前言
clickhouse 可以将源数据加载进 clickhouse 作为字典表使用,字典表可以理解为 clickhouse 中的一张特殊表,我们在查询 clickhouse 表中的数据的时候不需要 JOIN 就可以直接查询字典表中的数据,非常方便,快速。
我刚好在工作场景中遇到了一个非常适合使用 clickhouse 字典表的场景,在这里记录总结下:
-
我们在 clickhouse 中一张原始数据表
ods_h53_file我们对 ods 进行了数据清洗,建模了 dwd 表
dwd_h53_trigger_type -
现在外部系统需要查询 ods 表中的数据,但是又需要用到清洗后的 ods 表中的数据,为了对查询速度进行优化不进行 JSON 关联查询,我们使用了 clickhouse 的字典对
dwd_h53_trigger_type进行了缓存生成了一张字典h53_trigger_type,在查询ods_h53_file表中的数据时可以直接关联字典h53_trigger_type查询 dwd 表中的数据。 -
后边外部系统又需要关联 MySQL 和 clickhouse 表的数据,关联查询 clickhouse
ods_h53_file表和 MySQLt_event_package_parse表。
如果不使用 clickhouse 的字典,就需要先从 clickhouse 中查询出对应数据,然后再从 MySQL 过滤查询出对应的数据,最后再在代码内存中进行关联清洗,效率极低,而且很 LOW。
- 这个时候可以使用 clickhouse 的字典,将外部数据源加载为字典,在查询 clickhouse 表的时候关联查询,效率高,使用简单,极力推荐。
创建库
下边的所有 clickhouse SQL 都是在 cloud_data库下执行的,需要先创建库:create DATABASE cloud_data
创建表
这里对使用到的相关表的创建进行说明,包括 clickhouse 使用到的表: ods_h53_file,dwd_h53_trigger_type,MySQL 使用到的表 t_event_package_parse,以及 clickhouse 中的字典:h53_trigger_type(源数据为clickhouse 内部表), dict_event_package_parse(源数据为 MySQL 外部表)。
注:
如果是在 clickhouse 集群上创建表或字典,需要制定 cluster,例如:
CREATE TABLE cloud_data.ods_h53_file on cluster 集群名称
clickhouse 表 ods_h53_file DDL
CREATE TABLE cloud_data.ods_h53_file (
`version` String COMMENT '智驾版本,对应config文件中的software_version',
`trigger_type` String COMMENT '触发类型',
`vin` String COMMENT '车架号',
`day_` Date DEFAULT toDate ( timestamp_ / 1000 ) COMMENT '数据时间-天',
`second_` DateTime DEFAULT toDateTime ( timestamp_ / 1000 ) COMMENT '数据时间-秒',
`timestamp_` Int64 COMMENT '秒时间戳,对应json中的timestamp',
`packet_name` String COMMENT '包名',
) ENGINE = MergeTree()
PARTITION BY toYYYYMM(day_)
ORDER BY (vin, day_, second_)
SETTINGS index_granularity = 8192;
clickhouse 表 dwd_h53_trigger_type DDL
create table cloud_data.dwd_h53_trigger_type
(
`trigger_type` String COMMENT '触发类型',
`trigger_name` String COMMENT '触发名字',
`func_type` String COMMENT '事件对应功能'
) ENGINE = MergeTree()
PRIMARY KEY (trigger_type)
ORDER BY
(trigger_type) SETTINGS index_granularity = 8192 COMMENT 'H53触发器类型';
- 该表后边会作为源数据创建一张字典,这里的 PRIMARY KEY 很重要,这个是源数据同步至字典的重要字段,而且后边查询字典数据的时候也是通过主键作为过滤条件的。
mysql 表 t_event_package_parse DDL
CREATE TABLE t_event_package_parse (
id INT AUTO_INCREMENT PRIMARY KEY,
package_name VARCHAR(255) UNIQUE,
state ENUM('0', '1', '2'),
create_time DATETIME,
create_by VARCHAR(16),
update_time DATETIME,
update_by VARCHAR(16)
);
clickhouse 字典 DDL
注:
这里为了测试方便,在创建字典的时候 LIFETIME 设置的时间很短,更新频率较快,时间较短,这样在我们往源表插入数据的时候可以快速同步至字典中。
在实际的生产环境中需要根据具体的业务场景确定,后边会对 LAYOUT 和 LIFETIME 的配置进行说明。
使用 clickhouse 表 dwd_h53_trigger_type 作为数据源创建字典 h53_trigger_type:
create DICTIONARY cloud_data.h53_trigger_type
(
`trigger_type` String,
`trigger_name` String,
`func_type` String
)
PRIMARY KEY trigger_type
SOURCE(CLICKHOUSE(
HOST '127.0.0.1'
PORT 9000
USER 'root'
PASSWORD '123456'
DB 'cloud_data'
TABLE 'dwd_h53_trigger_type'
))
LAYOUT(COMPLEX_KEY_HASHED())
LIFETIME(10);
- 这里需要注意主键和数据源表保持一致,使用
trigger_type SOURCE配置需要改为 clickhouse 连接信息,需要注意这里的 DB 和 TABLE 不要写错了,这里指的是你需要将哪张表的数据作为源数据。
使用 MySQL 表 t_event_package_parse作为数据源创建字典dict_event_package_parse:
create DICTIONARY cloud_data.dict_event_package_parse
(
`package_name` String,
`state` String
)
PRIMARY KEY package_name
SOURCE(MYSQL(
HOST '127.0.0.1'
PORT 3306
USER 'root'
PASSWORD 'password'
DB 'addcdata'
TABLE 't_event_package_parse'
))
LAYOUT(COMPLEX_KEY_HASHED())
LIFETIME(10);
- 注意将SOURCE 改为 MYSQL
往 clickhouse 和 MySQL 表中插入测试数据
现在我们往clickhouse 表ods_h53_file,dwd_h53_trigger_type,MySQL 使用到的表 t_event_package_parse中插入几条测试数据:
-- 插入 ods_h53_file
insert into cloud_data.ods_h53_file values('H53A3632801FK', 'RPA中断', 'LDP91C968PE201357', '2024-04-19', '2024-04-19 00:00:00', 1713456000, 'LDP91C968PE201357_20240419224750_A_2');
insert into cloud_data.ods_h53_file values('H53A3632801FK', 'RPA中断2', 'LDP91C968PE201357', '2024-04-20', '2024-04-20 00:00:00', 1713542400, 'LDP91C968PE201357_20240420224750_A_2');
insert into cloud_data.ods_h53_file values('H53A3632801FK', 'RPA中断3', 'LDP91C968PE201357', '2024-04-21', '2024-04-21 00:00:00', 1713628800, 'LDP91C968PE201357_20240421224750_A_2');
-- 插入 dwd_h53_trigger_type
insert into cloud_data.dwd_h53_trigger_type values('RPA', 'RPA中断', 'RPA');
-- 插入 MYSQL 表 t_event_package_parse
INSERT INTO `addcdata`.`t_event_package_parse` (`package_name`, `state`) VALUES ('LDP91C968PE201357_20240420224750_A_2', '0');
插入完后我们验证下字典表中是否已经有数据了: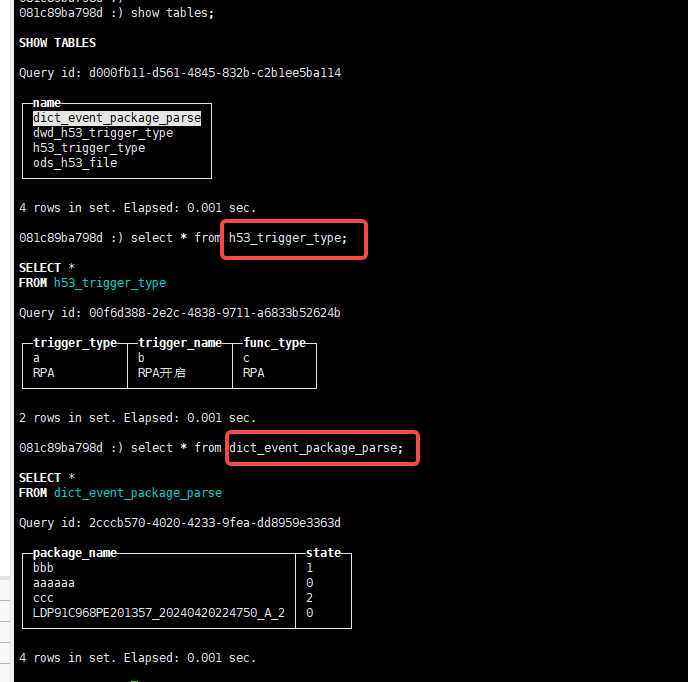
联合查询语句
当我们创建好内部字典和外部字典后,我们就可以通过一条 clickhouse SQL 联合查询 clickhouse 与 MySQL 中的数据,并且不需要 JOIN,查询速度快,简单。
SELECT
`vin` AS `vin`,
version,
toString(parseDateTimeBestEffort(splitByChar('_', packet_name)[2])) as event_time,
-- 这一行就是查询内部数据源字典中的数据
dictGetStringOrDefault('cloud_data.h53_trigger_type', 'trigger_name', trigger_type, trigger_type) AS `func`,
-- 这一行就是查询外部数据源 MySQL 字典中的数据
dictGetStringOrDefault('cloud_data.dict_event_package_parse', 'state', packet_name, 0) AS `state`,
`packet_name` AS `package_name`
FROM `cloud_data`.`ods_h53_file`
WHERE `day_` >= toDate('2024-04-18')
AND `day_` <= toDate('2024-04-25')
AND `second_` >= toDateTime('2024-04-18 00:00:00')
AND `second_` < toDateTime('2024-04-25 00:00:00')
AND splitByChar('_', packet_name)[3] = 'A'
AND `vin` = 'LDP91C968PE201357'
AND func like '%RPA%'
AND package_name like '%LDP91C968PE201357_20240420224750_A_2%'
GROUP BY `vin`,
`version`,
`func`,
`packet_name`
ORDER BY event_time DESC
LIMIT 1000;
- 在查询字典中的数据时,不需要 JOIN, 可以直接通过 dict 函数即可,dictGetStringOrDefault 参数说明:字典表,需要查询的字段,主键key, 默认值。
还有许多其他函数可以参考官方文档。
查询结果如下: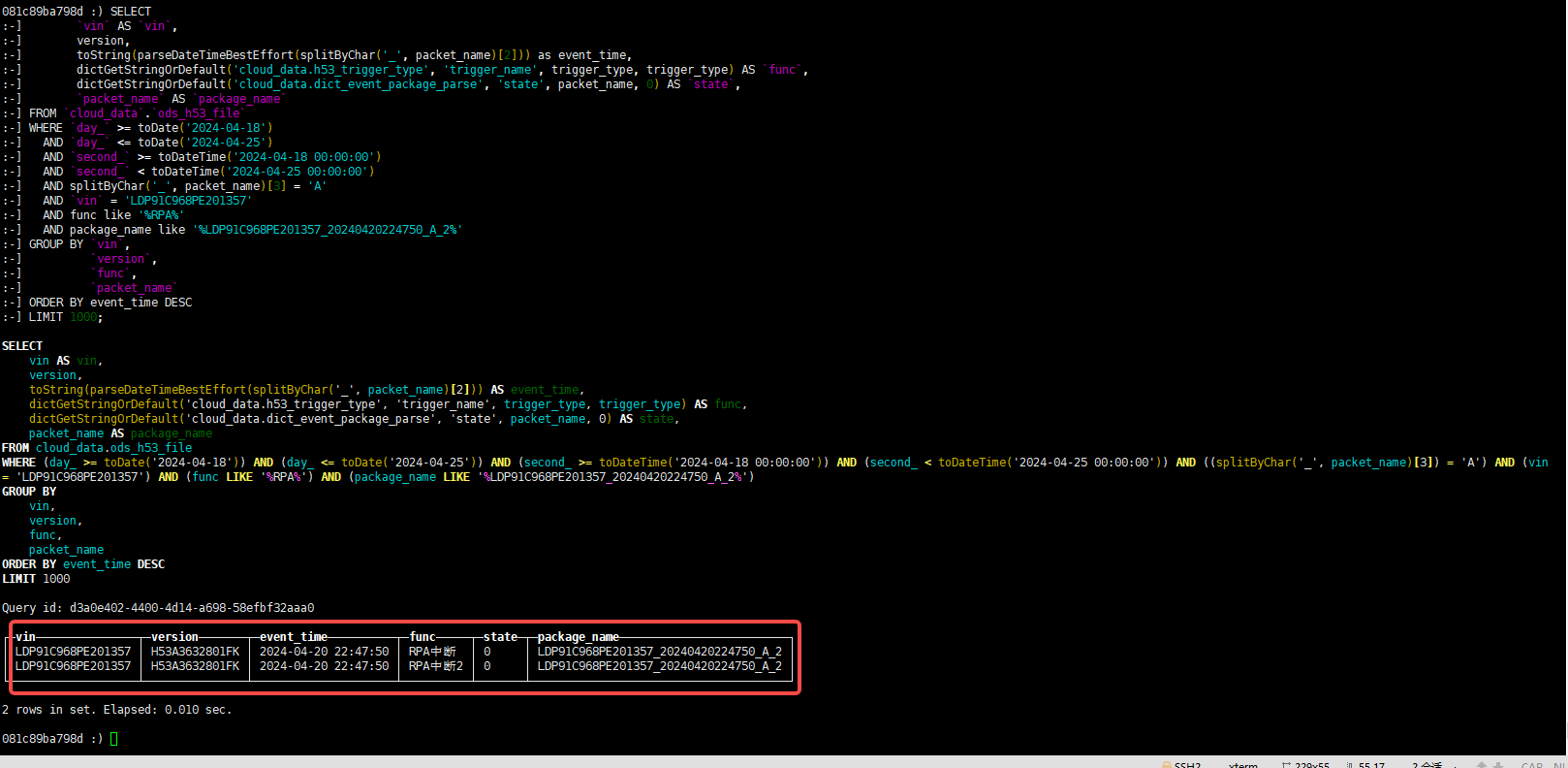
LAYOUT 说明
该配置是说明字典在内存中存储的方式,有许多中,下图是官网的一张截图:
从上图可以看出有很多种,具体说明可以参考官方文档
关于几种常见的可以看下这篇文章说的还是比较清晰的:
大数据ClickHouse进阶(十八):数据字典类型
LIFETIME 说明
该配置是字典刷新加载源数据的频率,主要有三种使用方式:
- 直接写入刷新间隔时间,比如
LIFETIME(10), 10 s 刷新一次, 如果设置为0 代表不会刷新 - 写入 min 和 max,比如
LIFETIME(MIN 300 MAX 360),表示将在300到360s 间随机选择一个时间刷新,在使用分布式 clickhouse 集群时,避免同时大量字典更新导致资源不足,建议使用这种随机的方式,打散刷新频率。 - 第三种比较高级,在创建字典时指定
invalidate_query参数控制字典中的数据是否刷新,主要有两种方式:- 我们的源表需要有一个类似
update_time的字段,当源表数据更新时,该字段一定会更新,这样 clickhouse 就知道需要更新字典了。 - 查询表行数。
- 我们的源表需要有一个类似
注:
但是我在验证第三种方式的时候,不知道为什么没有生效,有验证通过的小伙伴评论或者私信我下,万分感谢。
除了上边的三种配置方式,我们在配置完字典,或者需要立即刷新字典数据时可以通过下边的命令刷新:
# SYSTEM RELOAD DICTIONARY 字典表名
SYSTEM RELOAD DICTIONARY dict_event_package_parse