一、强化学习都有哪些分类?
1、基于模型与不基于模型
根据是否具有环境模型,强化学习算法分为两种:基于模型与不基于模型
基于模型的强化学习(Model-based RL):可以简单的使用动态规划求解,任务可定义为预测和控制,预测的目的是评估当前策略的好坏,即求解状态价值函数
V
π
(
S
)
V_π(S)
Vπ(S),控制的目的则是寻找最优策略
π
∗
π_∗
π∗和
V
∗
(
s
)
V_∗(s)
V∗(s)。
在这里“模型”的含义是对环境进行建模,具体而言,是否已知其P和R,即
p
(
s
′
∣
s
,
a
)
p(s′|s,a)
p(s′∣s,a)和
R
(
s
,
a
)
R(s,a)
R(s,a)的取值。
如果有对环境的建模,那么智能体便可以在执行动作前得知状态转移的情况即
p
(
s
′
∣
s
,
a
)
p(s′|s,a)
p(s′∣s,a)和奖励
R
(
s
,
a
)
R(s,a)
R(s,a),也就不需要实际执行动作收集这些数据;否则便需要进行采样,通过与环境的交互得到下一步的状态和奖励,然后仅依靠采样得到的数据更新策略。
无模型的强化学习(model-free):需要使用蒙特了卡洛法、时序差分法不断的探索环境。
2、基于价值、基于策略
在无模型的方法中,又有基于价值和基于策略的两种方法。
基于价值:智能体通过学习价值函数,隐式的策略,并贪婪的选择值最大的动作,即
a
=
a
r
g
m
a
x
Q
(
s
,
a
)
a=arg maxQ(s,a)
a=argmaxQ(s,a),主要包络Q-learning和SARSA,这种方法一般得到的是确定性策略。
其有如下几点缺点:
1)对连续动作的处理能力不足;
2)对受限状态下的问题处理能力不足;
3)无法解决随机策略问题。包括Q-Learning、SARSA。
基于策略:没有价值函数,直接学习策略。其对策略进行进行建模 π ( s , a ) π(s,a) π(s,a)并优化,一般得到的是随机性策略。适用于随机策略、连续动作。主要包括Policy Gradient算法、TRPO、PPO。
对于以上两个分类的方法可以参照下图。

3、on/off-policy
On-policy:学习的 agent 跟和环境互动的 agent 是同一个。行为策略与目标策略相同。也就是说,行动遵循的行动策略与被评估的目标策略是同一个策略(如果要学习的智能体和与环境交互的智能体是相同的),则称之为同策略,比如Sarsa。其好处就是简单粗暴,直接利用数据就可以优化其策略,但这样的处理会导致策略其实是在学习一个局部最优,因为On-policy的策略没办法很好的同时保持即探索又利用。
Off-policy: 学习的 agent 跟和环境互动的 agent 不是同一个。将收集数据当做一个单独的任务。Off-policy将目标策略和行为策略分开,可以在保持探索的同时,更能求到全局最优值。行动遵循的行动策略和被评估的目标策略是不同的策略(或如果要学习的智能体和与环境交互的智能体不是相同的),则称之为异策略,比如Q-learning。但其难点在于:如何在一个策略下产生的数据来优化另外一个策略。
综上,强化学习的分类可以比喻为如下图:

二、基于价值强化学习方法简介
1、Q-Learning
先上图:

在上述流程图中所说的Q表即为下表:
假设我们在玩一个小游戏,该游戏有上下左右不同的动作,同时也会有不同的状态,比如游戏结束等。Q表也可以称为状态-价值函数
Q
(
s
,
a
)
Q(s,a)
Q(s,a):这个表格的每一行代表每个 state上述例子中的游戏结束等,每一列代表每个 action上述例子中的上下左右,表格的数值就是在各个 state 下采取各个 action 时能够获得的最大的未来期望奖励。

通过上述的Q table 就可以找到每个状态下的最优行为,进而通过找到所有最优的action得到最大的期望奖励。
Q表更新公式如下:
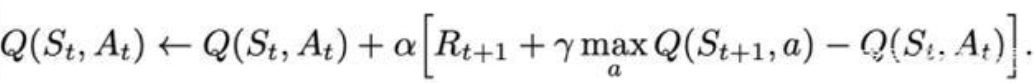
Q-learning在更新Q值时下一步动作是不确定的,它会选取Q值最大的动作来作为下一步的更新。
2、SARSA
SARSA(State-Action-Reward-State-Action)是一个学习马尔可夫决策过程策略的算法。至于马尔可夫决策过程策略是什么可以见上一篇文章。
它的算法和公式和 Q learning 很像,但是 Q-Learning 是Off-Policy的,SARSA 是On-Policy 的。
SARSA的Q表更新公式如下:

从上式中可以看出,Sarsa使用下一步的实际动作来作为更新,而在Q-learning算法中,使用确定性策略选出的新动作只用于动作价值函数,而不会被真正执行,当动作价值函数更新后,得到新状态,并基于新状态由ε贪心策略选择得到执行行动,这意味着行动策略与目标策略不属于同一个策略。
上述两种方法最先提出的时候是没有引入时序差分方法的,而是在计算奖励的过程中一条路走到头,直到状态变为结束为止。而这种方式的计算是会消耗大量的时间。因此有了将时序差分方法与Sarsa/Q-learning或者其他算法结合的新方法。
3、TD(0)控制/Sarsa(0)算法与TD(n)控制/n步Sarsa算法

TD每过一个时序p就利用奖励
R
t
+
1
R_{t+1}
Rt+1和值函数
V
(
S
t
+
1
)
V(S_{t+1})
V(St+1)
更新一次,当然,这里所说的one-step TD 方法,也可以两步一更新,三步一更新”,这个所谓的多步一更新我们便称之为N步时序差分法。如上图。
回报公式的定义,即为(根据前几项可以看出:γ的上标加t+1即为R的下标,反过来,当最后一项R的下标T确定后,自然便可以得出γ的上标为T−t−1)。因此有如下式:

从而有:
单步回报:
G
t
:
t
+
1
=
R
t
+
1
+
γ
V
t
(
S
t
+
1
)
G_{t:t+1}=R_{t+1}+γV_t(S_{t+1})
Gt:t+1=Rt+1+γVt(St+1),即为TD(0)控制/Sarsa(0)算法
两步回报:
G
t
:
t
+
2
=
R
t
+
1
+
γ
R
t
+
2
+
γ
2
V
t
+
1
(
S
t
+
2
)
G_{t:t+2}=R_{t+1}+γR_{t+2}+γ^2V_{t+1}(S_{t+2})
Gt:t+2=Rt+1+γRt+2+γ2Vt+1(St+2)
n步回报:
G
t
:
t
+
n
=
R
t
+
1
+
γ
R
t
+
2
+
⋯
+
γ
n
−
1
R
t
+
n
+
γ
n
V
t
+
n
−
1
(
S
t
+
n
)
G_{t:t+n}=R_{t+1}+γR_{t+2}+⋯+γ^{n−1}R_{t+n}+γ^nV_{t+n−1}(S_{t+n})
Gt:t+n=Rt+1+γRt+2+⋯+γn−1Rt+n+γnVt+n−1(St+n)
类似的,当用n步时序差分的思路去更新Q函数则就是所谓的n步Sarsa算法,当我们重新根据动作价值的估计定义如下的b步方法的回报为:

如此,便可以得到如下Q的更新方式:

4、Sarsa算法与Q-learning更新规则的对比