线程池
线程池本质上一组事先创建的子线程,用于并发完成特定任务的机制,避免运行过程中频繁创建、销毁线程,从而降低程序运行效率。通常,线程池主要涉及到以下几个方面问题:
- 如何创建线程池?
- 线程池如何执行何种任务?如何执行?
- 如何将用户数据、任务传递给线程池?
- 如何解决线程池的线程安全问题?
- 如何销毁线程池?
thread_pool简介
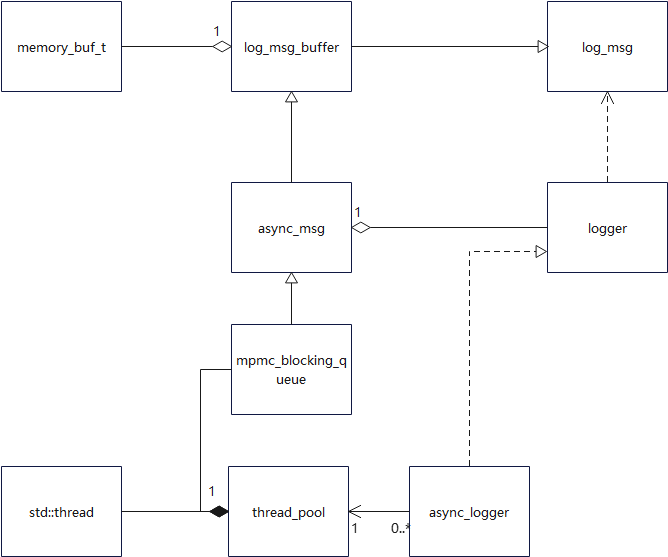
thread_pool 使用了 mpmc_blocking_queue(多生产者-多消费者阻塞队列)来缓存日志消息。这个队列允许多个前端线程(生产者)同时向队列中添加日志消息,也允许多个后端线程(消费者)同时从队列中取出消息。
前端线程是指用户调用日志记录功能的线程。当用户调用异步日志记录方法时,日志消息会被封装成 async_msg 对象,并放入 mpmc_blocking_queue 队列中。
thread_pool 内部维护了一组后端线程,这些线程从 mpmc_blocking_queue 队列中取出日志消息并进行处理。实际上是调用 async_logger::backend_sink_it_ 方法,将日志消息写入到预先注册的 sink(日志输出目标,如文件、控制台等)。
多生产者-多消费者阻塞队列模型
spdlog支持多个线程向同一个logger写log消息,也支持logger将同一个log消息写向多个sink file目标。因此,使用多生产者-多消费者的异步模型。该模型通过类模板mpmc_blocking_queue实现,支持存放用户需要的数据类型。底层通过环形队列q_来存储数据,通过2个条件变量+1个互斥锁确保线程安全。
// include/spdlog/details/mpmc_blocking_queue.h
// 多生产者-多消费者阻塞队列
template<typename T>
class mpmc_blocking_queue
{
public:
using item_type = T;
explicit mpmc_blocking_queue(size_t max_items)
: q_(max_items)
{}
...
private:
std::mutex queue_mutex_; // 互斥锁, 确数据的线程安全
std::condition_variable push_cv_;
std::condition_variable pop_cv_;
spdlog::details::circular_q<T> q_;//环形队列
std::atomic<size_t> discard_counter_{0};
};
阻塞与非阻塞方式插入数据
环形队列是一个通用的数据结构,当队列满时,如果还往其中插入数据,那么head和tail都后移1,也就是说,丢弃最老的数据,插入新数据。这是非阻塞的插入数据方式。
当然,阻塞、非阻塞的概念是在mpmc_blocking_queue中提出的,分别通过两个接口enqueue、enqueue_nowait实现。enqueue_nowait直接调用circular_q插入数据(不论队列是否已满),而enqueue则会在插入数据前先阻塞等待队列非满的条件。
// try to enqueue and block if no room left
void enqueue(T &&item)
{
{
std::unique_lock<std::mutex> lock(queue_mutex_);
pop_cv_.wait(lock, [this] { return !this->q_.full(); });
q_.push_back(std::move(item));
}
push_cv_.notify_one();
}
// enqueue immediately. overrun oldest message in the queue if no room left.
void enqueue_nowait(T &&item)
{
{
std::unique_lock<std::mutex> lock(queue_mutex_);
q_.push_back(std::move(item));
}
push_cv_.notify_one();
}
取出数据
mpmc_blocking_queue只提供了阻塞方式取出数据接口dequeue_for,当然也考虑了可能会长期阻塞,因此也为用户提供指定超时等待参数的功能。
// dequeue with a timeout.
// Return true, if succeeded dequeue item, false otherwise
bool dequeue_for(T &popped_item, std::chrono::milliseconds wait_duration) {
{
std::unique_lock<std::mutex> lock(queue_mutex_);
if (!push_cv_.wait_for(lock, wait_duration, [this] { return !this->q_.empty(); })) {
return false;
}
popped_item = std::move(q_.front());
q_.pop_front();
}
pop_cv_.notify_one();
return true;
}
overrun异常处理机制
当队列满时,如果继续往其中以非阻塞方式插入数据,会丢弃老的数据,但用户如何得知?这需要用到overrun机制:每丢弃一个数据,overrun计数器+1。这依赖于更底层的circular_q的实现,mpmc_blocking_queue只是为用户提供接口,实际转发给了circular_q。
size_t overrun_counter()
{
std::unique_lock<std::mutex> lock(queue_mutex_);
return q_.overrun_counter();
}
void reset_overrun_counter()
{
std::unique_lock<std::mutex> lock(queue_mutex_);
q_.reset_overrun_counter();
}
环形队列circular_q
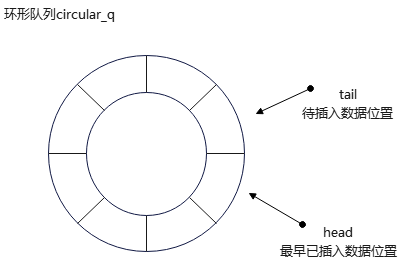
环形队列通过类模板circular_q实现,存储数据的数组v大小是固定的,由构造者决定;circular_q预留了一个额外的存储空间,用于区分队列空和队列满的情形。值得一提的是,当环形队列满时,如果用户还想插入数据,circular_q会丢弃头部数据,在尾部插入新数据。这个过程称为overrun(超负荷运行)。circular_q通过一个计数器overrun_counter_来记录发生overrun的次数。
// include/spdlog/details/circular_q.h
template<typename T>
class circular_q
{
size_t max_items_ = 0; // 环形队列大小
typename std::vector<T>::size_type head_ = 0; // 指向环形队列首部(第一个有效数据位置)
typename std::vector<T>::size_type tail_ = 0; // 指向环形队列尾部(待插入数据位置). 注意尾部没有实际数据
size_t overrun_counter_ = 0; // overrun 次数
std::vector<T> v_; // 存放数据的数组
public:
using value_type = T;
// empty ctor - create a disabled queue with no elements allocated at all
circular_q() = default;
explicit circular_q(size_t max_items)
: max_items_(max_items + 1) // one item is reserved as marker for full q
, v_(max_items_)
{}
circular_q(const circular_q &) = default;
circular_q& operator=(const circular_q &) = default;
// push back, overrun (oldest) item if no room left
void push_back(T &&item)
{
if (max_items_ > 0) {
v_[tail_] = std::move(item);
tail_ = (tail_ + 1) % max_items_;
if (tail_ == head_) { // overrun last item if full
head_ = (head_ + 1) % max_items_;
++overrun_counter_;
}
}
}
// Return reference to the front item.
// If there are no elements in the container, the behavior is undefined.
const T &front() const
{
return v_[head_];
}
T& front()
{
return v_[head_];
}
// Return number of elements actually stored
size_t size() const
{
if (tail_ >= head_) {
return tail_ - head_;
}
else {
return max_items_ - (head_ - tail_);
}
}
// Return const reference to item by index.
// If index is out of range 0..size()-1, the behavior is undefined.
const T &at(size_t i) const
{
assert(i < size());
return v_[(head_ + i) % max_items_];
}
// Pop item from front.
// If there are no elements in the container, the behavior is undefined.
void pop_front()
{
head_ = (head_ + 1) % max_items_;
}
bool empty() const
{
return tail_ == head_;
}
bool full() const
{
// head is ahead of the tail by 1
if (max_items_ > 0) {
return ((tail_ + 1) % max_items_) == head_;
}
return false;
}
size_t overrun_counter() const
{
return overrun_counter_;
}
void reset_overrun_counter()
{
overrun_counter_ = 0;
}
...
};
circular_q一个有别于普通环形队列实现的地方,是对右值的支持。如果实参是左值,就需要利用std::move将左值转换为右值。这里不用std::swap交换*this与右值引用other,因为默认的std::swap会构造一个新的临时对象,用于交换std::swap两个参数。而other本身是右值,可以直接利用。
circular_q(circular_q &&other) SPDLOG_NOEXCEPT {
copy_moveable(std::move(other));
}
circular_q &operator=(circular_q &&other) SPDLOG_NOEXCEPT {
copy_moveable(std::move(other));
return *this;
}
// copy from other&& and reset it to disabled state
void copy_moveable(circular_q &&other) SPDLOG_NOEXCEPT {
max_items_ = other.max_items_;
head_ = other.head_;
tail_ = other.tail_;
overrun_counter_ = other.overrun_counter_;
v_ = std::move(other.v_);
// put &&other in disabled, but valid state
other.max_items_ = 0;
other.head_ = other.tail_ = 0;
other.overrun_counter_ = 0;
}
thread pool实现
设计
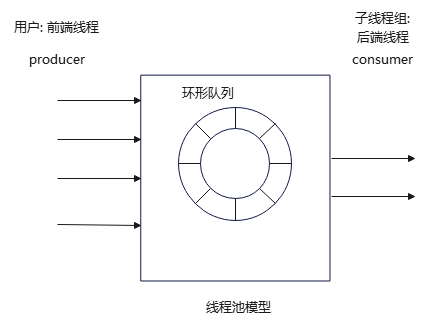
- 前端线程往线程池插入数据;
- 从线程池取出数据交给后端线程处理;
- 线程池数据满时,插入数据异常处理;
- 线程池空时,取出数据异常处理;
由于线程池的唯一需要确保线程安全的数据是环形队列,而环形队列本身提供线程安全支持,因此线程池无需额外支持线程安全。
类接口
class SPDLOG_API thread_pool
{
public:
using item_type = async_msg;
using q_type = details::mpmc_blocking_queue<item_type>;
thread_pool(size_t q_max_items, size_t threads_n, std::function<void()> on_thread_start, std::function<void()> on_thread_stop);
...
// message all threads to terminate gracefully and join them
~thread_pool();
thread_pool(const thread_pool &) = delete;
void post_log(async_logger_ptr &&worker_ptr, const details::log_msg &msg, async_overflow_policy overflow_policy);
void post_flush(async_logger_ptr &&worker_ptr, async_overflow_policy overflow_policy);
size_t overrun_counter();
void reset_overrun_counter();
size_t queue_size();
private:
// 环形阻塞队列
q_type q_;
// 子线程数组
std::vector<std::thread> threads_;
// 从队列取出异步消息(async_msg)
void post_async_msg_(async_msg &&new_msg, async_overflow_policy overflow_policy);
// 工作循环, 子线程任务循环
void worker_loop_();
// 处理队列中的下一条消息
// 如果这个线程仍应该保持活跃(即未收到终止消息),则返回 true
bool process_next_msg_();
};
这里的SPDLOG_API是用于控制跨平台开发中的符号导出和导入,确保在构建和使用 spdlog 库时,符号能够正确地暴露给外部使用者。通过控制符号的可见性,可以减少导出符号的数量。这不仅减少了共享库的大小,还可以加快编译和链接过程。对于大型项目来说,这种性能提升是显著的。
#if defined(_WIN32) && defined(SPDLOG_DLL)
# ifdef SPDLOG_EXPORTS
# define SPDLOG_API __declspec(dllexport)
# else
# define SPDLOG_API __declspec(dllimport)
# endif
#elif defined(__GNUC__) && __GNUC__ >= 4
# define SPDLOG_API __attribute__((visibility("default")))
#else
# define SPDLOG_API
#endif
构造与析构
thread_pool的构造很简单,创建由用户指定数量threads_n的子线程数组。其中,q_max_items是环形队列容量;on_thread_start和on_thread_stop每个子线程循环执行前后的回调,也是由用户指定。
SPDLOG_INLINE thread_pool::thread_pool(
size_t q_max_items, size_t threads_n, std::function<void()> on_thread_start, std::function<void()> on_thread_stop)
: q_(q_max_items)
{
if (threads_n == 0 || threads_n > 1000) { // 1000是子线程数量最大值
throw_spdlog_ex("spdlog::thread_pool(): invalid threads_n param (valid "
"range is 1-1000)");
}
for (size_t i = 0; i < threads_n; i++) {
threads_.emplace_back([this, on_thread_start, on_thread_stop] {
on_thread_start();
this->thread_pool::worker_loop_(); // 线程循环
on_thread_stop();
});
}
}
当用户指定子线程数量太大时,抛出异常throw_spdlog_ex,该类是spdlog自定义异常类。
thread_pool的析构用来释放构造函数中申请的资源,即连接线程:等待子线程退出并回收线程资源。由于回收资源过程,可能出现异常,但析构函数是不建议抛出异常的,因此内部捕获、处理。
SPDLOG_INLINE thread_pool::~thread_pool()
{
// 析构函数不要抛出异常, 但释放线程池资源资源可能发生异常, 因此内部捕获并处理
SPDLOG_TRY
{
for (size_t i = 0; i < threads_.size(); i++) {
// 有几个子线程,就要post几个terminate的async_msg。
post_async_msg_(async_msg(async_msg_type::terminate), async_overflow_policy::block);
}
for (auto & t : threads_) {
t.join();
}
}
SPDLOG_CATCH_STD
}
在连接线程前,需要先通知子线程退出消息处理循环。通常做法是控制子线程while循环条件为false。实际上,thread_pool析构函数是向环形缓冲区末尾添加一个类型为terminate的消息,通知子线程退出循环。
这么做的好处是,不会立即退出子线程循环,而导致部分log消息可能没来得及写到目标文件。
SPDLOG_TRY和SPDLOG_CATCH_STD是spdlog定义的异常处理宏,通过宏定义SPDLOG_NO_EXCEPTIONS,我们可以一键决定spdlog是否抛出异常,or 库自行处理异常。
#ifdef SPDLOG_NO_EXCEPTIONS
# define SPDLOG_TRY
# define SPDLOG_THROW(ex) \
do \
{ \
printf("spdlog fatral error: %s\n", ex.what); \
std::abort(); \
} while(0)
# define SPDLOG_CATCH_STD
#else
# define SPDLOG_TRY try
# define SPDLOG_THROW(ex) throw(ex)
# define SPDLOG_CATCH_STD \
catch (const std::exception &) {}
#endif
post_log插入log消息
通常是async_logger往thread_pool插入数据,使用的接口就是thread_pool::post_log。也就是说,async_logger应该负责构造log_msg对象,并调用post_log将构造的log_msg对象传给线程池处理。
// 往线程池插入数据
void SPDLOG_INLINE thread_pool::post_log(async_logger_ptr &&worker_ptr,
const details::log_msg &msg, async_overflow_policy overflow_policy)
{
// 将log_msg转换为async_msg
async_msg async_m(std::move(worker_ptr), async_msg_type::log, msg);
post_async_msg_(std::move(async_m), overflow_policy);
}
post_async_msg_是private方法,负责往线程池插入一条异步消息(async_msg对象)。队列满时,会用到两种策略:block(阻塞),overrun_oldest(丢弃最老的消息)。
void SPDLOG_INLINE thread_pool::post_async_msg_(async_msg &&new_msg,
async_overflow_policy overflow_policy)
{
if (overflow_policy == async_overflow_policy::block) // block策略, 阻塞等待环形队列非满
{
q_.enqueue(std::move(new_msg));
}
else // overrun_oldest策略, 非阻塞等待, 直接丢弃队列中最老的数据
{
q_.enqueue_nowait(std::move(new_msg));
}
}
post_flush 冲刷log消息
post_log把数据加入环形队列末尾,用户可以调用post_flush冲刷log消息,立即将缓冲区中的log消息写入目标文件。实现方式是向队列末尾插入一个类型为flush的消息,后端线程识别到该类消息时,会调用对应的flush函数将缓存数据冲刷到目标文件。
void SPDLOG_INLINE thread_pool::post_flush(async_logger_ptr &&worker_ptr,
async_overflow_policy overflow_policy)
{
post_async_msg_(async_msg(std::move(worker_ptr), async_msg_type::flush), overflow_policy);
}
post_flush与post_log类似,通常都是由async_logger调用。这里不展开介绍,相见介绍logger的章节。
子线程循环
子线程循环就是一个while循环,循环的每次都会执行process_next_msg_:从环形缓冲区取数据作为异步消息async_msg,并根据消息类型分类处理。当环形缓冲区为空时,最多阻塞等待10秒。这里可以改成更长或更短时间。
// 子线程循环
void SPDLOG_INLINE thread_pool::worker_loop_()
{
while (process_next_msg_()) {}
}
bool SPDLOG_INLINE thread_pool::process_next_msg_()
{
async_msg incoming_async_msg;
bool dequeued = q_.dequeue_for(incoming_async_msg, std::chrono::seconds(10)); // 从环形缓冲区取出数据
if (!dequeued)
{
return true;
}
// 成功取出一条数据存作为异步消息, 根据消息类型分类处理
switch (incoming_async_msg.msg_type)
{
case async_msg_type::log: { // 处理类别为log的异步消息
incoming_async_msg.worker_ptr->backend_sink_it_(incoming_async_msg);
return true;
}
case async_msg_type::flush: { // 处理类别为flush的异步消息
incoming_async_msg.worker_ptr->backend_flush_();
return true;
}
case async_msg_type::terminate: { // 处理类别为terminate的异步消息
return false;
}
default: {
assert(false); // impossible except exception
}
}
return true;
}
这里的SPDLOG_INLINE是为了在不同的编译器或构建配置下更好地控制内联函数的行为,可以显著提高性能。
#if defined(_MSC_VER)
# define SPDLOG_INLINE __forceinline
#elif defined(__GNUC__) || defined(__clang__)
# define SPDLOG_INLINE inline __attribute__((always_inline))
#else
# define SPDLOG_INLINE inline
#endif
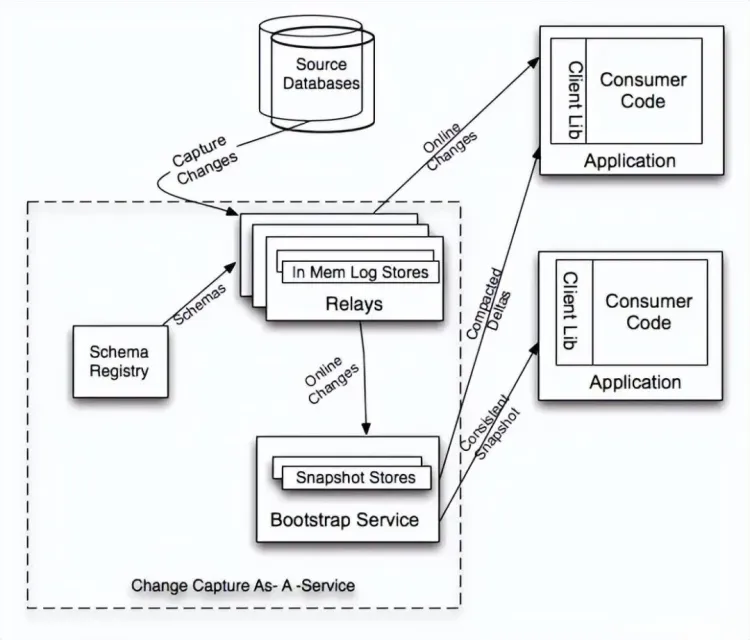
线程池数据:异步消息async_msg
线程池的每个子线程就是一个循环,不断从环形阻塞队列取数据、处理数据。环形队列details::mpmc_blocking_queue<item_type>是一个类模板,数据类型item_type实际上是async_msg类。
派生类async_msg本质上是一个log_msg_buffer(log消息缓存),但async_msg扩展了其功能,还包含:消息类型和一个指向async_logger的共享指针。
定义派生类async_msg目的何在?为什么不直接用log_msg_buffer作为线程池代表数据的log消息?
log_msg_buffer本质上是一个log_msg(log消息各部分原始数据) + memory_buf_t二进制缓存(存放格式化后的数据)。扩展后,消息类型可用于后端线程识别异步消息类型,async_logger共享指针可用于回调处理异步消息。
异步消息类型
消息类型可用于后端线程识别消息类型,并根据分类处理。消息类型async_msg_type分为3类:
log —— 普通日志消息
flush —— 冲刷日志消息到目标(sink)
terminate —— 终止线程池子线程(工作线程)
enum class async_msg_type
{
log,
flush,
terminate
};
async_msg类实现
// 异步消息类,用于在队列中移动
// 仅可移动,不应复制
using async_logger_ptr = std::shared_ptr<spdlog::async_logger>;
struct async_msg : log_msg_buffer
{
async_msg_type msg_type{async_msg_type::log};
async_logger_ptr worker_ptr;
async_msg() = default;
~async_msg() = default;
// should only be moved in or out of the queue..
async_msg(const async_msg &) = delete;
async_msg(async_msg &&) = default;
async_msg &operator=(async_msg &&) = default;
// construct from log_msg with given type
async_msg(async_logger_ptr &&worker, async_msg_type the_type, const details::log_msg &m)
: log_msg_buffer{m}
, msg_type{the_type}
, worker_ptr{std::move(worker)}
{}
...
explicit async_msg(async_msg_type the_type)
: async_msg{nullptr, the_type}
{}
};
使用 shared_ptr&&(右值引用)作为参数可以避免增加引用计数。这仅传递共享指针的控制权,不会触发引用计数的增加和减少,减少了性能开销。如果传递的是左值,可以用 std::move 将其转换为右值,仍然可以避免不必要的复制。
基类log_msg_buffer
基类log_msg_buffer从log_msg派生而来,在基类继承上添加了memory_buf_t类型的二进制缓存buffer,用于存放格式化的log消息。格式化的过程,是放在构造函数中的,无需调用其他接口,构造即格式转换。
// Extend log_msg with internal buffer to store its payload.
// This is needed since log_msg holds string_views that points to stack data.
class SPDLOG_API log_msg_buffer : public log_msg
{
memory_buf_t buffer;
void update_string_views();
public:
log_msg_buffer() = default;
explicit log_msg_buffer(const log_msg &orig_msg);
log_msg_buffer(const log_msg_buffer &other);
log_msg_buffer(log_msg_buffer &&other) SPDLOG_NOEXCEPT;
log_msg_buffer &operator=(const log_msg_buffer &other);
log_msg_buffer &operator=(log_msg_buffer &&other) SPDLOG_NOEXCEPT;
};
基类log_msg
log_msg包含了一条log消息的各个组成部分的原始信息:logger name,log level,logging time point,thread id,记录log消息的代码位置信息(文件名、行数),用户负载等。如果想要支持log消息着色,log_msg也包含了可用于log消息着色的位置信息。
struct SPDLOG_API log_msg
{
log_msg() = default;
log_msg(log_clock::time_point log_time, source_loc loc, string_view_t logger_name, level::level_enum lvl, string_view_t msg);
log_msg(source_loc loc, string_view_t logger_name, level::level_enum lvl, string_view_t msg);
log_msg(string_view_t logger_name, level::level_enum lvl, string_view_t msg);
log_msg(const log_msg &other) = default;
log_msg &operator=(const log_msg &other) = default;
string_view_t logger_name; // logger名字
level::level_enum level{level::off}; // log level
log_clock::time_point time; // 记录log的时间点
size_t thread_id{0}; // 线程id
// wrapping the formatted text with color (updated by pattern_formatter).
mutable size_t color_range_start{0}; // 着色范围起始位置
mutable size_t color_range_end{0}; // 着手范围结束位置
source_loc source; // 创建该对象的源码位置(文件名、行数)
string_view_t payload; // 负载(用户想要记录的数据)
};
logger name通常用来唯一标识logger对象。不过,在log_msg中,这只是一个用于记录log的标识字符串。类型string_view_t是C++17标准库的内容,表示一个字符串视图,不提供实际存储;spdlog内嵌的ftm库包含了该类型定义。
level表示日志等级,值越大优先级越高;off表示关闭日志等级,n_levels表示日志等级个数。
enum level_enum : int
{
trace = SPDLOG_LEVEL_TRACE,
debug = SPDLOG_LEVEL_DEBUG,
info = SPDLOG_LEVEL_INFO,
warn = SPDLOG_LEVEL_WARN,
err = SPDLOG_LEVEL_ERROR,
critical = SPDLOG_LEVEL_CRITICAL,
off = SPDLOG_LEVEL_OFF,
n_levels
};
thread_pool的使用
registry类创建
resitry只提供3个与thread_pool有关的成员函数:
- set_tp 设置thread_pool共享指针成员tp_
- get_tp 获取thread_pool共享指针成员tp_
- shutdown 释放线程池tp_
// include/spdlog/details/registry.h
class SPDLOG_API registry
{
public:
...
void set_tp(std::shared_ptr<thread_pool> tp);
std::shared_ptr<thread_pool> get_tp();
void shutdown();
...
private:
std::shared_ptr<thread_pool> tp_;
...
}
SPDLOG_INLINE void registry::set_tp(std::shared_ptr<thread_pool> tp)
{
std::lock_guard<std::recursive_mutex> lock(tp_mutex_);
tp_ = std::move(tp);
}
SPDLOG_INLINE std::shared_ptr<thread_pool> registry::get_tp()
{
std::lock_guard<std::recursive_mutex> lock(tp_mutex_);
return tp_;
}
SPDLOG_INLINE void registry::shutdown()
{
{
std::lock_guard<std::mutex> lock(flusher_mutex_);
periodic_flusher_.reset();
}
drop_all();
{
std::lock_guard<std::recursive_mutex> lock(tp_mutex_);
tp_.reset(); // 释放线程池
}
}
async_logger类使用
async_logger并非线程池对象的管理者,出于安全考虑,async_logger通过一个弱指针(weak_ptr<thread_pool>)thread_pool_获取线程池对象。
class SPDLOG_API async_logger final : public std::enable_shared_from_this<async_logger>, public logger
{
friend class details::thread_pool;
public:
template<typename It>
async_logger(std::string logger_name, It begin, It end, std::weak_ptr<details::thread_pool> tp,
async_overflow_policy overflow_policy = async_overflow_policy::block)
: logger(std::move(logger_name), begin, end)
, thread_pool_(std::move(tp))
, overflow_policy_(overflow_policy)
{}
...
std::shared_ptr<logger> clone(std::string new_name) override;
protected:
void sink_it_(const details::log_msg &msg) override;
void flush_() override;
void backend_sink_it_(const details::log_msg &incoming_log_msg);
void backend_flush_();
private:
std::weak_ptr<details::thread_pool> thread_pool_;
async_overflow_policy overflow_policy_;
};
私有函数sink_it_负责调用thread_pool::post_log,将log消息写到线程池缓存(环形队列)。
私有函数flush_负责调用thread_pool::post_flush,将冲刷缓存(环形队列+标准库缓存)中的log消息到目标文件。
// include/spdlog/async_logger-inl.h
// 前端线程调用
SPDLOG_INLINE void spdlog::async_logger::sink_it_(const details::log_msg &msg)
{
if (auto pool_ptr = thread_pool_.lock())
{
pool_ptr->post_log(shared_from_this(), msg, overflow_policy_);
}
else
{
throw_spdlog_ex("async log: thread pool doesn't exist anymore");
}
}
// 发送 flush请求
SPDLOG_INLINE void spdlog::async_logger::flush_()
{
if (auto pool_ptr = thread_pool_.lock())
{
pool_ptr->post_flush(shared_from_this(), overflow_policy_);
}
else
{
throw_spdlog_ex("async flush: thread pool doesn't exist anymore");
}
}
async_logger通过post_log将包裹this的共享指针shared_from_this(),传递给了thread_pool对象;而thread_pool对象又通过环形队列持有async_logger的共享指针,这不会形成循环引用。因为async_logger持有thread_pool对象点弱指针,而非共享指针。因此不会形成循环引用。
上面2个函数,是由前端线程调用;后端线程在接收到相应log消息,实际对应执行的是backend_sink_it_和backend_flush。
总结
spdlog 的高效性主要体现在以下几个方面:
- 通过线程池避免频繁的线程创建和销毁。
- 使用多生产者-多消费者模型,实现高效的并发日志处理。
- 通过环形队列和右值引用支持,优化数据插入和移动效率。
- 异步消息类型和任务处理机制,确保日志消息的正确处理和写入。
- 宏定义控制符号导出和内联函数,提升跨平台性能。