DETR流程
-
Backbone用卷积神经网络抽特征。最后通过一层1*1卷积转化到d_model维度fm(B,d_model,HW)。
-
position embedding建立跟fm维度相同的位置编码(B,d_model,HW)。
-
Transformer Encoder,V为fm,K,Q为fm+position embedding。因为V代表的是图像特征。所以不添加位置编码
-
Transformer Decoder。生成一个固定大小(query_num)的object query(B,q_num,d_model)比如100个预测框。Decoder输入tgt与object query形状相同。代码中为torch.zero()。第一层selfattention K,V为tgt+query,Q为tgt。第二层Q为上一层输出+query。V为encoder输出,K为encoder输出+position。这里V仍然代表图像特征所以不添加位置编码
-
用输出的100个object query框和ground truth框做一个匹配,然后在一一配对好的框中去计算目标检测的loss(分类loss与回归loss(L1+IOU))
-
二分图匹配与匈牙利算法
DETR 预测了一组固定大小的 N = 100 个边界框
将 ground-truth 也扩展成 N = 100 个检测框
使用一个额外的特殊类标签 ϕ 来表示在未检测到任何对象,或者认为是背景类别。
这样预测和真实都是两个100 个元素的集合了
采用匈牙利算法进行二分图匹配,对预测集合和真实集合的元素进行一一对应,使得匹配损失最小。
-
推理过程不需要二分图匹配,只需要取最大得分框即可
代码详细参考:
transformer 在 CV 中的应用(二) DETR 目标检测网络 -
网络结构
参数说明:B:batchsize大小,C通道数,H,W:CNN输出特征图的高宽。d_model设定的特征维度大小如512。
Q,K,V:自注意力矩阵。l_q:Q矩阵的长度,l_kv:K,V矩阵的长度。KV矩阵的长度必须相同,Q矩阵长度可以跟KV矩阵长度不同
Q矩阵维度:(B,l_q,d_model)
K矩阵维度:(B,l_kv,d_model)
V矩阵维度:(B,l_kv,d_model)
object_query维度(B,q_num,d_model)
Backbone:
img→CNNbackbone→fm特征图(B,C,H,W) → fm特征图输入到transformer中时要再经过一层卷积将通道数转化成d_ model。C→d_model.
position embedding(B,d_model,H*W)。backbone通过CNN提取图像特征,然后通过特征图生成尺度对应的位置编码。
position embedding:
位置编码官方实现了两种,一种是固定位置编码,另一种是自学习位置编码,这里就介绍固定位置编码。
位置编码要考虑 x, y 两个方向,图像中任意一个点 (h, w) 有一个位置,这个位置编码长度为 256 ,前 128 维代表 h 的位置编码, 后 128 维代表 w 的位置编码,把这两个 128 维的向量拼接起来就得到一个 256 维的向量,它代表 (h, w) 的位置编码。位置编码的计算公式如下图所示
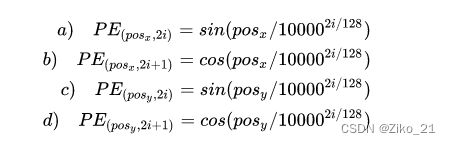
Transformer
DETRtransformer结构图

接受CNN提取的特征(B,d_model,HW),位置编码(B,d_model,HW),querys(B,query_num,d_model)
encoder:q,k添加位置编码。v代表图像本身特征,不添加位置编码。multi_head_attention跟FFN后都带了两个残差连接。
# post代表norm放在后面
def forward_post(self,
src,
src_mask: Optional[Tensor] = None,
src_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None):
q = k = self.with_pos_embed(src, pos) #q,k增加position
src2 = self.self_attn(q, k, value=src, attn_mask=src_mask,key_padding_mask=src_key_padding_mask)[0]
src = src + self.dropout1(src2) # 残差
src = self.norm1(src)
# ffn
src2 = self.linear2(self.dropout(self.activation(self.linear1(src))))
# 残差
src = src + self.dropout2(src2)
src = self.norm2(src)
return src
decoder:
设定一个object queries(num_query,d_model)
有两层multihead self attention
- 第一层obquery添加到K,Q上作为position embedding
第二层的Q来于decoder,K,V来自于encoder输出。
第二层self attention K添加编码,Q增加object queries。V代表图像特征,不添加任何信息
KV要有相同维度,Q可以跟KV在长度维度上不同,d_model维度相同
softmax(QKt/(d^0.5))V→矩阵乘法Q*Kt:(l_q,d_model)@(d_model_l_kv)→(l_q,l_kv)
再乘以V(l_q,l_kv)@(l_kv,d_model)→(l_q,d_model)
def forward_post(self, tgt, memory,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
query_pos: Optional[Tensor] = None):
'''
:param tgt: query_pos rep 2tensor of shape (bs, c, h, w) ->tgt = torch.zeros_like(query_embed)
:param memory:
:param tgt_mask:
:param memory_mask:
:param tgt_key_padding_mask:
:param memory_key_padding_mask:
:param pos:
:param query_pos:
:return:
'''
q = k = self.with_pos_embed(tgt, query_pos)
tgt2 = self.self_attn(q, k, value=tgt, attn_mask=tgt_mask,
key_padding_mask=tgt_key_padding_mask)[0]
tgt = tgt + self.dropout1(tgt2)
tgt = self.norm1(tgt)
tgt2 = self.multihead_attn(query=self.with_pos_embed(tgt, query_pos),
key=self.with_pos_embed(memory, pos),
value=memory, attn_mask=memory_mask,
key_padding_mask=memory_key_padding_mask)[0]
tgt = tgt + self.dropout2(tgt2)
tgt = self.norm2(tgt)
tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt))))
tgt = tgt + self.dropout3(tgt2)
tgt = self.norm3(tgt)
return tgt
-
DETR在计算attention的时候没有使用masked attention,因为将特征图展开成一维以后,所有像素都可能是互相关联的,因此没必要规定mask。
-
object queries的转换过程:object queries是预定义的目标查询的个数,代码中默认为100。它的意义是:根据Encoder编码的特征,Decoder将100个查询转化成100个目标,即最终预测这100个目标的类别和bbox位置。最终预测得到的shape应该为[N, 100, C],N为Batch Num,100个目标,C为预测的100个目标的类别数+1(背景类)以及bbox位置(4个值)
得到预测结果以后,将object predictions和ground truth box之间通过匈牙利算法进行二分匹配:假如有K个目标,那么100个object predictions中就会有K个能够匹配到这K个ground truth,其他的都会和“no object”匹配成功,使其在理论上每个object query都有唯一匹配的目标,不会存在重叠,所以DETR不需要nms进行后处理。
匹配
匈牙利匹配算法
匈牙利匹配算法,二分图匹配算法
scipy.optimize.linear_sum_assignment(cost_matrix, maximize=False)
#cost_matrix 二分图开销矩阵
https://blog.csdn.net/CV_Autobot/article/details/129096035
https://blog.csdn.net/lemonxiaoxiao/article/details/108672039
query与gt匹配
transformer通过query输出n_q数量的bbox与对应分类置信度
真实框[gt1,gt2,…gtn]
每个bbox与gt之间有一个距离度量。
距离度量由三部分组成:真实类别的置信度得分+边界框的L1loss+边界框的IOUloss
通过匈牙利算法找出距离最小的query_bbox为gt对应的prebbox
loss训练
整体流程
pred输出→100(num_queries)class,100(num_queries)boxes
gt(tagert)→100class,100boxes(包含背景类)
pred,gt→计算相互loss,得到二分图成本矩阵,然后计算匈牙利匹配算法→return匹配上的classes与boxes
匹配成功的框→计算真正的class损失(),box回归损失(GLOUloss)。。
预测框与真实框的差异来自于两方面:1.二分图匹配时带来的差异。2.预测框与真实框之间的差异。
-
分类损失:交叉熵损失,针对所有predictions。没有匹配到的querybbox应该分类为背景
-
回归损失:bbox loss采用了L1 loss和giou loss,针对匹配成功的querybbox
-
cardinality 损失,对应函数是 loss_cardinality ; cardinality 损失是计算预测有物体的个数的绝对损失,值是为了记录,不参与反向传播



![[vue3后台管理一]vue3下载安装及环境配置教程](https://img-blog.csdnimg.cn/direct/6e4cc31fd333436d8bc94bcff8055a99.png)