最近,Oracle的产品管理总监在Oracle数据库内幕中介绍了True Cache。

原文链接如下:
-
https://blogs.oracle.com/database/post/introducing-oracle-true-cache
由于这篇文章比较火爆,我们国内已经有很多的数据库爱好者完整的翻译这篇文章,所以笔者也不需要重复翻译,本文旨在提炼文中关键信息,并使用大白话和大家一起探讨下23ai中的True Cache功能:
-
1.为什么需要True Cache?
-
2.True Cache工作原理
-
3.应用程序使用True Cache
-
4.True Cache的好处和应用场景
1.为什么需要True Cache?
通常这个问题会是IT部门的领导层最关心的问题,现有架构下,为什么需要引入True Cache?
回答这个问题,需要先了解下目前的发展趋势,当下随着数字化环境的不断发展,各类应用要求提供实时响应成为当务之急,而大家都知道数据库的资源很宝贵,大部分高并发应用其实都是读多写入的场景,所以业界常用的方案就是在数据库的前面加一个缓存层,且将它设计在内存中缓存(Caching),这个底层逻辑其实也非常简单,就是内存的速度一定是远远高于存储速度的,这是介质本身存在的数量级的性能差异。当然,能接受用缓存的共识是这个缓存中无需最新的数据,说白了,无论你用什么样的缓存技术,读的数据无论多少,一定都是有延迟的,可应用需求一定会要求这个延迟越小越好,这里原文中立马就提到Oracle提供的True Cache是一个突破性的缓存解决方案,那这个突破性具体体现在哪里呢?
-
性能的进一步优化
-
缓解数据陈旧问题
-
有效管理缓存数据
这些方面的优势是因为True Cache相当于是一个主库的全功能的只读副本,类似ADG,但又比ADG轻量,它不需要数据文件的存储,别小看这一点,对于当下一个动辄几十T数据量的数据库来说,将会是非常大的成本节约。
2.True Cache工作原理
这里,提炼文中关键的几点:
-
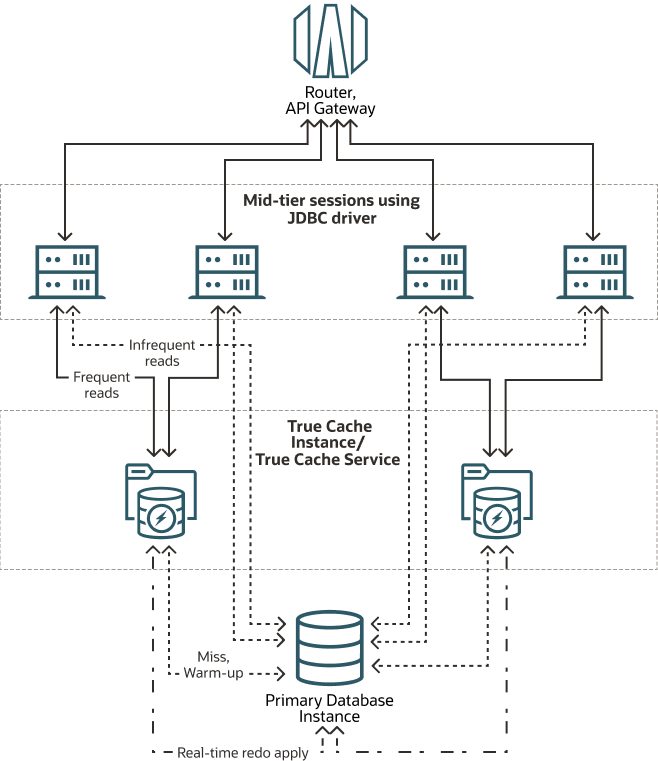
应用程序通过Oracle JDBC Driver连接对应实例(主库和True Cache实例)
-
当发生Cache miss(缓存未命中)时,True Cache会从主库获取块
-
当True Cache实例首次启动,除了获取Cache miss的块,还会以large chunks的方式预热大量周围相关块
-
对于已经缓存到True Cache实例中的数据块,块的更新自动通过redo apply来更新,这其实就用到ADG ASYNC的技术,从而实现sub-second的延迟,实时性非常高,有效缓解了普通缓存技术的数据陈旧问题
-
数据一致性,这点基本是Oracle的万能优势,原生的缓存确保你从True Cache中读到的数据也是提交成功的数据
3.应用程序使用True Cache
文中提到了两种方式:
-
多个物理连接
-
一个逻辑连接
这里多个物理连接不用多说,主要优势点还是在于支持提供一个逻辑连接,然后通过Driver处理底层的物理连接,这就可以真正的简化应用配置。
4.True Cache的好处和应用场景
True Cache的好处体现在:
-
提升APP性能
-
简单高效:自动化维护、简化开发、提升SLA
-
成本节约
应用场景文中提到的可以给大家参考:
-
用户会话存储,提供微妙级的响应时间
-
电子商务,对在线产品目录的高效浏览
-
在线游戏,实时的排行榜,用户排名
-
用户身份验证
-
实时分析
-
边缘计算
-
数据主权
这些点大部分都比较好理解,也可以作为我们发现更多应用场景的一个启发。不过最后这点“数据主权”的应用场景,笔者其实也是有一些疑问的,因为如果单纯使用True Cache技术,即便True Cache部署在特殊地区,数据其实都还在主库中,只是这个True Cache接受到的用户请求没有出境而已。如果要做到真正的数据主权,应该是还要配合Sharding技术。大家觉得呢?
最后总结部分,文中提到Oracle的True Cache是全面的解决方案,再次强调原生的Ture Cache能同时利用到Oracle DB的完整能力,这个其实也是所有Oracle原生技术的通用优势了,比较容易理解。
文章转载自:AlfredZhao
原文链接:https://www.cnblogs.com/jyzhao/p/18217008/23ai-zhong-detrue-cache-dao-di-neng-zuo-sha
体验地址:引迈 - JNPF快速开发平台_低代码开发平台_零代码开发平台_流程设计器_表单引擎_工作流引擎_软件架构