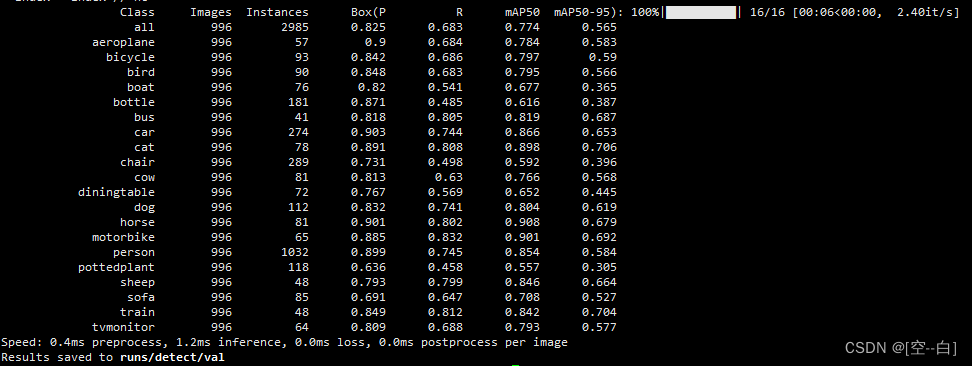
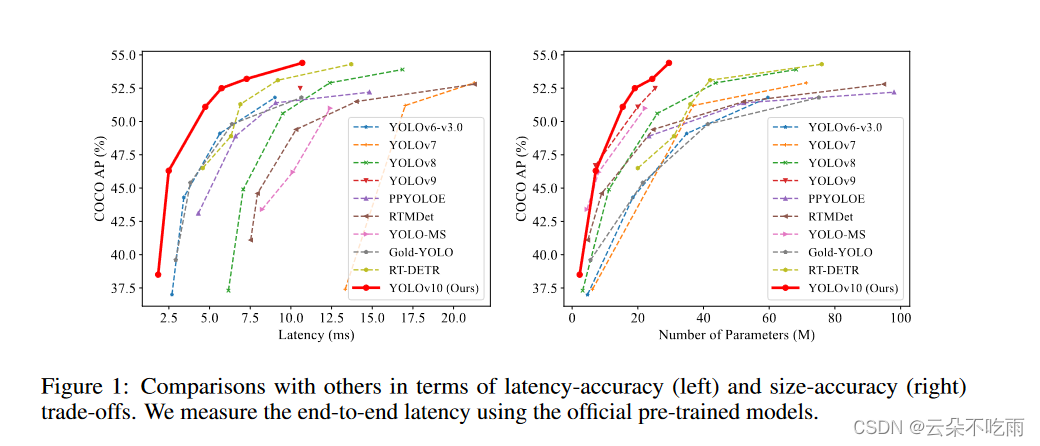
YOLO-10简介
主要贡献:
- 无NMS的一致双分配
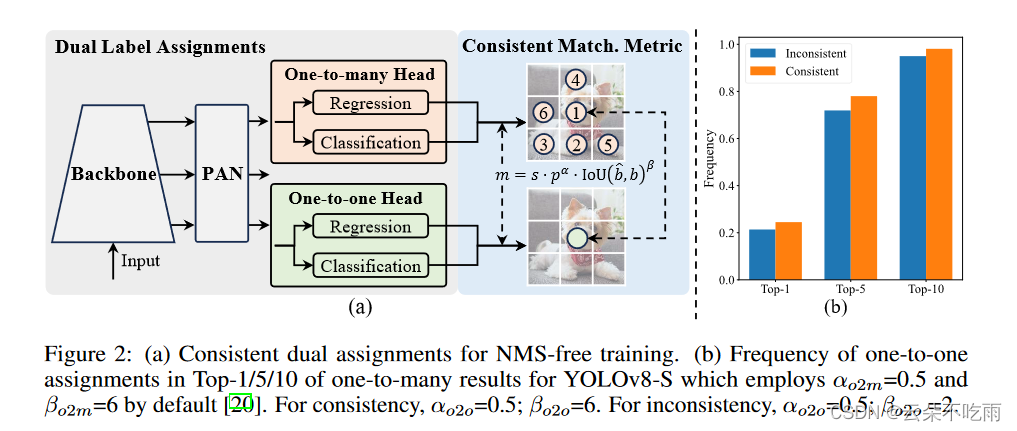
- YOLOv10提出了一种通过双标签分配而不用非极大值抑制NMS的策略。这种方法结合了一对多和一对一分配策略的优势,提高了效率并保持了性能。
- 高效的网络设计
-
轻量化分类头:在不显著影响性能的情况下,减少了计算开销。
-
空间-通道解耦下采样:解耦空间下采样和通道调整,优化计算成本。
-
基于秩的块设计:根据各阶段的内在秩适应块设计,减少冗余,提高效率。
-
大核卷积和部分自注意力PSA:在不显著增加计算成本的情况下,增强了感受野和全局建模能力。
-
一致双分配策略
-
一对多分配:在训练期间,多个预测框被分配给一个真实物体标签。这种策略提供了丰富的监督信号,优化效果更好。
-
一对一分配:仅一个预测框被分配给一个真实物体标签,避免了NMS,但由于监督信号较弱,容易导致收敛速度慢和性能欠佳。
-
双头架构:模型在训练期间使用两个预测头,一个使用一对多分配,另一个使用一对一分配。这样,模型可以在训练期间利用一对多分配的丰富监督信号,而在推理期间则使用一对一分配的预测结果,从而实现无NMS的高效推理。
Head优化
- 综合一对一多与一对一的bbox分配策略,网络模块添加两种类型的head模块;推理过程中只保留一对一分配head
- 相较于分类head,回归head承担更多意义
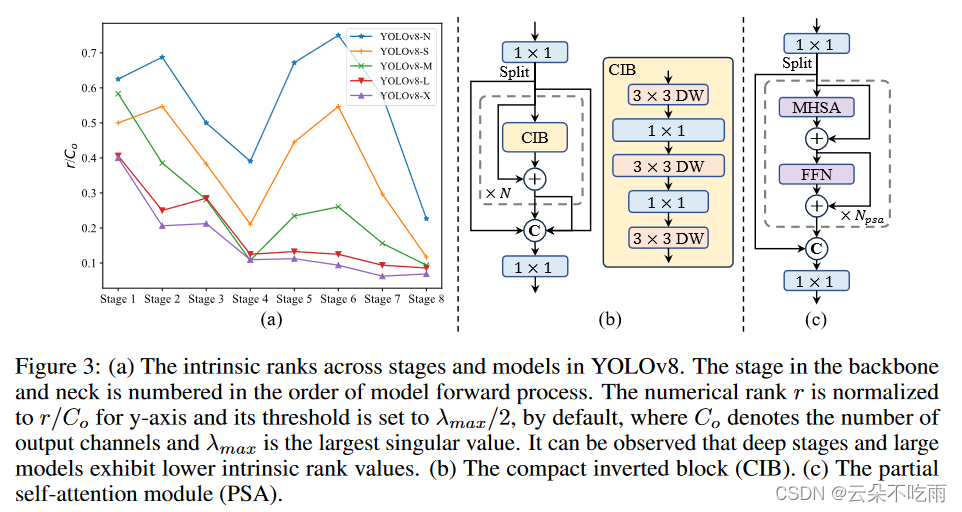
效率驱动的模型设计
- 空间-通道解耦下采样,首先利用点状卷积调节通道维度,然后使用深度卷积进行空间下采样
- 秩引导的块设计:提出了一个紧凑型倒置块(CIB)结构,它采用廉价的深度卷积进行空间混合和高效的一维卷积进行通道混合,如图(b),作为高效的基本构建块。
- 随着模型规模的增加,其感受野自然扩大,使用大核卷积的好处减弱,作者只对小型模型规模采用大核卷积
CIB
class Conv(nn.Module):
"""Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)."""
default_act = nn.SiLU() # default activation
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
"""Initialize Conv layer with given arguments including activation."""
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x):
"""Apply convolution, batch normalization and activation to input tensor."""
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
"""Perform transposed convolution of 2D data."""
return self.act(self.conv(x))
class CIB(nn.Module):
"""Standard bottleneck."""
def __init__(self, c1, c2, shortcut=True, e=0.5, lk=False):
"""Initializes a bottleneck module with given input/output channels, shortcut option, group, kernels, and
expansion.
"""
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = nn.Sequential(
Conv(c1, c1, 3, g=c1),
Conv(c1, 2 * c_, 1),
Conv(2 * c_, 2 * c_, 3, g=2 * c_) if not lk else RepVGGDW(2 * c_),
Conv(2 * c_, c2, 1),
Conv(c2, c2, 3, g=c2),
)
self.add = shortcut and c1 == c2
def forward(self, x):
"""'forward()' applies the YOLO FPN to input data."""
return x + self.cv1(x) if self.add else self.cv1(x)
class C2fCIB(C2f):
"""Faster Implementation of CSP Bottleneck with 2 convolutions."""
def __init__(self, c1, c2, n=1, shortcut=False, lk=False, g=1, e=0.5):
"""Initialize CSP bottleneck layer with two convolutions with arguments ch_in, ch_out, number, shortcut, groups,
expansion.
"""
super().__init__(c1, c2, n, shortcut, g, e)
self.m = nn.ModuleList(CIB(self.c, self.c, shortcut, e=1.0, lk=lk) for _ in range(n))
class Attention(nn.Module):
def __init__(self, dim, num_heads=8,
attn_ratio=0.5):
super().__init__()
self.num_heads = num_heads
self.head_dim = dim // num_heads
self.key_dim = int(self.head_dim * attn_ratio)
self.scale = self.key_dim ** -0.5
nh_kd = nh_kd = self.key_dim * num_heads
h = dim + nh_kd * 2
self.qkv = Conv(dim, h, 1, act=False)
self.proj = Conv(dim, dim, 1, act=False)
self.pe = Conv(dim, dim, 3, 1, g=dim, act=False)
def forward(self, x):
B, C, H, W = x.shape
N = H * W
qkv = self.qkv(x)
q, k, v = qkv.view(B, self.num_heads, self.key_dim*2 + self.head_dim, N).split([self.key_dim, self.key_dim, self.head_dim], dim=2)
attn = (
(q.transpose(-2, -1) @ k) * self.scale
)
attn = attn.softmax(dim=-1)
x = (v @ attn.transpose(-2, -1)).view(B, C, H, W) + self.pe(v.reshape(B, C, H, W))
x = self.proj(x)
return x
class PSA(nn.Module):
def __init__(self, c1, c2, e=0.5):
super().__init__()
assert(c1 == c2)
self.c = int(c1 * e)
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv(2 * self.c, c1, 1)
self.attn = Attention(self.c, attn_ratio=0.5, num_heads=self.c // 64)
self.ffn = nn.Sequential(
Conv(self.c, self.c*2, 1),
Conv(self.c*2, self.c, 1, act=False)
)
def forward(self, x):
a, b = self.cv1(x).split((self.c, self.c), dim=1)
b = b + self.attn(b)
b = b + self.ffn(b)
return self.cv2(torch.cat((a, b), 1))
class SCDown(nn.Module):
def __init__(self, c1, c2, k, s):
super().__init__()
self.cv1 = Conv(c1, c2, 1, 1)
self.cv2 = Conv(c2, c2, k=k, s=s, g=c2, act=False)
def forward(self, x):
return self.cv2(self.cv1(x))
class C2f(nn.Module):
"""Faster Implementation of CSP Bottleneck with 2 convolutions."""
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5):
"""Initialize CSP bottleneck layer with two convolutions with arguments ch_in, ch_out, number, shortcut, groups,
expansion.
"""
super().__init__()
self.c = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)
self.m = nn.ModuleList(Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))
def forward(self, x):
"""Forward pass through C2f layer."""
y = list(self.cv1(x).chunk(2, 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
def forward_split(self, x):
"""Forward pass using split() instead of chunk()."""
y = list(self.cv1(x).split((self.c, self.c), 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))