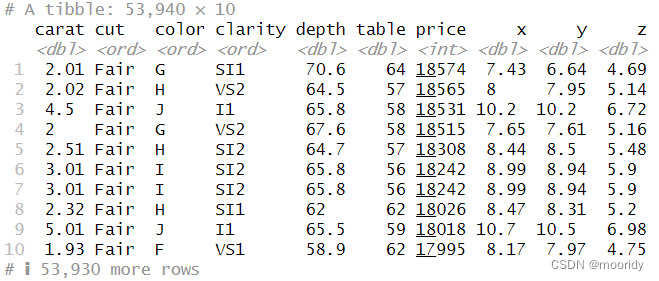
3.1简介
3.1.1准备工作
3.1.2 dplyr 基础
3.2 使用 filter() 筛选行
filter() 函数可以基于观测的值筛选出一个观测子集。
filter(数据集,条件)
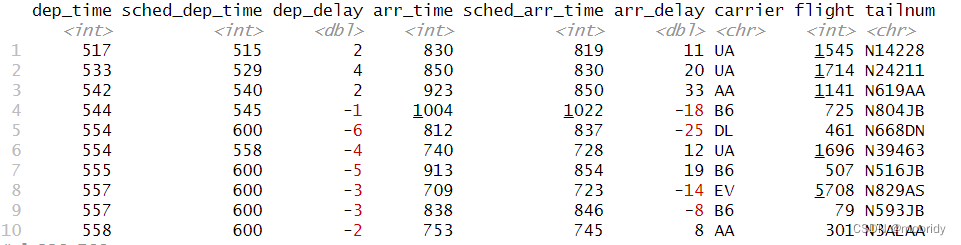
filter(flights, month == 1, day == 1)
注意:用双等号
进行赋值,保存数据集
jan1 <- filter(flights, month == 1, day == 1)
3.2.1 比较运算符
比较运算符:>、>=、<、<=、!=(不等于)和 ==(等于)
比较浮点数是否相等时,不能使用 ==,而应该使用 near()

3.2.2 逻辑运算符
& 表示“与”、| 表示 “或”、! 表示“非”。
filter(flights, month >= 5 | month <= 12)
filter(flights, month == 11 & day == 12)
而不是用&&,||(不要和C语言混淆)
简写形式:x %in% y
简化前:filter(flights, month == 1|month==3|month == 12)
简化后:filter(flights, month%in%c(1,3,12))
3.2.3 缺失值
is.na() 函数:确定一个值是否为缺失值
3.2.4 练习
a. 到达时间延误 2 小时或更多的航班。
filter(flights,arr_delay>=120)
b. 飞往休斯顿(IAH 机场或 HOU 机场)的航班。
filter(flights,dest=="TAH"|dest=="HOU")
c. 由联合航空(United)、美利坚航空(American)或三角洲航空(Delta)运营的航班。
filter(flights,carrier%in%c("AA","UA","DL"))
d. 夏季(7 月、8 月和 9 月)出发的航班。
filter(flights,month%in%c(7,8,9))
e. 到达时间延误超过 2 小时,但出发时间没有延误的航班。
filter(flights,arr_delay>120&dep_delay==0)
f. 延误至少 1 小时,但飞行过程弥补回 30 分钟的航班。
filter(flights,arr_delay>=60,(arr_delay-dep_delay)>=30)
g. 出发时间在午夜和早上 6 点之间(包括 0 点和 6 点)的航班。
filter(flights,dep_time<=600|dep_time==2400)
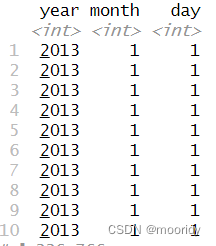
3.3 使用 arrange() 排列行
注意:NA数据总是排在最后(无论升序、降序)。
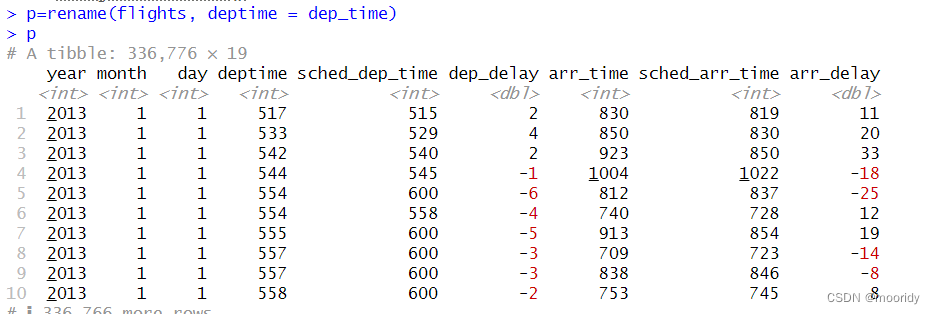
3.4 使用 select() 选择列
3.4.1select()函数
看到想要看的数据子集。
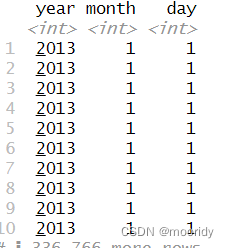
3.4.2一些辅助函数
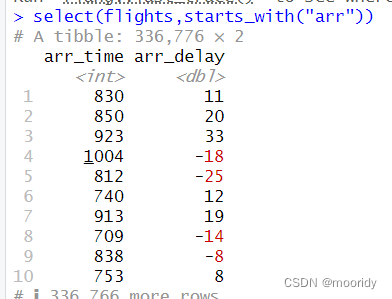
3.5 使用 mutate() 添加新变量
mutate()函数:添加新列
flights_sml <- select(flights,year:day,ends_with("delay"),distance,air_time)
mutate(flights_sml,gain = arr_delay - dep_delay,speed = distance / air_time * 60)
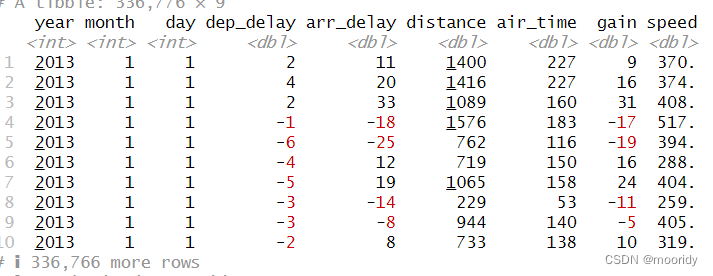
一旦创建,新列就可以立即使用:
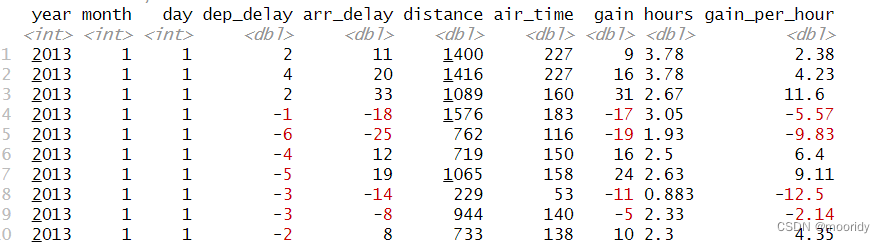
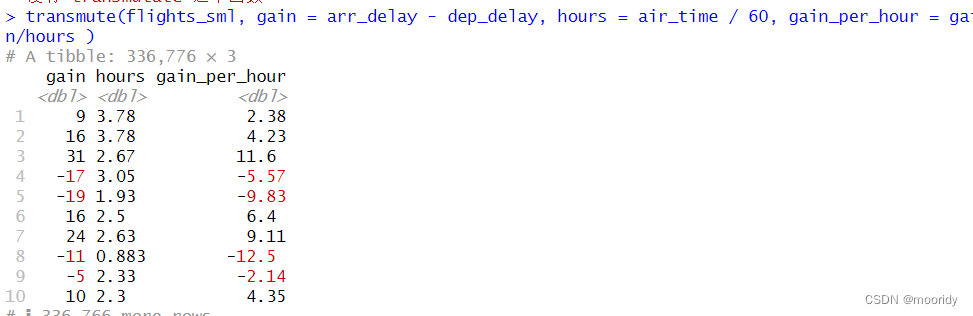
transmute() 函数:只保留新变量,其余不要
3.5.1 常用创建函数
算术运算符
对数函数
log()、log2() 和 log10()
偏移函数
lead() 和 lag() 函数 可以返回一个序列的领先值和滞后值。
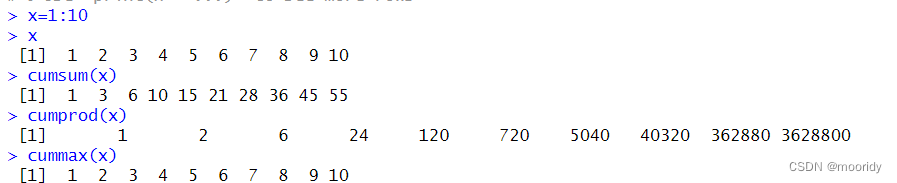

排秩
rank函数(排名)(默认升序)(从低到高)
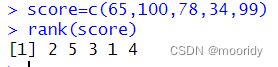
desc函数(倒序)(从高到低)
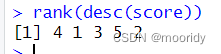
区别sort(排序):

minrank()函数
出现相同元素时,用minrank()排名,rank()算积分
![]()
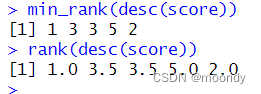
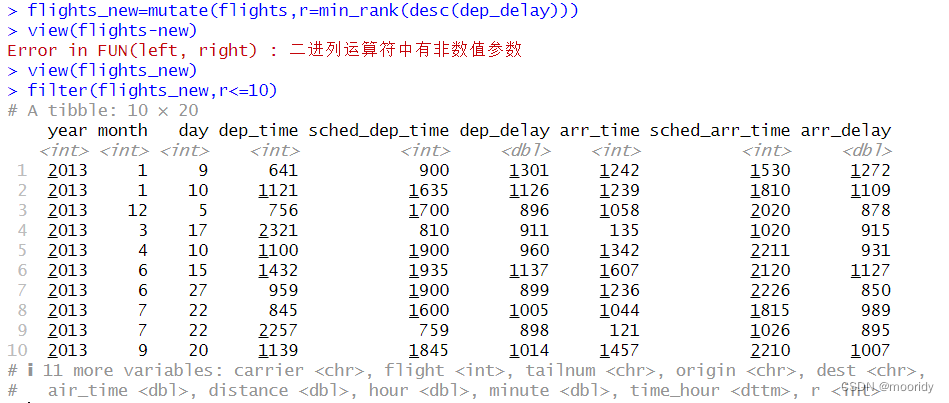
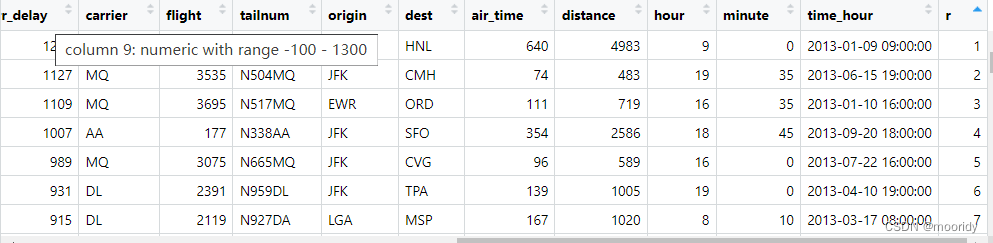
练习: 使用排秩函数找出 10 个延误时间最长的航班。如何处理名次相同的情况?仔细阅读
min_rank() 的帮助文件。
3.6 使用 summarize() 进行分组摘要
summarize():可以将数据框折叠成一行
summarize(flights, delay = mean(dep_delay, na.rm = TRUE))

na.rm = TRUE:移除NA值
group_by()
可以将分析单位从整个数据集更改为单个分组
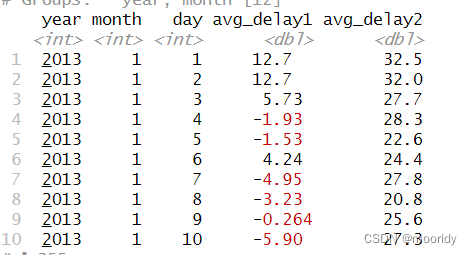
by_day <- group_by(flights, year, month, day)
summarize(by_day, delay = mean(dep_delay, na.rm = TRUE))
得到每一天的平均延误时间:
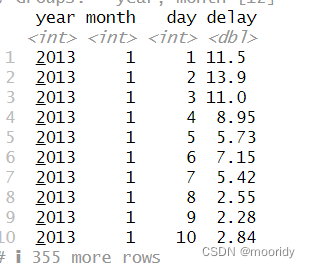
练习:找平均延误时间最长的10个城市
by_city=group_by(flights,dest)%>%summarize(avg_delay=mean(arr_delay,na.rm=TRUE))%>%mutate(r=min_rank(desc(avg_delay)))%>%filter(r<=10)

不同加工钻石平均价格和数量
by_cut <- group_by(diamonds, cut)
summarize(by_cut, mean_price = mean(price,count=n(), na.rm = TRUE))

3.6.1 使用管道组合多种操作
常规做法
by_dest <- group_by(flights, dest) //根据目的地分组
delay <- filter(delay, count > 20, dest != "HNL") //在delay中去除起飞量20以下的,去除目的地HNL的
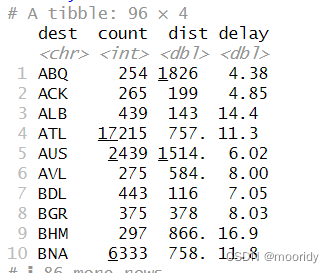
ggplot(data = delay, mapping = aes(x = dist, y = delay)) +
geom_point(aes(size = count), alpha = 1/3) +
geom_smooth(se = FALSE)
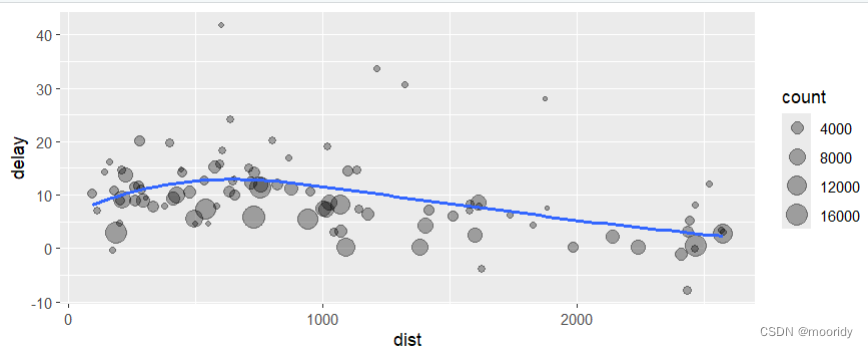
管道做法
%>%就像一根管道一样,把前面的命令结果传给后面地命令作为参数。可以理解为“然后”。
3.6.2 缺失值
3.6.3 计数
1.n() (需要na.rm=TRUE)
2.非缺失值的计数(sum(!is_na()))
注:数据来源Lahman 包中Batting数据集
# 转换成tibble,以便输出更美观

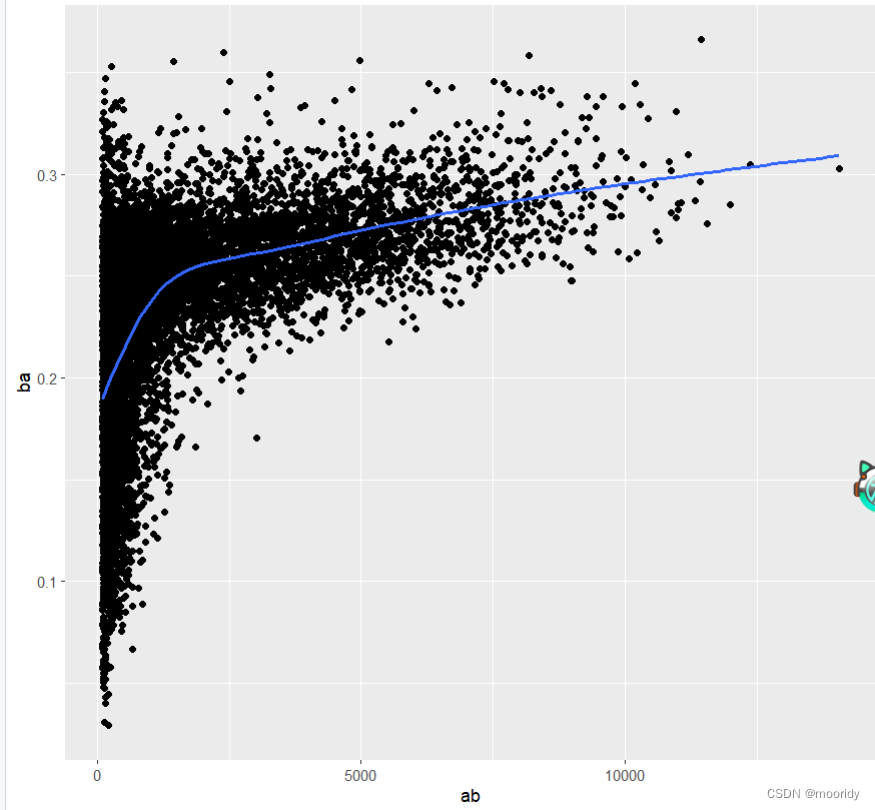
结论:说明球员出场次数越多,命中率越高,但当出场次数足够多时,能力也就趋于稳定了。
最后我们来找出最伟大的十个球员。
batters%>%filter(ab>1000)%>%arrange(desc(ba))
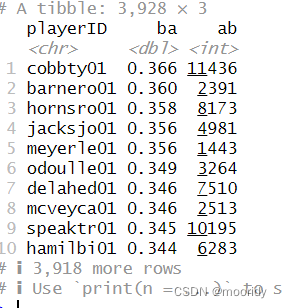
3.6.4 常用的摘要函数
为了后面方便演示,我们先对没有取消的航班建立一个数据集 not_cancelled<-flights%>%filter(!is.na(dep_delay),!is.na(arr_delay))
位置度量
mean(x):平均数
median(x):中位数
分散程度度量
秩的度量
Q:找出不同加工钻石中最贵和最便宜的
diamonds %>%
group_by(cut) %>%
summarize(
cheapest = min(price),
most_exp = max(price)
)
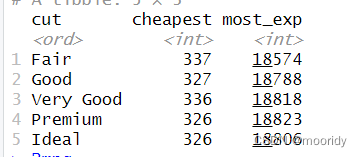
定位度量
first(x):与 x[1] 相同
nth(x, 2):与x[2] 相同
last(x):与x[length(x)] 相同
记得先排序再使用。
diamonds %>%
group_by(cut) %>%arrange(desc(price))%>%
summarize(
cheapest = last(price),
most_exp = first(price)
)
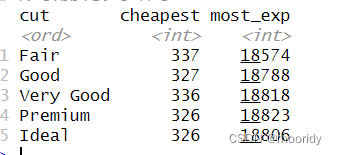
range(r)
给出范围中的最小值和最大值
#每天起飞最晚和最早的航班
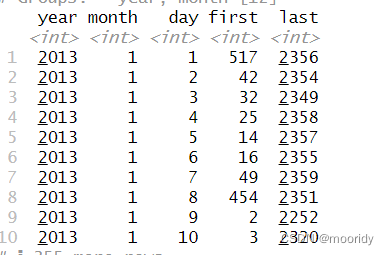
not_cancelled %>% + group_by(year, month, day) %>% + mutate(r = min_rank(desc(dep_time))) %>% + filter(r %in% range(r))
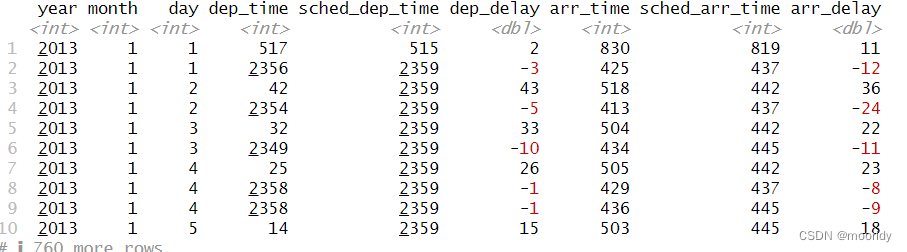
#找出不同加工钻石中最贵的那一颗和最便宜的那一颗 diamonds %>% + group_by(cut) %>% + mutate(r = min_rank(desc(price))) %>% + filter(r %in% range(r))
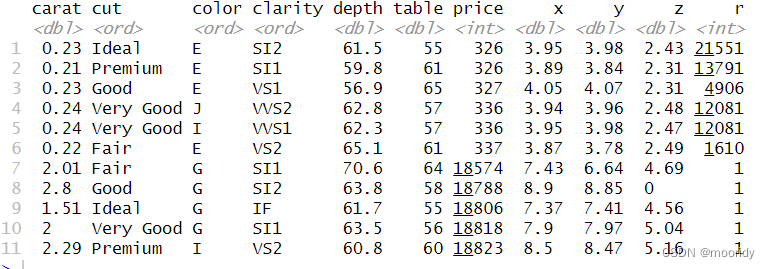
计数
通过下面这个简单的例子,我们来看看n()函数和n_distinct()函数的区别
y=c("aa","aa","ua","ua","dl")
> demo=data.frame(y)


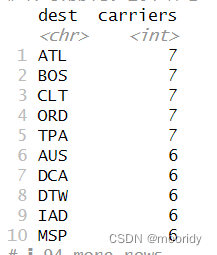
diamonds%>%count(color)
比这样写简单:diamonds%>%group_by(color)%>%summarise(n=n())

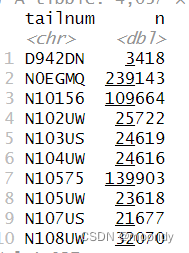
not_cancelled%>%count(tailnum,wt=distance)
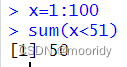
逻辑值的计数和比例
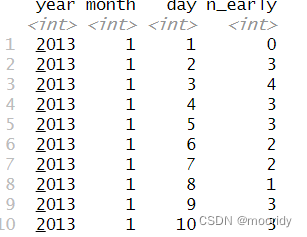
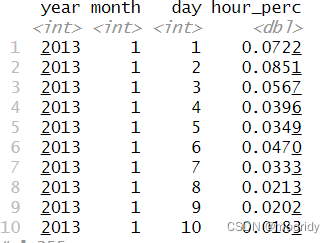
3.6.5 按多个变量分组
循序渐进地进行摘要分析
daily <- group_by(flights, year, month, day)
(per_day <- summarize(daily, flights = n())) (per_month <- summarize(per_day, flights = sum(flights)))
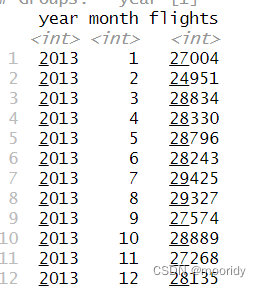
(per_year <- summarize(per_month, flights = sum(flights)))

3.6.6 取消分组
ungroup()函数:取消分组
daily<-group_by(flights,year,month,day)
daily%>%ungroup()%>%summarize(n())
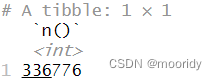
3.7 分组新变量(和筛选器)
diamonds%>%group_by(color)%>%filter(min_rank(desc(price))<=5)
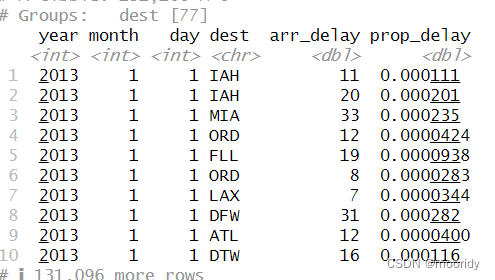
不同颜色钻石中最贵的5颗钻石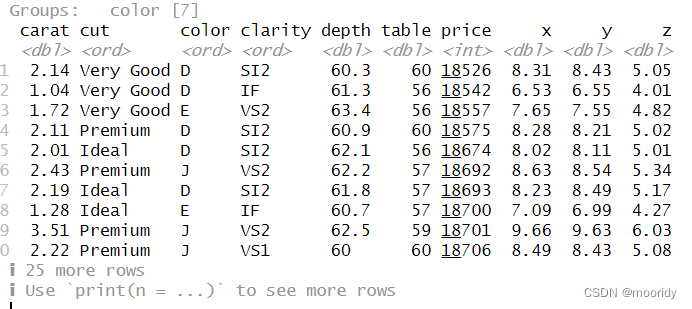 popular_dests % group_by(dest) %>% filter(n() > 365)
popular_dests % group_by(dest) %>% filter(n() > 365)
popular_dests %>% filter(arr_delay > 0) %>% mutate(prop_delay = arr_delay / sum(arr_delay)) %>% select(year:day, dest, arr_delay, prop_delay)