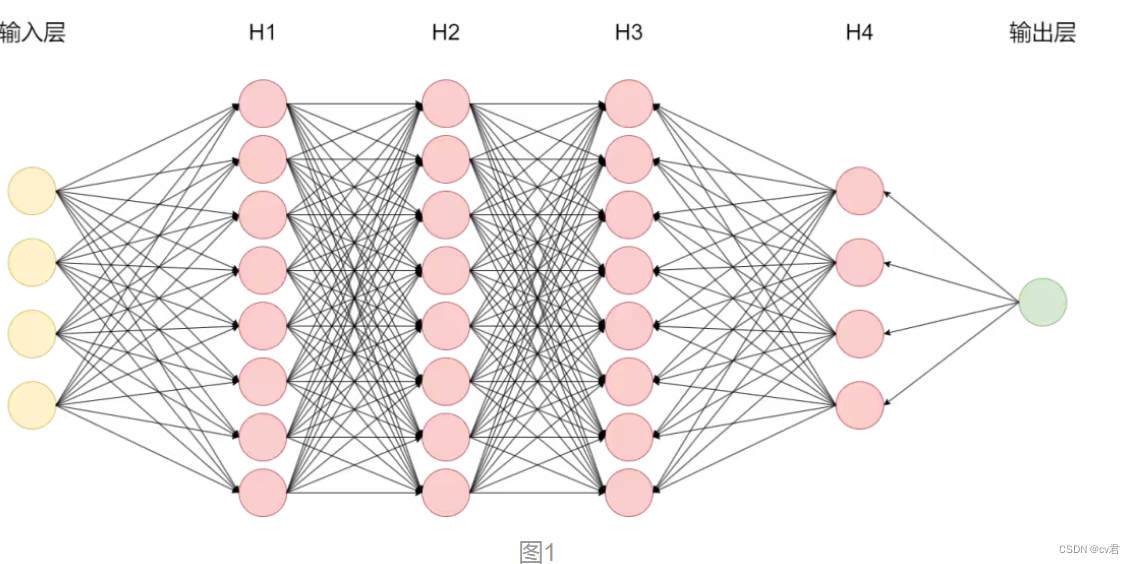
之前在基地的ChatGPT分享中提到过LLM的工作原理是根据输入文本通过模型神经网络中各个节点来预测下一个字,以自回归生成的方式完成回答。
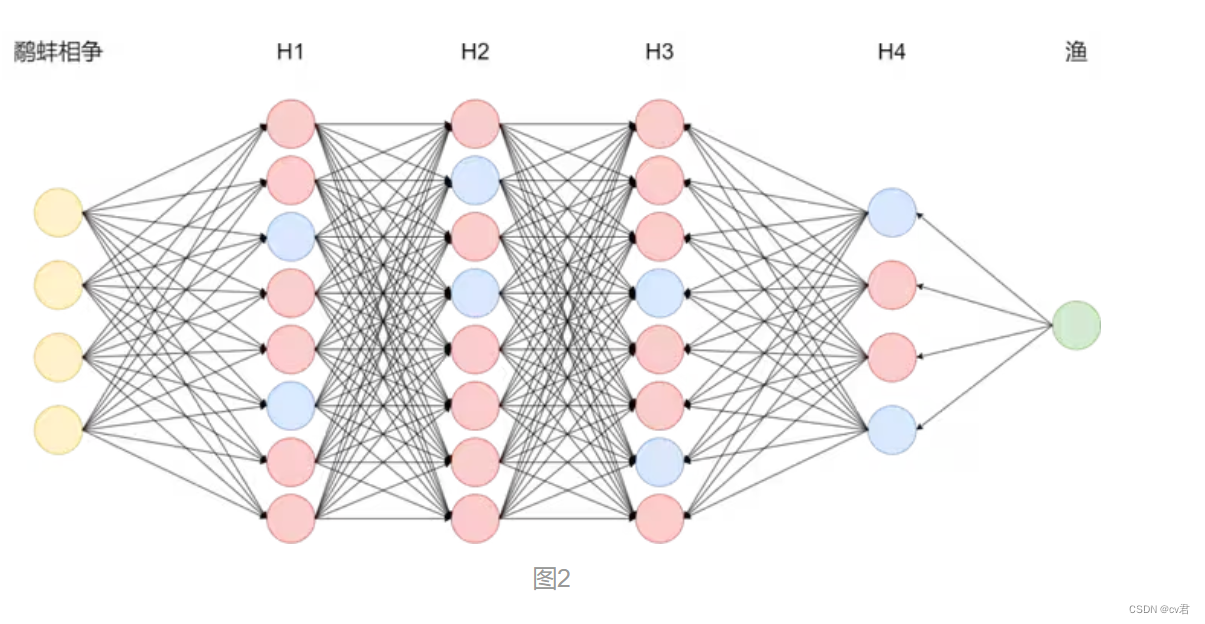
实际上,模型在整个自回归生成过程中决定最终答案的神经网络节点只占总节点的极少一部分。如图1所示为多级反馈神经网络,以输入鹬蚌相争为例,真正参与运算的节点如下图2蓝色节点所示,实际LLM的节点数有数亿之多,我们称之为参数量。 作者:神州数码云基地
神经网络包含许多稠密层,执行矩阵乘法运算。这些层中的权重矩阵通常具有满秩。LLM具有较低的“内在维度”,即使在随机投影到较小子空间时,它们仍然可以有效地学习。
假设权重的更新在适应过程中也具有较低的“内在秩”。对于一个预训练的权重矩阵W0 ∈ Rd×k,我们通过低秩分解W0 + ∆W = W0 + BA来表示其更新,其中B ∈ Rd×r,A ∈ Rr×k,且秩r ≤ min(d,k)。在训练过程中,W0被冻结,不接收梯度更新,而A和B包含可训练参数。需要注意的是,W0和∆W = BA都与相同的输入进行乘法运算,它们各自的输出向量在坐标上求和。前向传播公式如下:h = W0x + ∆Wx = W0x + BAx
在图3中我们对A使用随机高斯随机分布初始化,对B使用零初始化,因此在训练开始时∆W = BA为零。然后,通过αr对∆Wx进行缩放,其中α是r中的一个常数。在使用Adam优化时,适当地缩放初始化,调整α的过程与调整学习率大致相同。因此,只需将α设置为我们尝试的第一个r,并且不对其进行调整。这种缩放有助于在改变r时减少重新调整超参数的需求。
LoRa微调ChatGLM-6B
有时候我们想让模型帮我们完成一些特定任务或改变模型说话的方式和自我认知。作为定制化交付中心的一员,我需要让“他”加入我们。先看一下模型原本的输出。

接下来我将使用LoRa微调将“他”变成定制化交付中心的一员。具体的LoRa微调及微调源码请前往Confluence查看LoRa高效参数微调准备数据集我们要准备的数据集是具有针对性的,例如你是谁?你叫什么?谁是你的设计者?等等有关目标身份的问题,答案则按照我们的需求进行设计,这里列举一个例子

设置参数进行微调
CUDA_VISIBLE_DEVICES=0 python ../src/train_sft.py \ --do_train \ --dataset self \ --dataset_dir ../data \ --finetuning_type lora \ --output_dir path_to_sft_checkpoint \ --overwrite_cache \ --per_device_train_batch_size 4 \ --gradient_accumulation_steps 4 \ --lr_scheduler_type cosine \ --logging_steps 10 \ --save_steps 1000 \ --learning_rate 5e-5 \ --num_train_epochs 3.0 \ --plot_loss \ --fp16 影响模型训练效果的参数主要有下面几个 lora_rank(int,optional): LoRA 微调中的秩大小。这里并不是越大越好,对于小型数据集如果r=1就可以达到很不错的效果,即便增加r得到的结果也没有太大差别。 lora_alpha(float,optional): LoRA 微调中的缩放系数。 lora_dropout(float,optional): LoRA 微调中的 Dropout 系数。 learning_rate(float,optional): AdamW 优化器的初始学习率。如果设置过大会出现loss值无法收敛或过拟合现象即过度适应训练集而丧失泛化能力,对非训练集中的数据失去原本的计算能力。 num_train_epochs(float,optional): 训练轮数,如果loss值没有收敛到理想值可以增加训练轮数或适当降低学习率。
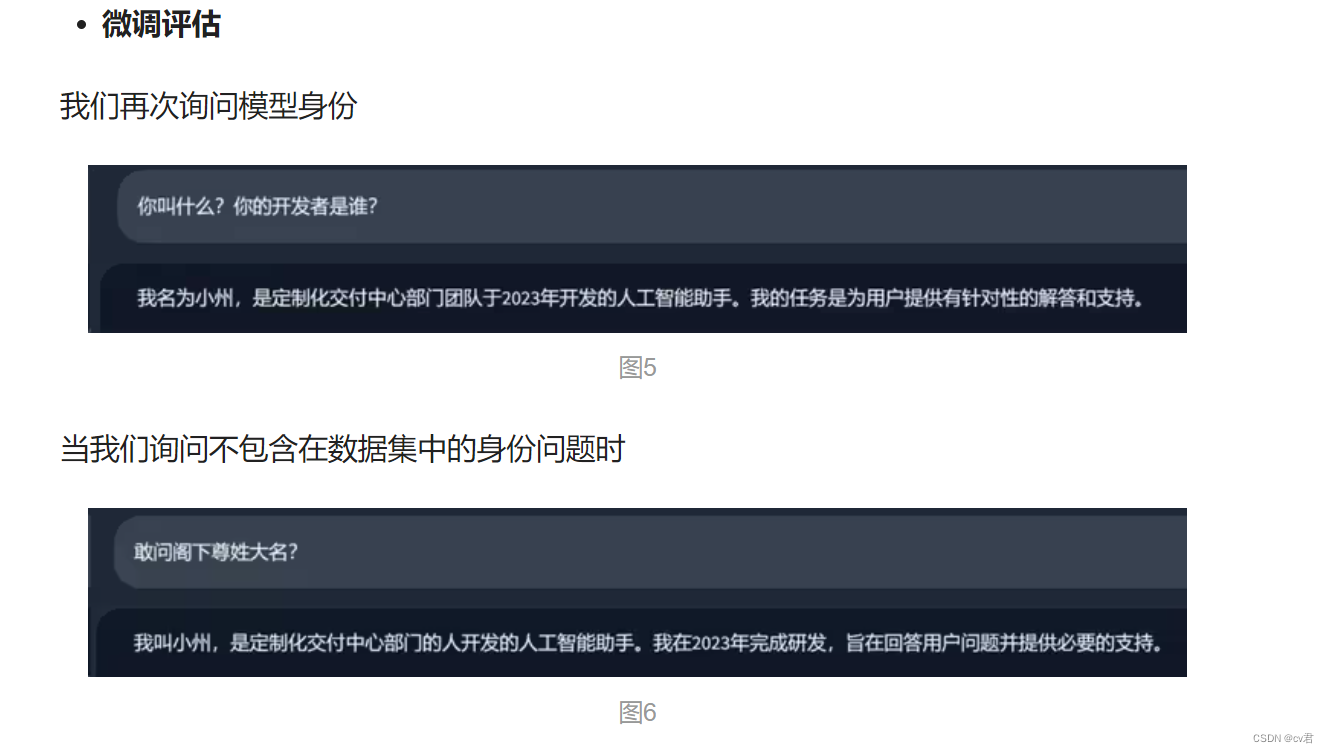
很好,我们得到了理想的回答,这说明“小州”的人设已经建立成功了,换句话说,图二中蓝色节点(身份信息)的权重已经改变了,之后任何关于身份的问题都会是以“小州”的人设进行回答。
LoRA使用
HuggingFace的PEFT(Parameter-Efficient Fine-Tuning)中提供了模型微调加速的方法,参数高效微调(PEFT)方法能够使预先训练好的语言模型(PLMs)有效地适应各种下游应用,而不需要对模型的所有参数进行微调。
对大规模的PLM进行微调往往成本过高,在这方面,PEFT方法只对少数(额外的)模型参数进行微调,基本思想在于仅微调少量 (额外) 模型参数,同时冻结预训练 LLM 的大部分参数,从而大大降低了计算和存储成本,这也克服了灾难性遗忘的问题,这是在 LLM 的全参数微调期间观察到的一种现象PEFT 方法也显示出在低数据状态下比微调更好,可以更好地泛化到域外场景。
例如,使用PEFT-lora进行加速微调的效果如下,从中我们可以看到该方案的优势: 
## 1、引入组件并设置参数
from transformers import AutoModelForSeq2SeqLM
from peft import get_peft_config, get_peft_model, get_peft_model_state_dict, LoraConfig, TaskType
import torch
from datasets import load_dataset
import os
os.environ["TOKENIZERS_PARALLELISM"] = "false"
from transformers import AutoTokenizer
from torch.utils.data import DataLoader
from transformers import default_data_collator, get_linear_schedule_with_warmup
from tqdm import tqdm
## 2、搭建模型
peft_config = LoraConfig(task_type=TaskType.SEQ_2_SEQ_LM, inference_mode=False, r=8, lora_alpha=32, lora_dropout=0.1)
model = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path)
## 3、加载数据
dataset = load_dataset("financial_phrasebank", "sentences_allagree")
dataset = dataset["train"].train_test_split(test_size=0.1)
dataset["validation"] = dataset["test"]
del dataset["test"]
classes = dataset["train"].features["label"].names
dataset = dataset.map(
lambda x: {"text_label": [classes[label] for label in x["label"]]},
batched=True,
num_proc=1,
)
## 4、训练数据预处理
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
def preprocess_function(examples):
inputs = examples[text_column]
targets = examples[label_column]
model_inputs = tokenizer(inputs, max_length=max_length, padding="max_length", truncation=True, return_tensors="pt")
labels = tokenizer(targets, max_length=3, padding="max_length", truncation=True, return_tensors="pt")
labels = labels["input_ids"]
labels[labels == tokenizer.pad_token_id] = -100
model_inputs["labels"] = labels
return model_inputs
processed_datasets = dataset.map(
preprocess_function,
batched=True,
num_proc=1,
remove_columns=dataset["train"].column_names,
load_from_cache_file=False,
desc="Running tokenizer on dataset",
)
train_dataset = processed_datasets["train"]
eval_dataset = processed_datasets["validation"]
train_dataloader = DataLoader(
train_dataset, shuffle=True, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True
)
eval_dataloader = DataLoader(eval_dataset, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True)
## 5、设定优化器和正则项
optimizer = torch.optim.AdamW(model.parameters(), lr=lr)
lr_scheduler = get_linear_schedule_with_warmup(
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=(len(train_dataloader) * num_epochs),
)
## 6、训练与评估
model = model.to(device)
for epoch in range(num_epochs):
model.train()
total_loss = 0
for step, batch in enumerate(tqdm(train_dataloader)):
batch = {k: v.to(device) for k, v in batch.items()}
outputs = model(**batch)
loss = outputs.loss
total_loss += loss.detach().float()
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
model.eval()
eval_loss = 0
eval_preds = []
for step, batch in enumerate(tqdm(eval_dataloader)):
batch = {k: v.to(device) for k, v in batch.items()}
with torch.no_grad():
outputs = model(**batch)
loss = outputs.loss
eval_loss += loss.detach().float()
eval_preds.extend(
tokenizer.batch_decode(torch.argmax(outputs.logits, -1).detach().cpu().numpy(), skip_special_tokens=True)
)
eval_epoch_loss = eval_loss / len(eval_dataloader)
eval_ppl = torch.exp(eval_epoch_loss)
train_epoch_loss = total_loss / len(train_dataloader)
train_ppl = torch.exp(train_epoch_loss)
print(f"{epoch=}: {train_ppl=} {train_epoch_loss=} {eval_ppl=} {eval_epoch_loss=}")
## 7、模型保存
peft_model_id = f"{model_name_or_path}_{peft_config.peft_type}_{peft_config.task_type}"
model.save_pretrained(peft_model_id)
## 8、模型推理预测
from peft import PeftModel, PeftConfig
peft_model_id = f"{model_name_or_path}_{peft_config.peft_type}_{peft_config.task_type}"
config = PeftConfig.from_pretrained(peft_model_id)
model = AutoModelForSeq2SeqLM.from_pretrained(config.base_model_name_or_path)
model = PeftModel.from_pretrained(model, peft_model_id)
model.eval()
inputs = tokenizer(dataset["validation"][text_column][i], return_tensors="pt")
print(dataset["validation"][text_column][i])
print(inputs)
with torch.no_grad():
outputs = model.generate(input_ids=inputs["input_ids"], max_new_tokens=10)
print(outputs)
print(tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True))
提问
LoRA 的权重可以组合吗?
答案是肯定的。在训练期间,我们将 LoRA 权重和预训练权重分开,并在每次前向传播时加入。
假设在现实世界中,存在一个具有多组 LoRA 权重的应用程序,每组权重对应着一个应用的用户,那么单独储存这些权重,用来节省磁盘空间是很有意义的。同时,在训练后也可以合并预训练权重与 LoRA 权重,以创建一个单一模型。这样,我们就不必在每次前向传递中应用 LoRA 权重。
weight += (lora_B @ lora_A) * scaling
我们可以采用如上所示的方法更新权重,并保存合并的权重。
同样,我们可以继续添加很多个 LoRA 权重集:
weight += (lora_B_set1 @ lora_A_set1) * scaling_set1weight += (lora_B_set2 @ lora_A_set2) * scaling_set2weight += (lora_B_set3 @ lora_A_set3) * scaling_set3...
我还没有做实验来评估这种方法,但通过 Lit-GPT 中提供的 scripts/merge_lora.py 脚本已经可以实现。
脚本链接:https://github.com/Lightning-AI/lit-gpt/blob/main/scripts/merge_lora.py
-
如果要结合 LoRA,确保它在所有层上应用,而不仅仅是 Key 和 Value 矩阵中,这样才能最大限度地提升模型的性能。
-
调整 LoRA rank 和选择合适的 α 值至关重要。提供一个小技巧,试试把 α 值设置成 rank 值的两倍。
-
14GB RAM 的单个 GPU 能够在几个小时内高效地微调参数规模达 70 亿的大模型。对于静态数据集,想要让 LLM 强化成「全能选手」,在所有基线任务中都表现优异是不可能完成的。想要解决这个问题需要多样化的数据源,或者使用 LoRA 以外的技术。
LoRA可以用于视觉任务吗?
可以的,经常结合stable diffusion等大模型进行微调,在aigc中经常使用,下期我们深入分析lora和lora该如何进行优化。
总结
针对LLM的主流微调方式有P-Tuning、Freeze、LoRa、instruct等等。由于LoRa的并行低秩矩阵几乎没有推理延迟被广泛应用于transformers模型微调,另一个原因是ROI过低,对LLM的FineTune所需要的计算资源不是普通开发者或中小型企业愿意承担的。而LoRa将训练参数减少到原模型的千万分之一的级别使得在普通计算资源下也可以实现FineTune。