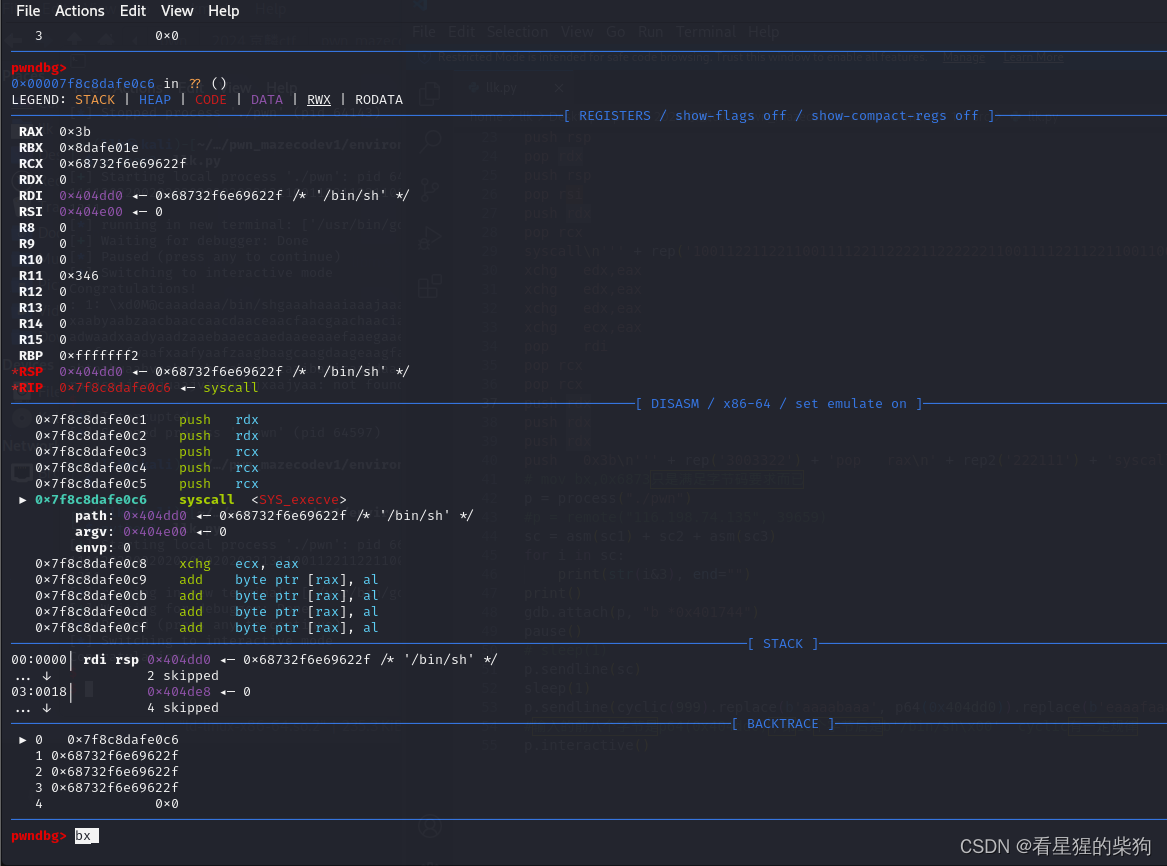
前言
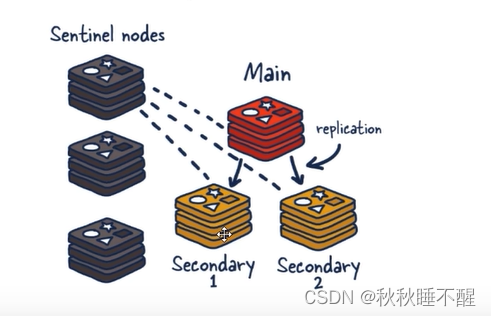
上篇我们讲解了哨兵集群是怎么回事
也说了对应的leader选举raft算法
也说了对应的slave节点是怎么被leader提拔的
主要是比较优先级 比较同步偏移量 比较runid等等
今天我们再说说,其实哨兵也有很多缺点
虽然在master挂了之后能很快帮我们选举出新的master
但是对于单个master承受的压力过大的情况还是没有得到很好的解决
因此,我们就推出了新的技术 集群cluster
于是我们也就放弃了原有的哨兵操作
下面我们慢慢介绍
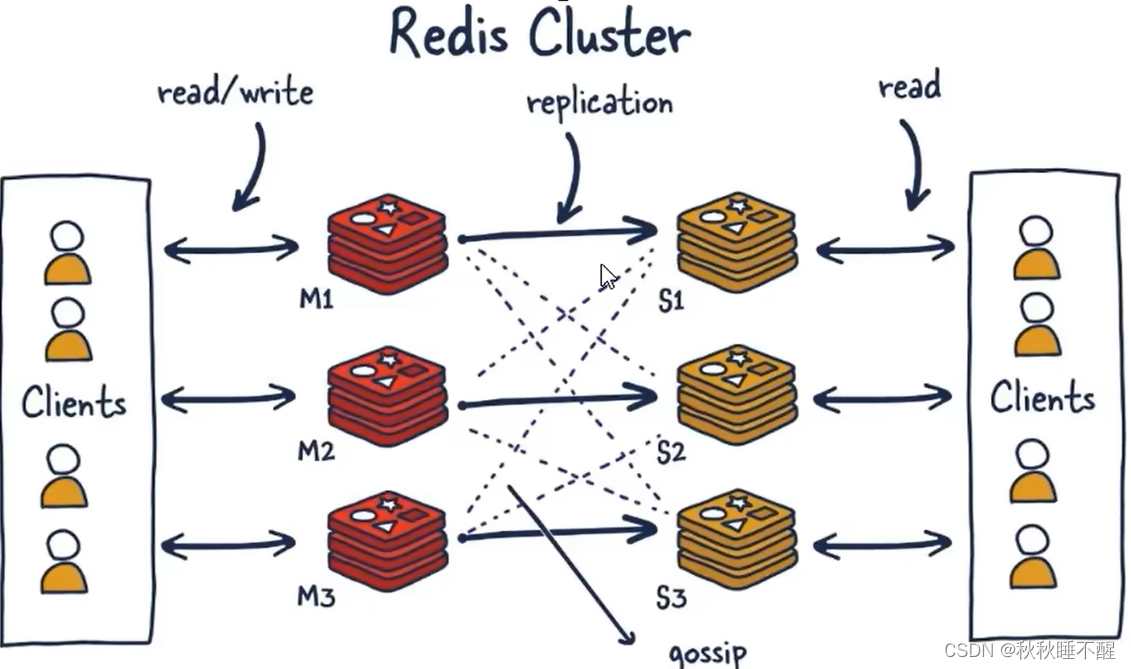
结构
首先我们也是先看看原来的哨兵架构
再来看看今天要介绍的集群架构
这里对应master之间是数据共享的
至于为什么我们下面慢慢介绍
由于集群自带故障迁移,这里也是自然取代了哨兵
首先我们先介绍几个基本的概念
分片
这里分片的意思就是对应的每个节点负责一部分的槽位数据
一个集群负责所有的数据
一个节点就负责一片片区的数据
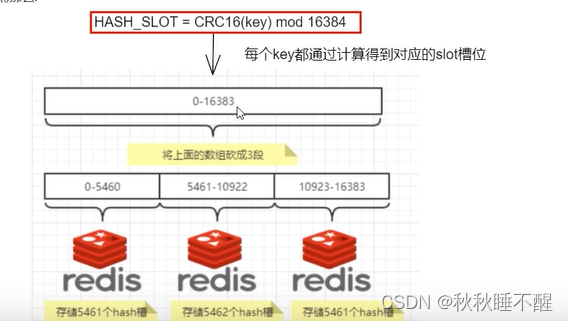
槽位
上面我们提到的一片片区的基本单位就是槽位
是由16384个槽位组成的
注:这里建议节点数不要超过1k
上述的架构可以这样理解
哈希算法
我们如何找到对应的槽位呢?
通过一次CRC16算法再&0x3FFF即可
哈希映射有哪些 方式呢???
1.哈希取余分区算法
简单有效
将对应的哈希值取模一个机器数量即可
缺点就是扩容比较困难
我们需要将所有数据key进行一次rehash的操作
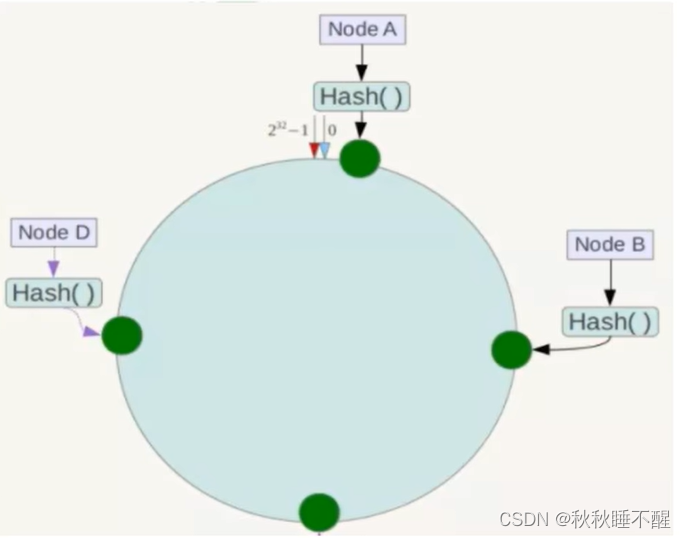
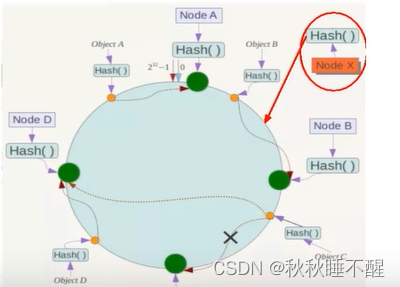
2.一致性哈希分区算法
首先由一个重要的概念称之为哈希环
也就是将所有数据首位相连成一个一致性哈希环
假设是0-65535
这里0和65536指向的就是同一块位置
逻辑图如下
这样我们也就得到了一个所有哈希值的全量集
接着将对应的服务器ip进行对应的映射
最后就是对应的key进行hash了
就是顺时针找到的第一个节点就负责存储这一个键值对
优点是容错性好,缺失一个节点也能直接使用下一个遇见的redis节点进行存储
扩展性好,假设需要加上一个节点x,就只需要移动一小块区域的数据
如上图 我们只需要移动对应的a到x的数据即可
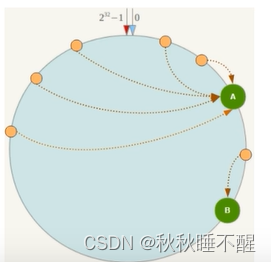
但是缺点也是存在的
很可能出现数据倾斜的问题
也就是说头重脚轻,分配不均匀的情况
于是我们就使用了哈希槽的方式解决问题
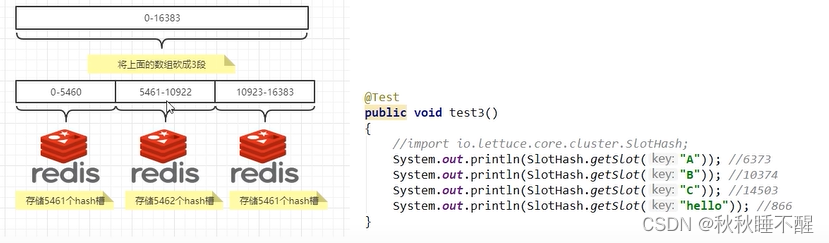
3.哈希槽分区算法
就是我们之前说的将16384个哈希槽分给不同的节点来保存
这里主要就是一个使用CRC16(key) 再进行了一次取模16384的操作
主要架构如下

为啥是16384???
为啥是16384个槽位呢
主要是因为以下原因
1.首先客户端每隔一段时间会给服务器发送心跳包,心跳包中就有槽位的数据
如果需要65536个槽位这里的数据量就达到了8K,但是如果是16384个槽位这里的数据就只有2k,这样的性能更好不容易导致网络阻塞
2.官网声明不可以使用超过1000个节点
因为节点过多就会导致传输数据的失真等等,也是不可取的
这里16384个槽位也是足够使用的
3.对于文件的压缩
发送的数据包如果太大就不方便压缩了
这里16384个槽位slot是刚刚好的
数据丢失
注:redis集群并没有保证数据的强一致性
假设我给1号机器写入数据还没来得及同步给从机就挂掉了
从机即使上位也无法得到之前的数据
集群搭建
首先我们在myredis下面创建新的cluster文件夹存放对应的配置文件
mkdir -p /myredis/cluster 这里-p就是父目录不存在也会创建我们三台虚拟机每台放两个配置文件
分别对应一主一从
对应的配置文件如下
这里我们使用的是从6381开始的6个redis节点
bind 0.0.0.0 daemonize yes protected-mode no port 6382 logfile "/myredis/cluster/cluster6382.log" pidfile /myredis/cluster6382.pid dir /myredis/cluster dbfilename dump6382.rdb appendonly yes appendfilename "appendonly6382.aof" requirepass 111111 masterauth 111111 cluster-enabled yes cluster-config-file nodes-6382.conf cluster-node-timeout 5000在六个redis节点都启动之后我们开始创建集群
使用如下命令,注意结合自身ip 使用ifconfig可以查看
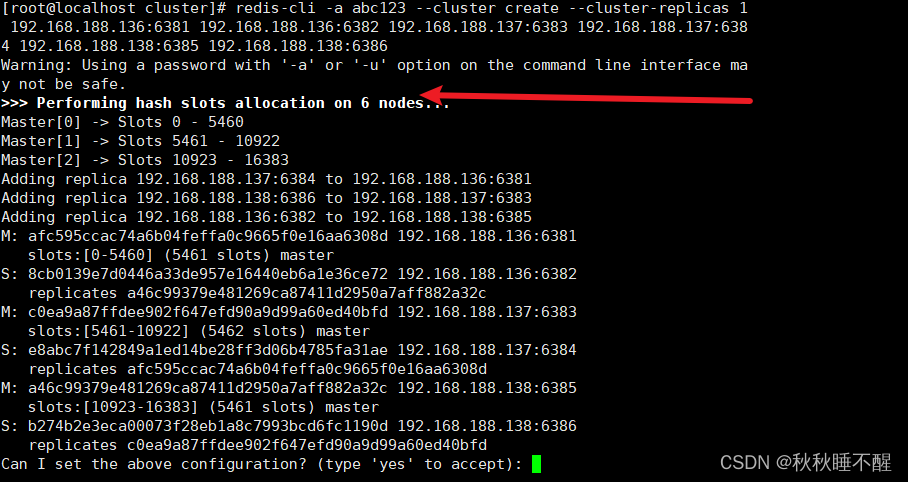
redis-cli -a abc123 --cluster create --cluster-replicas 1 192.168.188.136:6381 192.168.188.136:6382 192.168.188.137:6383 192.168.188.137:6384 192.168.188.138:6385 192.168.188.138:6386 这里replicas 1 就是每个主机配置一个从机 后面对应主从关系 使用任意一台vm进行操作即可
接下来直接yes即可
出现对应的配置文件即算配置成功
我们可以使用
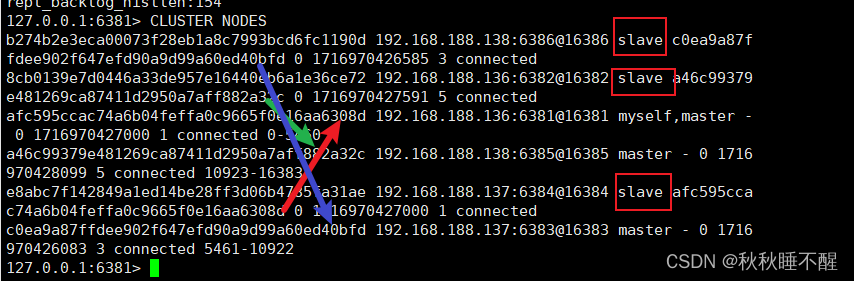
cluster nodes 查看集群状态
注意这里不同的机器对应的槽位不同
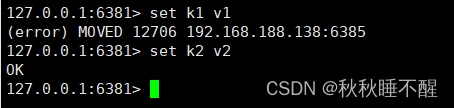
所以set k1 v1 很可能会失败
而k2v2会成功
这是因为登入的是1号节点 而对应计算的槽位是由5号节点管理的
我们只需要在登录的时候在最后加上一个-c 以集群形式登录
此时遇到哪个集群就会自动跳转到对应的ip端口进行操作了
redis-cli -a abc123 -p 6381 -c这里可以理解为路由/重定向
容灾
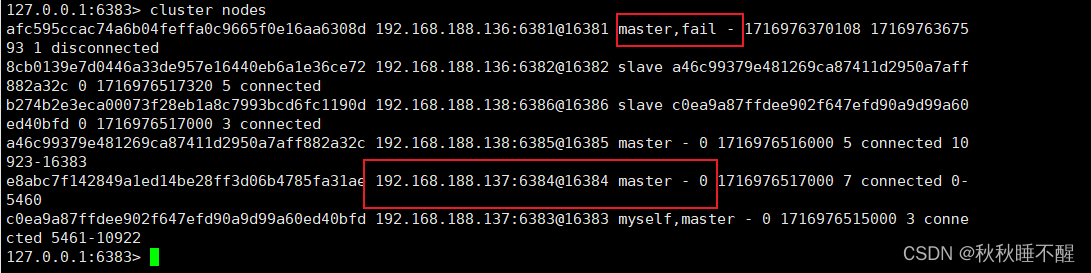
先说结论,主机挂了从机会上位
此时主机再回来也只能当从机了
下面是具体演示
手动shutdown6381
使用cluster nodes查看情况
我们发现对应的6384上位了
此时重启6381只能当小弟了
我们还可以进行对应的恢复
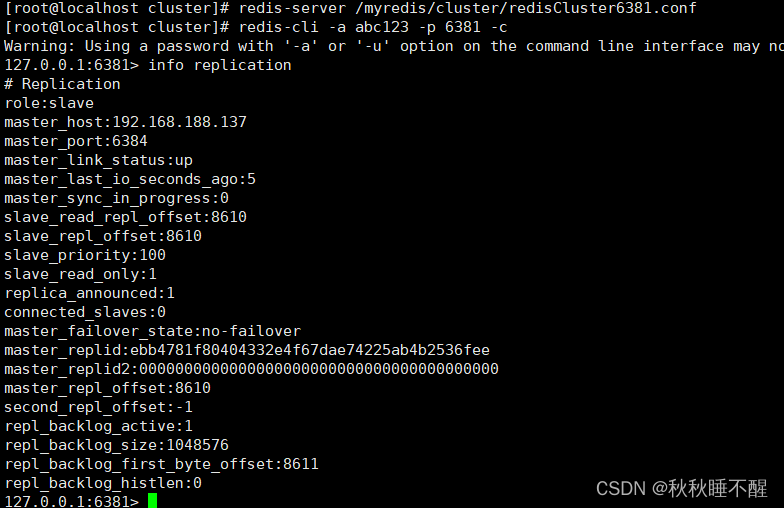
让6381继续当老大,6384继续当小弟
此时只需要登录6381进行对应的操作即可
cluster failover此时6381就可以重回master


扩容
下面演示扩容节点
我们先在192.168.138第三台vm下创建两个配置文件
并启动对应的redis
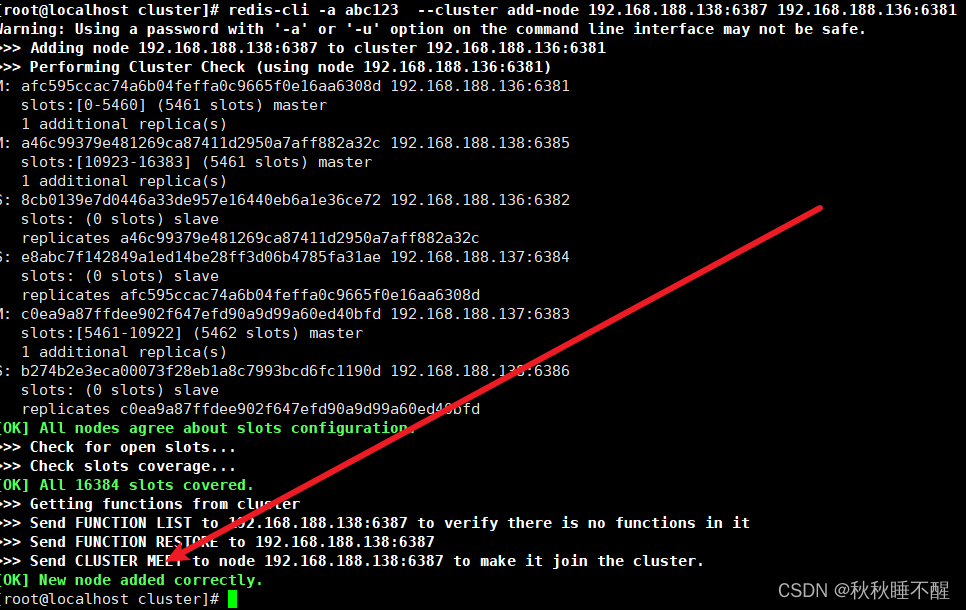
加入集群只需要执行以下命令
找6381当做引路人即可
此时我们会发现虽然添加节点成功但是没有分配槽位
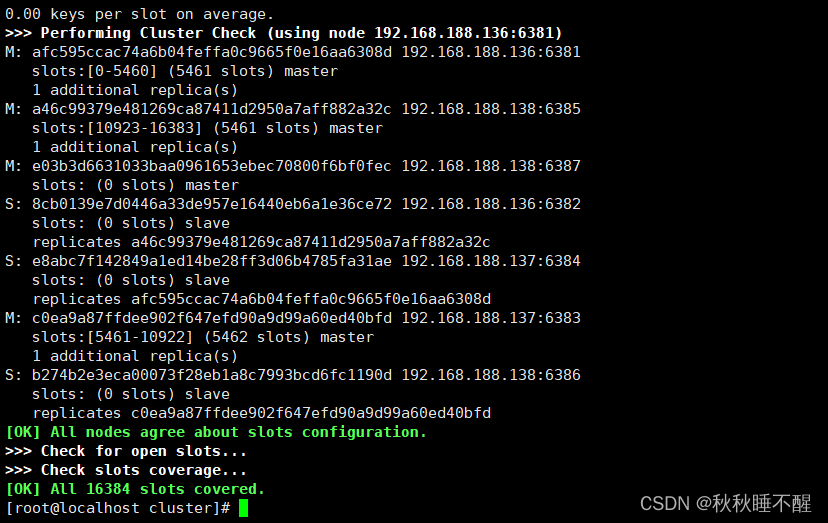
检查一下集群状态
redis-cli -a abc123 --cluster check 192.168.188.136:6381
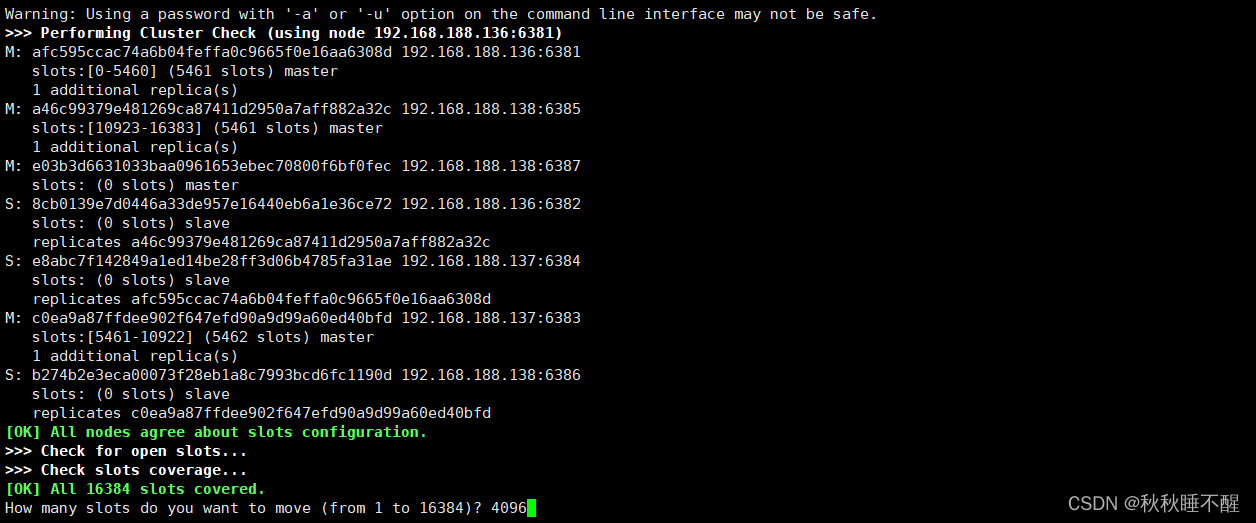
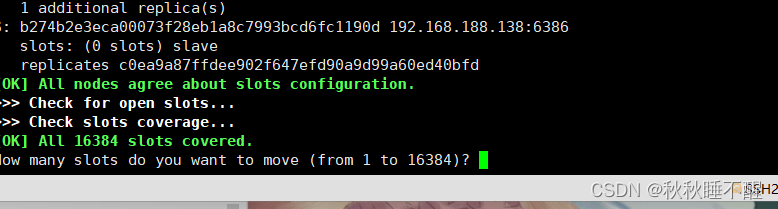
我们需要进行reshard进行分配槽位
redis-cli -a abc123 --cluster reshard 192.168.188.138:6387因为现在是4个节点所以分配一个节点4096个槽位
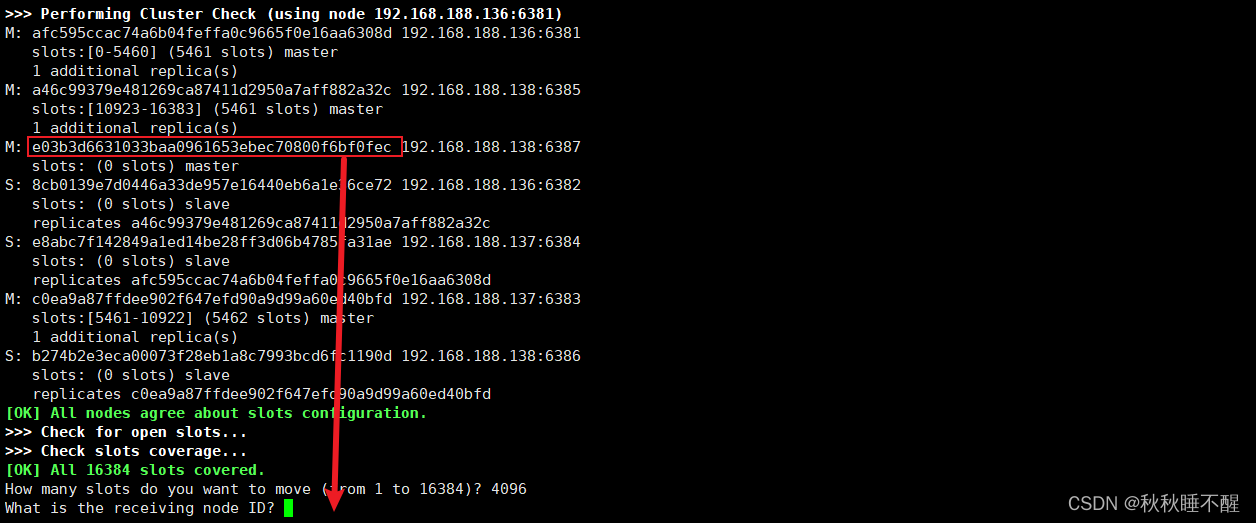
我们需要之前check的6387的id号
然后输入all
进行对应的reshard
在进行一次check查看对应的状态
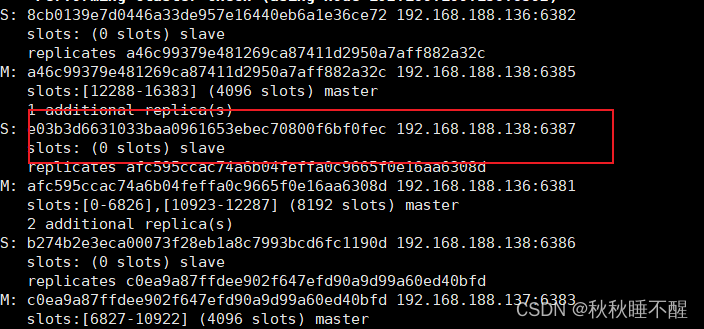
最后为6387分配从节点
redis-cli -a abc123 --cluster add-node 192.168.188.138:6388 192.168.188.138:6387 --cluster-slave --cluster-master-id e03b3d6631033baa0961653ebec70800f6bf0fec最后检查一下结构
最后四主四从也就搭建完成了



缩容
虽然基本上用不到,但是咱们主打一个完整性
首先清楚6388
使用上面的check指令获取对应的id
redis-cli -a abc123 --cluster del-node 192.168.188.138:6388 20dd91501451051961745a005f580858db6f7a2e删除之后对应的子节点可以再查看一下
然后得执行reshard将对应的slot槽位分配回去
为了方便起见我们直接全分配给6381号机器即可
redis-cli -a abc123 --cluster reshard 192.168.188.136:6381
直接全部分配写4096
然后选择6381号机器的id
对应的done即可
此时我们再进行一次check
我们发现6387已经变成salve了
对应的槽位也清零了
最后进行删除节点操作
redis-cli -a abc123 --cluster del-node 192.168.188.138:6387 e03b3d6631033baa0961653ebec70800f6bf0fec批处理操作
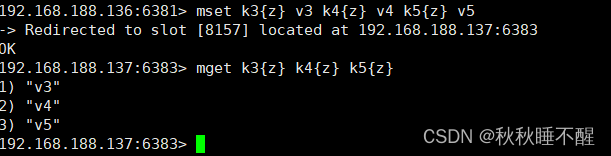
我们知道不同的key k1 k2 k3会被分配到不同的slot上
所以进行批处理查询操作是会报错的
如果我们想进行批处理
可以使用通配符将几个key映射为一组
类似于以下操作
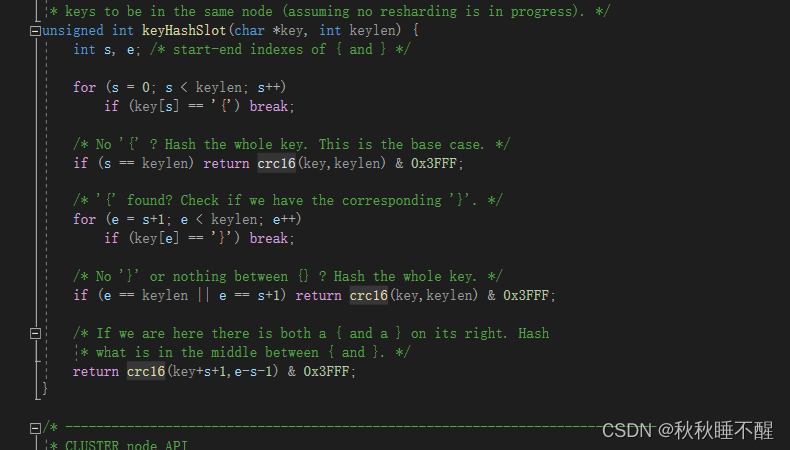
我们在cluster.c的源文件中也可以找到对应的
我们发现redis会使用通配符{}中间的元素进行CRC算法


其他操作
redis还有一个重要参数
就是当假设分区1的主从节点都宕机了之后
我们对外还会不会进行服务暴露???
默认是yes 也就是不服务暴露的 但是我们也是可以设置服务暴露的
但是这时候就会有一些数据是不可访问的
重要的三个集群命令
cluster nodes 查看节点情况 cluster countinkeysinslot slotId 查看slot是否被占用 cluster keyslot k1 查看key使用的slot是啥 也就是进行了一次CRC16算法并取余16384示例如下
说明1236槽位没有存放数据
说明k123会存放在4255槽位上