目录
目录
一、随机森林简介
(一)随机森林模型的基本原理如下:
(二)随机森林模型的优点包括:
(三)森林中的树的生成规则如下:
(四)在随机森林中,每棵树都使用不同的训练集进行训练,原因如下
随机森林的分类性能(即错误率)受以下两个关键因素影响:
参数介绍
二、导入数据集
三、对数据进行独热编码转换
四、选择特征x和标签y
五、导入随机森林模块并实例化
六、网格搜索法查找最优参数
一、随机森林简介
随机森林(Random Forest)是一种集成学习(Ensemble Learning)方法,由 Leo Breiman 在2001年提出。随机森林是一种决策树(Decision Tree)的集成,它通过构建许多决策树并结合它们的预测结果来提高模型的准确性和稳定性。
(一)随机森林模型的基本原理如下:
个体模型(Base Estimator):随机森林使用决策树作为基本的学习单元。每个决策树都是一个独立的分类或回归模型。
特征子集(Random Subspace):在构建每棵树时,随机森林从原始特征集中随机抽取一个子集,这个子集的大小通常小于全部特征数。这样可以减少特征之间的相关性,提高模型的多样性。
样本子集(Bootstrap Aggregating,Bagging):在构建每棵树时,随机森林使用从原始样本集中随机抽取的子集(Bootstrap样本),这称为自助采样(Bootstrap Sampling)。这样可以减少模型对训练数据的依赖,提高模型的稳健性。
随机性(Randomness):除了特征子集和样本子集,随机森林在每个节点分裂时也会随机选择一个最优特征进行分裂,进一步增加了模型的随机性。
集成预测:最后,随机森林通过投票(对于分类问题)或平均(对于回归问题)来确定最终的预测结果,这提高了模型的预测性能和泛化能力。
(二)随机森林模型的优点包括:
- 可以处理高维数据和大量特征。
- 可以处理缺失值。
- 自动进行特征选择,通过特征的重要性评估。
- 不容易过拟合,因为多个决策树的随机性和多样性有助于降低过拟合的风险。
随机森林广泛应用于各种机器学习任务,如分类、回归、特征选择和异常检测等,特别是在数据具有复杂关系和非线性关系的情况下,表现得尤为出色。
(三)森林中的树的生成规则如下:
1)对于每棵树,我们使用bootstrap sample方法从训练集中随机且有放回地抽取N个训练样本作为该树的训练集。这样可以确保每棵树都有不同的训练数据,从而提高了模型的多样性。
2)在每个样本的特征维度为M的情况下,我们指定一个常数m(m远小于M),并从M个特征中随机选取m个特征子集。每次树进行分裂时,我们从这m个特征中选择最优的特征进行分裂。这种方法可以降低模型的复杂度,提高计算效率。
3)每棵树都尽最大程度的生长,并且没有剪枝过程。这样可以让每棵树尽可能地拟合训练数据,从而提高模型的预测能力。同时,由于我们使用了bootstrap sample方法和随机特征选择,所以即使没有剪枝过程,也不会导致过拟合问题。
(四)在随机森林中,每棵树都使用不同的训练集进行训练,原因如下
1)随机抽样训练集:如果不进行随机抽样,那么每棵树的训练集都会完全相同,导致所有树的分类结果也都会相同。这样,整个模型就失去了集成学习的意义,因为集成学习的核心在于通过结合多个不同的模型来提高整体的预测性能。
2)有放回地抽样:如果采用无放回的抽样,每棵树的训练样本将完全不同,这会导致每棵树都是从一个“片面”的视角进行学习,从而使得每棵树的预测结果存在较大的差异。随机森林的最终预测是通过对多棵树的预测结果进行投票或平均得到的,这种“求同”的策略旨在综合多个模型的观点,以获得更准确、更稳定的预测。因此,使用完全不同的训练集来训练每棵树并不利于最终的分类结果,这类似于“盲人摸象”,每个模型只了解问题的一部分,无法全面地理解问题。
通过有放回地重新抽样,我们可以确保每棵树的训练集都有所不同,但同时又有一定的重叠,这样既保证了模型的多样性,又使得每棵树都能从整体上对问题有一个较为全面的理解。这种策略有助于提高随机森林的整体预测性能,使其更加稳健和可靠。
随机森林的分类性能(即错误率)受以下两个关键因素影响:
1)森林中任意两棵树的相关性:如果森林中的决策树之间具有较高的相关性,这意味着它们在对数据进行分类时往往会出现相似的错误,从而无法通过集成方法有效地降低错误率。因此,树与树之间的相关性越高,整个森林的错误率也就越大。
2)森林中每棵树的分类能力:另一方面,如果森林中的每一棵树都具备较强的分类能力,那么整个森林在集成这些树的预测结果时,错误率自然会降低。因此,提高单棵树的分类能力对于降低整个森林的错误率至关重要。
为了优化随机森林的性能,需要在保持树与树之间低相关性的同时,确保每棵树都具有较强的分类能力。这可以通过调整随机森林的参数来实现,例如增加树的数量、调整树的深度、改变叶节点的最小样本数等。通过精细地调整这些参数,可以在降低模型错误率的同时,提高其整体的泛化能力。
关键点:
减小特征选择个数m,树的相关性和分类能力也会相应的降低;增大m,两者也会随之增大。所以关键是如何选择最优的m(或者是范围),这也是随机森林唯一的一个参数。
参数介绍
RandomForestClassifier(n_estimators=10, criterion=’gini’, max_depth=None,
min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0,
max_features=’auto’, max_leaf_nodes=None, min_impurity_decrease=0.0,
min_impurity_split=None, bootstrap=True, oob_score=False, n_jobs=1,
random_state=None,verbose=0, warm_start=False, class_weight=None)
参数介绍参考了机器学习5—分类算法之随机森林(Random Forest)_随机森林分类-CSDN博客 这篇博客
n_estimators:数值型取值
含义:森林中决策树的个数,默认是10
criterion:字符型取值
含义:采用何种方法度量分裂质量,信息熵或者基尼指数,默认是基尼指数max_features: 通常情况下取值为int型, float型。
含义:用于控制在构建每棵决策树时从原始特征集中随机选择的特征子集的大小。
int:表示在构建每棵决策树时从全部特征中随机选择的特征数。例如,如果max_features=4,则每棵决策树在构建时从全部特征中随机选择 4 个特征。
float:表示在构建每棵决策树时从全部特征中随机选择的特征数的比例。例如,如果max_features=0.5,则每棵决策树在构建时从全部特征中随机选择 50% 的特征。max_depth:int型取值或者None,默认为None
含义:树的最大深度min_samples_split:int型取值,float型取值,默认为2
含义:分割内部节点所需的最少样本数量
int:如果是int值,则就是这个int值
float:如果是float值,则为min_samples_split * n_samplesmin_samples_leaf:int取值,float取值,默认为1
含义:叶子节点上包含的样本最小值
int:就是这个int值
float:min_samples_leaf * n_samplesmin_weight_fraction_leaf : float,default=0.
含义:能成为叶子节点的条件是:该节点对应的实例数和总样本数的比值,至少大于这个min_weight_fraction_leaf值max_leaf_nodes:int类型,或者None(默认None)
含义:最大叶子节点数min_impurity_split:float取值
含义:它用于控制决策树的早停规则。具体来说,这个参数定义了一个节点在分裂之前必须达到的最小不纯度阈值。在决策树的构建过程中,如果一个节点的信息增益(或基尼不纯度减少)小于
min_impurity_split设定的阈值,那么这个节点将不再进行分裂,而是被视为一个叶节点。这样做的目的是为了防止树的过度生长,从而减少过拟合的风险。需要注意的是,在较新的 scikit-learn 版本中,
min_impurity_split参数已经被弃用,取而代之的是min_impurity_decrease参数。min_impurity_decrease的工作原理与min_impurity_split类似,但它考虑了分裂后每个子节点的样本数,提供了更精细的控制。min_impurity_decrease:float取值,默认0.
含义:这个参数定义了一个节点在分裂之前必须达到的最小不纯度减少量。bootstrap:布尔类型取值,默认True
含义:是否采用有放回式的抽样方式oob_score:布尔类型取值,默认False
含义:是否使用袋外样本来估计该模型大概的准确率它在随机森林模型训练时启用或禁用一种称为“袋外(Out-of-Bag,OOB)估计”的特性。
当
oob_score=True时,随机森林在构建过程中,每次建立树时都会随机抽取一部分样本(通常为样本总数的一定比例,如 1/3)作为验证集,剩下的样本用于训练。这样,每个决策树都会有一部分样本(即“袋外”样本)在训练过程中未被使用。在每个决策树训练完成后,可以使用袋外样本来评估该树的性能,比如计算准确率、精确率、召回率等。通过所有决策树的袋外样本评估,我们可以得到一个整体的模型性能估计,即
oob_score。这对于评估模型的泛化能力、选择合适的参数,以及防止过拟合非常有帮助。oob_score是一种无监督的模型评估方法,因为它不需要额外的验证集。请注意,
oob_score可能会消耗额外的计算资源,尤其是在数据集很大或者树的数量很多时。如果计算资源有限,可能需要权衡是否开启这个参数。也就是说
OOB(Out-of-Bag)评估方法不需要额外的数据集来评估模型的性能。
在训练一些机器学习模型时,我们通常需要将数据集分成训练集和验证集(或测试集)。训练集用于训练模型,而验证集用于评估模型的性能。这种方法被称为监督式学习(supervised learning),因为我们需要事先知道输入和输出之间的关系。
然而,OOB评估方法不需要额外的数据集,因为它在训练过程中自动地将一部分数据抽出作为袋外样本。这些袋外样本在训练过程中没有被使用,因此可以用作评估模型性能。这种评估方法不需要额外的数据集,也不需要事先知道输入和输出之间的关系,因此被称为无监督的(unsupervised)。
总之,OOB评估方法是一种在训练过程中自动生成袋外样本的方法,可以用来评估随机森林模型的性能,而无需额外的数据集。
n_jobs:int类型取值,默认1
含义:拟合和预测过程中并行运用的作业数量。如果为-1,则作业数设置为处理器的core数。
n_jobs是随机森林模型中的一个参数,用于控制并行计算的数量。在训练随机森林模型时,会构建多个决策树。如果
n_jobs的取值大于 1,则会尝试使用多个 CPU 核心来并行构建这些决策树,从而加速训练过程。具体来说,n_jobs参数指定了可以并发执行的 CPU 核心数量。如果
n_jobs的取值为 -1,则表示使用所有可用的 CPU 核心。如果n_jobs的取值为 1,则表示不使用并行计算,只使用一个 CPU 核心来训练模型。需要注意的是,如果
n_jobs的取值大于 1,则可能会增加内存使用量,因为每个 CPU 核心都需要保留一份模型的副本。因此,如果内存有限,可以尝试降低n_jobs的取值,以减少内存使用量。重要:
class_weight:dict, list or dicts, "balanced"
含义:class_weight是一个用于处理不平衡数据集的参数。它用于指定分类任务中各个类别的权重,从而帮助模型更好地学习不平衡数据集中的信息。在不平衡数据集中,某些类别的样本数量可能远远少于其他类别,这可能导致模型在训练过程中更倾向于预测样本数量较多的类别,而忽略样本数量较少的类别。为了解决这个问题,可以使用
class_weight参数来为不同类别分配不同的权重,使得模型在训练过程中更加关注样本数量较少的类别。
class_weight参数的取值可以是一个字典,其中键是类别标签,值是对应的权重。例如,如果数据集中有两个类别,类别标签分别为 0 和 1,可以使用以下方式指定权重:class_weight = {0: 1, 1: 2}
如果没有给定这个值,那么所有类别都应该是权重1
对于多分类问题,可以按照分类结果y的可能取值的顺序给出一个list或者dict值,用来指明各类的权重。
class_weight参数允许用户为不同的类别设置不同的权重,以此来调整模型对各个类别的关注度。当class_weight被设置为'balanced'时,模型会自动调整权重,使得权重与每个类别的样本数成反比。具体来说,如果类别i的样本数为n_i,那么类别i的权重w_i将按照以下公式计算:w_i = n_samples / (n_classes * n_i)
其中n_samples是总样本数,n_classes是类别总数。"balanced_subsample"模式和"balanced"模式类似,只是它计算使用的是有放回式的取样中取得样本数,而不是总样本数
二、导入数据集
import pandas
data = pandas.read_csv('随机森林.csv',
encoding='utf8',
engine='python')
三、对数据进行独热编码转换
import pandas as pd
df = pd.get_dummies(data, columns=['性别',"父母鼓励"])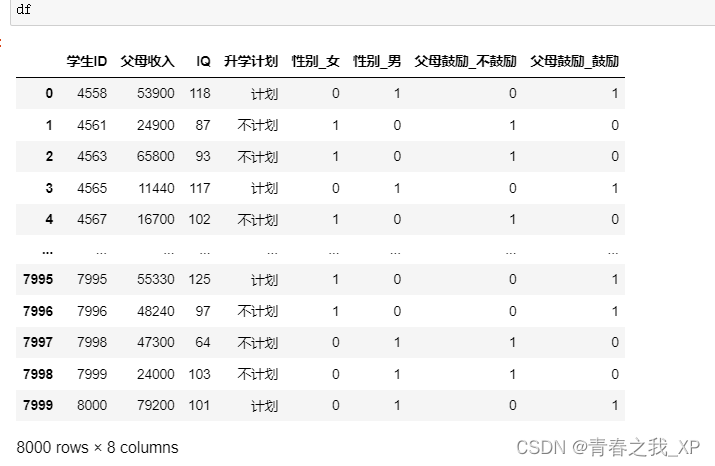
四、选择特征x和标签y
x=df.drop(["升学计划"],axis=1)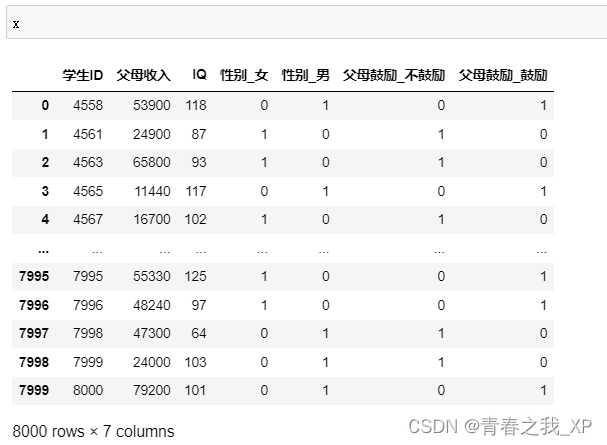
data['升学计划'] = data['升学计划'].replace({'计划': 1, '不计划': 0})
y=data["升学计划"]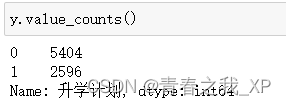
五、导入随机森林模块并实例化
from sklearn.ensemble import RandomForestClassifier
rfClassifier = RandomForestClassifier()六、网格搜索法查找最优参数
from sklearn.model_selection import GridSearchCV
#网格搜索,寻找最优参数
paramGrid = dict(
max_depth=[1, 2, 3, 4, 5],
criterion=['gini', 'entropy'],
max_leaf_nodes=[3, 5, 6, 7, 8],
n_estimators=[10, 50, 100, 150, 200], # n_estimators为随机森林使用的树的数量,默认是100
)
gridSearchCV = GridSearchCV(
rfClassifier, paramGrid,
cv=10, verbose=1, n_jobs=10, # verbose 执行过程中调试信息的等级,等级越高,输出信息越多。n_jobs 并行运算的模型数,默认为1,可根据CPU设置
return_train_score=True # 是否返回训练得分
)
grid = gridSearchCV.fit(df, y)
print('最好的得分是: %f' % grid.best_score_)
print('最好的参数是:')
for key in grid.best_params_.keys():
print('%s=%s'%(key, grid.best_params_[key]))







![[ACL 2024 Main] StickerConv: 从零开始的多模态共情回复生成](https://img-blog.csdnimg.cn/direct/b3cb03ccd6cc4f91a01aee944a77ad2e.png)



![Fastjson 反序列化漏洞[1.2.24-rce]](https://img-blog.csdnimg.cn/direct/16fd4bba409c400e82294be5e07e692a.png)