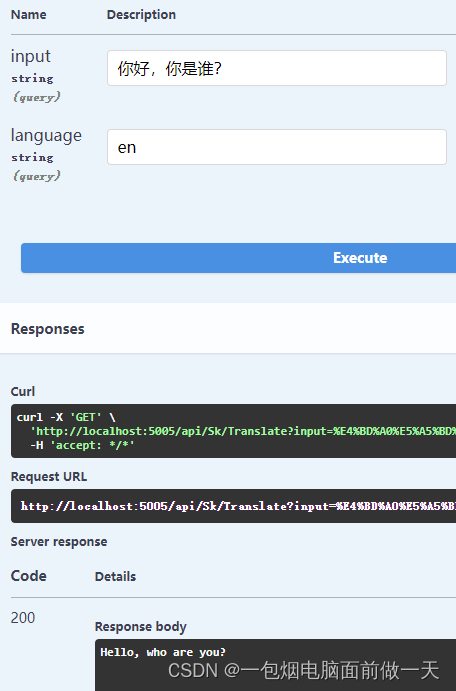
写在前面
本文为王树森老师《小红书推荐系统公开课》的课程笔记
- 课程来源:ShusenWang的个人空间-ShusenWang个人主页-哔哩哔哩视频 (bilibili.com)
- 课程资料:GitHub - wangshusen/RecommenderSystem
由于篇幅较长,分为【上】【下】两篇文章来记录。其中【上】包括推荐系统基础、召回、排序,【下】包括特征交叉、行为序列、重排、物品冷启动、涨指标的方法
【上】部分,内容导航如下:



(一)推荐系统基础
1、推荐系统的基础概念
打开小红书APP,默认打开 “发现” 页面,展示推荐系统分发给你的内容,即用户自己创作的笔记,将它们展示给其他用户,形成陌生人社交的社区
小红书推荐系统的转化流程
推荐系统决定给用户曝光什么内容,用户自己决定是否点击、滑动到底、...

抖音没有曝光和点击,用户下滑一次只能看到一个视频
短期消费指标
反映出用户对推荐是否满意
- 点击率 = 点击次数 / 曝光次数
- 越高说明推荐越精准
- 不能作为唯一优化目标(标题党)
- 点赞率 = 点赞次数 / 点击次数
- 收藏率、转发率同理
- 阅读完成率 = 滑动到底次数 / 点击次数 * 归一化函数(跟笔记长度有关)
- 笔记越长,完成阅读的比例就越低
- 若没有归一化函数,对长笔记会不公平
短期消费指标容易竭泽而渔,用户很快会失去兴趣,不再活跃。故还需关注多样性(用户没看过的话题),有助于提高用户黏性,留住用户,让用户更活跃
北极星指标
衡量推荐系统好坏最重要的指标,根本标准
- 用户规模:日活用户数DAU(只要今天登录了一次小红书就增加了一次DAU)、月活用户数MAU(只要这个月登录了一次小红书就增加了一次MAU)
- 消费:人均使用推荐的时长、人均阅读笔记的数量
- 通常与点击率涨跌一致。若矛盾,应以北极星指标为准,如增加多样性,点击率不一定涨,但时长可能变多
- 发布:发布渗透率、人均发布量
- 激励作者发布通常是由冷启动来负责
实验流程
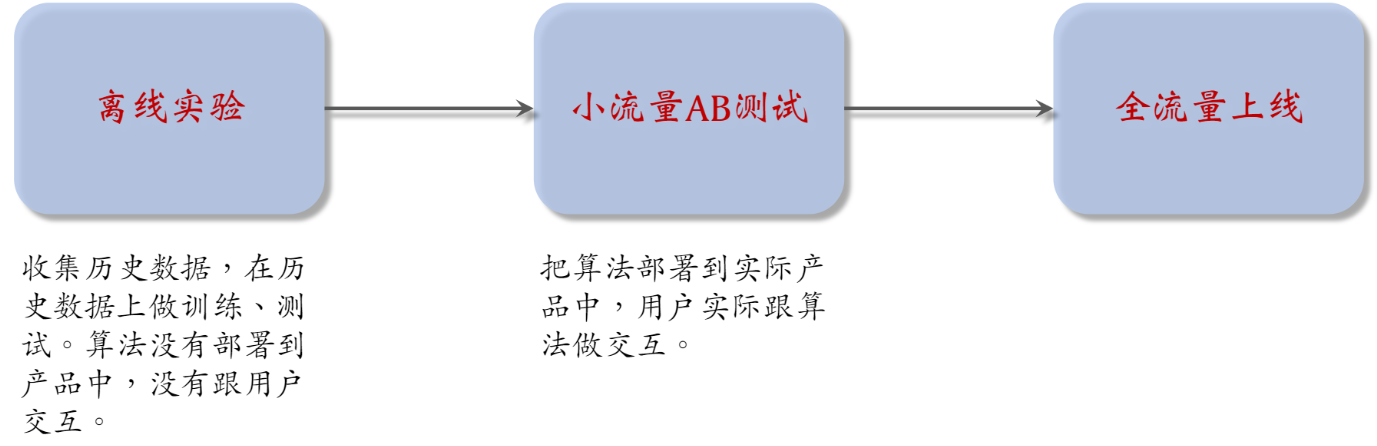
- 做离线实验不需要把算法部署到产品中,没有跟用户实际交互,没有占用线上流量
- 离线实验结果没有线上实验结果可靠(北极星指标都是线上指标,只能通过线上实验获得)
- AB测试:把用户随机分成实验组和对照组,实验组用新策略,对照组用旧策略,对比两者的业务指标,判断新策略是否会显著优于旧策略。若是,可以加大流量,最终推全
2、推荐系统的链路
推荐系统的目标是从物品的数据库中选出几十个物品展示给用户

召回(几亿->几千)
从物品的数据库中快速取回一些物品
几十条召回通道,每条召回通道取回几十~几百个物品,一共取回几千个物品作为候选集
- 召回通道:协同过滤、双塔模型、关注的作者等
- 融合、去重、过滤(排除掉用户不喜欢的作者、笔记、话题等)

让排序决定该把哪些物品曝光给用户,以及展示的顺序。为了解决计算量的问题,将排序分为粗排和精排(二者非常相似,但精排模型更大,用的特征更多)
粗排(几千->几百)
用规模较小的机器学习模型给几千个物品逐一打分,按照分数做排序和截断,保留分数最高的几百个物品送入精排(也会用一些规则,保证进入精排的笔记具有多样性)
- 排序分为粗排和精排,平衡计算量和准确性
- 召回和粗排是最大的漏斗
精排(几百->几百)
用大规模深度神经网络给几百个物品逐一打分,做排序和截断(截断可选)
- 精排相比粗排用的特征更多,计算量更大,模型打分更可靠
- 把多个预估值做融合(比如加权和)得到最终的分数,分数决定会不会展示给用户,以及展示的位置
重排(几百->几十)
根据精排分数和多样性分数做随机抽样,得到几十个物品。用规则把相似内容打散,并插入广告和运营推广内容,根据生态要求调整排序,即为最终展示给用户的结果
- 重排主要是做多样性抽样(如MMR、DPP)、规则打散、插入广告和运营内容
- 做多样性抽样(比如MMR、DPP),从几百个物品中选出几十个
- 用规则打散相似物品
- 插入广告、运营推广内容,根据生态要求调整排序
整条链路上,召回和粗排是最大的漏斗(候选物品从几亿->几千->几百)
3、AB测试
目的:
- 离线实验的指标有提升,不代表线上实验也会有收益。判断新策略能带来多大的业务指标收益
- 模型中有一些参数,需要用AB测试选取最优参数,如GNN网络的深度可以是1/2/3层
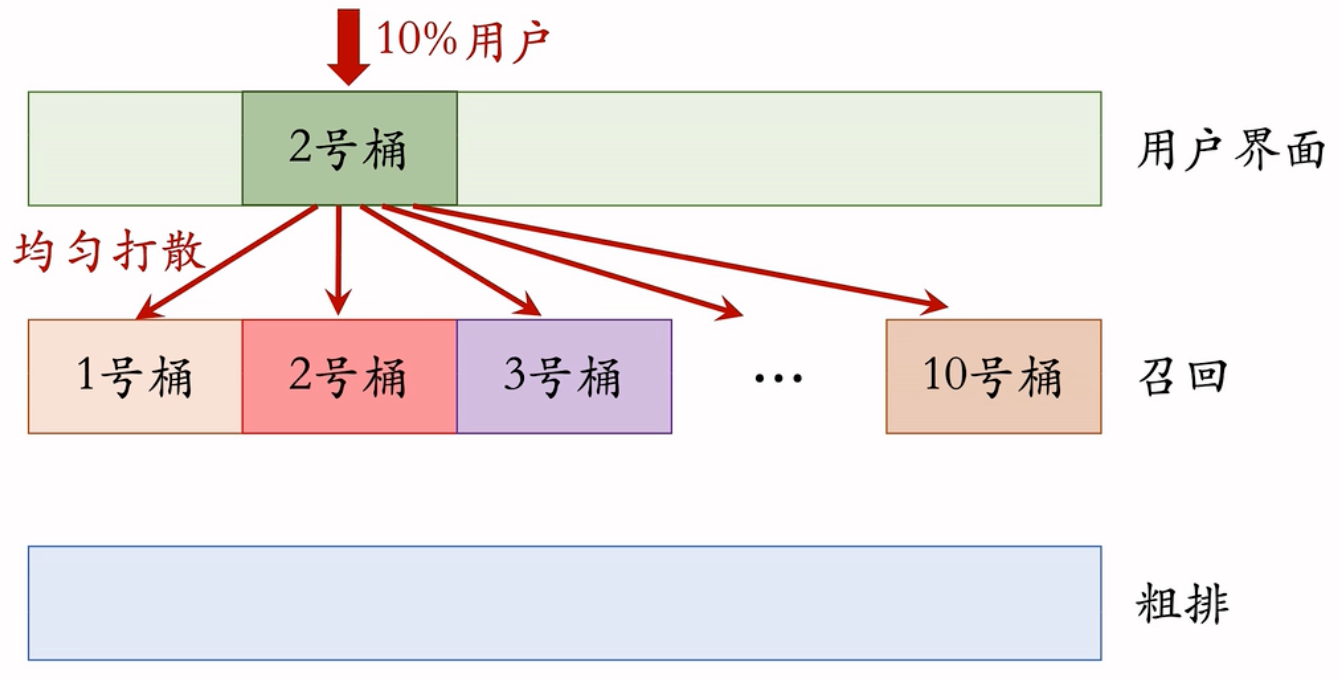
离线实验结果正向,下一步是做线上的小流量AB测试(一般10%用户)
随机分桶

若用户数量足够大,每个桶的DAU/留存/点击率等指标都是相等的
例:召回团队实现了一种GNN召回通道,离线实验结果正向。下一步是做线上的小流量A/B测试,考虑新的召回通道对线上指标的影响。模型中有一些参数,比如GNN的深度取值∈{1, 2, 3},需要用A/B测试选取最优参数

- 1~3桶的GNN深度分别为1~3层,4号桶没有用GNN做召回
- 计算每个桶的业务指标,比如DAU、人均使用推荐的时长、点击率等
- 如果某个实验组指标显著优于对照组,则说明对应的策略有效,如2桶的业务指标与对照组的diff有显著性,说明2层的GNN召回通道是有效果的,值得推全(把流量扩大到100%,给所有用户都使用2层GNN召回通道)
分层实验
目标:解决流量不够用的问题
- 信息流产品的公司有很多部门和团队,都需要做AB测试
- 推荐系统(召回、粗排、精排、重排)
- 用户界面
- 广告
- 如果把用户随机分成10组,1组做对照,9组做实验,那么只能同时做9组实验,无法满足产品迭代需求
分层实验:召回、粗排、精排、重排、用户界面、广告...(例如GNN召回通道属于召回层)
- 同层互斥:GNN实验占了召回层的4个桶,其他召回实验只能用剩余的6个桶
- 两个召回实验不会同时作用到同一个用户上
- 避免一个用户同时被两个召回实验影响,若两个实验相互干扰,实验结果将变得不可控
- 不同层正交:每一层独立随机对用户做分桶,每一层都可以独立用100%的用户做实验
- 一个用户可以同时受一个召回实验和一个精排实验的影响,因为它们的效果不容易相互增强或抵消

互斥 vs 正交:
- 如果所有实验都正交,则可以同时做无数组实验
- 同类的策略(例如精排模型的两种结构)天然互斥,对于一个用户,只能用其中一种
- 同类的策略(例如添加两条召回通道)效果会相互增强或相互抵消。互斥可以避免同类策略相互干扰
- 不同类型的策略(例如添加召回通道、优化粗排模型)通常不会相互干扰,可以作为正交的两层
Holdout机制
- 每个实验(召回、粗排、精排、重排)独立汇报对业务指标的提升
- 公司考察一个部门(比如推荐系统)在一段时间内对业务指标总体的提升
- 取10%的用户作为holdout桶(对照组),推荐系统使用剩余90%的用户做实验,两者互斥
- 10% holdout桶 vs 90% 实验桶的diff(需要对指标做归一化)为整个部门的业务指标收益

- 每个考核周期结束之后,清除holdout桶,让推全实验从90%用户扩大到100%用户
- 重新随机划分用户,得到holdout桶和实验桶,开始下一轮考核周期
- 新的holdout桶与实验桶各种业务指标的diff接近0
- 随着召回、粗排、精排、重排实验上线和推全,diff会逐渐扩大
实验推全
若业务指标的diff显著正向,则可以推全实验。如重排策略实验,取一个桶作为实验组,一个桶作为对照组,实验影响了20%用户,若观测到显著正向的业务收益,则可以推全

- 把重排层实验关掉,把两个桶空出来给其他实验
- 推全时新开一层,新策略会影响全部90%用户
- 在小流量阶段,新策略会影响10%用户,会微弱提升实验桶和hold桶的diff
- 推全后,新策略作用到90%用户上,diff会扩大9倍
- 如ab测试发现新策略会提升点击率9个万分点,小流量实验只作用10%用户上,所以只能把跟holdout桶的diff提升1个万分点,推全后,理论上可以把diff提升到9个万分点,跟ab实验得到的结果一致

反转实验
- 有的指标(如点击、交互)立刻受到新策略影响,有的指标(留存)有滞后性,需要长期观测
- 实验观测到显著收益后需要尽快推全新策略。目的是腾出桶供其他实验开展,或需要基于新策略做后续的开发
- 用反转实验解决上述矛盾,既可以尽快推全,也可以长期观测实验指标
- 在推全的新层中开一个旧策略的桶,可以把反转桶保留很久,长期观测实验指标
- 一个考核周期结束之后,会清除holdout桶,会把推全新策略用到holdout用户上,不影响反转桶;当反转实验完成时,新策略会用到反转桶用户上,实验真正推全,对所有用户生效

- 分层实验:同层互斥(不允许两个实验同时影响同一位用户)、不同层正交(实验有重叠的用户)
- Holdout:保留10%的用户完全不受实验影响,可以考虑整个部门对业务指标的贡献
- 实验推全:扩大到90%流量上,新建一个推全层,与其它层正交
- 反转实验:为了在尽早推全新策略的同时还能长期观测各种指标,在新的推全层上,保留一个小的反转桶,反转桶使用旧策略。反转桶可以保留很久,长期观测新旧策略的diff
(二)召回
1、基于物品的协同过滤(ItemCF)
ItemCF的原理
我喜欢看《笑傲江湖》,《笑傲江湖》与《鹿鼎记》相似,我没看过《鹿鼎记》——> 给我推荐《鹿鼎记》
推荐系统如何知道《笑傲江湖》与《鹿鼎记》相似?
- 基于知识图谱:
- 两本书的作者相同,故两本书相似
- 基于全体用户的行为:
- 看过《笑傲江湖》的用户也看过《鹿鼎记》
- 给《笑傲江湖》好评的用户也给《鹿鼎记》好评
ItemCF的实现
假设点击、点赞、收藏、转发四种行为各1分

逐一计算用户对候选物品的兴趣分数,返回分数高的topn个物品
物品相似度
两个物品的受众重合度越高,两个物品越相似
- 例如,喜欢《射雕英雄传》和《神雕侠侣》的读者重合度很高,可以认为它们相似

上述公式只要是喜欢就看作1,不喜欢就看作0,没有考虑用户喜欢的程度
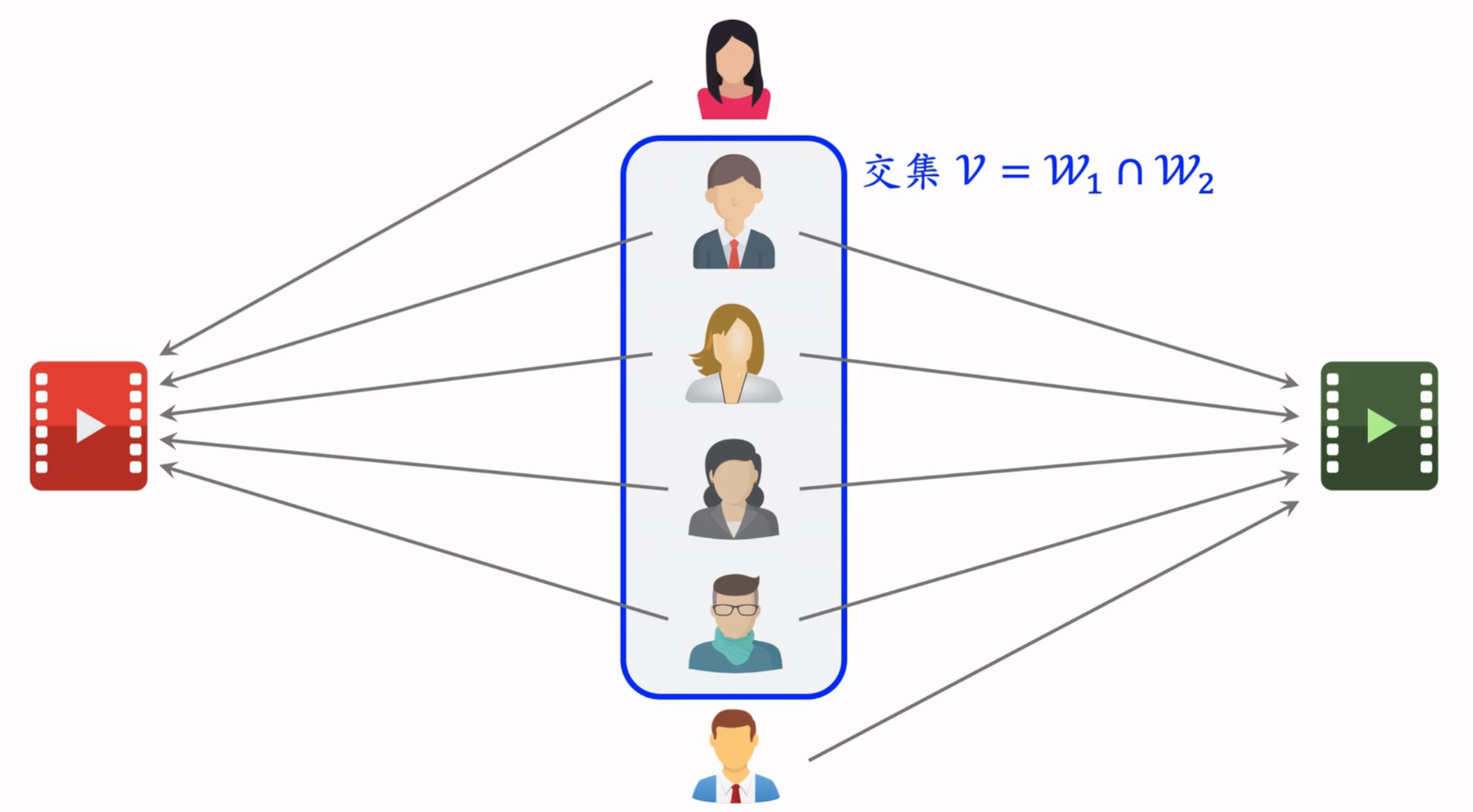
考虑用户喜欢的程度,如点击、点赞、收藏、转发各自算1分,用户对物品的喜欢程度最多是4分
- 分子表示同时喜欢两个物品的用户v(如果兴趣分数的取值是0或1,那么分子就是同时喜欢两个物品的人数)
- 分母第一项表示用户对物品i1的兴趣分数,关于所有用户求连加,然后开根号
- 把一个物品表示成一个向量,向量每个元素表示一个用户,元素的值就是用户对物品的兴趣分数,两个向量的夹角的余弦就是这个公式

ItemCF的基本思想:根据物品的相似度做推荐
- 如果用户喜欢物品Item1,而且物品Item1和Item2相似
- 那么用户很可能喜欢物品Item2
预估用户对候选物品的兴趣:
计算两个物品的相似度:
- 把每个物品表示为一个稀疏向量,向量每个元素对应一个用户
- 相似度sim就是两个向量夹角的余弦
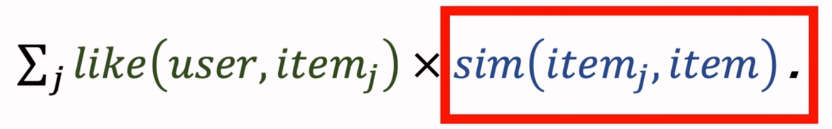
ItemCF召回的完整流程
为了能在线上实时推荐,必须要事先做离线计算,建立两个索引
事先做离线计算
建立 “用户->物品” 的索引:
- 记录每个用户最近点击、交互过的物品ID
- 给定任意用户ID,可以找到他近期感兴趣的物品列表

建立 “物品->物品” 的索引:
- 计算物品之间两两相似度
- 对于每个物品,索引它最相似的k个物品
- 给定任意物品ID,可以快速找到它最相似的k个物品

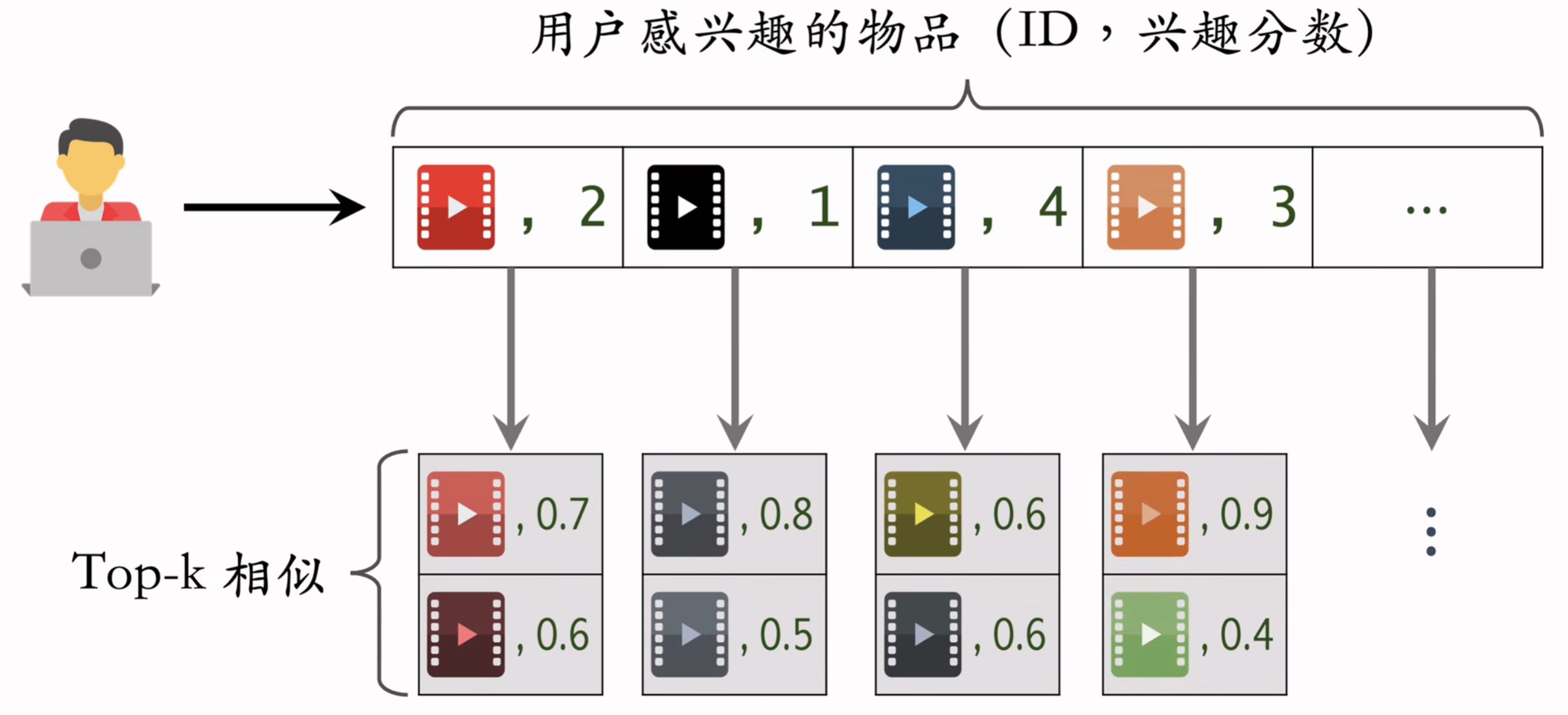
线上做召回
- 给定用户ID,通过 “用户->物品” 的索引,找到用户近期感兴趣的物品列表(last-n)
- 对于last-n列表中每个物品,通过“物品->物品” 的索引,找到top-k相似物品
- 对于取回的相似物品(最多有nk个),用公式预估用户对物品的兴趣分数
- 返回分数最高的100个物品,作为推荐结果(即ItemCF召回通道的输出,会跟其他召回通道的输出融合起来并排序,最终展示给用户)
索引的意义在于避免枚举所有的物品
- 记录用户最近感兴趣的n=200个物品
- 取回每个物品最相似的k=10个物品
- 给取回的nk=2000个物品打分(用户对物品的兴趣)
- 返回分数最高的100个物品作为ItemCF通道的输出
用索引,离线计算量大(需要更新2个索引),线上计算量小(不需访问上亿个物品)
ItemCF召回通道的输出,会跟其他召回通道的输出融合起来做排序
如果取回的物品ID有重复的,就去重,并把分数加起来
ItemCF的原理:
- 用户喜欢物品i1,那么用户喜欢与物品i1相似的物品i2
- 物品相似度:
- 不是根据物品的内容判定物品相似,而是根据用户行为
- 如果喜欢i1、i2的用户有很大的重叠,那么i1与i2相似
ItemCF召回通道:
- 维护两个索引:
- 用户->物品列表:用户最近交互过的n个物品
- 物品->物品列表:相似度最高的k个物品
- 线上做召回:
- 利用两个索引,每次取回nk个物品
- 预估用户对每个物品的兴趣分数:
- 返回分数最高的100个物品,作为召回结果

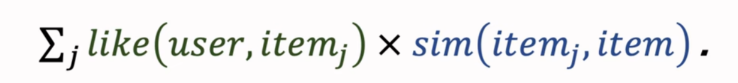
2、Swing召回通道(ItemCF的变种)
与ItemCF非常像,区别就是如何定义物品的相似度
ItemCF:


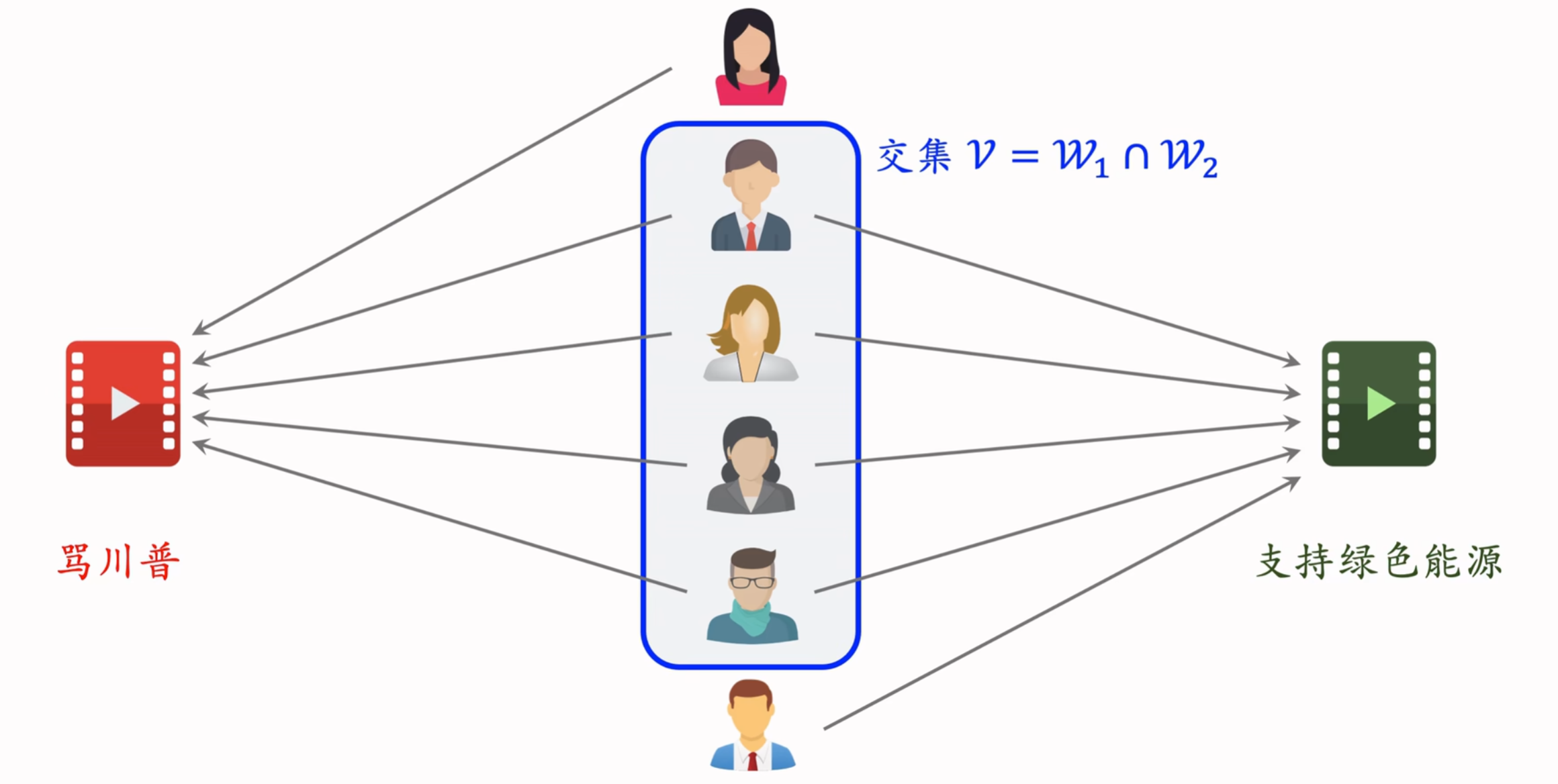
ItemCF的问题:两篇笔记受众不同,但由于被分享到一个小圈子,导致很多用户同时交互过这两篇笔记。需要降低小圈子用户的权重
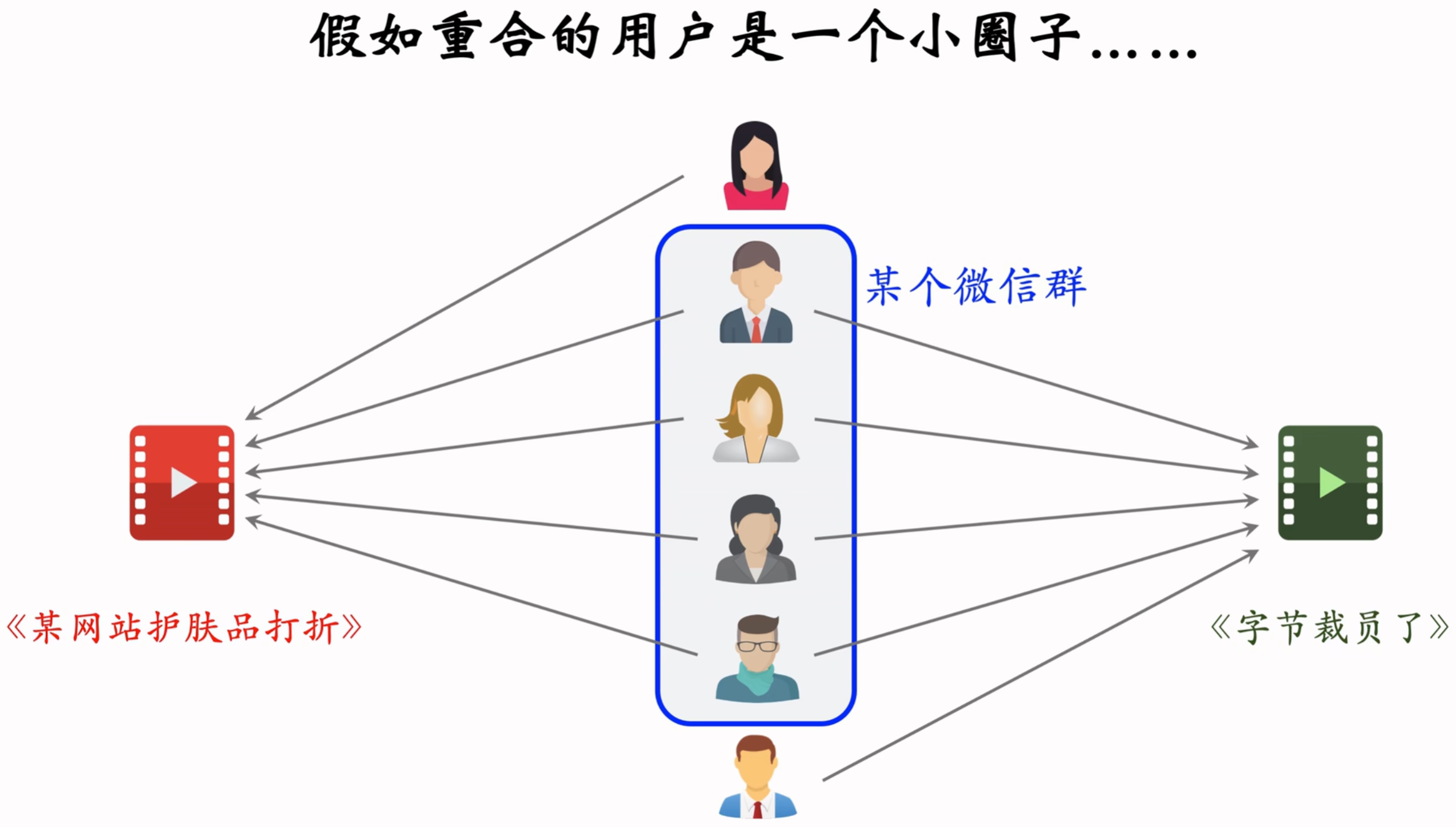
Swing模型即给用户设置权重,解决小圈子问题


α是个人工设置的参数;overlap为u1和u2的重叠,重叠大说明两个人是一个小圈子,对相似度的贡献应减小
Swing与ItemCF唯一的区别在于物品相似度
- ItemCF:两个物品重合的用户比例高,则判定两个物品相似
- Swing:额外考虑重合的用户是否来自一个小圈子
- 同时喜欢两个物品的用户记作集合v
- 对于v中的用户u1和u2,重合度记作overlap(u1, u2)
- 两个用户重合度大,则可能来自一个小圈子,权重降低
3、基于用户的协同过滤(UserCF)
UserCF原理
有很多跟我兴趣非常相似的网友,其中某个网友对某笔记点赞、转发,而我没看过这篇笔记,那么可能给我推荐这篇笔记
推荐系统如何找到跟我兴趣非常相似的网友呢?
- 点击、点赞、收藏、转发的笔记有很大的重合
- 关注的作者有很大的重合
UserCF实现
0代表用户没有看过物品,或对物品不感兴趣

用户相似度
用户有共同的兴趣点,即喜欢的物品有重合

上述公式同等对待热门和冷门的物品,需降低热门物品的权重

物品越热门, 越大,分子(即物品的权重)越小
UserCF的基本思想:
- 如果用户user1跟用户user2相似,而且user2喜欢某物品,那么用户user1也很可能喜欢该物品
预估用户user对候选物品item的兴趣:
计算两个用户的相似度:
- 把每个用户表示为一个稀疏向量,向量每个元素对应一个物品
- 如果用户对物品不感兴趣,向量元素为0;若感兴趣,元素为1,或1除以物品的热门程度
- 相似度sim就是两个向量夹角的余弦

UserCF召回的完整流程
为了能在线上实时推荐,必须要事先做离线计算,建立两个索引
事先做离线计算
建立 “用户->物品” 的索引:
- 记录每个用户最近点击、交互过的物品ID
- 给定任意用户ID,可以找到他近期感兴趣的物品列表

建立 “用户->用户” 的索引:
- 对于每个用户,索引他最相似的k个用户
- 给定任意用户ID,可以快速找到他最相似的k个用户
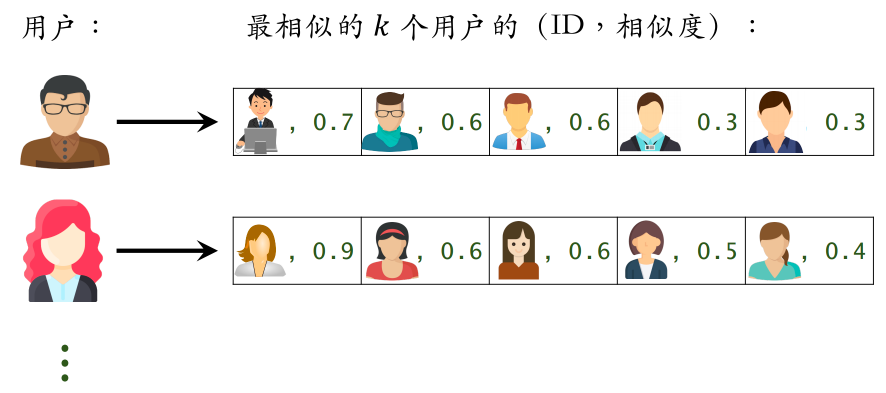
线上做召回
- 给定用户ID,通过 “用户->用户” 的索引,找到topk相似用户
- 对于每个top-k相似用户,通过 “用户->物品” 的索引,找到用户近期感兴趣的物品列表(last-n)
- 对于取回的nk个相似物品,用公式预估用户对每个物品的兴趣分数
- 返回分数最高的100个物品,作为召回结果
若取回的物品有重复的,去重,并把分数加起来

UserCF的原理:
- 用户u1跟用户u2相似,而且u2喜欢某物品,那么u1也可能喜欢该物品
- 用户相似度:
- 如果用户u1和u2喜欢的物品有很大的重叠,那么u1和u2相似
(分母是做归一化,让相似度分数介于0~1之间)
UserCF召回通道:
- 维护两个索引:
- 用户->物品列表:用户近期交互过的n个物品
- 用户->用户列表:相似度最高的k个用户
- 线上做召回:
- 利用两个索引,每次取回nk个物品
- 预估用户user对每个物品item的兴趣分数:
- 返回分数最高的100个物品,作为召回结果
--------------------------------------------- 分割线,上面都是协同过滤召回 ---------------------------------------
4、离散特征处理
- 协同过滤召回(以上内容)
- 向量召回(之后内容)
离散特征
如性别、国籍、英文单词、物品ID、用户ID
处理:
- 建立字典:把类别映射成序号
- 向量化:把序号映射成向量
- One-hot编码:把序号映射成高维稀疏向量,序号对应位置的元素为1,其他位置元素都是0
- Embedding:把序号映射成低维稠密向量
One-Hot编码
性别:男、女两种类别
- 字典:男->1,女->2
- One-hot编码:用2维向量表示性别
- 未知 -> 0 -> [0, 0]
- 男 -> 1 -> [1, 0]
- 女 -> 2 -> [0, 1]
国籍:中国、美国、印度等200种类别
- 字典:中国->1,美国->2,印度->3,...
- One-hot编码:用200维稀疏向量表示国籍
- 未知 -> 0 -> [0, 0, 0, 0, ..., 0]
- 中国 -> 1 -> [1, 0, 0, 0, ..., 0]
- 美国 -> 2 -> [0, 1, 0, 0, ..., 0]
- 印度 -> 3 -> [0, 0, 1, 0, ..., 0]
局限:类别数量太大时,通常不用one-hot编码
Embedding(嵌入)
把每个类别映射为一个低维的稠密向量

参数数量 = 向量维度 × 类别数量
- 设Embedding得到的向量都是4维的
- 一共有200个国籍
- 参数数量=800
编程实现:TensorFlow、Pytorch提供Embedding层
- 参数以矩阵的形式保存,矩阵大小是向量维度×类别数量
- 输入是序号,比如美国的序号是2
- 输出是向量,比如美国对应参数矩阵的第2列
两者联系

离散特征处理:One-hot编码、embedding
类别数量很大时,用embedding,如:
- word embedding
- 用户ID embedding
- 物品ID embedding
------------------------------------------------- 分割线,下面都是向量召回 ------------------------------------------
5、矩阵补充(Matrix Completion)、最近邻查找
矩阵补充(Matrix Completion)是向量召回最简单的一种,已经不太常用,是为了帮助理解双塔模型
矩阵补充模型结构
输出是一个实数(用户对物品兴趣的预估值),越大表示用户对物品越感兴趣
- 左边的Embedding Layer:矩阵列的数量为用户数量,每一列都是向量a这样的对用户的表征
- 右边的Embedding Layer
- 两个Embedding Layer不共享参数
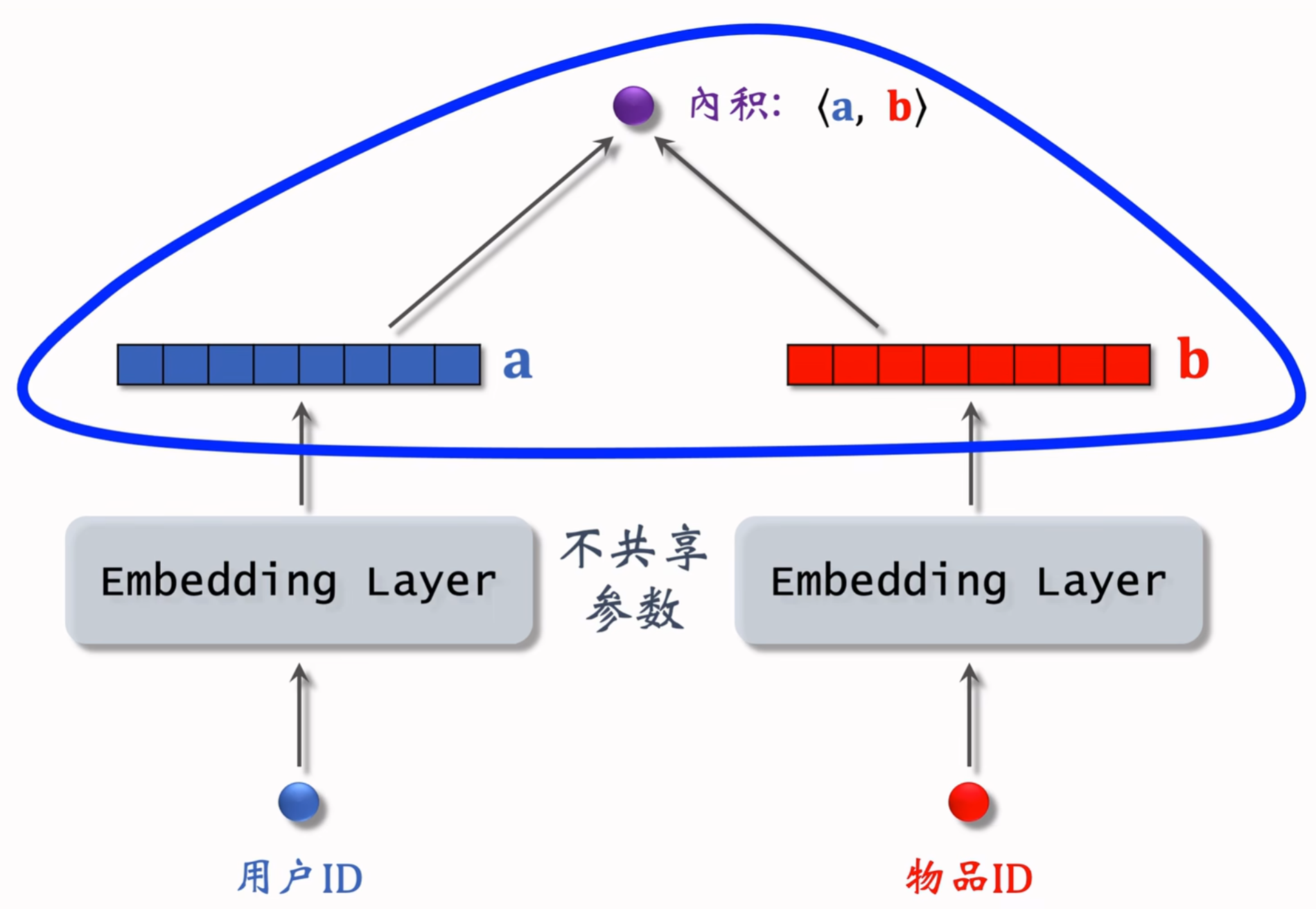
矩阵补充模型训练
(1)基本想法:

(2)数据集:是很多三元组的集合

(3)训练:让模型的输出拟合兴趣分数

- (u, i, y)三元组 是训练集中的一条数据,表示 用户u 对 物品i 的 真实兴趣分数y
- 对目标函数求min,可以用随机梯度下降,每次更新A和B的一列
(4)直观解释:

拿绿色位置的数据训练模型,预估所有灰色位置的分数。给定一个用户,选出用户对应行中分数较高的物品,推荐给用户
矩阵补充的缺点
矩阵补充在实践中效果不好,在工业界不work
- 缺点1:仅用ID Embedding,没利用物品、用户属性
- 物品属性:类目、关键词、地理位置、作者信息
- 用户属性:性别、年龄、地理定位、感兴趣的类目
- 双塔模型可以看做矩阵补充的升级版,会结合物品属性和用户属性
- 缺点2:负样本的选取方式不对
- 样本:用户-物品的二元组,记作(u, i)
- 正样本:曝光之后,有点击、交互(正确的做法)
- 负样本:曝光之后,没有点击、交互(错误的做法)
- 缺点3:做训练的方法不好
- 内积 <au, bi> 不如余弦相似度
- 用平方损失(回归),不如用交叉熵损失(分类)
矩阵补充线上服务
模型存储:
- 训练得到矩阵A和B。A的每一列对应一个用户,B的每一列对应一个物品
- 把矩阵A的列存储到key-value表,key是用户ID,value是A的一列。给定用户ID,返回一个向量(用户Embedding)
- 矩阵B的存储和索引比较复杂,不能简单地用key-value存储
线上服务:

近似最近邻查找(Approximate Nearest Neighbor Search)
避免暴力枚举(暴力枚举计算量正比于物品数量),近似最近邻查找的结果未必最优,但不会比最优差多少
支持最近邻查找的系统:
- 系统:Milvus、Faiss、HnswLib,等
- 衡量最近邻的标准:
- 欧式距离最小(L2距离)
- 向量内积最大(内积相似度):矩阵补充用的就是这个
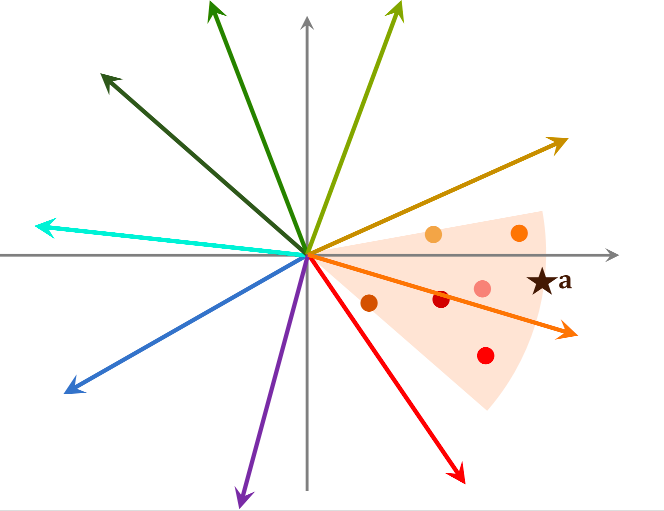
- 向量夹角余弦最大(cosine相似度):最常用,即夹角最小
有些系统不支持余弦相似度,可以把所有向量都做归一化,让它们的二范数等于1,那么内积就等于余弦相似度
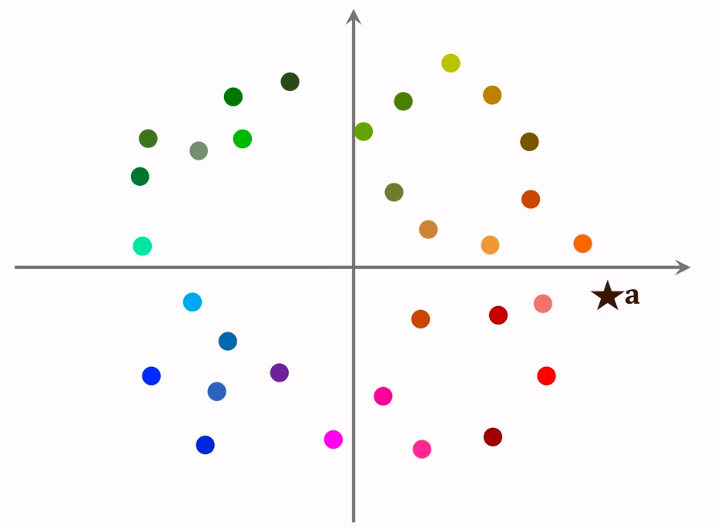
在做线上服务前,把数据划分为很多区域:
- cos相似度,划分结果为扇形
- 欧式距离,划分结果为多边形

划分后,每个区域用一个向量表示,这些向量的长度都是1。划分区域后,建立索引,key为每个区域的向量,value为区域中所有点的列表
首先计算用户a与索引向量的相似度,通过索引找出该区域内的所有点,再计算用户a与该区域所有点的相似度
矩阵补充:
- 把物品ID、用户ID做embedding,映射成向量
- 两个向量的内积<au, bi>作为 用户u 对 物品i 兴趣的预估
- 让<au, bi>拟合真实观测的兴趣分数,用回归的方式学习模型的embedding层参数
- 矩阵补充模型有很多缺点,效果不好。工业界不用矩阵补充,而是用双塔模型
线上召回:
- 把用户向量a作为query,查找使得<a, bi>最大化的物品i(内积最大的 top k 物品i)
- 暴力枚举速度太慢,实践中用近似最近邻查找
- Milvus、Faiss、HnswLib等开源向量数据库支持近似最近邻查找
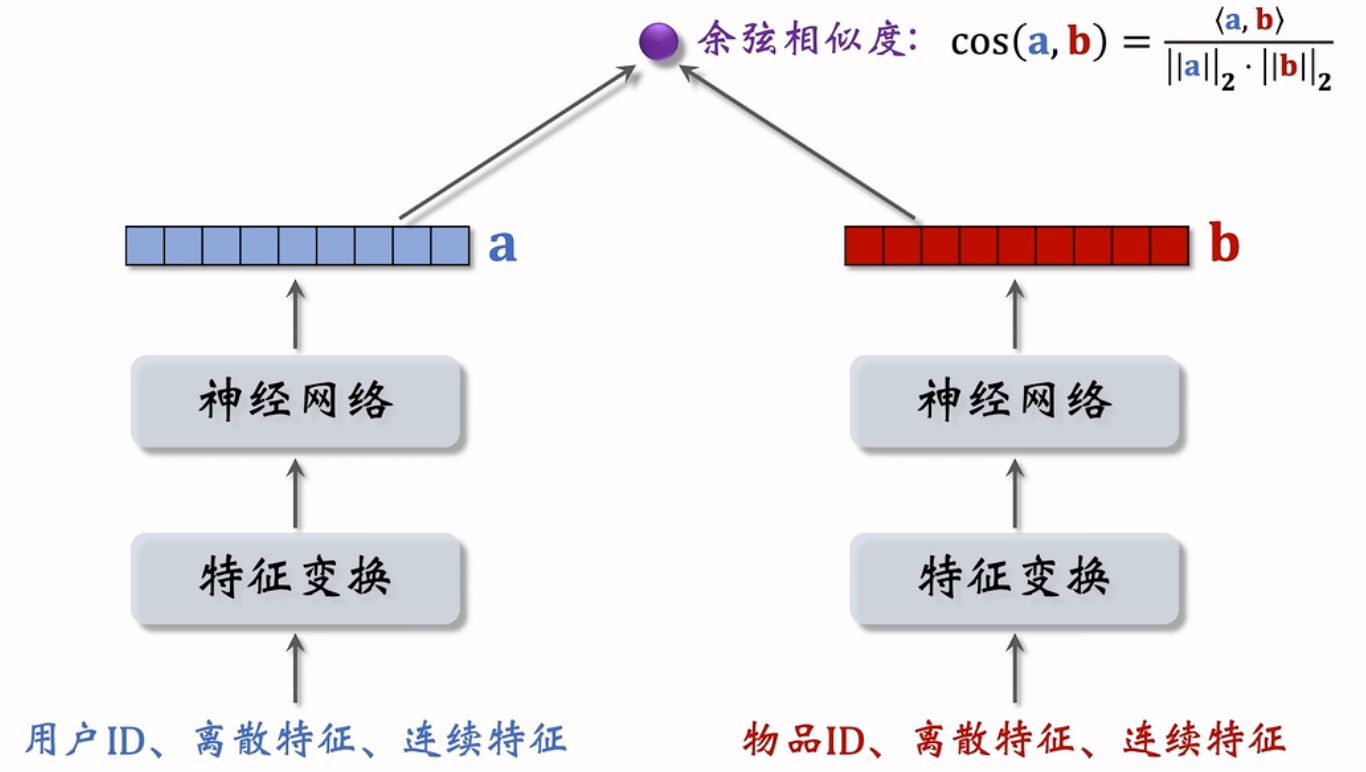
6、双塔模型(DSSM)
双塔模型可以看做是矩阵补充模型的升级
模型结构
用户离散特征:
- 所在城市、感兴趣的话题等:Embedding,不同的离散特征要用不同的Embedding层得到向量
- 性别:对类别数量很少的离散特征,用One-hot编码即可,可以不做Embedding
用户连续特征:年龄、活跃程度、消费金额
- 归一化:让特征的均值为0,标准差为1
- 有些长尾分布的连续特征需要特殊处理,如取log、分桶
神经网络可以是简单的全连接网络,也可以是更复杂的深度交叉网络

物品的表征类似处理

双塔模型使用了ID之外的多种特征作为输入,输出介于-1~1的余弦相似度(余弦相似度相当于先对两个向量做归一化,再求内积,比内积更常用)
正负样本的选择
- 正样本:历史记录显示用户喜欢的物品。如用户点击的物品
- 负样本:用户不感兴趣的物品
- 没有被召回的?
- 召回但是被粗排、精排淘汰的?
- 曝光但是未点击的? —— 不能作为召回的负样本,可以作为排序的负样本
训练方法
pairwise:Jui-Ting Huang et al. Embedding-based Retrieval in Facebook Search. In KDD, 2020.(Facebook)
listwise:
Xinyang Yi et al. Sampling-Bias-Corrected Neural Modeling for Large Corpus ItemRecommendations. In RecSys, 2019.(YouTube)
- pointwise:独立看待每个正样本、负样本,做简单的二元分类。即把正样本和负样本组成一个数据集,在数据集上做随机梯度下降训练双塔模型
- pairwise:每次取一个正样本、一个负样本,组成一个二元组,损失函数为triplet hinge loss或triplet logistic loss
- listwise:每次取一个正样本、多个负样本,组成一个list,训练方式类似于多元分类
pointwise训练
- 把召回看做二元分类任务
- 对于正样本,鼓励 cos(a,b) 接近+1
- 对于负样本,鼓励 cos(a,b) 接近-1
- 控制正负样本数量为1:2或者1:3(行业经验)
pairwise训练
输入一个三元组,用户的特征向量为a,两个物品的特征向量为b+和b-。两个物品塔共享参数

让用户对正样本的兴趣分数尽量高(最好接近+1),对负样本的兴趣分数尽量低(最好接近-1)
(1)Triplet Hinge Loss:孪生网络

(2)Triplet Logistic Loss:让cos(a, b-)尽量小,让cos(a,b+)尽量大
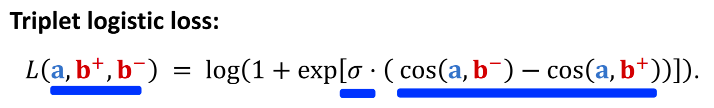
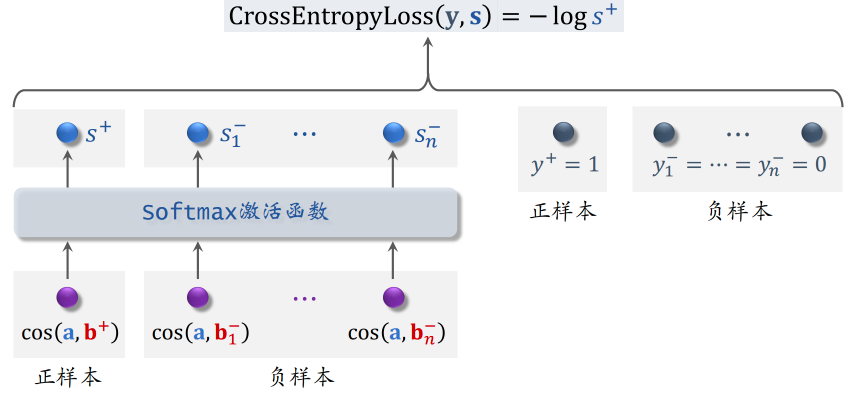
listwise训练

最大化正样本的余弦相似度,最小化负样本的余弦相似度
不适用于召回的模型

上图为粗排/精排的模型,不能应用于召回
- 前期融合,在进入全连接层之前就把特征向量拼起来了 —— 排序模型
- 双塔模型属于后期融合,两个塔在最终输出相似度时才融合 —— 召回模型
前期融合的模型不适用于召回,否则要把所有物品的特征挨个输入模型,预估用户对所有物品的兴趣,无法使用近似最近邻查找来加速计算。通常用于排序(从几千个物品中选出几百个)
双塔模型:
- 用户塔、物品塔各输出一个向量
- 两个向量的余弦相似度作为兴趣的预估值,越大,用户越有可能对物品感兴趣
- 三种训练方式:
- pointwise:每次用一个用户、一个物品(可正可负)
- pairwise:每次用一个用户、一个正样本、一个负样本。训练目标是最小化triplet loss,即让正样本余弦相似度尽量大,负样本余弦相似度尽量小
- listwise:每次用一个用户、一个正样本、多个负样本。训练时用softmax激活+交叉熵损失,让正样本余弦相似度尽量大,负样本余弦相似度尽量小
正负样本
选对正负样本的作用 > 改进模型结构
正样本:
- 正样本:曝光而且有点击的用户-物品二元组(用户对物品感兴趣)
- 问题:二八法则,少部分物品占据大部分点击,导致正样本大多是热门物品。拿过多热门物品当正样本,会对冷门物品不公平,让热门更热、冷门更冷
- 解决方案:过采样冷门物品,或降采样热门物品
- 过采样(up-sampling):一个样本出现多次
- 降采样(down-sampling):一些样本被抛弃。如以一定概率抛弃热门物品,抛弃的概率与样本的点击次数正相关
负样本:用户不感兴趣的物品,或链路上每一步被淘汰的物品

简单负样本:未被召回物品
(1)全体物品:从全体物品中做非均匀抽样,作为负样本
未被召回的物品,大概率是用户不感兴趣的。几亿个物品里只有几千个被召回,故未被召回的物品 ≈ 全体物品

使用非均匀抽样,热门物品成为负样本的概率大
(2)batch内负样本
图中是一个batch内的样本。训练时要鼓励正样本的余弦相似度尽量大,负样本的余弦相似度尽量小
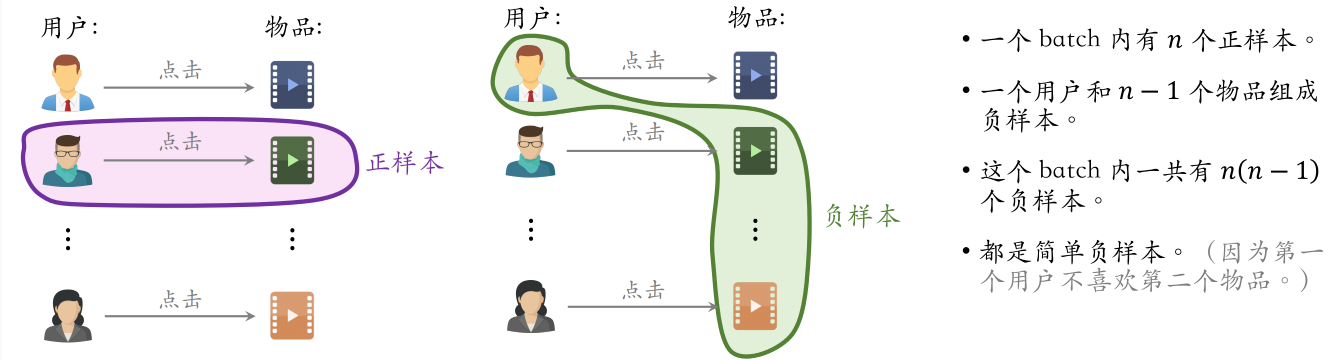
一个物品成为负样本的概率越大,模型对这个物品打压就会越狠

这样理解Batch内负样本的修正:p越小,-logp越大,softmax结果s更高。如果是正样本(s>0.5),那导数会偏小(输出已经很接近正确标签,不希望模型做出太大的调整);如果是负样本,那导数会偏大。就形成了对低频物品(p小)更强的负样本的倾向,相当于是放大了冷门负样本的梯度
-logp算是物品的先验,模型实际上是非常容易拟合先验的,所以要debias掉
注意,线上召回时,还是用原本的余弦相似度,不用做这种调整,不用减掉 logpi
困难负样本:粗排/精排淘汰
-
被粗排淘汰的物品 (比较困难)
-
精排分数靠后的物品 (非常困难)
训练双塔模型,其实是对正负样本做二元分类:
- 全体物品(简单)分类准确率高
-
被粗排淘汰的物品 (比较困难) 容易分错
-
精排分数靠后的物品 (非常困难) 更容易分错
训练数据
混合几种负样本,50%的负样本是从全体物品随机非均匀抽样得到(简单负样本),50%的负样本是没通过粗排精排的物品,即从粗/精排淘汰的物品中随机抽样得到(困难负样本)
常见的错误

选择负样本的原理:
- 召回的目标:快速找到用户可能感兴趣的物品,再交给后面的排序逐一甄别
-
全体物品(easy): 绝大多数是用户根本不感兴趣的
-
被排序淘汰(hard): 用户可能感兴趣,但是不够感兴趣。这样的负样本做分类时比较难以区分,所以是困难负样本
-
有曝光没点击(不能作为负样本): 用户感兴趣,可能碰巧没有点击【 可以作为排序的负样本,不能作为召回的负样本 】
-
正样本:曝光而且有点击的用户-物品二元组
简单负样本:
- 全体物品中做非均匀随机抽样
- batch内负样本
困难负样本:被召回,但是被排序淘汰(跟正样本很像,做分类会有困难)
错误:曝光但是未点击的物品做召回的负样本。这类负样本只能用于排序,不能用于召回
线上服务/线上召回
训练好的两个塔,分别提取用户特征和物品特征
- 向量数据库存储物品特征向量和ID的二元组,用作最近邻查找
- 不要事先计算和存储用户向量。当用户发起推荐请求时,调用神经网络现算一个特征向量a,然后把向量a作为query,去向量数据库中检索查找最近邻

离线存储:把物品向量b存入向量数据库
- 完成训练之后,用物品塔计算每个物品的特征向量b
- 把几亿个物品向量b存入向量数据库,比如Milvus、Faiss、HnswLib
- 向量数据库建索引(把向量空间划分成很多区域,每个区域用一个向量表示),以便加速最近邻查找
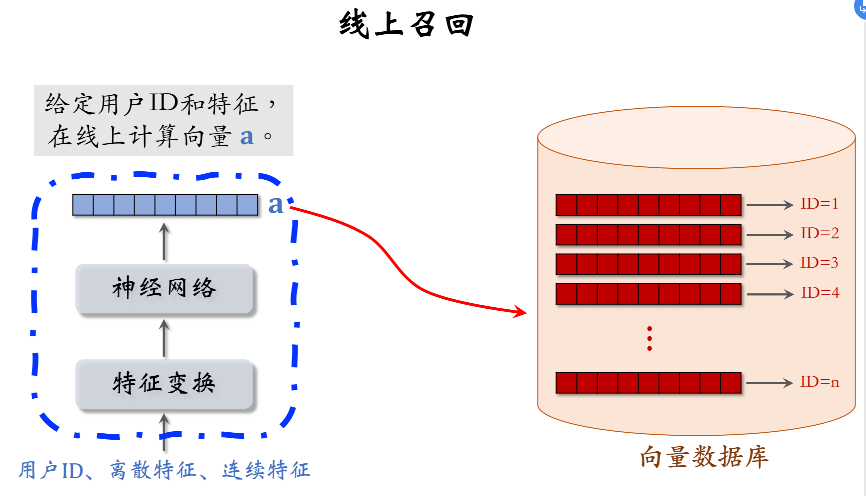
线上召回:查找用户最感兴趣的k个物品
- 给定用户ID和画像,线上用神经网络算用户向量a
- 最近邻查找:把向量a作为query,调用向量数据库做最近邻查找,返回余弦相似度最大的k个物品,作为召回结果
事先存储物品向量b,线上现算用户向量a,为什么?
- 每做一次召回,用到一个用户向量a,几亿物品向量b(线上算物品向量的代价过大)
-
用户兴趣动态变化,而物品特征相对稳定 (可以离线存储用户向量,但不利于推荐效果)
训练好双塔模型之后,在开始线上服务之前,先要做离线存储,在向量数据库建好索引之后,可以做线上召回
跟ItemCF、Swing、UserCF等召回通道的结果融合
模型更新
全量更新(天级别)
今天凌晨,用昨天全天的数据训练模型
- 在昨天模型参数的基础上做训练(不是随机初始化)
- 用昨天全天的数据(要先random shuffle打乱,然后打包成TFRecord)训练1个epoch,即每条数据只过一遍
- 训练完成后,发布新的用户塔神经网络(在线上实时计算用户向量,作为召回的query)和物品向量(存入向量数据库,向量数据库会重新建索引,在线上做最近邻查找),供线上召回使用
- 全量更新对数据流、系统的要求比较低
- 不需要实时的数据流,对生成训练数据的速度没有要求,延迟一两个小时也没关系。只需要把每天的数据落表,在凌晨做个批处理,把数据打包成TFRecord格式即可
- 每天只需要把神经网络和物品向量发布一次即可
- 只有做全量更新时才更新全连接层
增量更新(分钟级别)
做online learning更新模型参数,每隔几十分钟就要把新的模型参数发布出去,刷新线上的用户塔Embedding层参数
- 用户兴趣会随时发生变化
- 实时收集线上数据,做流式处理,实时生成训练模型用的TFRecord文件
-
对模型做online learning,梯度下降增量更新ID Embedding参数 (不更新神经网络其他部分的参数,全连接层是锁住的,不做增量更新;只有全量更新会更新全连接层参数)
-
发布用户ID Embedding(哈希表),供用户塔在线上计算用户向量,可以捕捉用户最新的兴趣点。这个过程会有延迟,但可以被缩短到几十分钟
全量 vs 增量

今天凌晨的全量更新,是基于昨天凌晨全量训练出来的模型,而不是用下面增量训练出来的模型。在完成这次全量之后,下面增量训练出来的模型就可以扔掉了
能否只做增量更新,不做全量更新?

-
小时级数据有偏,统计值跟全天数据差别很大(不同时间段用户的行为不同);分钟级数据偏差更大
-
全量更新: random shuffle (为了消除偏差)一天的数据,做 1 epoch 训练
-
增量更新:按照数据 从早到晚的顺序 ,做 1 epoch 训练
-
随机打乱 优于 按顺序排列数据 , 全量训练 优于 增量训练
全量训练的模型更好,而增量训练可以实时捕捉用户的兴趣
双塔模型:
召回:
更新模型:定期全量+实时增量
- 实际的系统:全量更新(每天) & 增量更新(实时) 相结合。每隔几十分钟,发布最新的用户 ID Embedding,供用户塔在线上计算用户向量(好处:捕捉用户的最新兴趣点)
7、双塔模型+自监督学习
自监督学习:改进双塔模型的方法,能提升业务指标,目的是把物品塔训练的更好
双塔模型的问题
- 推荐系统的头部效应严重:
- 少部分物品占据大部分点击
- 训练双塔模型时用点击数据作为正样本,模型学习物品的表征靠的就是点击行为
- 大部分物品的点击次数不高
- 高点击物品的表征学得好,长尾物品的表征学的不好(长尾物品的曝光和点击次数太少,训练的样本数量不够)
- 自监督学习:对物品做data augmentation,更好地学习长尾物品的向量表征
双塔模型的训练(同时训练用户塔和物品塔)
用batch内负样本
- 一个batch内有n对正样本
- 组成n个list,每个list中有1对正样本和n-1对负样本
listwise训练

让模型给正样本打的分数尽量高,给负样本打的分数尽量低
损失函数:考虑batch内第i个用户和全部n个物品
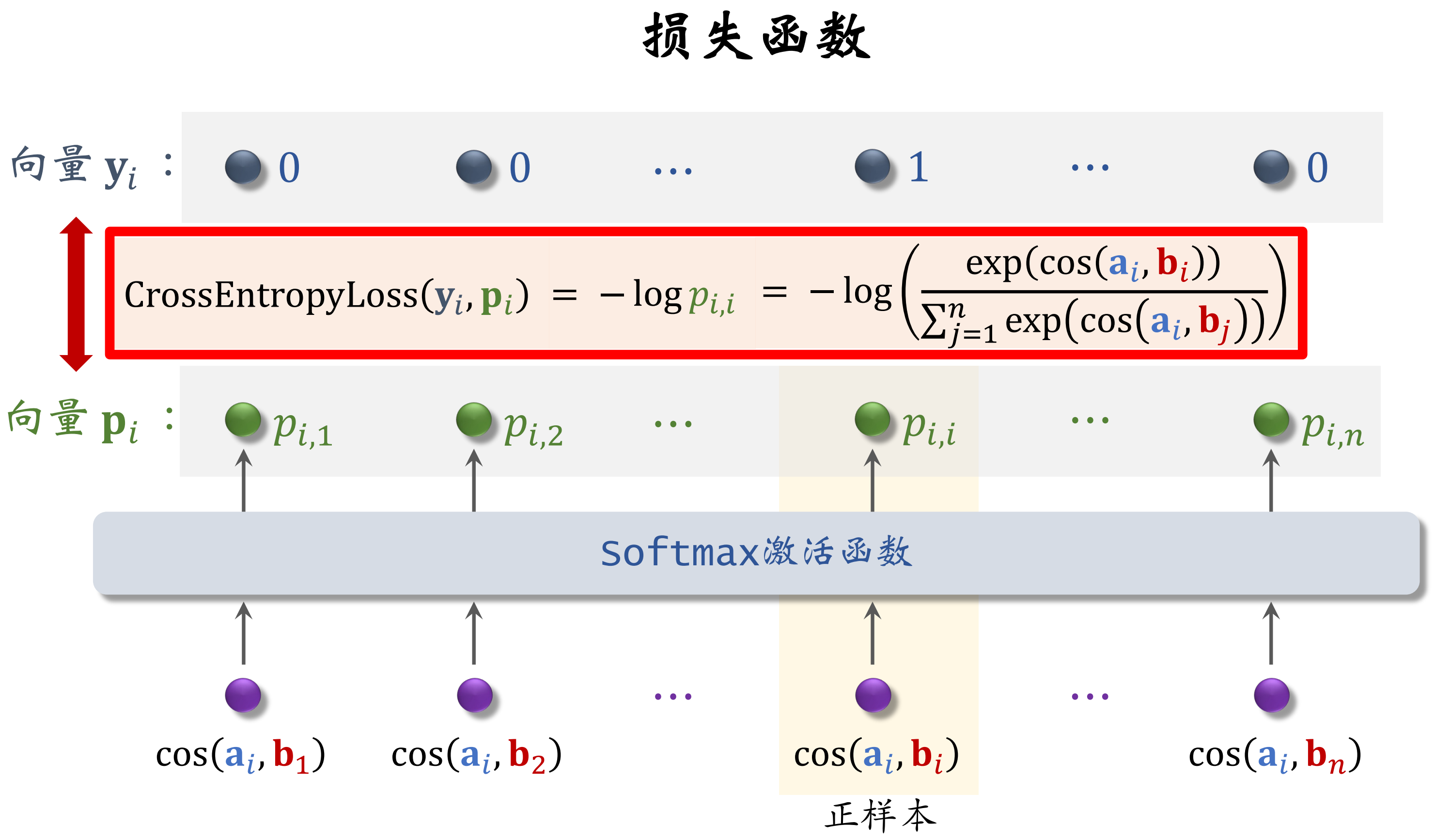
纠偏

batch内负样本会过度打压热门物品,造成偏差。如果用batch内负样本,需要纠偏,使热门物品不至于被过分打压。训练结束,在线上做召回时,还是用原本的余弦相似度
训练双塔模型
- i:第i个用户
- n:batch内一共有n个用户

自监督学习(训练物品塔)
- 双塔模型的listwise训练方式,同时训练用户塔和物品塔
- 自监督学习训练物品塔
Tiansheng Yao et al. Self-supervised Learning for Large-scale Item Recommendations. In CIKM, 2021. 【Google】

尽管对应不同的特征变换,但同一物品的两个向量表征应有较高的相似度

不同物品的向量表征的分布应尽量分散开

如何变换物品特征
四种方法:
- Random Mask(随机选一些离散特征,将它们的值换为default)
- Dropout(仅对多值离散特征生效)
- 互补特征(将物品的多个特征随机分组,鼓励两组特征形成的物品表征向量相似)
- Mask一组关联的特征(计算互信息来衡量特征两两之间的关联。随机选一个特征,mask该特征及其最相关的k/2种特征,其余保留)
(1)Random Mask

一个物品可以有多个类目
- 如果不做random mask,正常的特征处理方法是对数码和摄影分别做embedding,得到两个向量,再做求和或平均,得到一个向量,表征物品类目
- 如果对类目特征做mask,这个物品的类目特征就变成了default。default表示默认的缺失值,对default做embedding,得到一个向量表征类目。也就是说,做mask后,物品的类目特征直接被丢掉(数码和摄影都没了)
(2)Dropout(仅对多值离散特征生效)
多值离散特征:离散特征 + 一个物品可以有多个该特征的取值

random mask是对整个类目特征的取值都丢掉,dropout只丢掉类目特征取值的50%
(3)互补特征(complementary)

正常的做法是把四种特征的值分别做embedding,然后拼起来输入物品塔,最终得到物品的向量表征
(4)mask一组关联的特征
特征之间有较强的关联,遮住一个特征并不会损失太多的信息,模型可以从其他强关联特征中学到遮住的特征


两个特征关联越强,p(u,v)就比较大,它们的互信息就越大

- 好处:效果好,推荐的主要指标比random mask、dropout、互补特征等方法效果更好
- 坏处:方法复杂,实现的难度大,不容易维护(每添加一个新的特征,都需要重新计算所有特征的MI)
如何用变换后的特征训练模型

这里冷热门物品被抽样到的概率是相同的(注意跟训练双塔的区别。训练双塔得到的数据是根据点击行为抽样的,热门物品被抽到的概率大。双塔抽的是用户-物品二元组,这里只抽物品)
考虑batch中第i个物品的特征向量bi',和全部m个物品的特征向量b'':
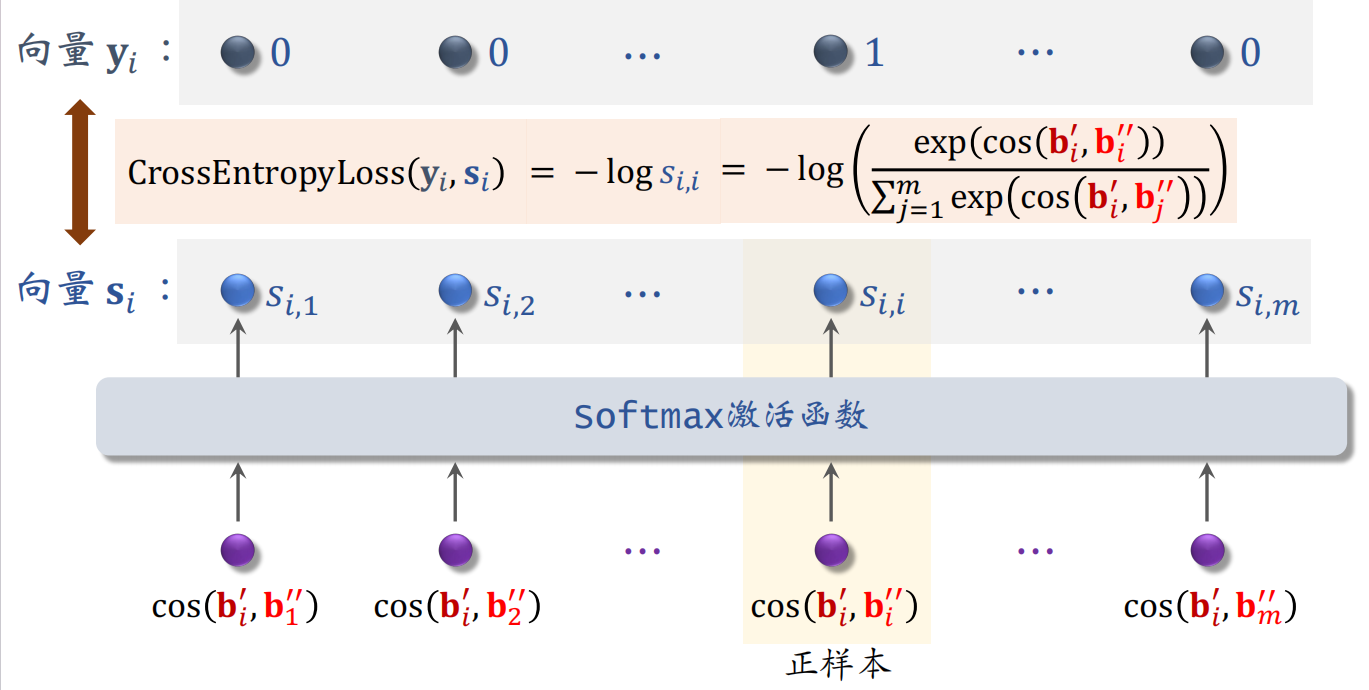
训练时希望向量si接近yi,说明物品塔训练的好,即使做随机特征变换,对物品的向量表征也影响不大。用yi和si的交叉熵作为损失函数

双塔模型存在的问题:
- 双塔模型学不好低曝光物品的向量表征(其实这是数据的问题,而不是双塔模型的问题。真实推荐系统都存在头部效应,小部分物品占据了大部分的曝光和点击)
Google提出一种自监督学习的方法,用在双塔模型上效果很好(低曝光物品、新物品的推荐变得更准)
- 对一个物品用两种特征变换,物品输出两个特征向量
- 同一物品的两个不同特征变换得到的向量应该有高相似度
- 不同物品应让物品的向量表征尽量分散在整个特征空间上
训练:

8、Deep Retrieval召回
Deep Retrieval(字节):
Weihao Gao et al. Learning A Retrievable Structure for Large-Scale Recommendations. InCIKM , 2021.TDM(阿里): Han Zhu et al. Learning Tree-based Deep Model for Recommender Systems. In KDD , 2018.
- 经典的双塔模型把用户、物品表示为向量,线上做向量最近邻查找
- Deep Retrieval把物品表征为路径(path),线上查找用户最匹配的路径,从而召回一批物品(类似于阿里的TDM,但更简单)
Deep Retrieval和TDM都用深度学习,但都不做向量最近邻查找

索引:关联路径和物品
L1~L3表示结构的3层(深度depth),每一层里面有K个节点(宽度width)
路径就是几个节点连接起来,路径可以有重合的节点
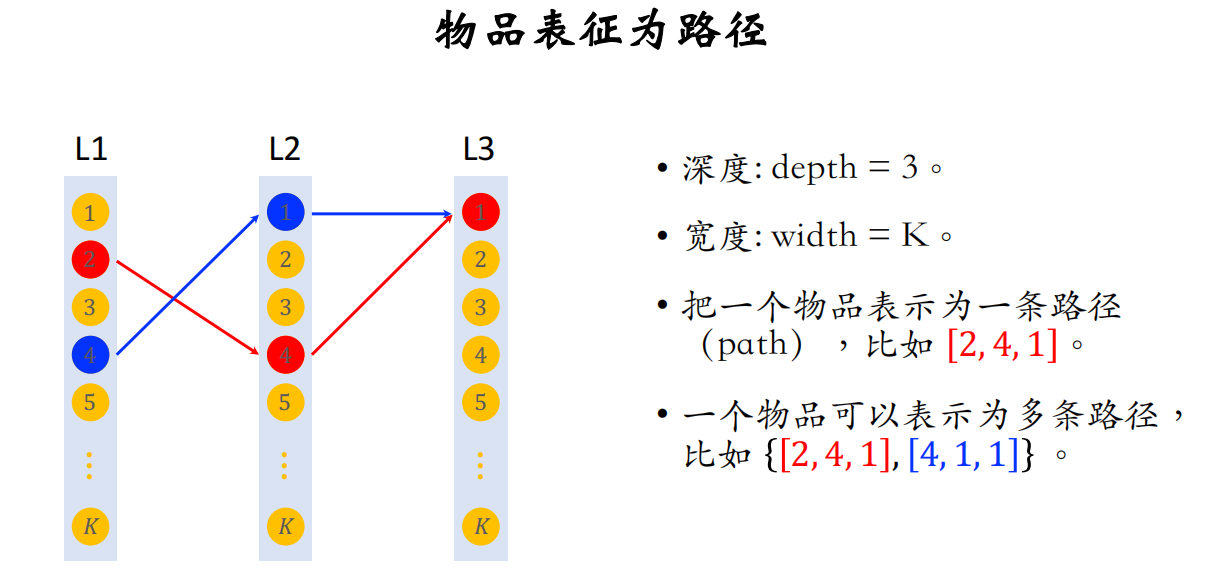
物品->路径的索引:训练神经网络时要用到
- 一个物品对应多条路径
- 用3个节点表示一条路径:path = [a,b,c]
路径->物品的索引:线上做召回时要用到
- 一条路径对应多个物品(给定一条路径,会取回很多个物品作为召回的结果)
预估模型-神经网络(寻找用户感兴趣的路径)
给定用户特征,预估用户对路径的兴趣分数(根据用户特征,召回多条路径)
预估用户对路径的兴趣:
假设结构有3层

过程:
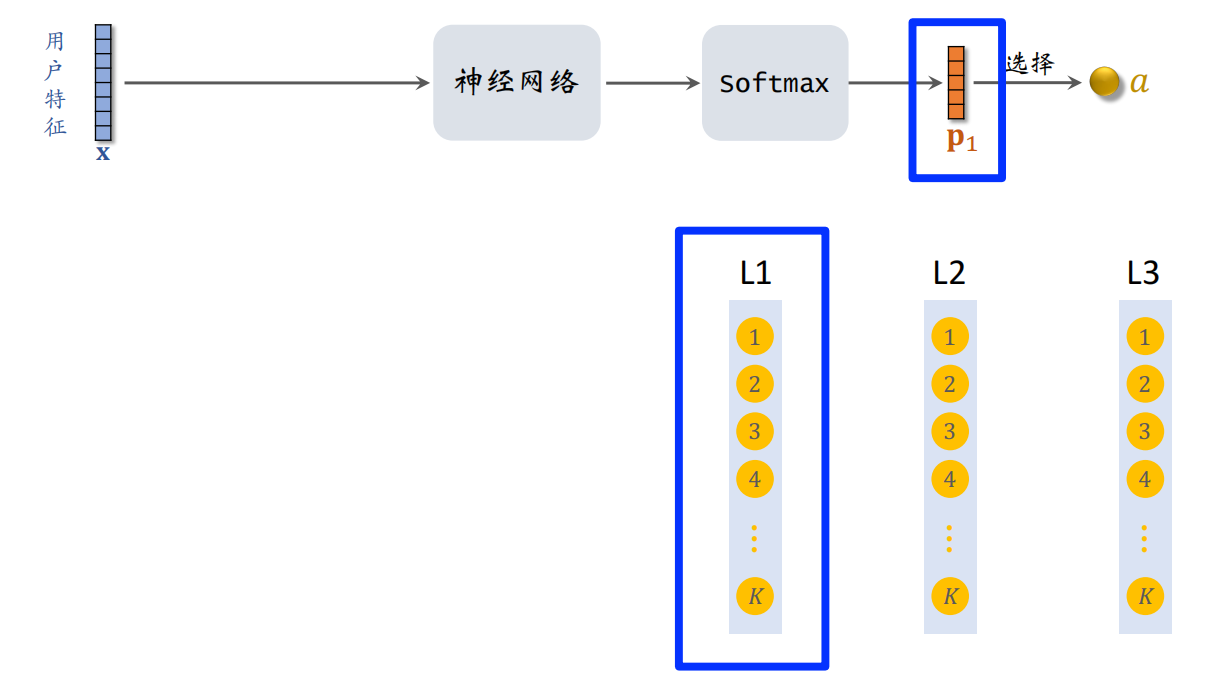
- 如果结构的每一层有k个节点,那么p1就是一个k维向量
- 向量p1对应L1层,向量p1的k个元素是神经网络对L1层k个节点打的分。分数越高,节点就越有可能被选中(用Beam Search的方法。假设选中节点a)
- 向量x不变,直接作为下一层的输入,对节点a做embedding,与x做concat,输入另一个神经网络

- 假设根据向量p1,从k个节点中选出节点a。把向量x和节点a一起送入下一层神经网络,输出k维向量p2(对应结构中的第二层)
- 同理选出节点b,把向量x和节点a、b一起输入下一层神经网络。从3层中各选出一个节点,组成路径 [a,b,c]
线上召回:user->path->item
给定用户特征,召回一批物品

用Beam Search召回一批路径:

beam size(每层选的节点数量)越大,计算量越大,但同时search的结果也会越好(最简单的情况即beam size=1)
Beam Search相当于贪心算法,选中的节点分别最大化p1、p2、p3,但独立对p1、p2、p3求最大化,未必会最大化这三项的乘积

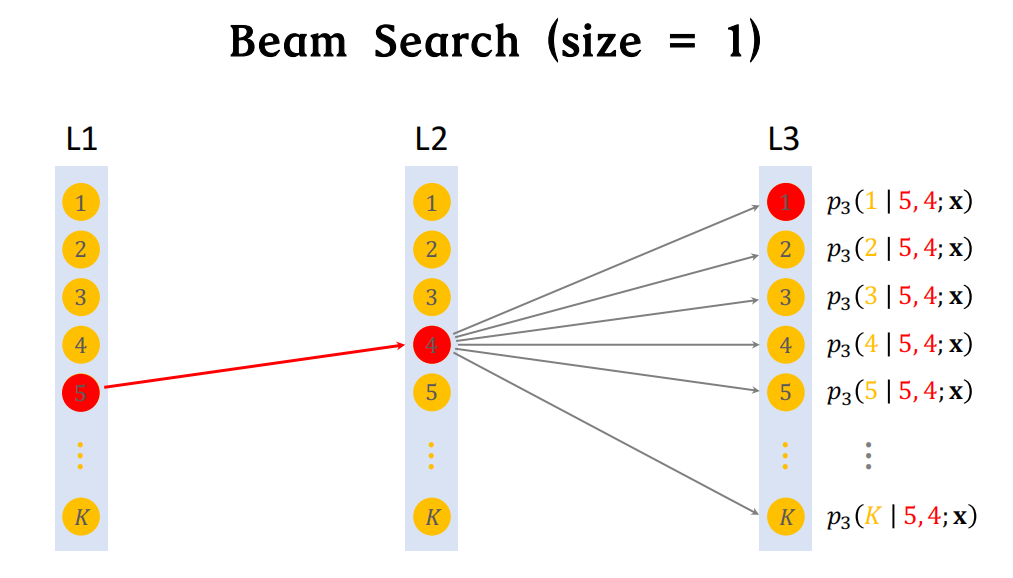
size大一些,结果会比贪心算法好一些,但计算量也变大

步骤:
- 第一步:给定用户特征,用神经网络做预估,用beam search召回一批路径
- 第二步:利用索引,召回一批物品
- 查看索引path->item(在线上做召回之前,线下已经把路径和物品匹配好了)
- 每条路径对应多个物品
- 第三步:对物品做排序,选出一个子集作为最终召回结果
- 用小的排序模型来打分排序,如双塔模型,防止物品超出召回通道的配额
离线训练(同时学习神经网络参数和物品表征)
神经网络可以判断用户对物品的兴趣,物品表征则是把物品映射到路径

训练时只用正样本,用户-物品二元组,只要用户点过物品就算正样本
学习神经网络参数
判断用户对路径有多感兴趣
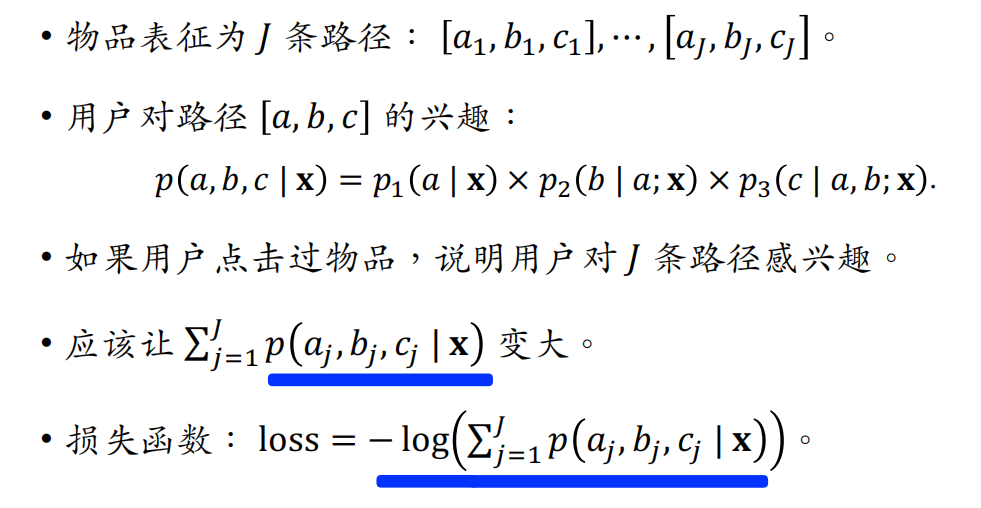
学习物品表征

解释:图中的用户都点击过左边的物品,如果其中很多用户也对路径感兴趣(兴趣分数是神经网络预估出来的),我们就判断物品和路径有很强的关联,可以把路径作为物品的表征

最小化损失,相当于根据score对path做排序,排序结果的top j,即对于每个物品item,选择score最高的j条路径,作为物品的表征
为了防止非常多的物品集中在一条路径上的情况,希望每条path上的item数量比较平衡,需要用正则项约束path。如果某条path上已经有了很多item,这条path就会受到惩罚,避免关联到更多物品

物品与J条路径的相关性越高,损失函数就越小;正则reg控制路径l上的物品不要太多
交替训练神经网络和物品表征
训练神经网络时,把物品当做中介,将用户和路径关联起来

线上召回:用户->路径->物品(两阶段,先用神经网络寻找用户感兴趣的路径,路径长度与神经网络层数相关;再取回路径上的物品)
这里也说明了为什么要用正则项控制一条path上的item不能太多,否则有时候召回的物品数量会特别多,有时候会特别少

Deep Retrieval召回的本质是用路径作为用户和物品之间的中介
双塔模型召回的本质是用向量表征作为用户和物品之间的中介
离线训练:同时学习 用户-路径 和 物品-路径 的关系
避免让索引失去平衡

9、其他召回通道
地理位置召回
GeoHash召回(附近召回)
用户可能对附近发生的事感兴趣
- GeoHash:对经纬度的编码(把经纬度编码为二进制哈希码),地图上一个长方形区域(以GeoHash作为索引,记录地图上一个长方形区域内的优质笔记)
- 索引:GeoHash -> 优质笔记列表(按时间倒排,即最新的笔记排在最前面)
- 召回时,给定用户的GeoHash,会取回这个区域内比较新的一些优质笔记
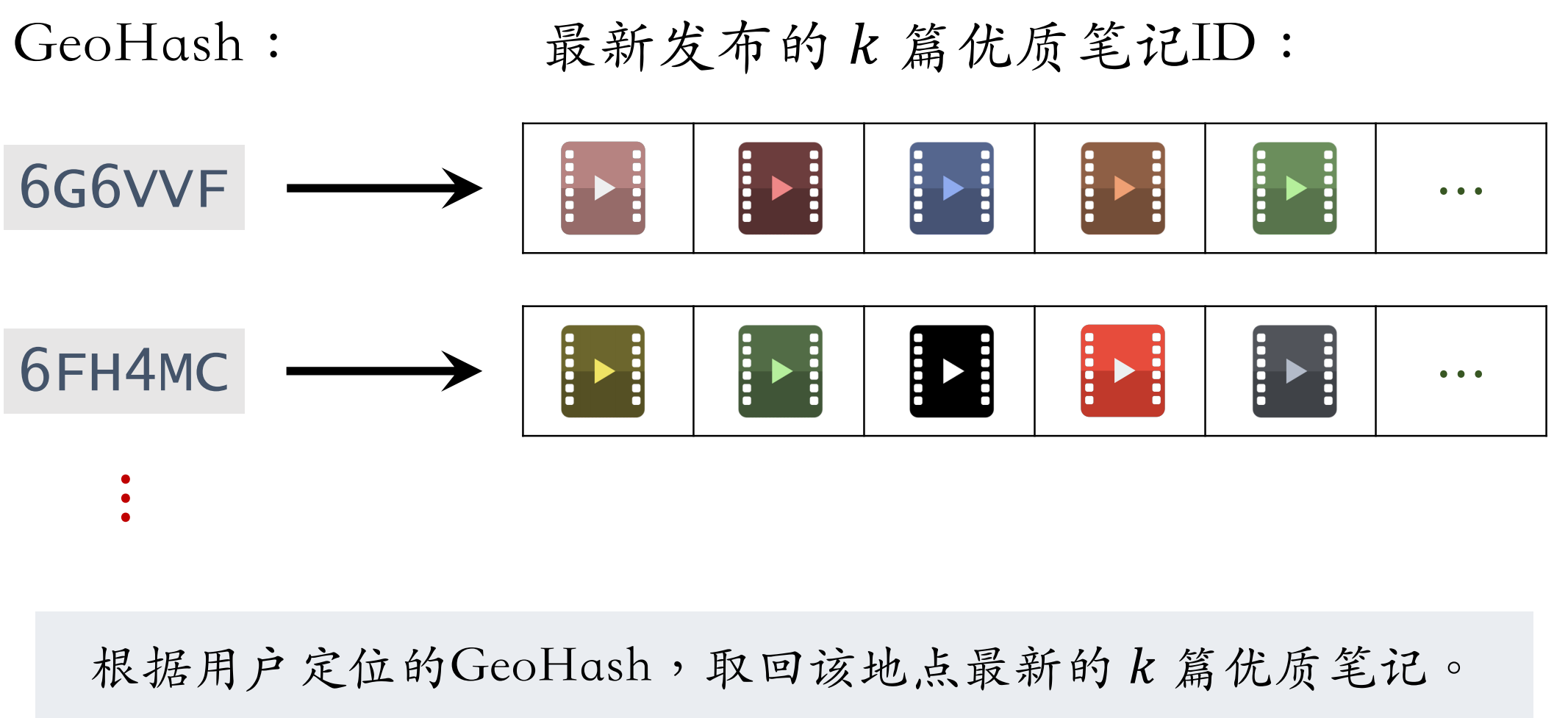
召回纯粹只看地理位置,完全不考虑用户兴趣(就是因为没有个性化,才需要考虑优质笔记。笔记本身质量好,即使没有个性化,用户也很可能会喜欢看;反之,既没有个性化,又不是优质笔记,召回的笔记大概率通不过粗精排)
同城召回
用户可能对同城发生的事感兴趣
- 根据用户所在城市和曾经生活过的城市做召回
- 索引:城市 -> 优质笔记列表(按时间倒排)
这条召回通道没有个性化
作者召回
关注的作者召回
用户对关注的作者发布的笔记感兴趣
- 索引:用户->关注的作者,作者->发布的笔记(按时间顺序倒排,新发布的笔记排在最前面)
- 召回:用户->关注的作者->最新的笔记
有交互的作者召回
即使没关注作者,如果推送有交互作者发布的笔记也可能会感兴趣而继续看
如果用户对某笔记感兴趣(点赞、收藏、转发),那么用户可能对该作者的其他笔记感兴趣
- 索引:用户->有交互的作者
- 召回:用户->有交互的作者->最新的笔记
作者列表需要定期更新,保留最新交互的作者,删除一段时间没有交互的作者
相似作者召回
如果用户喜欢某作者(感兴趣的作者包括用户关注的作者+用户有交互的作者),那么用户喜欢相似的作者。取回每个作者最新的一篇笔记

相似性的计算类似于ItemCF:如果两个作者的粉丝有很大重合,那么两个作者相似
缓存召回
想法:复用前n次推荐精排的结果(精排前50但是没有曝光的,缓存起来,作为一条召回通道)
- 精排输出几百篇笔记,送入重排;重排做多样性的随机抽样(如DPP),选出几十篇
- 精排结果一大半没有曝光,被浪费
问题:缓存大小固定(比如最多存100篇笔记),需要退场机制。有很多条规则作为退场机制,如
- 一旦笔记成功曝光,就从缓存退场
- 如果超出缓存大小,就移除最先进入缓存的笔记
- 笔记最多被召回10次,达到10次就退场
- 每篇笔记最多被保存3天,达到3天就退场
还能再细化规则,如想要扶持曝光比较低的笔记,那么可以根据笔记的曝光次数来设置规则,让低曝光的笔记在缓存中存更长时间
三大类、六条召回通道:
- 地理位置召回:用户对自己附近的人和事感兴趣
- GeoHash召回、同城召回
- 作者召回:
- 关注的作者、有交互的作者、相似的作者
- 缓存召回:把精排中排名高、但是没有成功曝光的笔记缓存起来,再多尝试几次
10、曝光过滤 & Bloom Filter
曝光过滤通常在召回阶段做,具体的方法就是用Bloom Filter(给用户曝光过等价于用户看过)
曝光过滤问题
实验表明,重复曝光同一个物品会损害用户体验(抖音、小红书);但YouTube这样的长视频就没有曝光过滤,看过的可以再推荐

在小红书,n和r的量级都是几千,暴力对比的计算量太大。实践中不做暴力对比,而是用Bloom Filter
Bloom Filter
判断一个物品ID是否在已曝光的物品集合中
- 如果判断为no,那么该物品一定不在集合中
- 如果判断为yes,那么该物品很可能在集合中(可能误伤,错误判断未曝光物品为已曝光,将其过滤掉)
概括一下:根据Bloom Filter的判断做曝光过滤,肯定能干掉所有已经曝光的物品,用户绝对不可能重复看到同一个物品;但是有一定概率会误伤,召回的物品明明没有曝光过,却被Bloom Filter给干掉了
Burton H. Bloom. Space/time trade-offs in hash coding with allowableerrors. Communications of the ACM, 1970.
Bloom Filter是一种数据结构
- 把物品集合表征为一个m维二进制向量(每个元素是一个bit,要么是0要么是1)
- 每个用户有一个曝光物品的集合,表征为一个向量,需要m bits的存储
- 有k个哈希函数,每个哈希函数把物品ID映射成介于 0~m-1 之间的整数
- k和m都是需要设置的参数
最简单的情况:k=1(只有1个哈希函数)


- 如果Bloom Filter认为没有曝光,那么这个物品肯定没有曝光(不可能把已曝光的物品误判为未曝光)
- 如果Bloom Filter认为已曝光,有可能是正确的,有可能是误判(有一定概率把未曝光物品认为已曝光,导致未曝光物品被过滤掉)
k=3,用3个不同的哈希函数把物品ID映射到3个位置上,把3个位置的元素都置为1。同样地,如果向量的某个位置元素已经是1,不需要修改数值

如果物品已经曝光,那么其3个位置肯定都是1,如果其中某个位置为0,说明该物品实际未曝光
Bloom Filter误伤的概率:


用户历史记录上有n个曝光物品,只需要 m=10n bits,就可以把误差概率降低到1%以下
推荐系统中曝光过滤的链路
- 推荐系统的链路:多路召回、粗排、精排、重排,最终选出一批物品曝光给用户
- 曝光过滤的链路:把曝光的物品记录下来,更新Bloom Filter,用于过滤召回的物品
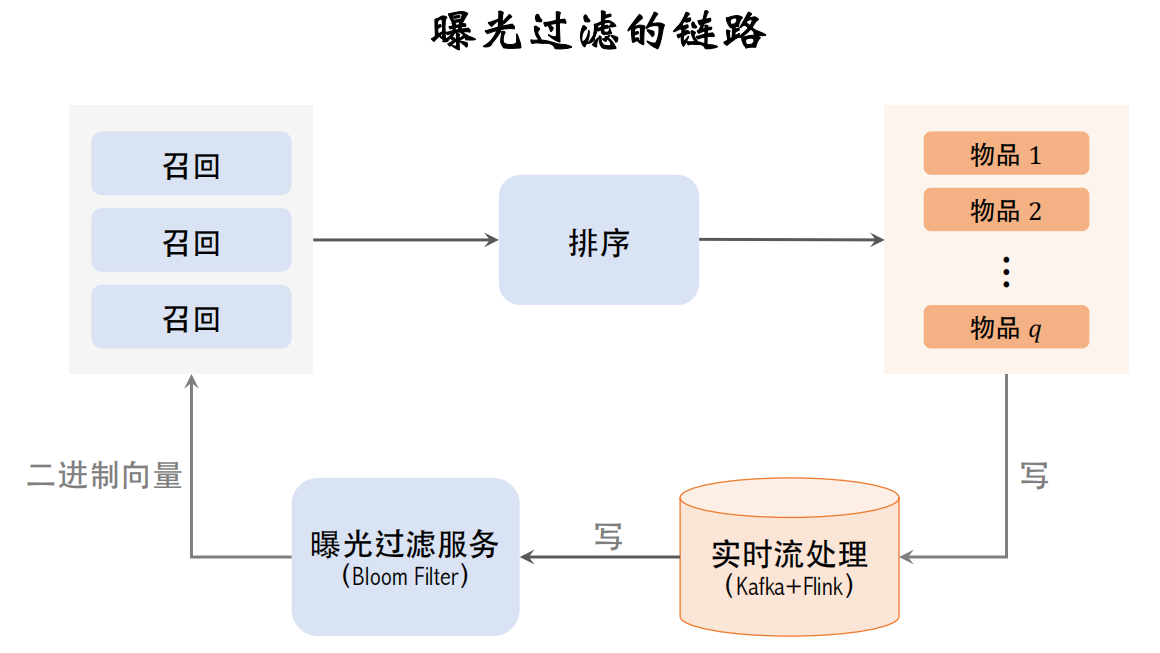
APP前端有埋点,所有曝光的物品都会被记录下来。但这个落表的速度要足够快,在用户推荐界面下一刷之前,就要把本次曝光的结果写到Bloom Filter上,否则下一刷很可能会出重复的物品,所以要用实时流处理,比如把曝光物品写入Kafka消息队列,用Flink做实时计算
Flink实时读取Kafka消息队列,计算曝光物品的哈希值,把结果写入Bloom Filter的二进制向量。用这样的实时数据链路,在曝光发生几秒之后,这位用户的Bloom Filter就会被修改,之后就能避免重复曝光
曝光过滤用在召回完成之后。召回服务器请求曝光过滤服务,曝光过滤服务把用户的二进制向量发送给召回服务器,在召回服务器上用Bloom Filter计算召回物品的哈希值,再跟二进制向量对比,把已经曝光的物品过滤掉,剩余的物品都是未曝光的,发送给排序服务器
Bloom Filter缺点

只需要计算出k个哈希值(k是哈希函数的数量)
删除物品,不能简单把这个物品对应的k个元素从1改为0,否则会影响其他物品。这是因为向量的元素是所有物品共享的,如果把向量的一个元素改为0,相当于把很多物品都移除掉了。想要删除一个物品,需要重新计算整个集合的二进制向量
推荐系统的曝光过滤问题、Bloom Filter数据结构
(三)排序
1、多目标排序模型
推荐系统的链路
- 有很多条召回通道,从几亿篇笔记中取出几千篇
- 从中选出用户最感兴趣的,要用到粗排和精排,粗排给召回的笔记逐一打分,保留分数最高的几百篇
- 然后用精排模型给粗排选出的几百篇笔记打分,不做截断,让几百篇笔记全都带着精排分数进入重排
- 重排做多样性抽样,把相似内容打散,最终有几十篇笔记被选中,展示给用户
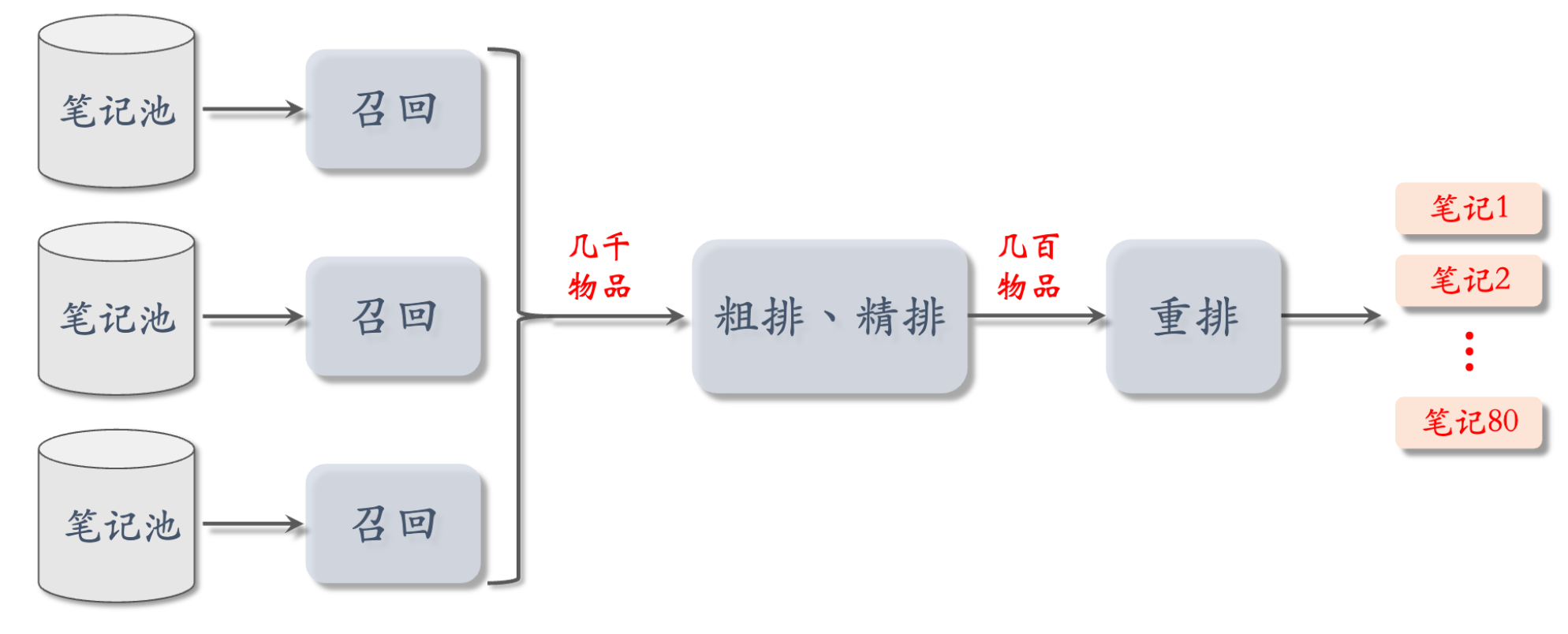
粗排、精排原理基本相同,只是粗排模型小,特征少,效果差一些,粗排的目的是做快速的初步筛选(如果不用粗排,直接把很大的精排模型用在几千篇候选笔记上,计算代价大)
排序的依据
以小红书为例,排序的主要依据是用户对笔记的兴趣,兴趣可以反映在用户与笔记的交互上。对于每篇笔记,系统记录以下统计量:
- 曝光次数(impression):一篇笔记被展示给多少用户
- 点击次数(click):一篇笔记被多少用户点开
- 点赞次数(like)
- 收藏次数(collect)
- 转发(share)
可以用点击率之类的消费指标衡量一篇笔记受欢迎的程度
- 点击率 = 点击次数 / 曝光次数
- 点赞率 = 点赞次数 / 点击次数(收藏率、转发率同理)。用户点开笔记之后才会发生点赞、收藏、转发等行为,故分母是点击次数,而不是曝光次数
排序依据:
- 在把笔记展示给用户之前,需要事先预估用户对笔记的兴趣(排序模型预估点击率、点赞率、收藏率、转发率等多种分数);
- 融合这些预估分数,比如加权和(比如点击率的权重是1,点赞率、收藏率、转发率的权重是2),权重是做ab测试调出来的;
- 根据融合的分数做排序、截断,保留分数高的笔记
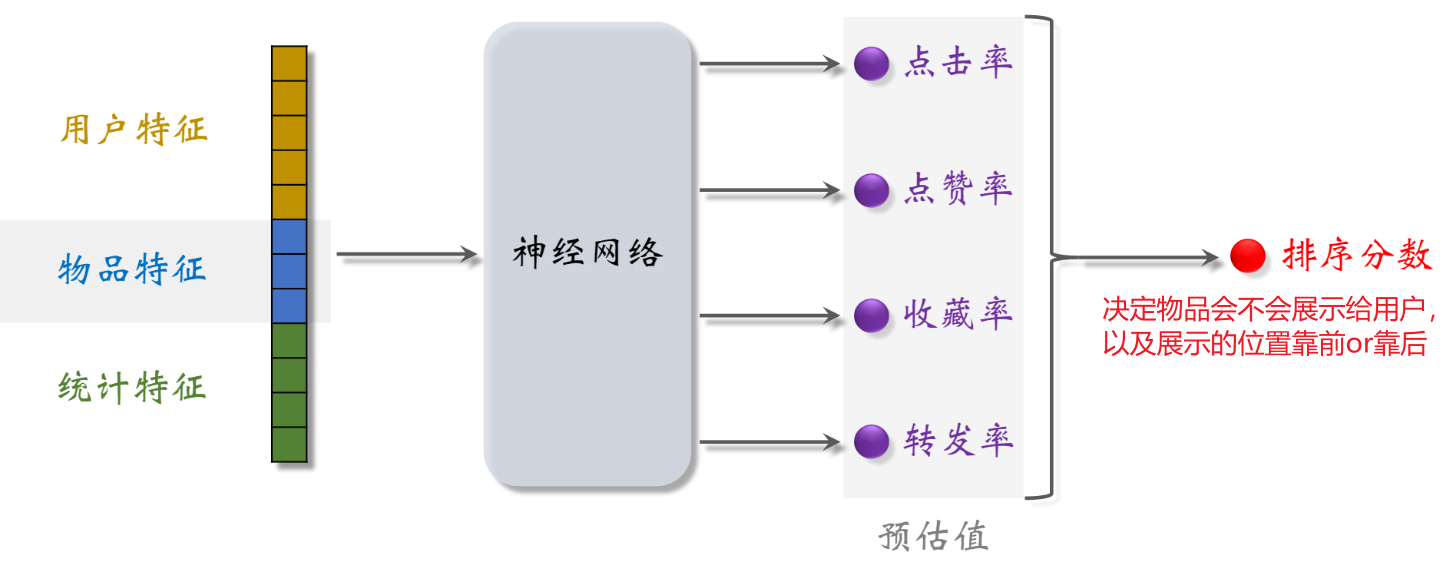
简单的多目标模型
排序模型的输入是各种各样的特征
- 用户特征:用户ID、用户画像
- 物品特征:物品ID、物品画像、作者信息(笔记的作者)
- 统计特征:
- 用户统计特征(用户在过去30天中一共曝光/点击...了多少篇笔记)
- 物品统计特征(候选物品在过去30天中一共获得了多少次曝光/点击...机会)
- 场景特征:随着用户请求传过来的,包含
- 当前时间(如当前是否是周末或节假日)
- 用户所在地点(候选物品和用户是否在同一城市)

输出4个预估值,都介于0~1之间,排序主要依靠这4个预估值
模型训练:
4个任务,每个任务都是一个二元分类,如判断用户是否会点击物品。用交叉熵损失函数
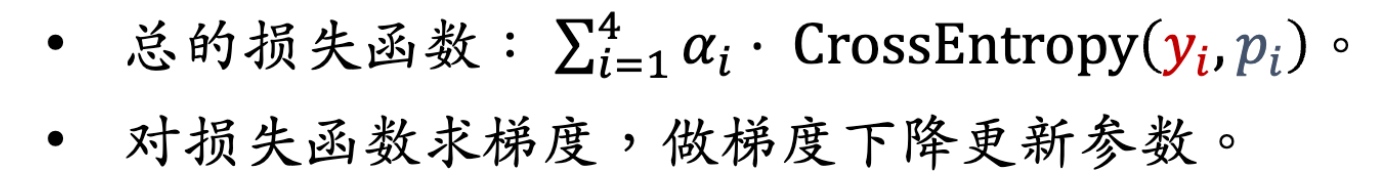
实际训练中会有很多困难,如类别不平衡(正样本少,负样本多)
- 每100次曝光,约有10次点击、90次无点击
- 每100次点击,约有10次收藏、90次无收藏
解决方案:负样本降采样(down-sampling)
- 保留一小部分负样本
- 让正负样本数量平衡,节约计算(比如原本一天积累的数据需要在集群上训练10h,做降采样后,负样本减少很多,训练只需3h)
预估值校准
给定用户特征和物品特征,用神经网络预估出点击率、点赞率等分数之后,要对这些预估分数做校准,做完校准之后才能把预估值用于排序
为什么要做校准?

α(采样率)越小,负样本越少,模型对点击率的高估就会越严重
Xinran He et al. Practical lessons from predicting clicks on ads at Facebook. In the 8th International Workshop on Data Mining for Online Advertising.

对预估点击率的校准公式:左边的 表示校准之后的点击率,右边是对预估点击率
做的变换,α为采样率
在线上做排序时,首先让模型预估点击率,然后用上述公式做校准,拿校准之后的点击率
做排序的依据
排序的多目标模型,用于估计点击率、点赞率等指标。做完预估之后,要根据负采样率对预估值做校准
2、Multi-gate Mixture-of-Experts(MMoE)
模型结构
Google的论文提出MMoE模型:Jiaqi Ma et al. Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts. In KDD, 2018.
模型的输入是一个向量,包含用户特征、物品特征、统计特征、场景特征
- 3个神经网络结构相同,都是由很多全连接层组成,但它们不共享参数
- 3个神经网络各输出一个向量,即3个“专家”(实践中通常用4个或8个。专家神经网络的数量是个超参数,需要手动调)
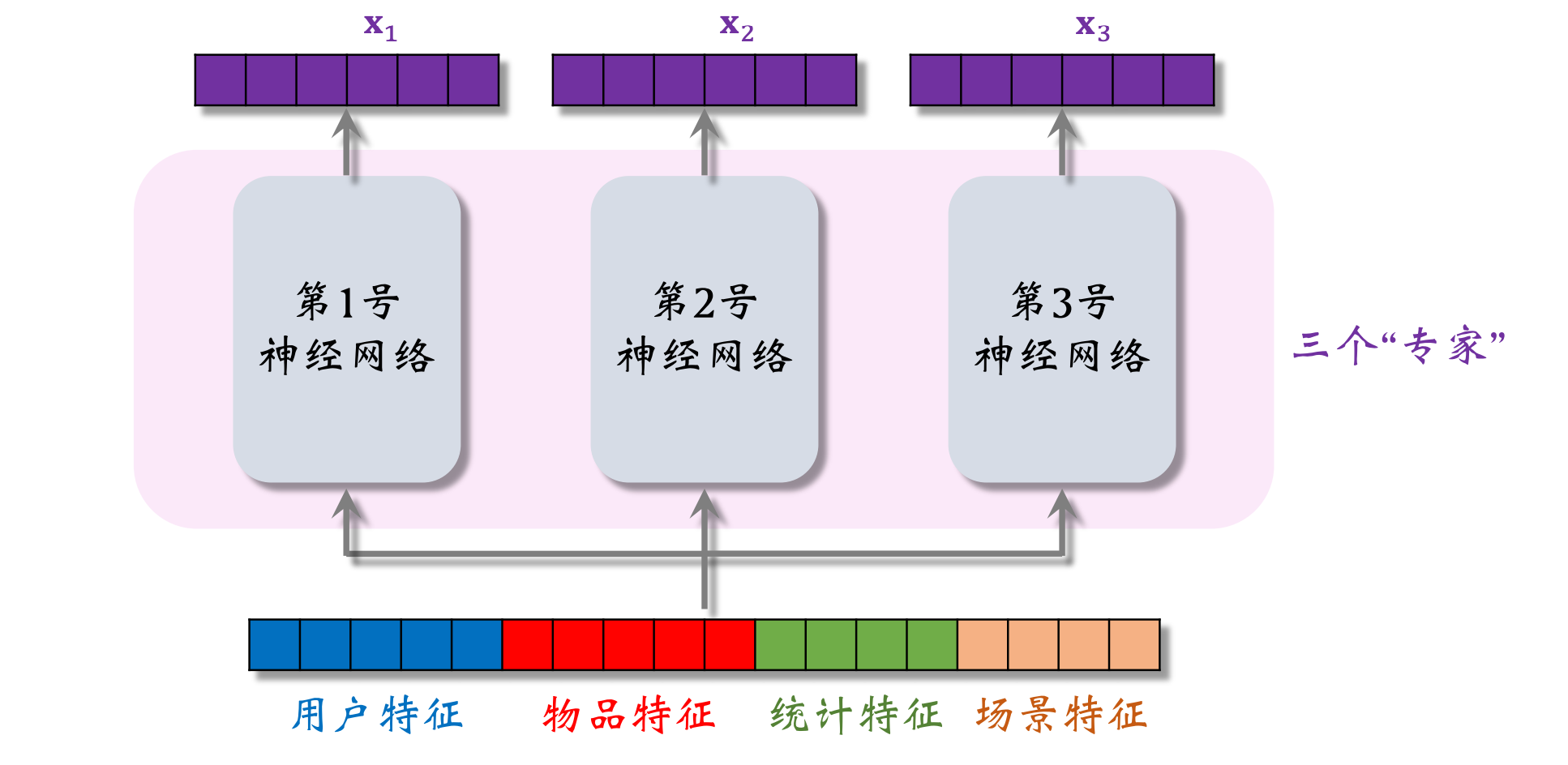
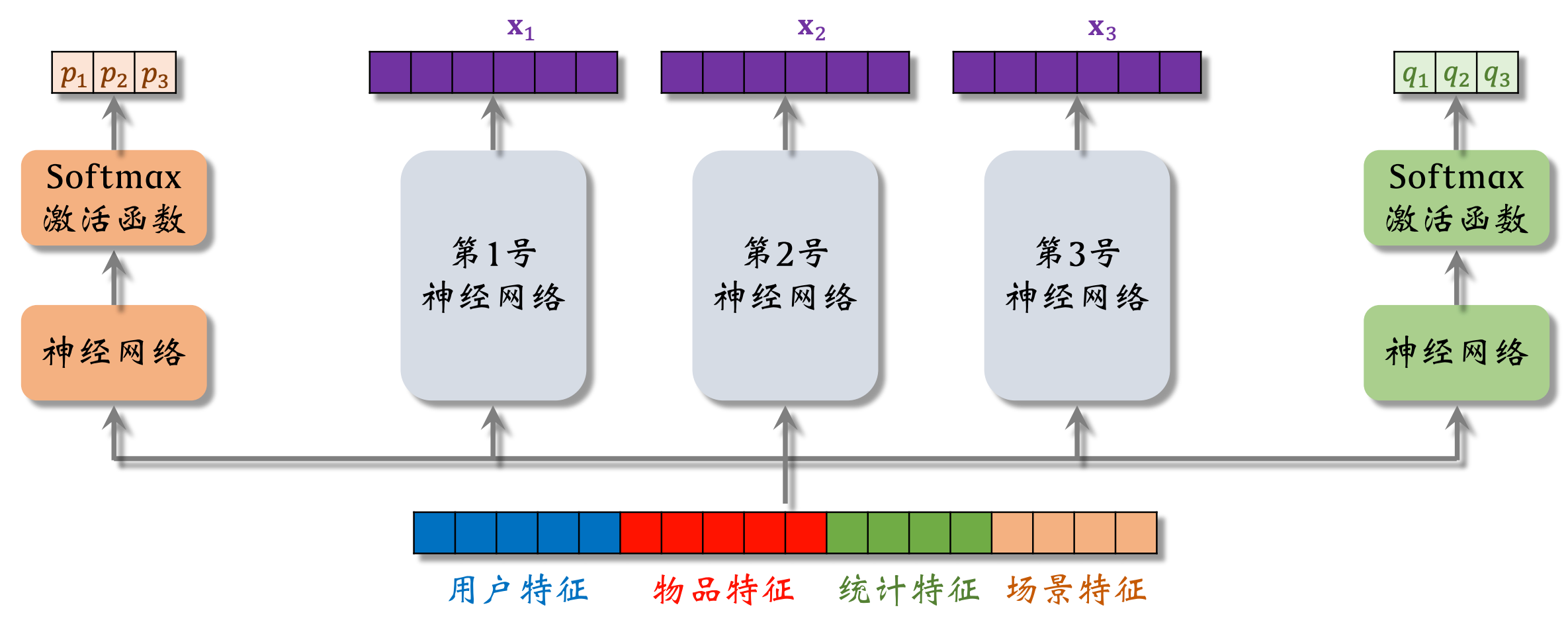
- softmax输出向量的3个元素都>0且相加为1
- p1~p3分别对应3个专家神经网络,之后会将这3个元素作为权重,对向量x1~x3做加权平均。q1~q3同理
神经网络可以有一个或多个全连接层,其输出取决于具体的任务,比如输出对点击率的预估,是一个介于0~1之间的实数

这里假设多目标模型只有点击率和点赞率两个目标,所以只有两组权重。
对神经网络输出的向量做加权平均,用加权平均得到的向量去预估某个业务指标。若多目标模型有n个目标,就要用n组权重
MMoE问题:极化现象
YouTube的论文提出极化问题的解决方案:Zhe Zhao et al. Recommending What Video to Watch Next: A Multitask Ranking System. In RecSys, 2019.
softmax会发生极化(Polarization):softmax输出值一个接近1,其余接近0
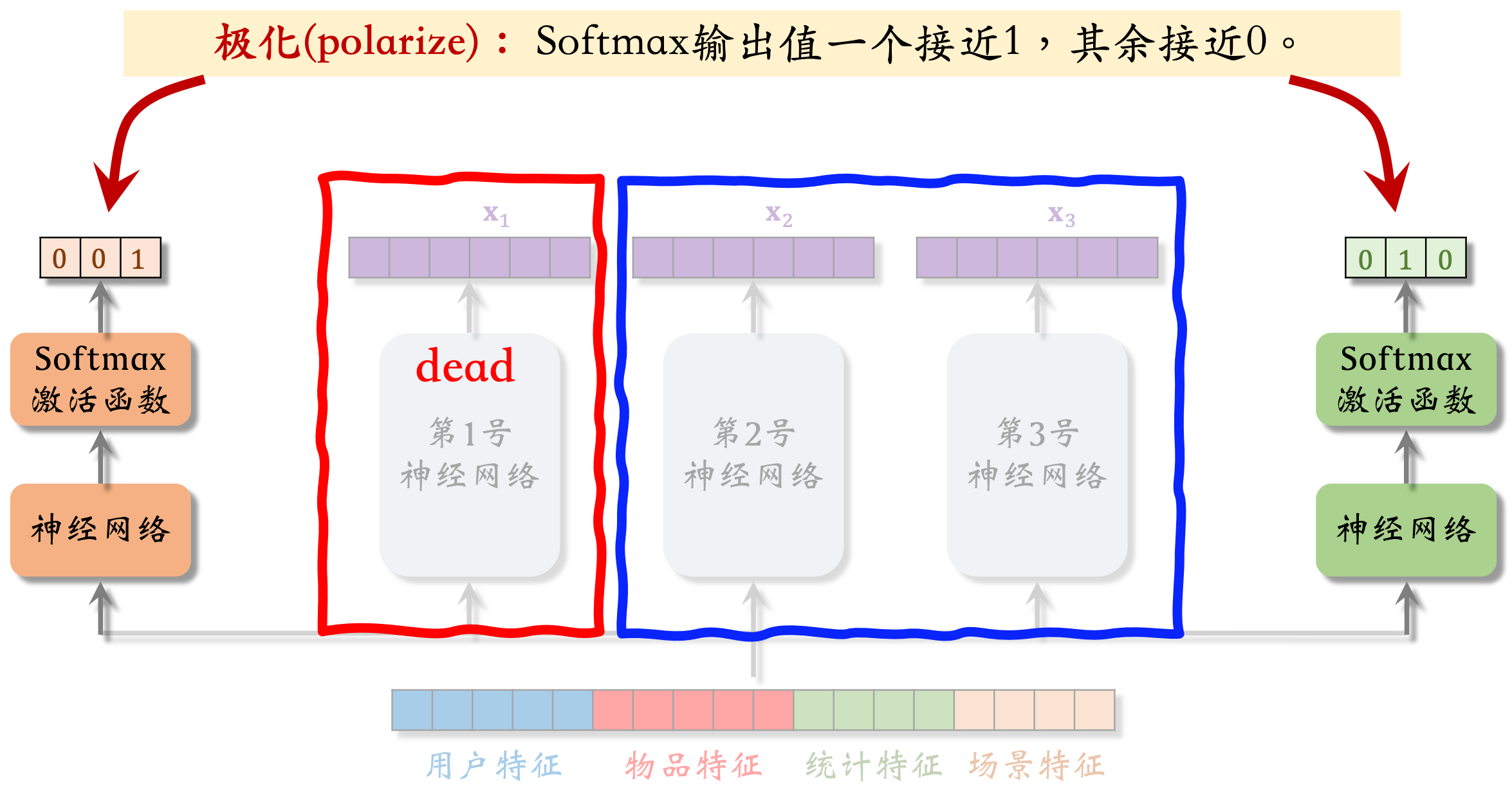
如左边softmax输出值 ≈ [0,0,1],说明左边的预估点击率任务只使用了第三号专家神经网络(没有让三个专家神经网络的输出融合,只是简单使用了一个专家)
那么MMoE就相当于一个简单的多目标模型,不会对专家做融合,失去了MMoE的优势
解决极化问题:
如果有n个专家神经网络,那么每个softmax的输入和输出都是n维向量。不希望看到其中一个输出的元素接近1,其余n-1个元素接近0
在训练时,对softmax的输出使用dropout,这样会强迫每个任务根据部分专家做预测
- softmax输出的n个数值被mask的概率都是10%
- 每个专家被随机丢弃的概率都是10%
如果用dropout,不太可能会发生极化,否则预测的结果会特别差。假如发生极化,softmax输出的某个元素接近1,万一这个元素被mask,预测的结果会错得离谱。为了让预测尽量精准,神经网络会尽量避免极化的发生,避免softmax输出的某个元素接近1。用了dropout,基本上能避免极化
用MMoE不一定会有提升,有可能是实现不够好,也有可能是不适用于特定的业务场景
3、预估分数的融合公式
多目标模型输出对点击率、点赞率等指标的预估。怎么融合多个预估分数?介绍工业界排序的几种融分公式
加权和

Pclick表示模型预估的点击率,权重为1;其他以此类推

Pclick*1就是预估的点击率,Pclick*Plike是曝光之后用户点赞的概率
海外某短视频APP的融分公式

Ptime是指预估短视频的观看时长(比如预测用户会观看10s),w1和α1都是超参数,通过线上ab选出合适的值
国内某短视频APP(快手)的融分公式
不是直接用预估的分数,而是用每个分数的排名

α和β都是需要调的超参数。预估的播放时长越长,排名越靠前,越小,最终得分就越高
某电商的融分公式

指数α1~α4是超参数,需要调。若都为1,该公式就表示电商的营收,有很明确的物理意义
4、视频播放建模
播放时长&完播率2个指标
指标1:视频播放时长
- 图文笔记排序的主要依据:点击、点赞、收藏、转发、评论...
- 视频排序的依据还有播放时长和完播
视频播放时长是连续变量,但直接用回归拟合效果不好,建议用YouTube的时长建模
Paul Covington, Jay Adams, & Emre Sargin. Deep Neural Networks for YouTube Recommendations. In RecSys, 2016.
神经网络叫做Share Bottom(被所有任务共享),每个全连接层对应一个目标(比如点击、点赞、收藏、播放时长),这里只关心播放时长的预估:

对z(实数,可正可负)做sigmoid变换得到p=sigmoid(z),让p拟合y = t / (1+t)( t表示用户实际观看视频的时长,t越大,y也越大),训练中用p和y的交叉熵作为损失函数【训练完毕后,p就没有用了】

CE(y, p) = y*logp + (1-y)*log(1-p)
可以用exp(z)作为播放时长的预估【线上做推理时,只用z的指数函数,把它作为对播放时长t的预估】
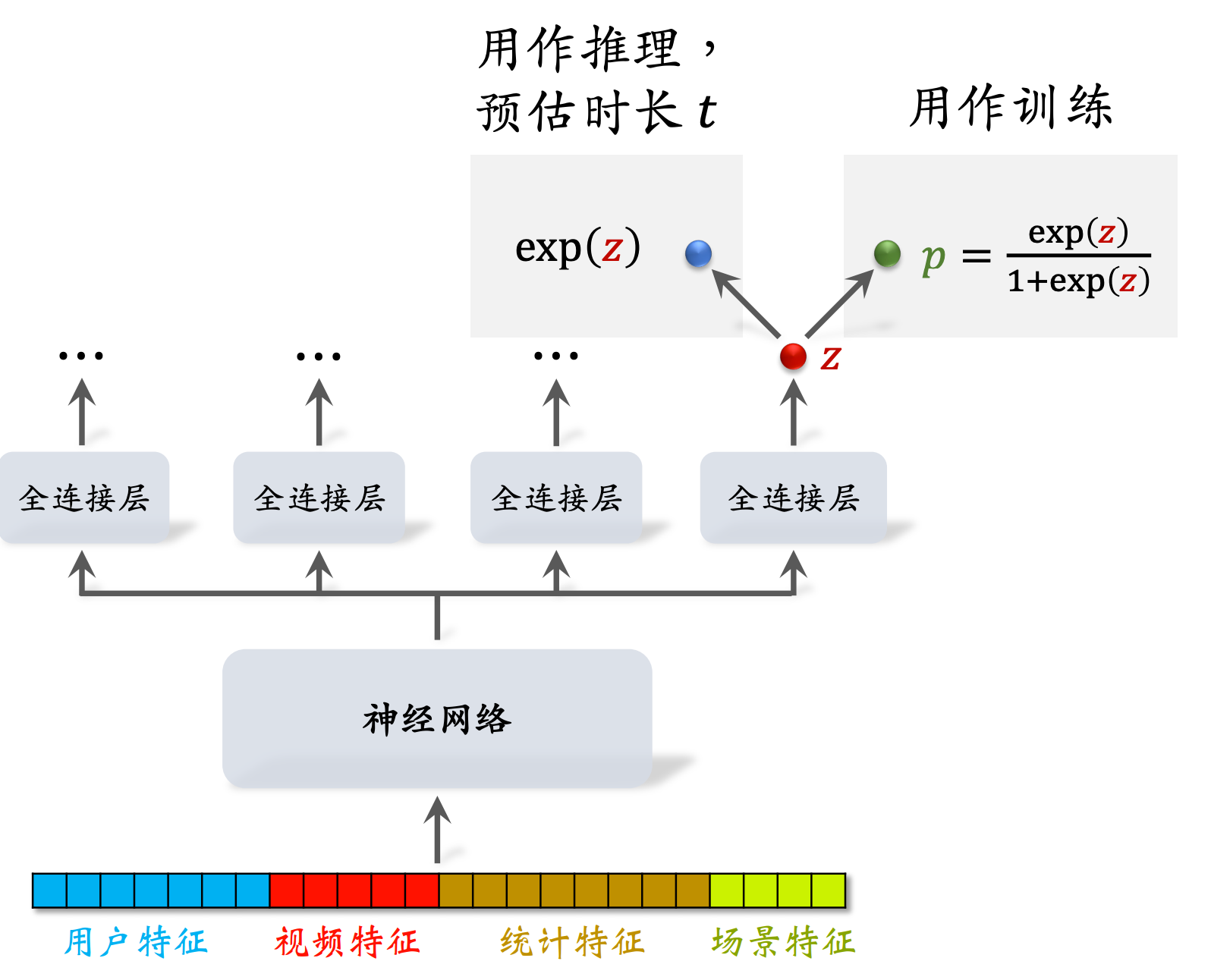
总结一下,右边的全连接层输出z,对z做sigmoid变换得到p,在训练中用p;
用y(= t / (1+t),其中t为播放时长)和p的交叉熵作为损失函数训练模型,训练完成后p就没有用了;
线上做推理时,只用z的指数函数,把它作为对播放时长t的预估
建模

实践中把分母1+t去掉也没问题,相当于给损失函数做加权,权重是播放时长
最终把exp(z)作为融分公式中的一项,它会影响到视频的排序
指标2:视频完播率
2种建模方法:回归;二元分类
回归方法

y的大小介于0~1之间
二元分类方法
需要算法工程师自己定义完播指标

预估的播放率会跟点击率等指标一起作为排序的依据

有利于短视频,而对长视频不公平

视频越长,函数值f越小,把调整之后的分数记作,可以反映出用户对视频的兴趣,而且对长、短视频是公平的
与播放时长、点击率、点赞率等指标一起,决定视频的排序
视频的排序;视频有两个独特的指标:播放时长和完播率
5、排序模型的特征
排序所需特征
用户画像特征(User Profile)
召回和排序的模型中都有用户属性,用户属性记录在用户画像中
- 用户ID(在召回、排序中做embedding)
- 用户ID本身不携带有用的信息,但作用很大,通常用32 or 64维向量
- 人口统计学属性:性别、年龄等
- 账号信息:新老(用户注册时间)、活跃度...
- 模型需要专门针对新用户和低活用户做优化
- 感兴趣的类目、关键词、品牌
- 属于用户兴趣信息,这些信息可以是用户自己填写的,也可以是算法自动提取的
笔记画像特征(Item Profile)
- 物品ID(在召回、排序中作embedding)
- 发布时间(或者年龄)
- 在小红书,一篇笔记发布时间越久,价值就越低,尤其是强时效性话题
- GeoHash(经纬度编码)、所在城市
- GeoHash表示地图上一个长方形的区域
- 标题、类目、关键词、品牌...
- 笔记的内容,通常对这些离散的内容特征做Embedding
- 字数、图片数、视频清晰度、标签数...
- 笔记自带的属性,反映出笔记的质量,笔记的点击和交互指标与之相关
- 内容信息量、图片美学...
- 算法打的分数,事先用人工标注的数据训练cv和nlp模型,当新笔记发布时,用模型给笔记打分,把分数写到物品画像中,可以作为排序模型的特征
统计特征(用户/笔记)
(1)用户统计特征:
-
用户最近30天 (7天、1天、1小时) 的曝光数、点击数、 点赞数、收藏数…
- 用各种时间粒度,可以反映出用户的实时兴趣、短期兴趣和中长期兴趣
-
按照笔记 图文/视频 分桶 (比如最近7天,该用户对图文笔记的点击率、对视频笔记的点击率)
- 对图文、视频两类笔记分开做统计,可以反映出用户对两类笔记的偏好
-
按照笔记类目分桶 (比如最近30天,用户对美妆笔记的点击率、对美食笔记的点击率、对科技数码笔记的点击率)
(2)笔记统计特征:
-
笔记最近30天 (7天、1天、1小时) 的曝光数、点击数、点赞数、收藏数…
- 统计量反映出笔记的受欢迎程度。如果点击率、点赞率等指标都很高,说明笔记质量高,算法应该给这样的笔记更多的流量
- 时间粒度是针对笔记的实效性。若笔记已经过时(如30天指标高,但1天指标低),不应该给更多的流量
- 笔记受众:按照用户性别、年龄、地域分桶
- 作者特征:发布笔记数、粉丝数、消费指标(曝光数、点击数、点赞数、收藏数)
- 作者统计特征反映了作者的受欢迎程度以及作品的平均品质
场景特征(Context)
随着推荐请求传来的,不用从用户画像、笔记画像等数据库中获取
-
用户定位GeoHash (经纬度编码) 、城市
- 用户可能对自己附近的事感兴趣
-
当前时刻 (分段,做embedding)
- 一个人在同一天不同时刻的兴趣可能有所区别
- 是否是周末或节假日
-
周末或节假日用户可能对特定的话题感兴趣
-
-
手机品牌、手机型号、操作系统
- 安卓or苹果
特征处理
离散特征:做embedding
- 用户ID、笔记ID、作者ID(数量大,消耗内存大)
- 类目、关键词、城市、手机品牌
连续特征:做分桶,变成离散特征
- 年龄(如把连续的年龄变为十个年龄段,做one-hot或Embedding)、笔记字数、视频长度
连续特征:其他变换
- 曝光数、点击数、点赞数等数值做log(1+x),可以解决异常值问题
- 曝光数等(大多数笔记只有几百次,少数笔记能有上百万次)为长尾分布,计算会出现异常(训练梯度会很离谱,推理的预估值会很奇怪)
- 或者把点击数、点赞数等转化为点击率、点赞率等值,并做平滑(去掉偶然性造成的波动)
- 实际处理中,两种变换之后的连续特征都会作为模型的输入,如log(1+点击数)、平滑之后的点击率都会被用到
特征覆盖率
特征工程需要注重特征覆盖率
- 理想情况下,每个特征都能覆盖100%样本,即不存在特征缺失
- 但实际很多特征无法覆盖100%样本,例:
-
很多用户不填年龄,因此用户年龄特征的覆盖率远小于100%
-
很多用户设置隐私权限,APP不能获得用户地理定位,因此场景特征有缺失
-
提高特征覆盖率,可以让精排模型更准;另外还要考虑,当特征缺失时,用什么作为默认值
数据服务(线上服务的简化版系统架构)
- 用户画像(User Profile)
- 物品画像(Item Profile)
- 统计数据
以上3个数据源都存储在内存数据库中。线上服务时,排序服务器会从3个数据源取回所需的数据,然后把读取的数据做处理,作为特征喂给模型,模型就能预估出点击率、点赞率等指标

当用户刷小红书时,用户请求会被发送到推荐系统的主服务器上,主服务器会把请求发送到召回服务器上。做完召回后,召回服务器会把几十路召回的结果做归并,把几千篇笔记的ID返回给主服务器(召回需要调用用户画像)
主服务器把笔记ID、用户ID、场景特征(1个用户ID+几千个笔记ID。笔记ID是召回的结果,用户ID和场景特征都是从用户请求中获取的,场景特征包括当前时刻、用户所在地点以及手机的型号和操作系统)发送给排序服务器

接下来,排序服务器要从多个数据源中取回排序所需的特征,主要是这3个数据源:用户画像、物品画像、统计数据
- 用户画像数据库线上压力小,因为每次只读1个用户的特征
- 性别、年龄几乎不变
- 用户活跃度、兴趣标签等为天级别的刷新
- 物品画像数据库压力大,因为粗排要给几千篇笔记排序,读取几千篇笔记的特征
- 物品自身属性、算法给物品打的标签在很长一段时间内不会发生变化
对用户画像和物品画像最重要的是读取速度快,而不太需要考虑时效性,因为它们都是静态的,甚至可以储存在排序服务器本地,让读取变得更快
- 统计数据:存用户统计值的数据库压力小,存物品统计值的数据库压力大
- 统计数据不能在本地缓存,因为它动态变化,时效性很强
在收集到排序所需的特征之后,排序服务器把特征打包传给TF Serving。TensorFlow会给笔记打分,把分数返回给排序服务器,排序服务器会用融合的分数、多样性分数、业务规则给笔记排序,把排名最高的几十篇笔记返回给主服务器,这就是最终给用户曝光的笔记
6、粗排模型
粗排 vs 精排

粗排牺牲准确性,以保证线上推理的速度快(目的是做初步筛选,从几千篇笔记中选出几百篇,而不是真正决定把哪些笔记曝光给用户);精排的模型足够大,牺牲更多的计算,确保预估的准确性足够高
精排模型 & 双塔模型

Shared Bottom含义为被多个任务共享【精排模型的代价主要在这,因为它很大,神经网络也很复杂】
精排模型属于前期融合(先对所有特征做concatenation,再输入神经网络),但线上推理代价大(如果有n篇候选笔记,整个大模型要做n次推理)
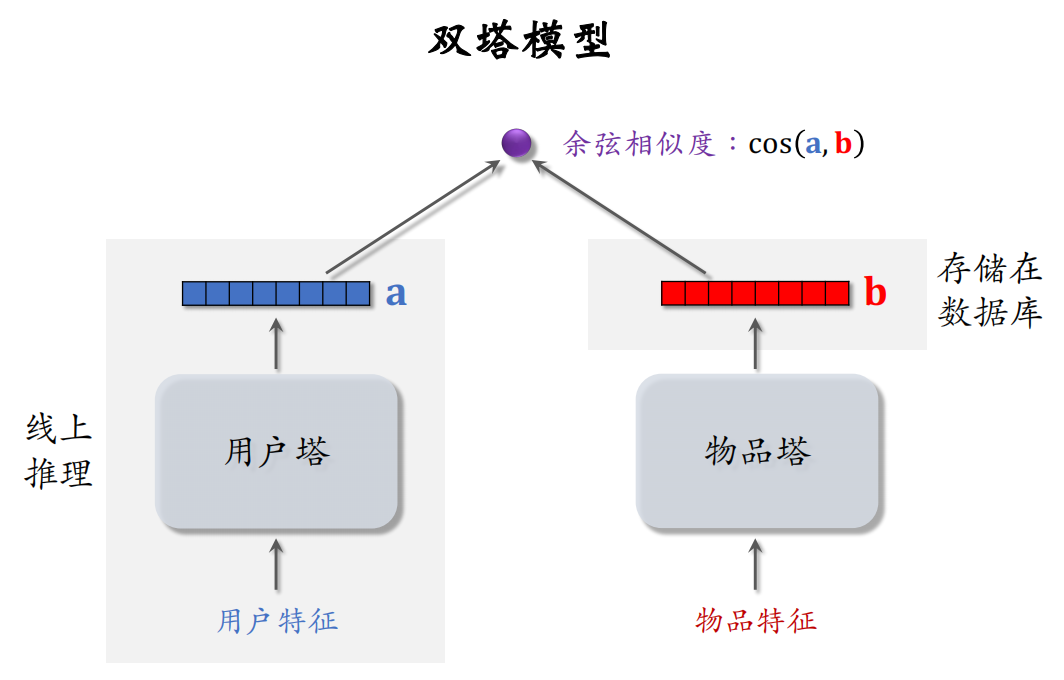
两个向量的余弦相似度表明用户是否对物品感兴趣
在训练好模型之后,把物品向量b存储在向量数据库,在线上不需要用物品塔做计算。线上推理只需要用到用户塔,每做一次推荐,用户塔只做一次推理,计算出一个向量a【双塔模型的计算代价很小,适合做召回】
双塔模型属于后期融合(把用户、物品特征分别输入不同的神经网络,不对用户、物品特征做融合,直到最后才计算a和b的相似度),线上计算量小(用户塔只需要做一次线上推理,计算用户表征a;物品表征b事先储存在向量数据库中,物品塔在线上不做推理),但预估准确性不如精排模型
粗排的三塔模型
小红书的粗排是三塔模型,效果介于双塔和精排之间
借鉴【阿里妈妈】Zhe Wang et al. COLD: Towards the Next Generation of Pre-Ranking System. In DLP- KDD , 2020

交叉特征是指用户特征和物品特征做交叉
训练粗排模型的方法就是正常的端到端训练,跟精排完全一样
三塔模型介于前期融合(把底层特征做concatenation)和后期融合之间,是把三个塔输出的向量做concatenation

- 物品的属性相对比较稳定,可以把物品塔输出向量缓存在PS,每隔一段时间刷新一次。由于做了缓存,物品塔在线上几乎不用做推理,只有遇到新物品时才需要做推理。粗排给几千个物品打分,物品塔实际只需要做几十次推理,所以物品塔的规模可以比较大
- 统计特征会实时动态变化(每当一个用户发生点击等行为,其统计特征都发生变化;每当一个物品获得曝光和交互,其点击次数、点击率等指标都会发生变化)。由于交叉塔的输入会实时发生变化,不应该缓存交叉塔输出的向量,交叉塔在线上的推理避免不掉,故交叉塔必须足够小、计算够快(通常来说交叉塔只有一层,宽度也比较小)
模型的上层结构:

模型上层做n次推理,代价大于交叉塔的n次推理
三塔模型的线上推理

- 物品塔输出的向量事先缓存在Parameter Server上,只有当没有命中缓存时,才需要物品塔做推理(实际上缓存命中率非常高,99%的物品都能命中缓存,不需要做推理。给几千个候选物品做粗排,物品塔只需要做几十次推理)
- 交叉塔的输入都是动态特征,不能做缓存
- 三个塔各输出一个向量,融合起来作为上层网络的输入
粗排大部分的计算量都在上层网络
粗排模型的设计理念:尽量减小推理的计算量,使得模型可以在线上给几千篇笔记打分