最近好多小伙伴都跑来问小北,百亿级别的数据存储要怎么设计架构啊?
听说面试里经常问到这个问题。
就像前几天,有位同学去字节面试,就碰到了这个问题:
“百亿级数据存储,你怎么设计?”
他们回答说要分库分表,但面试官好像不太满意。那到底为啥呢?
小北今天就用这10年的技术经验,给大家好好说说,怎么从0开始设计这个百亿级的数据存储架构。
首先,咱们得明白,这种级别的数据存储架构,得具备哪些能力。
简单来说,一般需要具备以下多种能力 :
- 要能处理高并发的在线事务、搜索
- 能处理海量数据的离线任务,甚至还得有冗余表双写能力,也就是能同时处理多个业务维度的事务。
比如说,在订单特别多的情况下,咱们得按用户维度和商家维度来分别处理事务。
当然,如果业务没那么复杂,这个双写能力就是可选的。
不过啊,搞这么多副本也有好处也有坏处。
好处是能满足各种处理需求,坏处就是得维护多个副本之间的数据一致性。
最近无意间获得一份阿里大佬写的刷题笔记,一下子打通了我的任督二脉,进大厂原来没那么难。
这是大佬写的, 7701页的BAT大佬写的刷题笔记,让我offer拿到手软
怎么实现这个数据一致性呢?
为了让商品搜索更快,咱们可以用两个方案:
- 把商品数据冗余存储在Elasticsearch里,这样搜索就超快了;
- 把商品数据放在redis里,做个高速缓存。这样一来,搜索速度就嗖嗖的了!

既然我们有了这么多数据的副本,那么问题就来了,怎么确保这些副本的数据都是一模一样的呢?
举几个例子哈:
- 比如说,我们要让 mysql 和 es(一种搜索引擎)的数据在几秒钟内就同步上。
- 还有啊,mysql 和 redis(一个超快的内存数据库)也得在几秒钟内同步数据。
- 还有 mysql 和 hbase(一个分布式存储系统)也得有秒级别的数据同步。
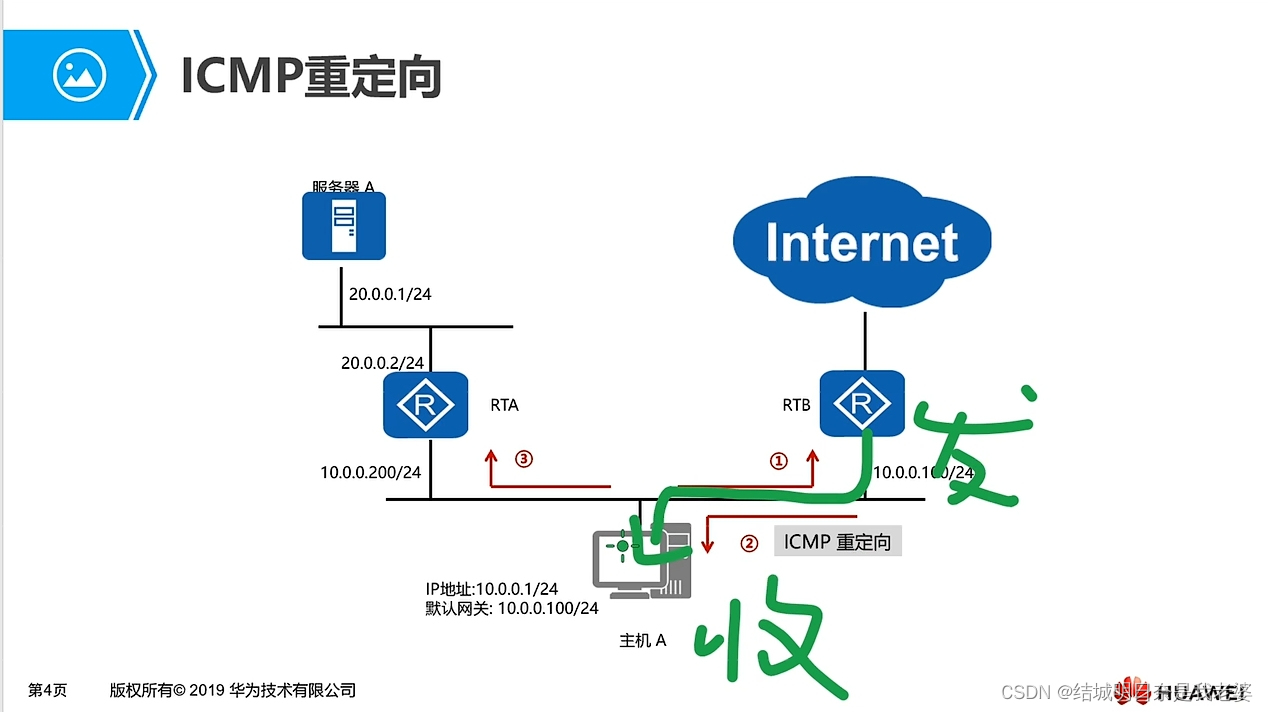
接下来,我就拿 mysql 和 es 的数据同步来给大家说道说道,其他的同步方式,其实都差不多。
大家要是能把下面这五大绝招,关于数据一致性的方案,说得头头是道、滔滔不绝,那面试官估计得听得目瞪口呆,口水都要流出来了!
方案1:同步双写
同步双写是一种最为简单的方式,在将数据写到 MySQL 时,同时将数据写到 ES。

同步双写的好处啊,就是快!简单直接,实时写入几乎就是秒秒钟的事儿。
但说到缺点,也是一大堆。
首先,业务太紧密了,这种写法让代码变得很复杂。
比如你原本写 mysql 的地方,现在还得加写 es 的代码,以后每次写 mysql 都得记得加 es。这就好比你在炒菜,本来只放一种调料,现在得放两种,麻烦得很。
再来说说性能吧。
因为要写入两个存储,所以响应时间会变长。
MySQL 本身性能就一般,再加上 ES,整个系统的性能肯定得降一降。
还有啊,扩展起来也麻烦。
比如搜索功能,有时候需要个性化,得对数据进行聚合处理,但这种方式就很难实现这种需求。
最要命的是,这种方式风险还高。如果双写失败了,数据就可能丢失!
方案2:异步双写
同步操作真的挺慢的,但异步操作就快多了。说到异步双写,它主要有两种实现方式:
- 使用内存队列(如阻塞队列)异步
- 使用消息队列进行异步
方案2.1 使用内存队列(如阻塞队列)异步
先把商品的数据写进数据库,然后把这个数据放进这个内存队列(比如BlockingQueue)里面。
之后,有一个专门负责“干活”的线程,它会从队列里拿出数据,再一批一批地写入ElasticSearch。这
样,数据的一致性就能得到保证了。
同步流程如下:

方案2.2 使用消息队列(如RRocketMQ)异步
我们都知道存储在内存的数据是不稳定的,一旦服务宕机或重启,内存队列里边数据就会丢失,那么es 当中的数据和DB就不一致了
针对这种问题,我们该如何解决呢?
这时候就可以用可靠性消息队列(RocketMQ)来解决了
生产场景中,我们一般会有一个搜索服务,由搜索服务去订阅商品变动的消息,来完成同步。

异步双写优点:
- 性能高;
- 不易出现数据丢失问题,主要基于 MQ 消息的消费保障机制,比如 ES 宕机或者写入失败,还能重新消费 MQ 消息;
- 多源写入之间相互隔离,便于扩展更多的数据源写入。
异步双写缺点:
- 硬编码问题,接入新的数据源需要实现新的消费者代码;
- 系统复杂度增加,引入了消息中间件;
- MQ是异步消费模型,用户写入的数据不一定可以马上看到,造成延时。
最近无意间获得一份阿里大佬写的刷题笔记,一下子打通了我的任督二脉,进大厂原来没那么难。
这是大佬写的, 7701页的BAT大佬写的刷题笔记,让我offer拿到手软
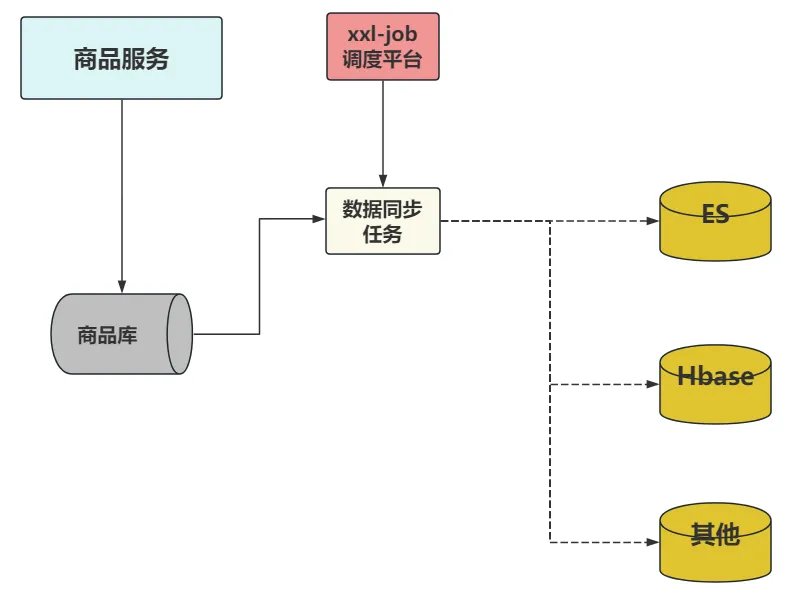
方案3 定期同步
定期同步我们可以设计两个方案,分别是:增量数据同步和全量数据同步
方案3.1 增量数据同步
通过定时任务(例如xxl-job)调度平台,定期同步增量数据。
例如每一个小时,同步所有更新时间变更的数据
适用场景:
- 数据增量不是很大,更新时间变更的数据不多
- 一致性要求不高,可以接受一定的数据同步延迟
方案3.2 全量数据同步
全量数据同步一般很少用,因为如果百亿级别的数据,采用全量数据同步,会有以下的问题:
- 同步完成时间很长,导致数据延迟很高
- 会有中间中断的情况
所以全量同步一般只作为第一次DB的数据往ES或HBase等大数据框架中同步使用。
或者是每天晚上做一次全量数据(一定时间范围内)同步检查,以保证第二天的部分热数据完全一致性
定期全量同步优点:
- 实现比较简单
定期同步缺点:
- 实时性难以保证
- 对存储压力较大
方案4 数据订阅(MySQL的binlog+Canal)
实现方案
- 基于Binlog的实时同步:
- MySQL的Binlog(Binary Log)记录了所有的增删改操作。通过解析Binlog,可以实时获取数据变更。
- 使用工具如Debezium或Canal,这些工具可以捕获MySQL Binlog并将变更数据同步到Elasticsearch

步骤
- 配置MySQL开启Binlog,并确保日志格式为ROW。
- 部署Debezium或Canal,连接到MySQL并订阅Binlog。
- 配置Kafka、Logstash等数据管道,将捕获的变更数据流式传输到Elasticsearch。
- 在Elasticsearch中配置索引和文档结构,确保能够正确接收和存储变更数据。
优点
- 实时性好: 数据几乎实时同步,延迟较低。
- 性能优: 只同步变化的数据,减少了不必要的全量同步开销。
- 一致性强: 可以保证数据的强一致性,尤其适用于频繁变更的数据。
- **无侵入:**对商品服务无侵入
缺点
- 复杂度高: 需要配置和维护Binlog捕获工具及数据管道。
- 依赖性强: 依赖于MySQL的Binlog机制和额外的工具,如Debezium、Canal等。
- 错误处理复杂: 数据变更过程中出现错误时,恢复和重新同步较为复杂。
最近无意间获得一份阿里大佬写的刷题笔记,一下子打通了我的任督二脉,进大厂原来没那么难。
这是大佬写的, 7701页的BAT大佬写的刷题笔记,让我offer拿到手软
方案5 冗余表的同步双写/异步双写
数据量都这么大了,为啥我们要搞个冗余表呢?
简单来说,当我们的t_order表里的订单数量达到500万条或者表的大小超过2GB时,就需要考虑把这个表拆分成多个小表,这样查询起来会更快。
拆分表时,我们得根据某个列(分表健)来分,比如按照userId来分。那对于用户来说,他们查询自己的订单时,带上userId就能找到对应的表。
但问题来了,商家想查自己店铺的订单时,他们不知道具体的userId啊,所以他们得把每个小表都查一遍,再把结果拼起来,这样效率就超级低了。
为了解决这个问题,我们可以给商家搞个冗余的订单表。
这个冗余表不是按照userId分的,而是按照merchantId(商家ID)来分的。
这样商家查自己店铺的订单时,直接查这个冗余表就行了,效率就大大提高了。
不过呢,这样做也有个坏处,就是我们要保证这个冗余表和普通表里的数据得一致,得定期维护它们,确保两边数据都一样。
但总的来说,为了提升查询效率,这点麻烦还是值得的。
冗余表的同步双写实现方案

更新t_order的操作要执行两次,一次更新普通表,一次更新冗余表,写两次。优点:
- 实现简单,由一次写变为两次写
- 容易维护数据的一致性
缺点:
- 代码冗余,第二次写跟第一次写的代码类似,而且每个更新的地方都要写两次
- 请求处理时间变长
冗余表的异步双写方案

更新请求过来,写一次数据库,再发送一条消息到消息中间件,返回响应。
消费者拉取消息进行写操作。
优点:
- 处理时间是单次写
缺点
- 较复杂,引入了消息中间件
- 不容易维护数据的一致性
方案6 ETL数据同步
什么是ETL数据同步?
ETL,是英文 Extract-Transform-Load 的缩写,用来描述将数据从来源端经过抽取(extract)、转换(transform)、加载(load)至目的端的过程。ETL一词较常用在数据仓库,但其对象并不限于数据仓库。
ETL的工作原理?
ETL是构建数据仓库的重要一环,用户从数据源抽取出所需的数据,经过数据清洗,最终按照预先定义好的数据仓库模型,将数据加载到数据仓库中去。
ETL的常用工具有哪些?
常用的etl工具有:databus、canal (方案四用了这个组件,有etl 的部分功能)、otter 、kettle 等
下面以 databus为例,介绍一下:
databus,其实就是一个特别牛的数据抓取系统。这个系统是LinkedIn在2013年开源的,它能实时、可靠地抓取数据库的变动。
你想啊,数据库里数据一变,databus就能立马知道,然后业务那边就可以通过特定的方式拿到这些变化,去做自己想做的事情。
那databus有啥厉害的地方呢?
首先,它支持多种数据源,比如Oracle和MySQL。也就是说,不管你的数据放在哪里,databus都能帮你抓到。
然后,它特别能抗造,可以支持很多消费者同时来拿数据,还不容易出问题。
而且啊,databus还能保持数据原来的顺序,比如你数据库里有个事务,它里面的数据变化,databus都会按照原来的顺序给你。
再说说速度吧,数据源一变,databus就能在几毫秒内把这些变化给消费者。消费者还可以自己选只拿自己想要的数据,特别方便。
最后,如果你想要重新看一遍之前的数据,databus也能做到,而且不会对数据库造成啥负担。就算你的数据已经落后数据库很多了,也能用这个功能来补。
总的来说,databus就是一个很厉害的数据抓取工具,特别适合那些需要实时知道数据库变化并做业务处理的场景。
最后再看看Databus 的系统架构
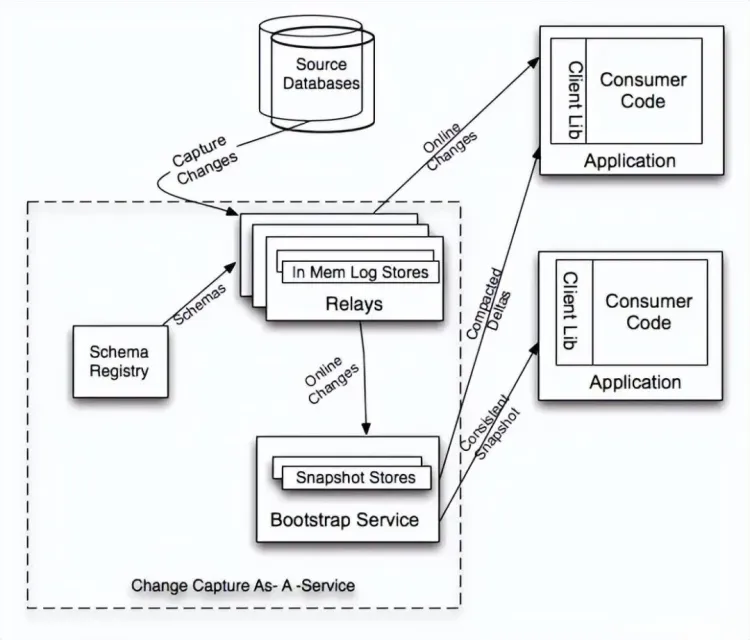
Databus 由 Relays、bootstrap 服务和 Client lib 等组成,Bootstrap 服务中包括 Bootstrap Producer 和 Bootstrap Server。
- 快速变化的消费者直接从 Relay 中取事件;
- 如果一个消费者的数据更新大幅落后,它要的数据就不在 Relay 的日志中,而是需要请求 Bootstrap 服务,返回的将会是自消费者上次处理变更之后的所有数据变更快照。
最后给大家贴一下Databus的开源地址,感兴趣的可以自己去研究下
开源地址:https://github.com/linkedin/databus
总结
看到这里,大家心里都对百亿级数据存储并发搜索的设计方案有一个清晰的认知了吧。
最后再给大家做一个完整的总结:以电商订单场景为例
- 首先百亿级数据级别的存储,肯定要分表
- 在分表的基础上,考虑到不同目标用户的场景,我们需要针对C端用户和商家用户做冗余表(一套ToC,一套ToB)
- 为了满足除单个用户、单个商家的查询场景(例如运营或者是其他搜素场景),我们需要借助ES等搜索引擎满足搜索的业务场景
- 最后解决数据库DB与ES、Hbase、Redis等中间件数据同步问题(参考本文的6种方案)
最后说一句(求关注,求赞,别白嫖我)
最近无意间获得一份阿里大佬写的刷题笔记,一下子打通了我的任督二脉,进大厂原来没那么难。
这是大佬写的, 7701页的BAT大佬写的刷题笔记,让我offer拿到手软
本文,已收录于,我的技术网站 cxykk.com:程序员编程资料站,有大厂完整面经,工作技术,架构师成长之路,等经验分享
求一键三连:点赞、分享、收藏
点赞对我真的非常重要!在线求赞,加个关注我会非常感激!







![[AI OpenAI] OpenAI董事会成立安全与保障委员会](https://img-blog.csdnimg.cn/img_convert/933ef00b4a44b9d1e6fa74e65ac0fb72.jpeg)