目录
- 一、如遇合并表格,注意结构化
- 二、确认主键,合并所有文件数据
- 三、sheet2同理
- 四、案例总结
如果遇到这样情形,多文件夹多文件,多工作表的分汇场景;可以参考以下方法解决。



一、如遇合并表格,注意结构化
首先在汇总以前,保证第一列表,合并列结构化为基本单元格。
(一)定义函数,遍历文件
定义函数ycl1(),先遍历B文件夹下C文件夹路径即“1月数据”“2月数据”“3月数据”
def ycl1(): #结构化数据sheet1
# 设置文件夹路径
folder_pathss = r"C:\Users\Desktop\A\B" ## 第一处要改!!!!!!!!!
folder_paths = [os.path.join(folder_pathss, file) for file in os.listdir(folder_pathss)] # os.listdir(folder_pathss)遍历folder_pathss下所有文件
(二)结构化工作表sheet1
再遍历filename的工作表1
filname是以“1月数据”为例下所有.xlsx文件
file_path是filename的路径
结构化遍历所有文件后,注意自定义一个空文件夹(例如“test”)保存
for folder_path in folder_paths: //遍历例如“1月数据”“2月数据”“3月数据”文件夹
# 创建一个新的工作簿用于合并数据
merged_workbook = Workbook() # Create a new workbook
# 遍历文件夹中的所有文件
for filename in os.listdir(folder_path):
if filename.endswith(".xlsx"): # 只处理Excel文件!!!!!!!
file_path = os.path.join(folder_path, filename)
# 1.加载数据
work_book = load_workbook(filename=file_path, data_only=True) # 控制带有公式的单元格是否具有公式(默认值)
sheet = work_book["Sheet1"] # 假设所有文件的工作表名称相同
## 第二处要改!!!!!!可以根据自己表格名字修改 定义Sheet_name = filename[:-5] sheet = work_book[Sheet_name]
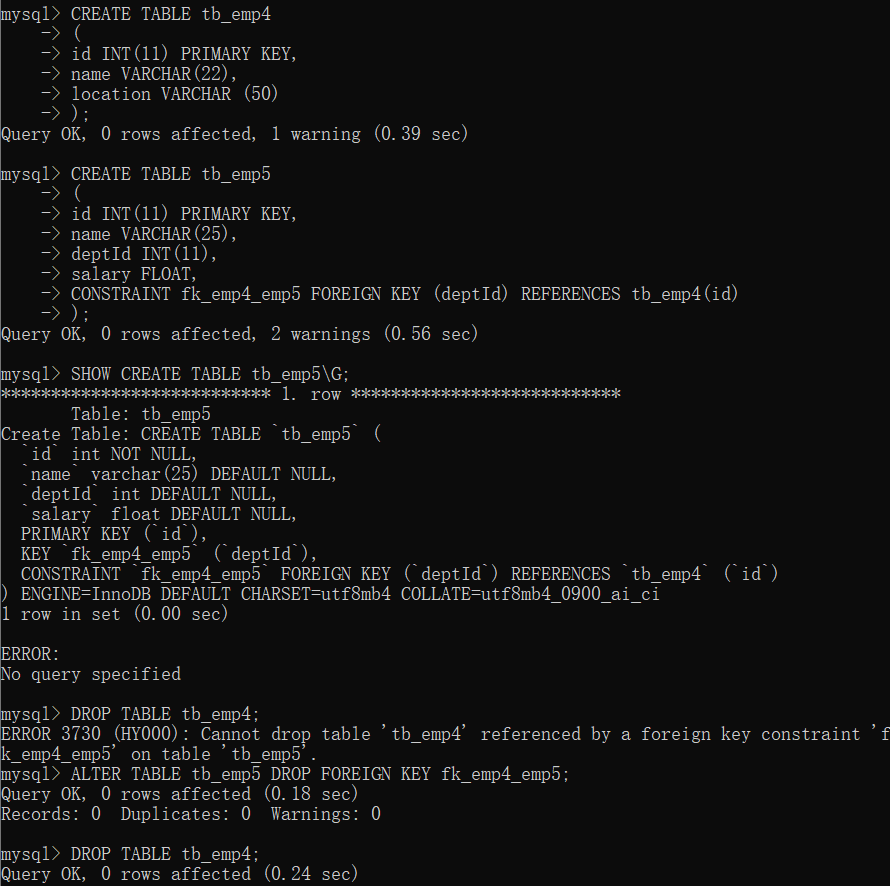
# 2. 找出所有的合并单元格的索引信息
mc_range_list = [str(item) for item in sheet.merged_cells.ranges]
# 3. 批量取消合并单元格,填充数据
for mc_range in mc_range_list:
# 取得左上角值的坐标
top_left, bot_right = mc_range.split(":") # ["A1", "A12"]
top_left_col, top_left_row = sheet[top_left].column, sheet[top_left].row # (1, 1,)
bot_right_col, bot_right_row = sheet[bot_right].column, sheet[bot_right].row # (1, 12,)
# 记下该合并单元格的值
cell_value = sheet[top_left].value
# 取消合并单元格
sheet.unmerge_cells(mc_range)
# 批量给子单元格赋值
# 遍历列
for col_idx in range(top_left_col, bot_right_col + 1):
# 遍历行
for row_idx in range(top_left_row + 1, bot_right_row + 1):
sheet[f"{chr(col_idx + 64)}{row_idx}"] = cell_value
# 4. 删除前三行和最后一行 根据表格情况修剪行!!!!!
sheet.delete_rows(1, 2)
sheet.delete_rows(sheet.max_row)
# 保存更改
file_paths = file_path[:22] + '\\test\\' + filename ## 第三处要改 自定义保存路径!!!!!!!
print(file_paths)
work_book.save(file_paths)
#将数据合并到新的工作簿中
for row in sheet.iter_rows(values_only=True):
merged_workbook.active.append(row)
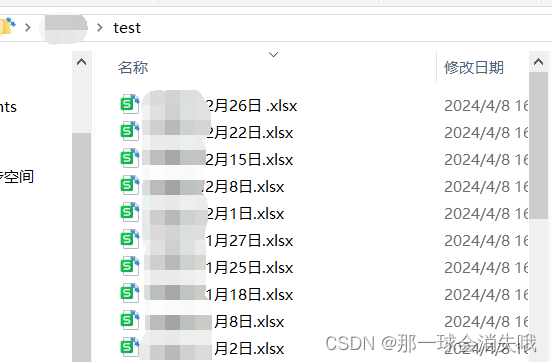
我这保存在"~/A/test"路径下
二、确认主键,合并所有文件数据
新起一列“时间”作为主键区分,这里的时间直接应用文件名
定义函数merge_excel(folder_paths,output_file),合并test路径下所有文件
这里 folder_paths = "/A/test" 由main()定义
def merge_excel(folder_paths, output_file): #合并数据
# 创建一个空的 DataFrame 用于存储合并后的数据
merged_data = pd.DataFrame()
# 遍历每个Excel
for excel_files in os.listdir(folder_paths):
# # 遍历每个 Excel 文件并处理
file_path = os.path.join(folder_paths, excel_files)
# 打开 Excel 文件
df = pd.read_excel(file_path,sheet_name='Sheet1')
# 添加文件名作为新列
file_name = os.path.splitext(excel_files)[0]
df.insert(0,'时间',file_name)
# 将数据添加到 merged_data 中
merged_data = pd.concat([merged_data, df], ignore_index=True)
merged_data.to_excel(output_file,index=False)
三、sheet2同理
(一)结构化
定义函数ycl2(), 注意修改工作表名,根据表情况修剪非结构化行。
def ycl2(): #结构化sheet2
# 设置文件夹路径
folder_pathss = r"C:\Users\Desktop\A\B"
folder_paths = [os.path.join(folder_pathss, file) for file in os.listdir(folder_pathss)]
for folder_path in folder_paths:
# 创建一个新的工作簿用于合并数据
merged_workbook = Workbook() # Create a new workbook
# 遍历文件夹中的所有文件
for filename in os.listdir(folder_path):
if filename.endswith(".xlsx"): # 只处理Excel文件
file_path = os.path.join(folder_path, filename)
# 1.加载数据
work_book = load_workbook(filename=file_path, data_only=True)
sheet = work_book["Sheet2"] # 假设所有文件的工作表名称相同
# 2. 找出所有的合并单元格的索引信息
mc_range_list = [str(item) for item in sheet.merged_cells.ranges]
# 3. 批量取消合并单元格,填充数据
for mc_range in mc_range_list:
# 取得左上角值的坐标
top_left, bot_right = mc_range.split(":") # ["A1", "A12"]
top_left_col, top_left_row = sheet[top_left].column, sheet[top_left].row # (1, 1,)
bot_right_col, bot_right_row = sheet[bot_right].column, sheet[bot_right].row # (1, 12,)
# 记下该合并单元格的值
cell_value = sheet[top_left].value
# 取消合并单元格
sheet.unmerge_cells(mc_range)
# 批量给子单元格赋值
# 遍历列
for col_idx in range(top_left_col, bot_right_col + 1):
# 遍历行
for row_idx in range(top_left_row + 1, bot_right_row + 1):
sheet[f"{chr(col_idx + 64)}{row_idx}"] = cell_value
# 4. 删除前三行和最后一行
sheet.delete_rows(1, 3)
# 保存更改
file_paths = file_path[:22] + '\\test\\' + filename
work_book.save(file_paths)
# 将数据合并到新的工作簿中
for row in sheet.iter_rows(values_only=True):
merged_workbook.active.append(row)
(二)汇总
修正sheet_name = Sheet2,合并数据
def merge_excel(folder_paths, output_file): #合并数据
# 创建一个空的 DataFrame 用于存储合并后的数据
merged_data = pd.DataFrame()
# 遍历每个Excel
for excel_files in os.listdir(folder_paths):
# # 遍历每个 Excel 文件并处理
file_path = os.path.join(folder_paths, excel_files)
# 打开 Excel 文件
df = pd.read_excel(file_path,sheet_name='Sheet2')
# 添加文件名作为新列
file_name = os.path.splitext(excel_files)[0]
df.insert(0,'时间',file_name)
# 将数据添加到 merged_data 中
merged_data = pd.concat([merged_data, df], ignore_index=True)
merged_data.to_excel(output_file,index=False)
四、案例总结
总体,分为两步骤,一是结构化遍历保存,二是汇总。整理的代码放在末尾了!!!
import pandas as pd
import os
from openpyxl import load_workbook, Workbook
import openpyxl
# def change(): #xls转化为xlsx
def ycl1(): #结构化数据sheet1
# 设置文件夹路径
folder_pathss = r"C:\Users\Desktop\A\B"
folder_paths = [os.path.join(folder_pathss, file) for file in os.listdir(folder_pathss)]
for folder_path in folder_paths:
# 创建一个新的工作簿用于合并数据
merged_workbook = Workbook() # Create a new workbook
# 遍历文件夹中的所有文件
for filename in os.listdir(folder_path):
if filename.endswith(".xlsx"): # 只处理Excel文件
file_path = os.path.join(folder_path, filename)
# 1.加载数据
work_book = load_workbook(filename=file_path, data_only=True) #控制带有公式的单元格是否具有公式(默认值)
sheet = work_book["Sheet1"] # 假设所有文件的工作表名称相同
# 2. 找出所有的合并单元格的索引信息
mc_range_list = [str(item) for item in sheet.merged_cells.ranges]
# 3. 批量取消合并单元格,填充数据
for mc_range in mc_range_list:
# 取得左上角值的坐标
top_left, bot_right = mc_range.split(":") # ["A1", "A12"]
top_left_col, top_left_row = sheet[top_left].column, sheet[top_left].row # (1, 1,)
bot_right_col, bot_right_row = sheet[bot_right].column, sheet[bot_right].row # (1, 12,)
# 记下该合并单元格的值
cell_value = sheet[top_left].value
# 取消合并单元格
sheet.unmerge_cells(mc_range)
# 批量给子单元格赋值
# 遍历列
for col_idx in range(top_left_col, bot_right_col + 1):
# 遍历行
for row_idx in range(top_left_row + 1, bot_right_row + 1):
sheet[f"{chr(col_idx + 64)}{row_idx}"] = cell_value
# 4. 删除前三行和最后一行
sheet.delete_rows(1, 2)
sheet.delete_rows(sheet.max_row)
# 保存更改
file_paths = file_path[:22] + '\\test\\' + filename
print(file_paths)
work_book.save(file_paths)
#将数据合并到新的工作簿中
for row in sheet.iter_rows(values_only=True):
merged_workbook.active.append(row)
def ycl2(): #结构化sheet2
# 设置文件夹路径
folder_pathss = r"C:\Users\Desktop\A\B"
folder_paths = [os.path.join(folder_pathss, file) for file in os.listdir(folder_pathss)]
for folder_path in folder_paths:
# 创建一个新的工作簿用于合并数据
merged_workbook = Workbook() # Create a new workbook
# 遍历文件夹中的所有文件
for filename in os.listdir(folder_path):
if filename.endswith(".xlsx"): # 只处理Excel文件
file_path = os.path.join(folder_path, filename)
# 1.加载数据
work_book = load_workbook(filename=file_path, data_only=True)
sheet = work_book["Sheet2"] # 假设所有文件的工作表名称相同
# 2. 找出所有的合并单元格的索引信息
mc_range_list = [str(item) for item in sheet.merged_cells.ranges]
# 3. 批量取消合并单元格,填充数据
for mc_range in mc_range_list:
# 取得左上角值的坐标
top_left, bot_right = mc_range.split(":") # ["A1", "A12"]
top_left_col, top_left_row = sheet[top_left].column, sheet[top_left].row # (1, 1,)
bot_right_col, bot_right_row = sheet[bot_right].column, sheet[bot_right].row # (1, 12,)
# 记下该合并单元格的值
cell_value = sheet[top_left].value
# 取消合并单元格
sheet.unmerge_cells(mc_range)
# 批量给子单元格赋值
# 遍历列
for col_idx in range(top_left_col, bot_right_col + 1):
# 遍历行
for row_idx in range(top_left_row + 1, bot_right_row + 1):
sheet[f"{chr(col_idx + 64)}{row_idx}"] = cell_value
# 4. 删除前三行和最后一行
sheet.delete_rows(1, 3)
# 保存更改
file_paths = file_path[:22] + '\\test\\' + filename
work_book.save(file_paths)
# 将数据合并到新的工作簿中
for row in sheet.iter_rows(values_only=True):
merged_workbook.active.append(row)
def merge_excel(folder_paths, output_file): #合并数据
# 创建一个空的 DataFrame 用于存储合并后的数据
merged_data = pd.DataFrame()
# 遍历每个Excel
for excel_files in os.listdir(folder_paths):
# # 遍历每个 Excel 文件并处理
file_path = os.path.join(folder_paths, excel_files)
# 打开 Excel 文件
df = pd.read_excel(file_path,sheet_name='Sheet1')
# 添加文件名作为新列
file_name = os.path.splitext(excel_files)[0]
df.insert(0,'时间',file_name)
# 将数据添加到 merged_data 中
merged_data = pd.concat([merged_data, df], ignore_index=True)
merged_data.to_excel(output_file,index=False)
def merge_excel_sheets(folder_paths, output_file): #合并数据
# 创建一个空的 DataFrame 用于存储合并后的数据
merged_data = pd.DataFrame()
# 遍历每个Excel
for excel_files in os.listdir(folder_paths):
# # 遍历每个 Excel 文件并处理
file_path = os.path.join(folder_paths, excel_files)
df = pd.read_excel(file_path,sheet_name='Sheet2')
# 添加文件名作为新列
file_name = os.path.splitext(excel_files)[0]
df.insert(0,'时间',file_name)
# 将数据添加到 merged_data 中
merged_data = pd.concat([merged_data, df], ignore_index=True)
merged_data.to_excel(output_file,index=False)
def main1():
# 输入多个文件夹的路径和输出文件的路径
# folder_pathss = [r"C:\Users\Desktop\A\B\1月数据", r"C:\Users\Desktop\A\B\2月数据"] # 修改为实际的文件夹路径
ycl1()
folder_paths = r"C:\Users\Desktop\A\test"
output_file = r"C:\Users\Desktop\A\XXX1.xlsx" # 输出文件路径
# 调用函数进行合并
merge_excel(folder_paths, output_file)
def main2():
ycl2()
folder_paths = r"C:\Users\Desktop\A\test"
output_file = r"C:\Users\Desktop\A\XXX2.xlsx" # 输出文件路径
# 调用函数进行合并
merge_excel_sheets(folder_paths, output_file)
if __name__ == '__main__':
main1()
if __name__ == '__main__':
main2()