【Paddle】稀疏计算的使用指南 & 稀疏ResNet的学习心得 + Paddle3D应用实例稀疏 ResNet代码解读
- 写在最前面
- 一、稀疏格式简介
- 1. COO(Coordinate Format)
- 2. CSR(Compressed Sparse Row Format)
- 二、Paddle稀疏张量支持
- 1. 创建 COO 格式的 SparseTensor
- 2. 创建 CSR 格式的 SparseTensor
- 3. 创建稀疏张量的相关参数详解
- 共通参数
- 特定于格式的参数细节
- 4. COO格式和CSR格式的选择建议
- 5. 稀疏与稠密 Tensor 互转
- 三、Paddle稀疏的设计优势
- 1. API设计的一致性
- 2. 集成度:训练和推理的处理流程
- 四、Paddle稀疏神经网络层支持
- 1. 稀疏 ResNet 的应用场景
- 2. 构建稀疏 ResNet 模型
- 3. 稀疏 ResNet的关键组件
- 4. 构建稀疏 ResNet 模型的示例代码
- 五、Paddle3D应用实例解读:稀疏 ResNet
- 代码注释
- 导入所需库和模块
- 定义卷积函数
- 定义稀疏基础块类
- 定义SparseResNet3D网络
- 六、小结
- 七、参考文献

写在最前面
在现代计算框架中,为了高效地处理和存储大规模的数据集,尤其是在这些数据集中存在大量零值的情况下,采用稀疏数据结构变得尤为重要。PaddlePaddle,作为一个领先的深度学习平台,提供了强大的稀疏计算能力,支持从基本的稀疏张量操作到构建复杂的稀疏神经网络。这些工具主要通过 paddle.sparse 命名空间来实现,使得开发者能够高效地处理大量包含零值的数据集,从而优化内存使用和计算速度。
本文将详细介绍如何在 PaddlePaddle 中利用稀疏计算,包括稀疏数据格式的基础知识、如何创建和操作稀疏张量,以及如何开发和训练稀疏神经网络模型,特别是如何实现和应用稀疏 ResNet。通过这些知识,我们可以更有效地利用计算资源,加速模型训练过程,同时提高模型处理大规模稀疏数据的能力。

一、稀疏格式简介
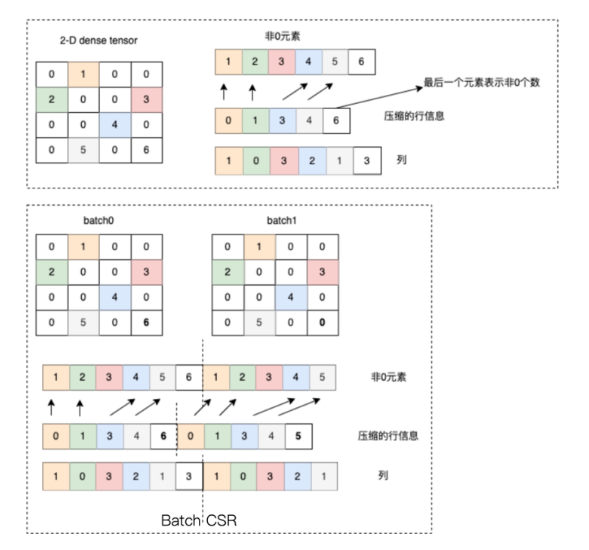
稀疏格式是一种特殊的数据存储方式,旨在有效存储和处理其中大部分元素为零的矩阵或张量。这种方法可以显著减少存储空间的需求,并提高数据处理的效率。常见的稀疏格式包括 COO(坐标列表格式)、CSR(压缩稀疏行格式)等。
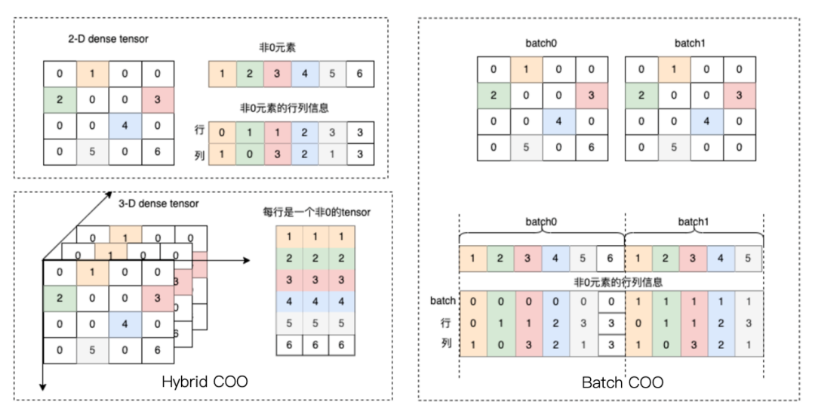
1. COO(Coordinate Format)
在 COO 格式中,只记录非零元素的位置和值。这种格式由三个主要组件组成:indices、values 和 shape。indices 是一个二维数组,其中的每一列代表一个非零元素的坐标;values 存储对应的非零元素值;shape 则描述了张量的维度。
2. CSR(Compressed Sparse Row Format)
CSR 格式是一种更为紧凑的稀疏表示,专为快速的行访问和矩阵乘法运算优化。在 CSR 中,通过三个数组 crows、cols 和 values 来表示稀疏矩阵。crows 存储每一行第一个非零元素的索引,cols 存储非零元素的列索引,而 values 则直接存储这些非零元素的值。
二、Paddle稀疏张量支持
PaddlePaddle 提供了完整的支持来创建和操作 COO 和 CSR 格式的稀疏张量。以下是使用 PaddlePaddle 创建和操作这些张量的具体方法。
1. 创建 COO 格式的 SparseTensor
COO格式(Coordinate List):
- 这是一种常用的稀疏表示格式,其中非零元素通过其坐标列表进行存储。
- 使用
paddle.sparse.sparse_coo_tensor(indices, values, shape)可以创建 COO 格式的稀疏张量,其中indices是一个二维整数张量,指示非零元素的坐标;values是一个张量,包含与indices对应的值;shape是一个定义张量形状的整数列表或张量。
结构特点:
- COO格式通过一个坐标列表存储非零元素的位置和相应的值。
- 它使用三个数组:一个数组存储行索引,一个存储列索引,第三个存储元素值。
适用场景:
- 数据添加频繁:当稀疏矩阵需要频繁添加新的非零元素时,COO格式是较好的选择,因为它允许直接添加数据而不需重新构造整个数据结构。
- 简单结构:适合于那些结构简单的矩阵,特别是在非零元素分布较为随机时。
示例代码:
PaddlePaddle 使用 sparse_coo_tensor 函数来创建 COO 格式的稀疏张量。
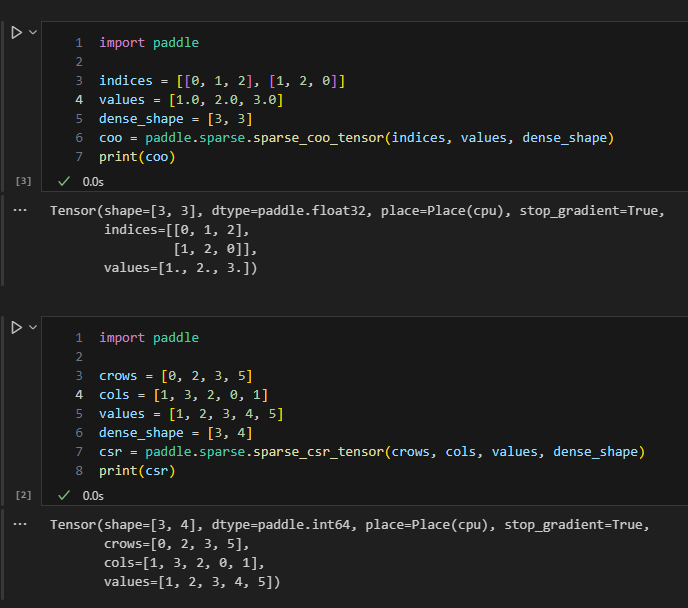
import paddle
indices = [[0, 1, 2], [1, 2, 0]]
values = [1.0, 2.0, 3.0]
dense_shape = [3, 3]
coo = paddle.sparse.sparse_coo_tensor(indices, values, dense_shape)
print(coo)
输出:
Tensor(shape=[3, 3], dtype=paddle.float32, place=Place(cpu), stop_gradient=True,
indices=[[0, 1, 2],
[1, 2, 0]],
values=[1., 2., 3.])
在这个例子中,indices定义了非零元素的位置,其中每个子数组的两个数字分别代表行和列的坐标。
2. 创建 CSR 格式的 SparseTensor
CSR格式(Compressed Sparse Row):
- 这是另一种常用的稀疏表示格式,主要用于优化行访问的性能,其中非零元素通过行的压缩方式进行存储。
- 使用
paddle.sparse.sparse_csr_tensor(crows, cols, values, dense_shape)可以创建 CSR 格式的稀疏张量,其中crows定义了每一行非零元素开始的位置在values数组中的索引,这有助于快速定位行的起始点和终点。cols则指示了非零元素在各自行中的列位置,values提供了相应的值。dense_shape指定了张量的整体形状,即行数和列数。
结构特点:
- CSR格式通过行来压缩存储,使用三个数组:行指针数组、列索引数组、以及非零元素值数组。
- 行指针数组的大小比实际行数多一个,用于表示每行的起始位置和结束位置。
适用场景:
- 行操作优化:当需要高效地进行行相关的操作(如行切片、行求和)时,CSR格式提供更优的性能。
- 矩阵乘法:对于稀疏矩阵与稀疏或密集矩阵的乘法运算,CSR格式通常会提供更好的性能。
- 大规模数据处理:在处理大规模稀疏数据时,CSR格式因其压缩特性而节省内存。
示例代码:
为了创建 CSR 格式的稀疏张量,PaddlePaddle 提供了 sparse_csr_tensor 函数。
import paddle
crows = [0, 2, 3, 5]
cols = [1, 3, 2, 0, 1]
values = [1, 2, 3, 4, 5]
dense_shape = [3, 4]
csr = paddle.sparse.sparse_csr_tensor(crows, cols, values, dense_shape)
print(csr)
输出:
Tensor(shape=[3, 4], dtype=paddle.int64, place=Place(cpu), stop_gradient=True,
crows=[0, 2, 3, 5],
cols=[1, 3, 2, 0, 1],
values=[1, 2, 3, 4, 5])
在这个例子中,crows定义了每一行非零元素开始的位置在values数组中的索引,这有助于快速定位行的起始点和终点。
这种CSR格式的表示方式适用于数据稀疏且行访问频繁的场景。它通过压缩行索引来减少内存使用,优化了对稀疏矩阵行的操作,使得行级操作更加高效。在处理行密集型操作(如行切片或行求和)时特别有用,也适合于稀疏矩阵的乘法等计算密集任务。
3. 创建稀疏张量的相关参数详解
在 PaddlePaddle 的稀疏张量创建API中,参数的设计允许用户灵活地定义和操作稀疏数据结构。对于两种类型的稀疏张量创建函数,参数主要涉及初始化数据的类型和结构,其中:
共通参数
对于 sparse_coo_tensor 和 sparse_csr_tensor 函数,存在一些共通的参数,这些参数允许用户指定如何构建和处理稀疏张量:
-
values (list|tuple|ndarray|Tensor):
- 表示非零元素的实际数值。
- 类似于索引参数,这可以是 list、tuple、NumPy ndarray 或 Paddle Tensor。
-
shape (list|tuple, 可选):
- 定义稀疏张量的形状,如果未提供,则会根据 indices 或 crows 和 cols 的最大值自动推断。
- 必须是一个整数列表或元组,指定张量在每个维度的大小。
-
dtype (str|np.dtype, 可选):
- 指定张量元素的数据类型,如 ‘float32’, ‘int64’ 等。
- 如果未指定,则从
values的数据类型自动推断。
-
place (CPUPlace|CUDAPinnedPlace|CUDAPlace|str, 可选):
- 决定张量的存储设备,例如 CPU 或 GPU。
- 如果未指定,则使用当前环境的默认设备。
-
stop_gradient (bool, 可选):
- 指示是否对该张量进行梯度计算。
- 在大多数深度学习应用中,非模型权重的张量通常设置为
True以提高计算效率。
特定于格式的参数细节
除了上述共通参数外,COO 和 CSR 格式因其数据结构的不同而在参数应用上有所区别。
indices, crows, cols (list|tuple|ndarray|Tensor):
- 对于 COO 格式,
indices参数是一个二维数组,用于直接指定每个非零元素的多维坐标。主要用于数据的随机访问和转换操作,适用于那些非零元素分布相对均匀的场景。 - 对于 CSR 格式,
crows表示每一行的起始非零元素索引,而cols存储这些非零元素的列索引。CSR 格式优化了行的连续访问,非常适合矩阵乘法和其他行优先操作。 - 这些参数可以是 Python 的 list 或 tuple,也可以是 NumPy ndarray 或 Paddle Tensor。
通过这些参数的灵活使用,PaddlePaddle 允许开发者以高效且灵活的方式处理大规模稀疏数据集,从而在保持性能的同时减少内存消耗。
4. COO格式和CSR格式的选择建议
- 如果你的应用主要涉及稀疏矩阵的构建和逐项添加数据,COO格式会更简单且直接。
- 如果你的应用需要高效的行操作或频繁进行矩阵乘法,特别是在稀疏矩阵较大的情况下,CSR格式是更好的选择。
选择哪种格式应基于你的具体应用需求,如操作类型、数据规模和性能要求。在PaddlePaddle中,你可以根据需要轻松地在两种格式之间转换,以适应不同的计算需求。
5. 稀疏与稠密 Tensor 互转
PaddlePaddle 提供了一套简单易用的接口,使得稀疏张量的使用与传统的稠密张量操作体验高度一致,从而降低了学习成本并便于开发者快速上手。这种设计允许在同一个模型中灵活地使用稠密和稀疏数据结构,而且可以无缝地在它们之间转换,这对于处理大规模数据集尤其重要,例如在深度学习、图像处理和自然语言处理等领域。
PaddlePaddle 支持通过几个简单的 API,实现稀疏与稠密之间的转换,这些操作保证了数据处理的灵活性和效率。如 Tensor.to_dense()可以将稀疏张量转换为标准的密集张量, Tensor.to_sparse_coo(), 和 Tensor.to_sparse_csr() 可以将密集张量转换为 COO 格式、CSR格式 的稀疏张量。
代码示例:稠密到稀疏的转换
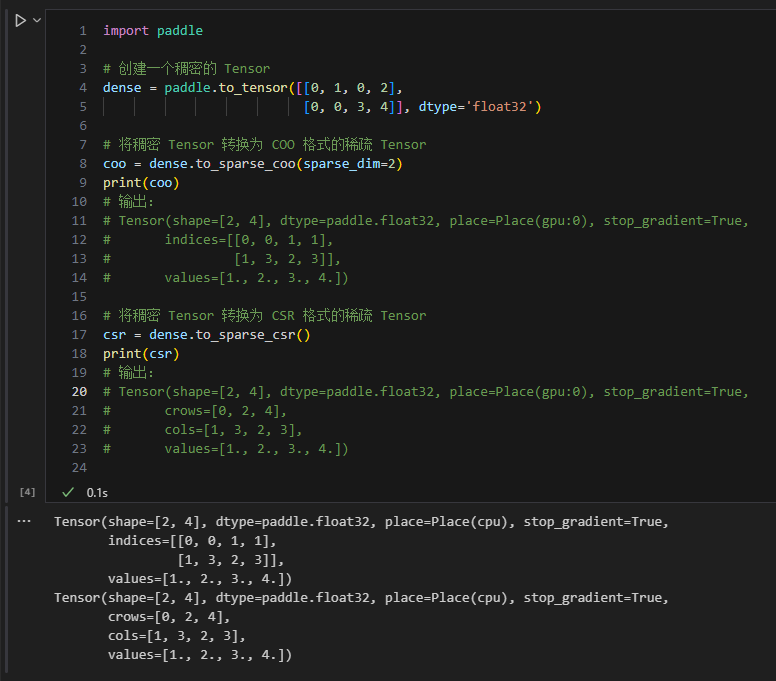
import paddle
# 创建一个稠密的 Tensor
dense = paddle.to_tensor([[0, 1, 0, 2],
[0, 0, 3, 4]], dtype='float32')
# 将稠密 Tensor 转换为 COO 格式的稀疏 Tensor
coo = dense.to_sparse_coo(sparse_dim=2)
print(coo)
# 输出:
# Tensor(shape=[2, 4], dtype=paddle.float32, place=Place(gpu:0), stop_gradient=True,
# indices=[[0, 0, 1, 1],
# [1, 3, 2, 3]],
# values=[1., 2., 3., 4.])
# 将稠密 Tensor 转换为 CSR 格式的稀疏 Tensor
csr = dense.to_sparse_csr()
print(csr)
# 输出:
# Tensor(shape=[2, 4], dtype=paddle.float32, place=Place(gpu:0), stop_gradient=True,
# crows=[0, 2, 4],
# cols=[1, 3, 2, 3],
# values=[1., 2., 3., 4.])
这些转换非常直观,仅需要简单的一步操作就可以完成,使得稀疏和稠密格式之间的交互变得无缝而高效。
三、Paddle稀疏的设计优势
PaddlePaddle 的设计目标之一是提供一致的用户体验,无论是处理稀疏数据还是稠密数据。这意味着即便是在处理包含大量零值的数据集时,开发者也可以利用熟悉的接口和模式来构建和训练模型。
1. API设计的一致性
PaddlePaddle 的稀疏模块提供了与常规稠密操作相似的API接口,使得开发者无需学习新的API就能处理稀疏数据。例如:
- 稀疏卷积层:稀疏模块中的
SubmConv3D直接对应于常规卷积操作中的Conv3D。它们的参数非常相似,如in_channels,out_channels,stride,padding等。 - 批归一化和激活函数:稀疏模块同样提供了批归一化和激活函数,如
BatchNorm3D和ReLU,其用法与常规模块中的相同。
2. 集成度:训练和推理的处理流程
无论是稀疏还是稠密模型,PaddlePaddle 中的训练和推理流程保持一致。稀疏操作可以与PaddlePaddle的其他特性(如自动微分和优化器)无缝集成,使得构建和训练稀疏模型与常规模型几乎无异。
- 定义模型:无论选择稀疏还是稠密模型,模型定义的方式都是相似的,使用
paddle.nn.Layer类来构建网络层。 - 编译模型:使用
paddle.Model对象来包装定义好的网络,然后编译,包括设置优化器、损失函数和评估指标。 - 训练和评估:通过调用
.fit和.evaluate方法来进行训练和评估,这与处理稠密数据的流程完全一致。
四、Paddle稀疏神经网络层支持
1. 稀疏 ResNet 的应用场景
在处理点云数据、图像识别或自然语言处理任务时,输入数据通常具有很高的维度和稀疏性。例如,3D点云数据往往是非结构化的,大部分体积内没有有效信息(即大部分体积是空的)。使用传统的密集(dense)卷积网络处理这类数据会带来两个主要问题:
- 效率低下:对于大量的空白区域依然进行计算,消耗计算资源。
- 存储浪费:需要为大量的零值分配存储资源。
稀疏 ResNet 解决了这些问题,通过仅在非零数据点上进行操作,从而大幅提高了计算和存储效率。
2. 构建稀疏 ResNet 模型
在 PaddlePaddle 中,稀疏 ResNet 可以通过 paddle.sparse 模块中的稀疏卷积层(如 SubmConv3D)来实现。这些层专门设计用来处理稀疏数据。稀疏卷积层接受包含非零元素坐标和值的稀疏张量,并只在这些非零元素上执行卷积运算。通过构建包含这些稀疏卷积层的网络(如 ResNet 结构中的基础块),可以高效处理稀疏数据。
创建稀疏 ResNet 主要涉及以下几个步骤:
- 创建稀疏张量:首先需要从稀疏数据(即大部分值为零的数据)中创建稀疏张量。这通常涉及指定非零数据点的坐标和相应的值。
- 定义稀疏网络结构:设计一个网络结构,它应该包含适用于处理稀疏数据的特殊卷积层(如 Paddle 的 SubmConv3D)。这些层特别优化了内存和计算资源,只在数据非零的地方进行计算。
- 前向传播:将稀疏张量输入到网络中,执行前向传播,网络会在内部处理稀疏数据,并输出结果。
- 训练和评估:就像使用常规神经网络一样,定义损失函数和优化器,然后在训练数据上训练网络,最后在验证数据上评估网络的性能。
3. 稀疏 ResNet的关键组件
PaddlePaddle 的 paddle.sparse 模块提供了对稀疏数据操作的支持,包括稀疏张量的创建、转换和计算功能。这些神经网络层针对稀疏数据的特点进行了优化,以减少对零值的计算和存储需求,提高处理效率。
- 稀疏张量(Sparse Tensor):
- 稀疏张量是一种特殊的数据结构,主要用于有效存储和处理大部分元素为零的数据。
- 在 PaddlePaddle 中,可以使用
paddle.sparse.sparse_coo_tensor来创建稀疏张量,这需要提供非零元素的坐标和值。
- 稀疏卷积层(Sparse Convolution):
paddle.sparse.nn.Conv3D:标准的三维卷积层,支持在稀疏数据上的操作,适用于处理体积大的三维数据。paddle.sparse.nn.SubmConv3D:子流形三维卷积层,用于处理3D数据的稀疏子矩阵卷积层。该层允许在3D体积数据中有效地进行卷积操作,无需将整个数据转换为密集格式,特别适用于医学影像和三维扫描等领域。
- 批归一化层(Batch Normalization)
paddle.sparse.nn.BatchNorm3D:批归一化层,专为三维数据设计,可以与稀疏卷积层结合使用,以优化稀疏数据的特征归一化过程。
- 池化层(Pooling Layers)
paddle.sparse.nn.MaxPool3D:三维最大池化层,用于在稀疏三维数据上执行池化操作,有助于降低数据的维度和提高模型的抽象能力。
- 激活层(Activation Layers)
paddle.sparse.nn.ReLU、paddle.sparse.nn.ReLU6:标准ReLU和ReLU6激活函数,支持在稀疏数据路径中使用,与常规的激活函数使用方法相同,但针对稀疏数据进行了优化。paddle.sparse.nn.LeakyReLU:LeakyReLU激活层,为包含小负斜率的ReLU变体,适用于在稀疏数据中增强模型的非线性处理能力。paddle.sparse.nn.Softmax:Softmax激活层,适用于稀疏数据路径,使用方法与常规密集数据的Softmax相同,但特别针对稀疏数据进行了优化,常用于处理多分类问题。
4. 构建稀疏 ResNet 模型的示例代码
在 PaddlePaddle 中,稀疏 ResNet 的实现和使用与传统的稠密网络相似,这得益于 PaddlePaddle 稀疏模块的设计,使得调用体验与稠密高度一致,非常容易上手。通过利用稀疏技术,可以有效处理大规模稀疏数据集,提高计算效率和降低存储需求,这在处理现代大数据应用时显得尤为重要。
下面以稀疏 ResNet为例,说明Paddle对稀疏神经网络层的支持:
import paddle
from paddle import sparse
from paddle.sparse import nn as sparse_nn
# 定义3D稀疏卷积块
def sparse_conv_block(in_channels, out_channels, stride=1, padding=1, key=None):
block = paddle.nn.Sequential(
sparse_nn.SubmConv3D(in_channels, out_channels, kernel_size=3, stride=stride, padding=padding, bias_attr=False, key=key),
sparse_nn.ReLU()
)
return block
# 定义一个简单的稀疏3D ResNet模型
class SparseResNet(paddle.nn.Layer):
def __init__(self, in_channels):
super(SparseResNet, self).__init__()
self.layer1 = sparse_conv_block(in_channels, 16, key='layer1')
self.layer2 = sparse_conv_block(16, 32, stride=2, key='layer2')
self.layer3 = sparse_conv_block(32, 64, stride=2, key='layer3')
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
return x
# 假设输入数据
batch_size = 1
channels = 1
depth = 100
height = 100
width = 100
# 创建稀疏张量的坐标和值
coords = paddle.to_tensor([[0, 0, 0, 0, 0], [0, 0, 0, 0, 0], [0, 1, 2, 1, 1], [0, 2, 2, 1, 2], [0, 1, 2, 2, 0]], dtype='int64') # 5D坐标 (batch, channel, depth, height, width)
values = paddle.to_tensor([1.0, 1.5, 2.0, 3.0, 3.5], dtype='float32') # 每个值对应一个坐标
shape = paddle.to_tensor([batch_size, channels, depth, height, width], dtype='int64') # 5D形状
# 创建稀疏张量
x = sparse.sparse_coo_tensor(coords, values, shape)
# 实例化模型
model = SparseResNet(channels)
# 使用模型进行预测
output = model(x)
print(output)
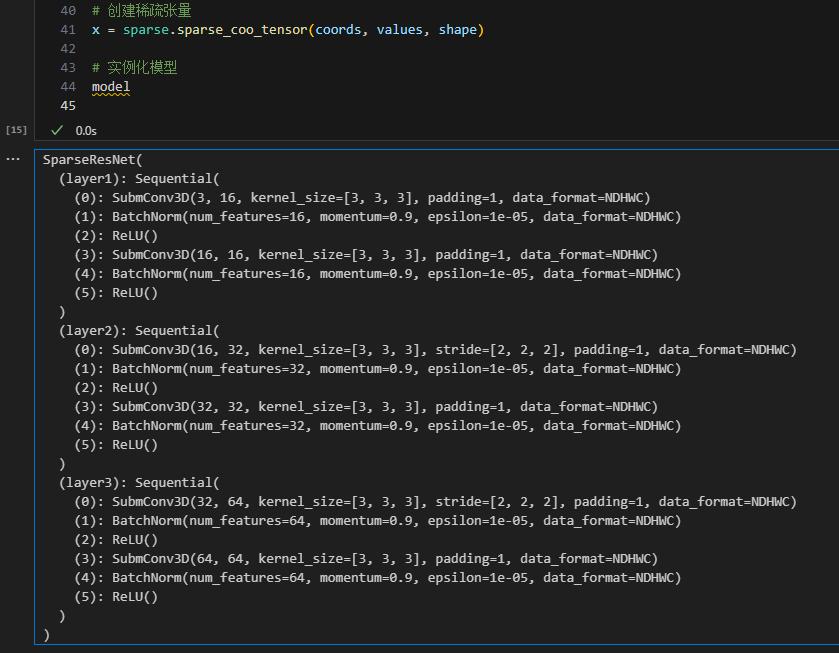
模型打印结果:
SparseResNet(
(layer1): Sequential(
(0): SubmConv3D(3, 16, kernel_size=[3, 3, 3], padding=1, data_format=NDHWC)
(1): BatchNorm(num_features=16, momentum=0.9, epsilon=1e-05, data_format=NDHWC)
(2): ReLU()
(3): SubmConv3D(16, 16, kernel_size=[3, 3, 3], padding=1, data_format=NDHWC)
(4): BatchNorm(num_features=16, momentum=0.9, epsilon=1e-05, data_format=NDHWC)
(5): ReLU()
)
(layer2): Sequential(
(0): SubmConv3D(16, 32, kernel_size=[3, 3, 3], stride=[2, 2, 2], padding=1, data_format=NDHWC)
(1): BatchNorm(num_features=32, momentum=0.9, epsilon=1e-05, data_format=NDHWC)
(2): ReLU()
(3): SubmConv3D(32, 32, kernel_size=[3, 3, 3], padding=1, data_format=NDHWC)
(4): BatchNorm(num_features=32, momentum=0.9, epsilon=1e-05, data_format=NDHWC)
(5): ReLU()
)
(layer3): Sequential(
(0): SubmConv3D(32, 64, kernel_size=[3, 3, 3], stride=[2, 2, 2], padding=1, data_format=NDHWC)
(1): BatchNorm(num_features=64, momentum=0.9, epsilon=1e-05, data_format=NDHWC)
(2): ReLU()
(3): SubmConv3D(64, 64, kernel_size=[3, 3, 3], padding=1, data_format=NDHWC)
(4): BatchNorm(num_features=64, momentum=0.9, epsilon=1e-05, data_format=NDHWC)
(5): ReLU()
)
)
输出:
Tensor(shape=[1, 1, 100, 100, 64], dtype=paddle.float32, place=Place(cpu), stop_gradient=False,
indices=[[0, 0, 0, 0],
[0, 0, 0, 0],
[0, 1, 1, 2],
[0, 1, 2, 2]],
values=[[0. , 0. , 0.08977110, 0. , 0. ,
0. , 0. , 0.16325581, 0. , 0. ,
0.08592274, 0. , 0. , 0. , 0.07656589,
……
0.12824626, 0.38880903, 0. , 0. , 0.23209766,
0. , 0. , 0. , 0.24539268, 0.17324814,
0. , 0. , 0. , 0. ]])
PaddlePaddle 的稀疏模块可以创建类似于常规 ResNet 的模型架构,但使用的是稀疏卷积层替换传统的密集卷积层。每个稀疏卷积层后通常跟随一个批归一化层和 ReLU 激活函数,形成一个基础的稀疏残差块。
五、Paddle3D应用实例解读:稀疏 ResNet
代码来源:Paddle3D的sparse_resnet.py
代码注释
这段代码定义了一个基于 PaddlePaddle 的稀疏3D残差网络(SparseResNet3D),主要用于处理3D点云数据,如自动驾驶系统中的激光雷达扫描数据。它通过稀疏卷积层对体素化(voxelized)的点云数据进行特征提取和处理。
“”“该符号内代码注释为新增”“”
导入所需库和模块
import numpy as np
import paddle
from paddle import sparse
from paddle.sparse import nn
from paddle3d.apis import manager
from paddle3d.models.layers import param_init
这些库包括numpy用于数学运算,paddle及其稀疏模块用于深度学习操作,以及paddle3d的API和模型层初始化。
定义卷积函数
def conv3x3(in_out_channels, out_out_channels, stride=1, indice_key=None, bias_attr=True):
"""3x3 convolution with padding, specifically for SubM sparse 3D convolution."""
return nn.SubmConv3D(
in_out_channels, out_out_channels, kernel_size=3, stride=stride, padding=1, bias_attr=bias_attr, key=indice_key)
def conv1x1(in_out_channels, out_out_channels, stride=1, indice_key=None, bias_attr=True):
"""1x1 convolution, also for SubM sparse 3D convolution."""
return nn.SubmConv3D(
in_out_channels, out_out_channels, kernel_size=1, stride=stride, padding=1, bias_attr=bias_attr, key=indice_key)
conv3x3 和 conv1x1 是用于创建3D稀疏卷积层的帮助函数,它们使用了PaddlePaddle的SubmConv3D,这是一种专门处理稀疏数据的3D卷积。
定义稀疏基础块类
class SparseBasicBlock(paddle.nn.Layer):
""" A basic building block for constructing sparse 3D ResNet with two convolutional layers."""
expansion = 1
def __init__(self, in_channels, out_channels, stride=1, downsample=None, indice_key=None):
super(SparseBasicBlock, self).__init__()
self.conv1 = conv3x3(in_channels, out_channels, stride, indice_key, True)
self.bn1 = nn.BatchNorm(out_channels, epsilon=1e-3, momentum=0.01)
self.relu = nn.ReLU()
self.conv2 = conv3x3(out_channels, out_channels, indice_key=indice_key, bias_attr=True)
self.bn2 = nn.BatchNorm(out_channels, epsilon=1e-3, momentum=0.01)
self.downsample = downsample
self.stride = stride
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
identity = self.downsample(x)
out = sparse.add(out, identity)
out = self.relu(out)
return out
SparseBasicBlock是SparseResNet3D的核心模块,包括两个稀疏卷积层、批归一化和ReLU激活函数,以及可选的下采样,用于残差连接。
定义SparseResNet3D网络
@manager.MIDDLE_ENCODERS.add_component
class SparseResNet3D(paddle.nn.Layer):
""" The main Sparse 3D ResNet class, designed for processing voxelized point cloud data."""
def __init__(self, in_channels, voxel_size, point_cloud_range):
super(SparseResNet3D, self).__init__()
# Initial conv layer
self.conv_input = paddle.nn.Sequential(
nn.SubmConv3D(in_channels, 16, 3, bias_attr=False, key='res0'),
nn.BatchNorm(16), nn.ReLU())
# Subsequent layers with increasing channel depth and decreasing spatial dimensions
self.conv1 = paddle.nn.Sequential(
SparseBasicBlock(16, 16, indice_key='res0'),
SparseBasicBlock(16, 16, indice_key='res0'),)
self.conv2 = paddle.nn.Sequential(
nn.Conv3D(16, 32, 3, 2, padding=1, bias_attr=False), # downsample
nn.BatchNorm(32), nn.ReLU(),
SparseBasicBlock(32, 32, indice_key='res1'),
SparseBasicBlock(32, 32, indice_key='res1'),)
self.conv3 = paddle.nn.Sequential(
nn.Conv3D(32, 64, 3, 2, padding=1, bias_attr=False), # downsample
nn.BatchNorm(64), nn.ReLU(),
SparseBasicBlock(64, 64, indice_key='res2'),
SparseBasicBlock(64, 64, indice_key='res2'),)
self.conv4 = paddle.nn.Sequential(
nn.Conv3D(64, 128, 3, 2, padding=[0, 1, 1], bias_attr=False), # downsample
nn.BatchNorm(128), nn.ReLU(),
SparseBasicBlock(128, 128, indice_key='res3'),
SparseBasicBlock(128, 128, indice_key='res3'),)
# Extra conv layer to further process features
self.extra_conv = paddle.nn.Sequential(
nn.Conv3D(128, 128, (3, 1, 1), (2, 1, 1), bias_attr=False), # Adjust the spatial dimensions
nn.BatchNorm(128), nn.ReLU(),)
# Calculate the grid size for the 3D data based on the provided voxel size and point cloud range
point_cloud_range = np.array(point_cloud_range, dtype=np.float32)
voxel_size = np.array(voxel_size, dtype=np.float32)
grid_size = (point_cloud_range[3:] - point_cloud_range[:3]) / voxel_size
grid_size = np.round(grid_size).astype(np.int64)
self.sparse_shape = np.array(grid_size[::-1]) + [1, 0, 0]
self.in_channels = in_channels
self.init_weight()
def init_weight(self):
""" Initialize weights for convolutional layers and batch normalization layers."""
for layer in self.sublayers():
if isinstance(layer, (nn.Conv3D, nn.SubmConv3D)):
param_init.reset_parameters(layer)
if isinstance(layer, nn.BatchNorm):
param_init.constant_init(layer.weight, value=1)
param_init.constant_init(layer.bias, value=0)
def forward(self, voxel_features, coors, batch_size):
""" The forward pass for processing input voxel features and coordinates."""
# Setup the sparse tensor with the specified shape and input features
shape = [batch_size] + list(self.sparse_shape) + [self.in_channels]
sp_x = sparse.sparse_coo_tensor(
coors.transpose((1, 0)),
voxel_features,
shape=shape,
stop_gradient=False)
# Pass the sparse tensor through the sequential layers
x = self.conv_input(sp_x)
x_conv1 = self.conv1(x)
x_conv2 = self.conv2(x_conv1)
x_conv3 = self.conv3(x_conv2)
x_conv4 = self.conv4(x_conv3)
# Final extra convolutional processing
out = self.extra_conv(x_conv4)
# Convert the output back to a dense tensor and adjust dimensions for further processing
out = out.to_dense()
out = paddle.transpose(out, perm=[0, 4, 1, 2, 3])
N, C, D, H, W = out.shape
out = paddle.reshape(out, shape=[N, C * D, H, W])
return out
此类中定义了一系列卷积层和残差块,用于逐步处理和提取输入点云数据的特征。网络通过逐层降采样来增加特征深度并减小空间维度,最终输出密集的特征张量,适合后续的处理或学习任务。
六、小结
PaddlePaddle 不仅支持自定义稀疏神经网络结构,也可以通过提供的API轻松地实现已有的经典结构,如ResNet、VGG等。对于这些经典网络,通过替换标准的卷积层为相应的稀疏卷积层,可以使其适应稀疏数据的处理,从而拓展其应用到新的领域,如3D点云处理。
总的来说,PaddlePaddle 在提供稀疏计算支持的同时,确保了开发体验的一致性和直观性,使得开发者可以无缝地在稀疏和稠密数据操作之间切换,同时保证高效的数据处理。
七、参考文献
- 官网paddle.sparse 目录
- 飞桨框架v2.3 API最新升级!对科学计算、概率分布和稀疏Tensor等提供更全面支持!
平台回复不及时,欢迎大家添加好友交流。