Redis知识点
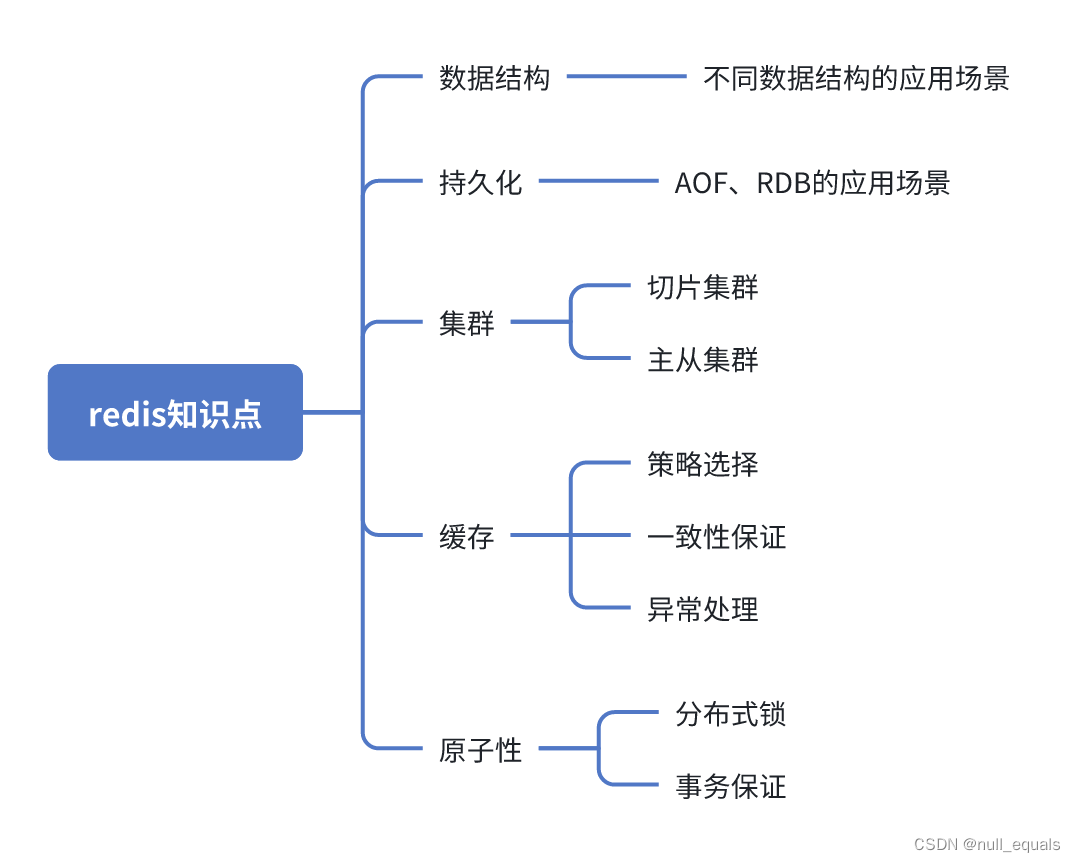
- Redis的RDB和AOF机制各是什么?它们有什么区别?
答:Redis提供了RDB和AOF两种数据持久化机制,适用于不同的场景。
RDB是通过在特定的时刻对内存中的完整的数据复制快照进行持久化的。
RDB工作原理:
- 当执行RDB持久化时,redis会调用fork方法,创建一个子线程,子线程会将内存中数据复制到快照文件中,当快照写完之后,会替换旧的RDB文件。
- RDB在执行持久化时,不会影响主线程对redis的操作,读和写,对用户无感。
优点: - RDB文件只保存内存快照,通常用于快速灾难恢复
- RDB文件由于是子线程来处理的,对性能影响较小
缺点: - RDB文件每次保存的都是全量的内存快照,数据量大时,比较耗时,并且会有大量的IO操作。
- 如果两次RDB之间发生故障,数据无法通过RDB快照恢复。
AOF是通过记录操作日志的方式进行持久化的。在redis重启后,AOF文件会进行操作重放来保证数据不丢失。
AOF工作原理: - 每执行一个写操作,就会在AOF文件的末尾追加一条
- AOF文件可以根据配置进行重写,重写后可以去除一些无效的或过期的指令
- redis提供了三种不同的AOF刷新策略,从不同步、每秒同步、每次都同步。从不同步会依赖操作系统的刷盘策略,每隔30s刷一次。三种不同的策略会影响redis操作的性能,可以根据业务需求来配置写策略。
优点: - 记录比较详细,通过配置能够保证数据尽可能的不丢失或只丢失1s
缺点: - AOF文件通常比RDB文件大很多,并且处理速度更慢,
- AOF刷新速度可能会影响redis的性能。
区别: - 数据安全性:AOF提供了更好的数据安全性,能够最小化数据丢失的风险。
- 性能影响:RDB对系统性能的影响较小,尤其适用于较大的数据集。
- 数据恢复速度:RDB可以更快地进行数据恢复,因为它是直接读取单一的数据文件。
- 文件大小和处理速度:AOF文件在没有重写的情况下可能会变得非常大,且处理速度较慢。
在实际应用中,根据需求,可以单独使用RDB或AOF,或者将两者结合使用,以此来平衡性能与数据安全性的需求。
-
Redis是单线程架构吗?为什么单线程还这么快?
redis的主线程是单线程的,主线程主要完成从请求读取、解析、键值对操作、返回结果。redis运行时也会有子进程来和其它的线程来执行主线程之外的其它的事,比如RDB快照文件生成。
redis在6.0引入了多IO线程来处理网络请求的读和写,在多核机器上能提高网络性能。
单线程能够有效的减少线程上下文的切换,避免了锁的开销。
内存操作、高效的数据结构、事件驱动模型、优化的命令执行也是其性能高的原因。 -
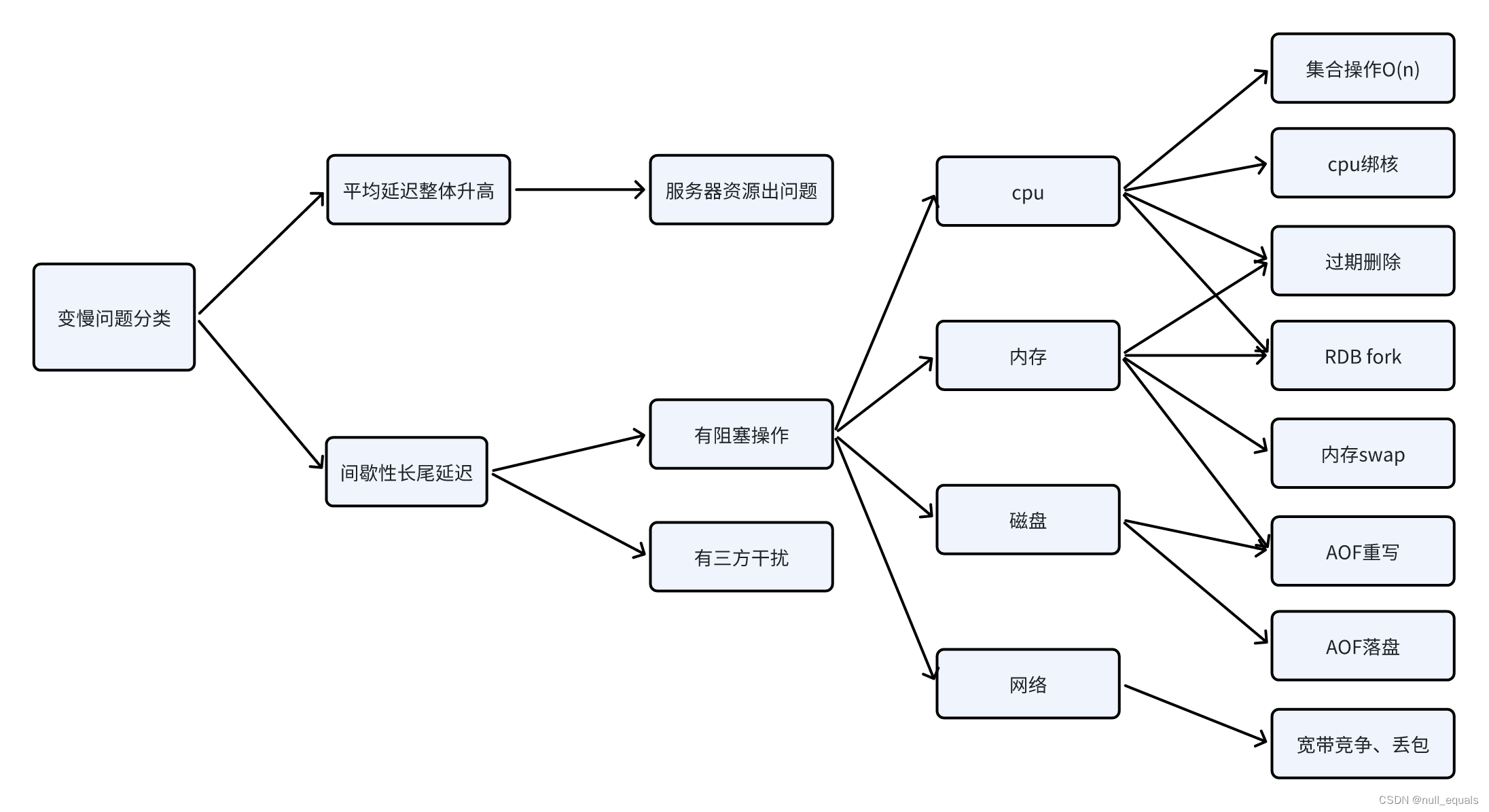
redis实例在运行时变慢了,该怎么办?
看哪里有阻塞,可以从cpu、内存、磁盘、网络来排查
-
什么是缓存雪崩、缓存击穿、缓存穿透?如何解决
- 缓存雪崩:缓存雪崩是指在缓存层面出现大面积的缓存失效的情况,导致大量的请求直接落到数据库上,从而引起数据库性能急剧下降,甚至宕机。缓存雪崩的解决方法是在设置过期时间时加一个随机数。
- 缓存击穿:缓存击穿指一个热点key(大量并发访问)在缓存中失效的瞬间,导致大量请求直接击穿缓存访问数据库,可能会使数据库瞬间压力剧增。缓存击穿的解决方法是将热点缓存设置为永不过期。
- 缓存穿透:缓存穿透是指查询不存在的数据,由于缓存不命中(因为数据根本就不存在),导致所有的查询请求都落在数据库上,如果有大量这样的请求,数据库可能会遭受很大压力。缓存穿透的解决方法是缓存空的结果,即使查不到数据,也缓存一个空的结果。这样查询就会落到缓存上。或者使用布隆过滤器前缀判断数据是否在缓存中存在,如果不存在,就直接返回空的结果。相比来说缓存空的结果会更友好并且更容易实现。
如果mysql或redis压力过大,也可以考虑前端限流的方式。
- 缓存一致性问题如何解决
缓存一般情况下有两种方法去更新:
- 先删除缓存,再更新数据库
- 先更新数据库,再删除缓存
无并发情况:先删除缓存,再更新数据库

缓存已经被删除了,而数据库更新失败了,如果数据库有retry机制,那么可以重试,重试失败,那么缓存中没有数据,数据库中是旧的数据,缓存与数据库是一致的。如果数据库retry成功,那么缓存与数据库也是一致的。
无并发情况:先更新数据库,再删除缓存
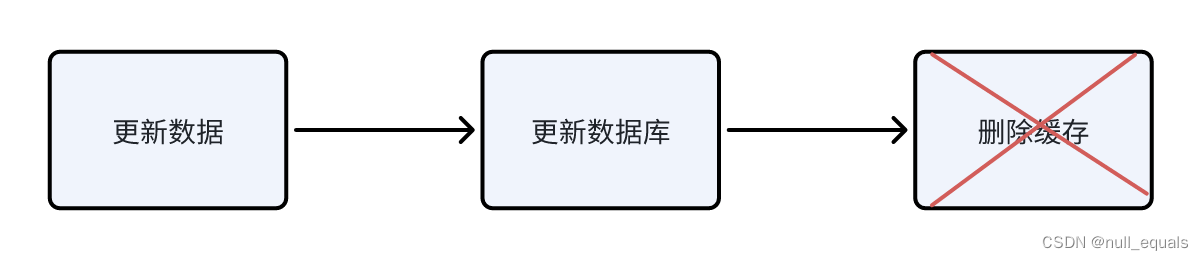
数据库更新成功,而缓存删除失败了,那么下次查询请求就会查询到旧的数据,而这是我们不希望看到的,所以删除缓存也可以加retry,一般情况下redis都会删除成功。
有并发情况:
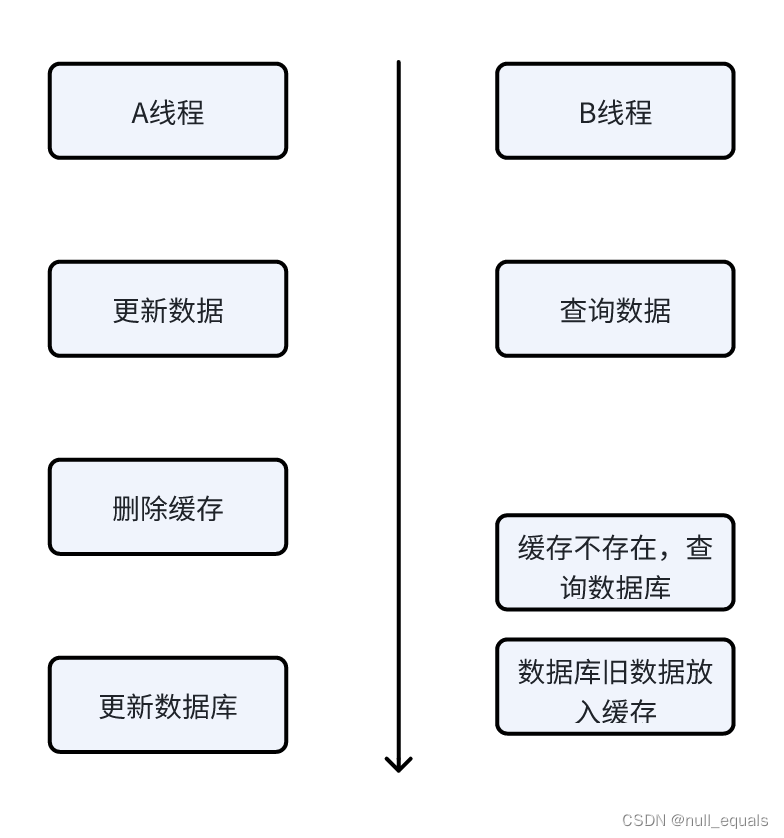
会出现旧数据被其它线程读取到缓存中的情况,这样你的服务会一直读到旧数据,这种方式可以采用两种方式来处理:
A. 绑定数据库连接,对于同一个id的操作(更新、查询)都通过同一个数据库连接来处理,这样就能保证对于同一个id操作的顺序性。这种方法比较重,需要修改数据库连接池,所以了解就行。
B. 缓存延迟双删策略,如果有数据更新操作,先做一次删除缓存,过一会儿再删除一下缓存,保证并发发生时的缓存被清理掉。过一会儿这个时间就需要看业务的容忍度咯,并且并不是所有的更新操作都会有并发,只有在并发发生时才可能出现缓存旧数据的情况,所以这个概率也是比较低的。
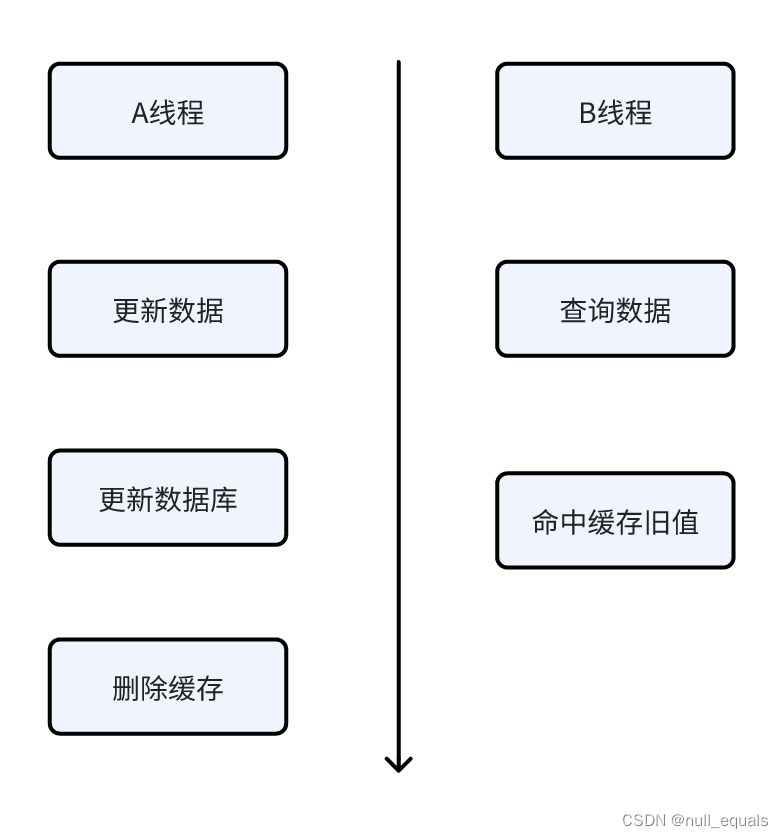
会出现删除缓存之前,所有并发的请求都会读到旧值,个人感觉这种可以直接忽略了,最终等A线程删除缓存之后就会读取到新的数据了。
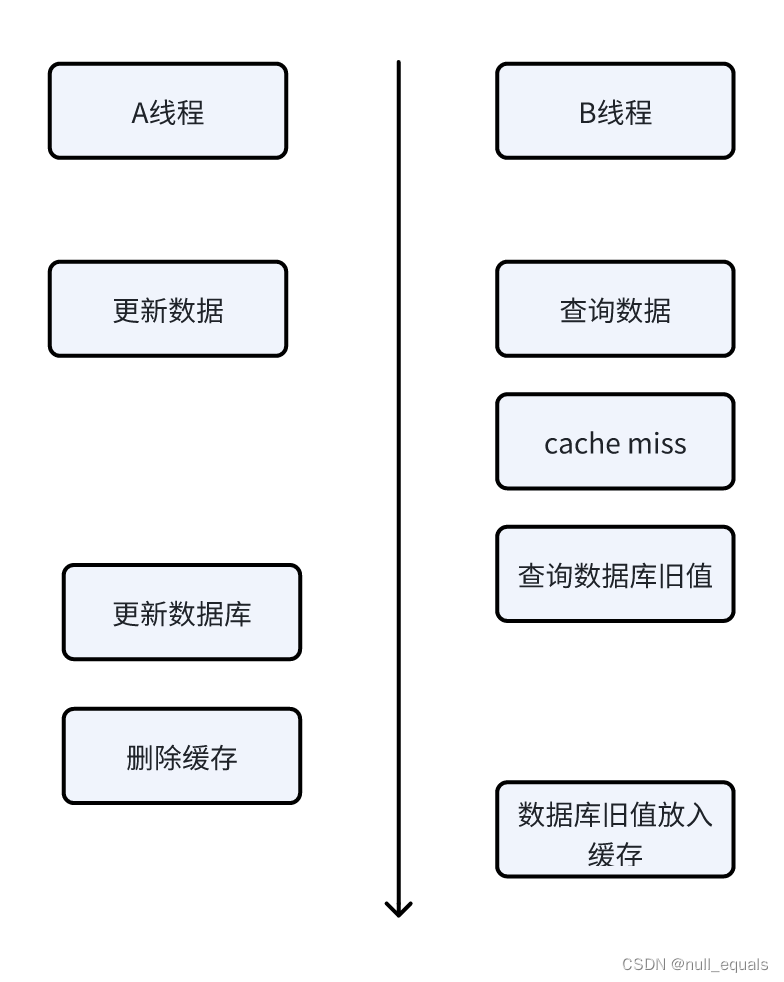
这种情况也是我们不愿意看到的,但是说实话这种情况感觉一般不会发生,正常情况下读数据比写数据会更快。当然这种情况也是可以使用缓存延迟双删策略来处理。