目录
HTTPS如何保证安全
1)引入非对称加密
2)引入非对称加密
3.中间人攻击
4.解决中间人攻击
JVM
1.JVM内存划分
2.JVM类加载过程
八股内容
3.JVM中的垃圾回收机制
释放垃圾的策略
1.标记-清除
2.复制算法
3.标记-整理
分代回收
HTTPS如何保证安全
1)引入非对称加密
在对称加密的情况下,
 要想进行对称加密,就需要客户端和服务器都具有同一个对称密钥
要想进行对称加密,就需要客户端和服务器都具有同一个对称密钥
一个服务器,同时给多个客户端提供服务的时候,还需要确保每个客户端,使用的对称密钥都得不相同!!
如何把密钥传输给对方呢?如果明文传输,又会被黑客获取到
需要给密钥进行加密(无法使用对称加密的方式,对密钥加密的)
2)引入非对称加密
对称加密是不安全的,所以通过非对称加密的方式,针对对称密钥来进行加密。
引入非对称加密,不是针对后续传输的数据内容展开的,而是只针对对称密钥来进行!!
非对称加密的系统开销比对称加密高很多消耗的时间,也比对称加密多很多不太适合使用非对称的方式来加密业务数据
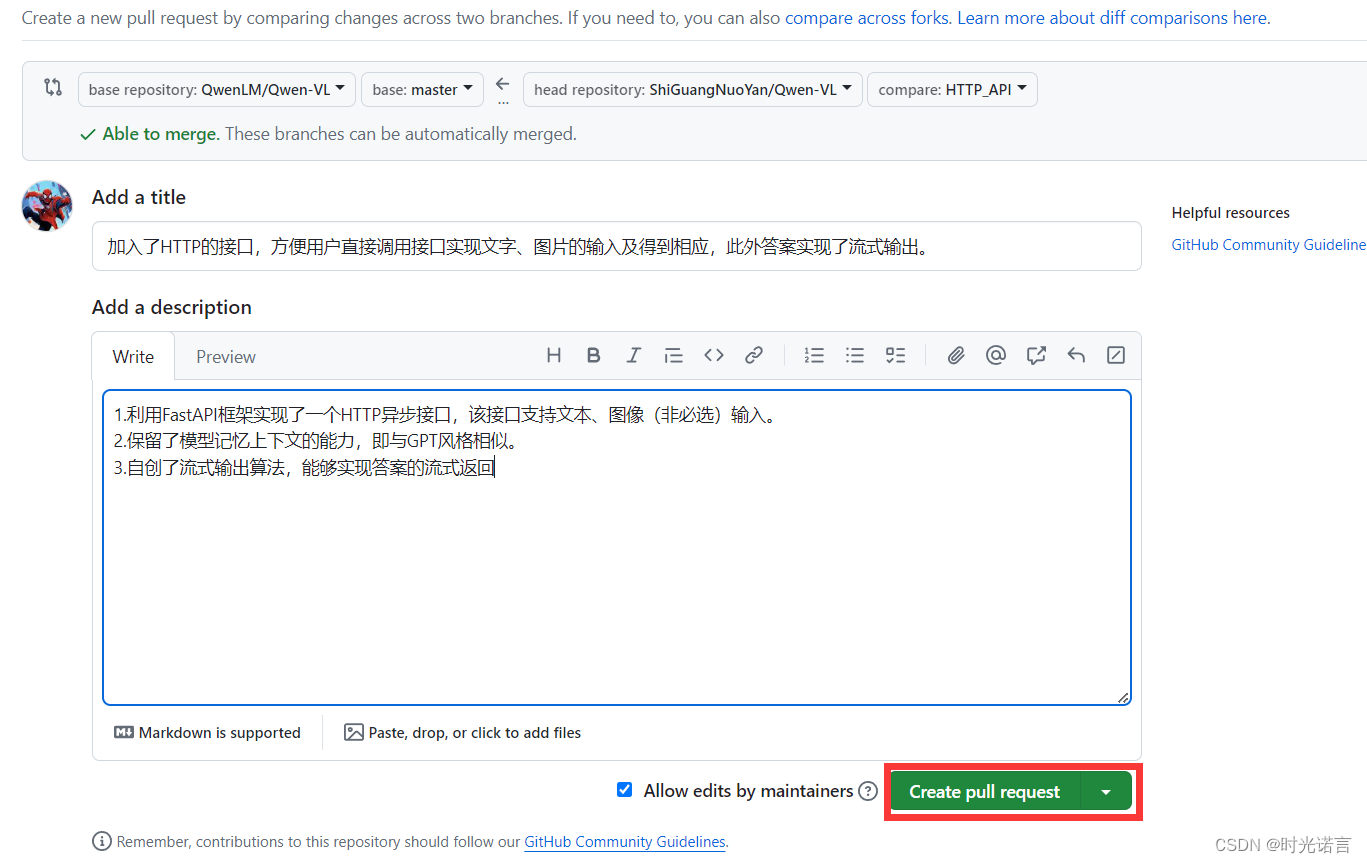
以下是一个完整的客户端与服务器之间使用RSA算法进行密钥交换和安全通信的具体流程:
- 服务器生成并分发公钥 (e,n)
- 客户端生成会话密钥 KKK 并用公钥 (e,n) 加密,得到 CKC_KCK。
- 客户端发送加密后的会话密钥 CKC_KCK 给服务器。
- 服务器使用私钥 (d,n) 解密 CKC_KCK,得到会话密钥 KKK。
- 客户端和服务器使用会话密钥 KKK 进行对称加密通信。
- (可选)服务器对消息进行数字签名,客户端验证签名。

接下来客户端生成对称密钥.(每个客户端生成自己的,客户端之间不知道别人的对称密钥是啥)通过服务器拿到的公钥,针对对称密钥,进行加密再把对称密钥的密文,传输给服务器~~
黑客拿到对称密钥的数据之后,无法解密的!!使用公钥加密,得拿着对应的私钥来解密黑客能轻松拿到公钥但是拿不到私钥.
但是黑客,可以冒充自己是服务器~
3.中间人攻击
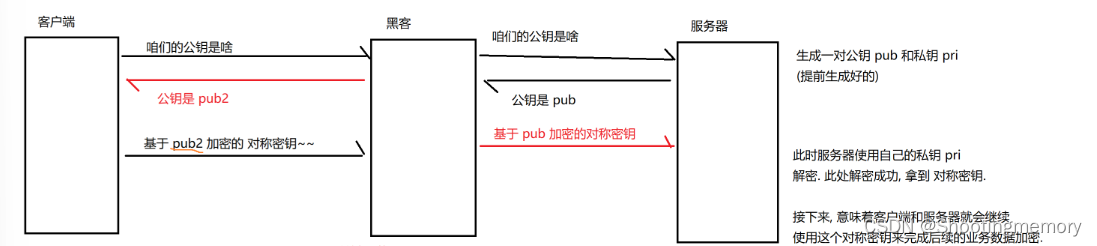
关键环节:黑客在中间自己生成一个公钥pub2和私钥pri2.
黑客首先受到服务器的公钥,黑客就向客户端发送pub2,然后客户端不知道公钥是不是服务器发来的,所以就会给出回应,基于pub2加密的对称密钥给予黑客,黑客针对刚才收到的pub2加密的数据进行解密,从而拿到这里的对称密钥!黑客继续把拿到的对称密钥,使用服务器的公钥pub再次加密~
这样黑客面对客户端的时候,
扮演服务器的角色面对服务器的时候,
扮演客户端的角色客户端和服务器。
4.解决中间人攻击
其中最主要的原因是公钥没有安全性,所以我们推出第三方工证机构,来进行认证,此时客户端就会被公钥公证了,这样就是合法的。
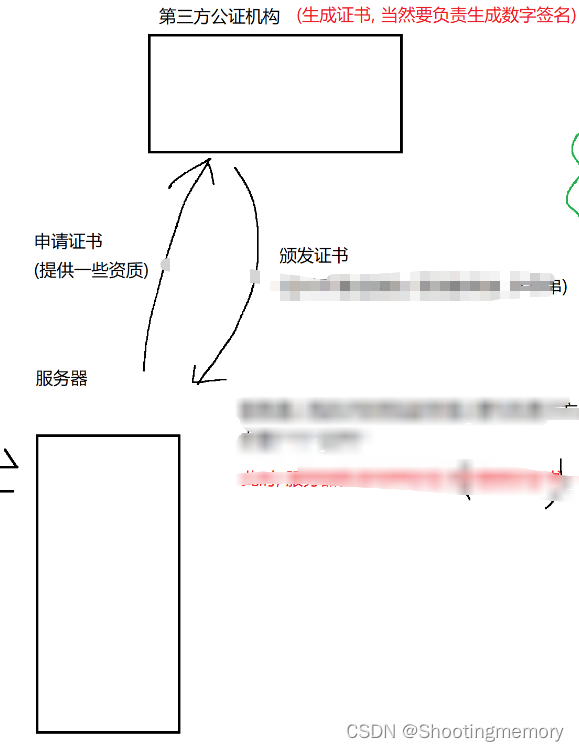
证书是通过校验和和pri(公证)来形成数字签名。
校验和:15发证机构2)证书的有效期3)月服务器的公钥41证书的所有者5)持有者网站的主域名
pri(公证):6)数字签名
数字签名就是加密后的校验和。
数字签名,就是针对这个校验和,再来一次加密!!基于非对称加密的方式来进行的加密。
客户端对证书的合法性进行校验
1.针对证书这些字段,计算校验和
1)发证机构2)证书的有效期3)月服务器的公钥4证书的所有者5)持有者网站的主域名=》校验和1
6数字签名
查看计算出的校验和和数字签名解密出来的校验和2是否一致。
2.针对数字签名进行解密
数字签名是基于公正机构的私钥来加密的就需要拿着公正机构的公钥来解密~
每个操作系统会内置公正机构的公钥。
接下来,就可以使用公正的机构的公钥
这样的时候黑客就没办法操作了.
是因为两种情况:
1.如果黑客修改了证书中的公钥,但是不修改数字签名。
客户端校验的时候就会发现,自己算出来的校验和和从数字签名中解密出来的校验和,不一致了客户端就可以判定,证书非法!!
2)如果黑客修改了公钥,并且自己重新计算校验和,重新加密得到数字签名??
重新加密需要私钥,但是黑客不知道第三方的私钥所以导致访问失败。
JVM
1.JVM内存划分
这个进程一旦跑起来之后,就会从操作系统这里,申请一大块内存空间.
JVM接下来就要进一步的对这个大的空间进行划分划分成不同区域,从而每个区域都有不同的功能作用.
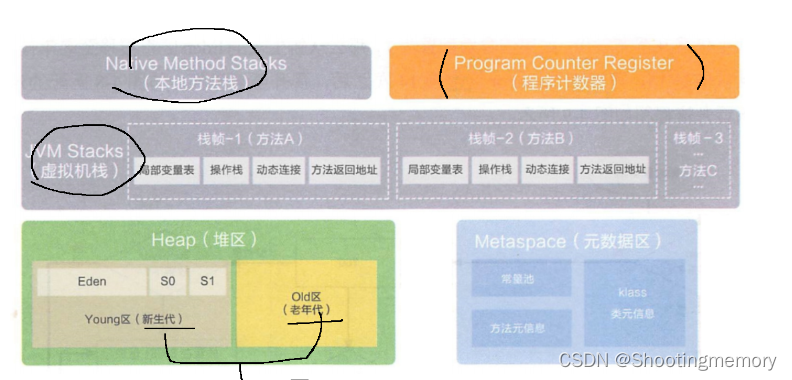
1.堆(heap)整个内存区域中,最大的区域,放的就是代码中new出来的对象 .
2.栈 JVM虚拟机栈(java)保存了方法的调用关系stack
本地方法栈(C++这里的调用关系,就是使用栈来维护.
3.元数据区(以前叫做"方法区",从java8改名字).
Test.class=>类对象.
代码中写的每个类,在jvm上运行的时候,都会有对应的类对象.
4.程序计数器 是内存区域中最小的区域,只需要保存,当前要执行的下一条指令(JVM字节 码)的地址(这个地址就是元数据区里面的一个地址).
class Test{
int a;
Test t2=new Test2();
String s="hello"
static int b;
}a,t2,s这三个都是Test的成员变量都是在堆上的!
hello 本体是在元数据区。
s自身是Test的成资自身在堆上里面保存的值是一个指向元数据区的地址。
static修饰,成了类属性,就会出现在类对象中,也就是在元数据区
函数中的方法都是元数据区。
public static void main(){
Test t = new Test();
} t不是对象!只是指向对象的引用保存了对象的首地址(堆上的地址)。
t在代码中的局部变量局部变量是在栈上的~~
new Test()是在堆上的。
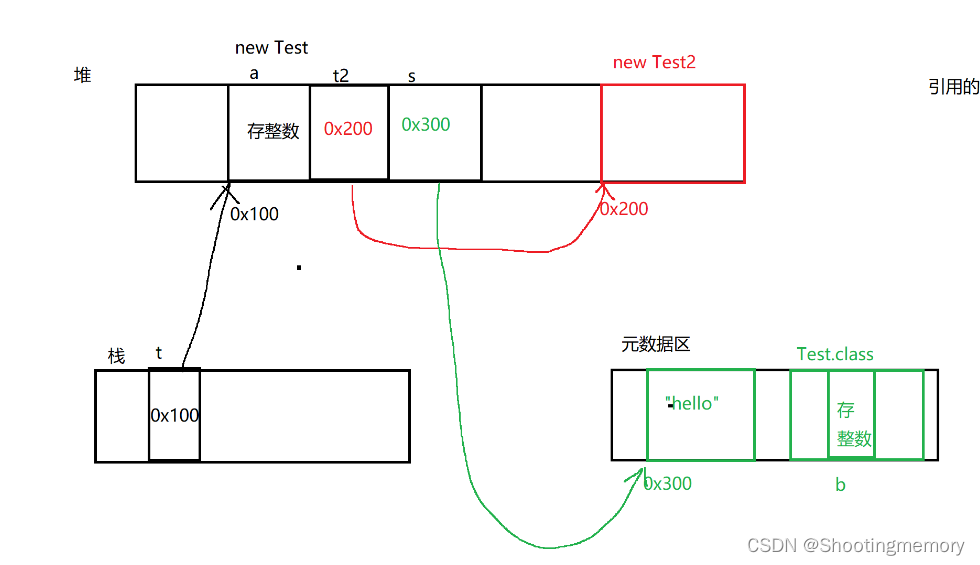
基本原则:一个对象在哪个区域,取决于对应变量的形态
1)局部变量栈上2)成员变量堆上3)静态成员变量方法区/元数据区
上述四个区域中,堆和元数据区,是整个进程只有一份
栈和程序计数器,是每个线程都有一份的.
多个进程,可能有多份的
多个线程共享同一份数据~~每个线程的局部变量,则不是共享的,
每个线程都是有自己一份~~
2.JVM类加载过程
一个java进程要跑起来,就需要把java先变成.class文件(硬盘),加载到内存中,得到"类对象"。
跑起来:就是执行指令:要执行的cpu指令,都是通过字节码让jvm翻译出来的。
八股内容
1.加载:在硬盘上,找到对应的.class文件.读取文件内容
2.验证:检查.class里的内容,是否符合要求
把读取进来的内容,往这个格式里套能不能套进去,看是否有问题~~
3.准备:给类对象,分配内存空间(类加载最终要得到的就是类对象
内存空间=》元数据区
会把这个空间里的数据先全都填充成0
4.解析:针对字符串常量来初始化把刚才.class文件中的常量的内容取出来,放到厂"元数据区
5:初始化:针对类对象进行初始化(不是针对对象初始化,和构造方法无关)给静态成员进行初始化执行静态代码块 .

类加载中的双亲委派模型(经典面试题)
出现在"加载"环节 (第一步)根据代码中写的"全限定类名”找到对应的class文件。
全限定类名:包名+类名。
双亲委派模型,描述了JVM加载.class文件过程中,找文件的过程。
类加载器
在JVM中包含的一个特定的模块/类~~这个类负责完成后续的类加载工作 .
JVM中内置了三个类加载器:
1)BootstrapClassLoader 爷爷 负责加载标准库的类
标准库是Java‘官方给出的1"规范文档上面要求要提供的类~
2)ExtentionClassLoader 父亲 负责加载JVM扩展库的类
各个JVM厂商在实现JVM的时候会根据需要,在上述标准之上做出一些扩展
3) ApplicationClassLoader 儿子 负责加载第三方库的类和你自己写的代码的类
此处的"父子关系"不是通过类的继承表示的(不是父类子类)而是通过类加载器中存在一个"parent"这样的字段,指向自己的父亲 类似于二叉树的"三叉实现形式

1.工作从 ApplicationClassLoader 开始进行
ApplicationClassLoader并不会立即搜索第三方库的相关目录,而是把任务交给自己的父亲来进行处理
2.工作就到了ExtentionClassLoaderExtentionClassLoader也不会立即搜索负责的扩展库的目录,也是把任务交给自己的父亲来处理~~
3.工作就到了 BootstrapClassLoader,BootstrapClassLoader也想交给自己的父亲来处理.但是,它的 parent 指向 null,只能自己处理.BootstrapClassLoader尝试在标准库的路径中搜索上述类~~java111.Test如果这个类,在标准库中找到了,于是搜索过程就完成了,类加载器负责打开文件,读取文件等后续操作就行了.如果没找到,任务还是要继续还给儿子来处理~~
4.工作回到了 ExtentionClassLoader,此时就要搜索扩展库对应的目录了~~如果找到了,就由当前的类加载器负责打开文件,读取文件等后续操作..如果没找到,任务还是要继续还给儿子来处理~~
5.工作回到了ApplicationClassLoader此时要搜索第三方库/用户项目代码的目录了~~如果找到了,也是由当前的类加载器负责处理.如果没找到,任务还是要继续还给儿子来处理~~此时,没有儿子了!!!
还没找到,就会最终抛出一个ClassNotFoundException.
双亲委派(父亲委派)模型:拿到任务,先交给父亲处理.父亲处理不了,再自己处理~
上述过程,主要为了应对这个场景:比如你自己代码里写了一个类,类的名字和标准库/扩展库冲突了,JVM会确保加载的类是标准库的类(就不加载你自己写的类]java.lang.String如果标准库的这个String加载不了,怕是整个Java进程没法正确工作了!
3.JVM中的垃圾回收机制
GC垃圾回收机制,是Java提供的对于内存自动回收的机制~~相对于C/C++的手动回收来命名的~~
C/C++不添加自动回收是因为他要提高自己的效率。
GC回收的是“内存",更准确说,是“对象”,回收的是“堆上的内存
1)程序计数器(不需要额外回收,线程销毁,自然回收了)
2)栈(不需要额外回收,线程销毁,自然回收了)
3)元数据区(一般也不需要,都是加载类,很少“卸载类")
4)堆~~~(GC的主力部分)
一定是一次回收一个完整的对象,不能回收半个对象~~(一个对象有10个成员,肯定是把10个成员的内存都回收了,而不是只回收一部分)。
GC的流程主要是两个步骤1.找到谁是垃圾2.释放对应的内存
1.找到垃圾的方式不好找,一般都是遍历然后标记然后找出。
此处引I入了非常“保守”的做法,一定不会误判的做法(可能会释放的不及时)判定某个对象,是否存在引用指向它.
Test t=new Test();
使用对象,都是通过引用的方式来使用的~~如果没有引用指向这个对象,意味着这个对象注定无法再代码中被使用!
t=null; 修改t的指向
此时newTestO的对象就没有引用指向了此时这个对象就可以认为是"垃圾
具体是怎么判定,某个对象是否有引用指向呢?
有很多种方式来实现介绍两种方式~~
如果面试官问:GC中,如何判定对象是垃圾~?要回答两种~如果问:Java的GC中,如何判定对象是垃圾~^只需要回答第二种!!!
1)引I用计数(不是JVM采取的方案,而是Python/PHP的方案)
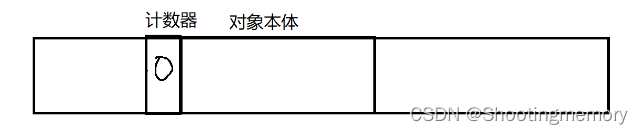
Test a=new Test();
Test b=a;
b=null;
a=null;如果有引用计数器就+1,为0的时候就是没有引用就是垃圾。
把对象的地址进行赋值都知道对象地址了,自然就能找到对象更能找到对象旁边的计数器了~
两个缺陷:
1.消耗额外的存储空间如果你对象比较大,浪费的空间还好.对象比较小,空间占用就多了~~并且对象数目多,空间的浪费的就多了~
2.存在"循环引l用”的问题~~[面试官考引用计数,就是为了考你循环引用的理解]
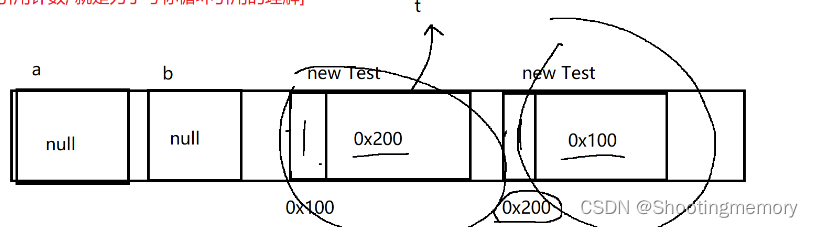
Class Test{
Test t;
}
Test a=new Test();
Test b=new Test();
a.t=b;
b.t=a;
a=null;
b=null;这样就会形成你中有我,我中有你,但是这样就没有办法直接删除两个“垃圾”引用。会花费更多的时间。
此时,这俩对象相互指向对方,导致两个对象的引l用计数,都为1(不为0.不是垃圾)但是你外部代码,也无法访问到这俩对象!!
2)可达性分析 (是JVM采取的方案)
JVM把对象之间的引I用关系,理解成了一个"树形结构”.
JVM就会不停的遍历这样的结构,把所有能够遍历访问到的对象标记成“可达",剩下的就是"不可达"
class Node{
Node left;
Node right;
}
Node build() {
Node a = new Node();
Node b = new Node();
Node c = new Node();
Node d = new Node();
Node e = new Node();
Node f= new Node();
Node g = new Node();
a.left = b;
a.right = c;
b.left = d;
b.right = e;
e.left = g;
c.right = f;
return a;
}
Node root=build();
此处只有一个引用通过这个引用,就能访问到所有树上的节点对象!!!
如果写了root=null就是要把树上的所有对象都干掉了.
如果写了root.right=null那么c,f都会被回收。
GC roots((这些树的根节点是怎么确定的?)
Java代码中,你所有的
1)栈上的局部变量,,引I用类型的,就都是GCroots
2)常量池中,引用的对象
3)方法区中的静态成员
由于可达性分析,需要消耗一定的时间,因此,Java垃圾回收,没法做到“实时性周期性进行扫描(JVM提供了一组专门的负责GC的线程,不停的进行扫描工作)。
释放垃圾的策略
1.标记-清除
直接把标记为垃圾的对象对应的内存,释放掉~一(简单粗暴)

这样的做法会存在“内存碎片”问题。
空闲内存被分成一个个的碎片了.后续很难申请到,大的内存!
申请内存,都是要申请“连续”的内存空间的~~
如果需要扩展一个内存大的地方,没有足够的空间,因为内存都是碎片,所以找不到内存大的地方。
2.复制算法
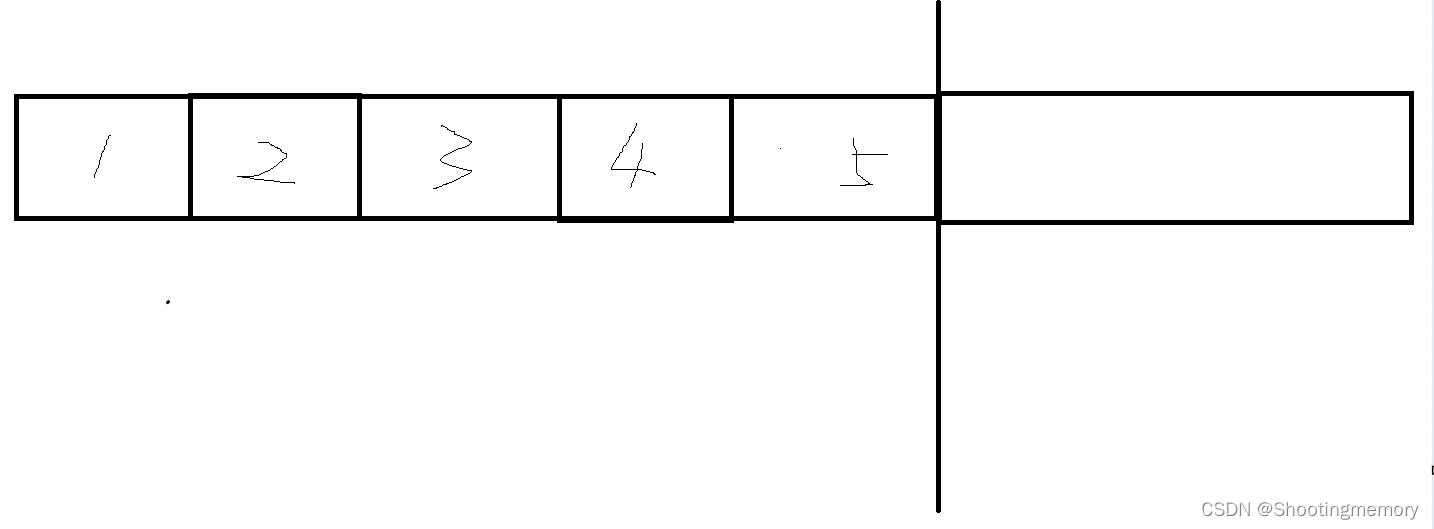
比如,要释放135,保留24不会直接释放135的内存,而是把24拷贝到另外一块空间中!!

3.标记-整理
能解决内存碎片,也能解决空间利用率的问题~~

释放246.保留1357类似于“顺序表删除中间元素”。
就是将数据删除之后将数据重新排序。
JVM使用分代回收
分情况讨论根据不同的场景/特点选择合适的方案。
根据对象的年龄
GC有一组线程,,周期性扫描某个对象,经历了一轮GC之后,还是存在没有成为垃圾,年龄+1。
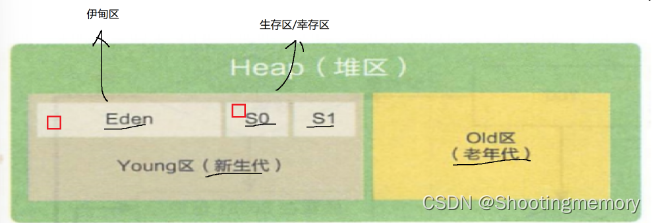
把新创建的对象,放到伊甸区中伊甸区中,
大部分的对象,生命周期都是比较短的,第一轮GC到达的时候,就会成为垃圾只有少数对象能活过第一轮GC~
伊甸区->生存区通过复制算法.(由于存活对象很少,复制开销也很低,生存区空间也不必很大)
生存区->另一个生存区通过复制算法.没经过一轮GC,生存区中都会淘汰掉一批对象,剩下的通过复制算法,进入到另一个生存区(进入另一个生的还有从伊旬区里进来的对象)
存活下来的对象,年龄+1
生存区->老年代某些对象,经历了很多轮GC,都没有成为垃圾,就会复制到老年代
老年代的对象,也是需要进行GC的,但是老年代的对象生命周期都比较常,就可以降低GC扫描的频率.
分代回收
对象伊甸区->生存区->生存区->老年代复制算法对象在老年代中,通过标记-整理(搬运)来进行回收~
垃圾回收器








![[图解]企业应用架构模式2024新译本讲解03-事务脚本+表数据入口](https://img-blog.csdnimg.cn/direct/904eb559bc7e49eb80f655b0be44e84a.png)