建立开源人工智能:一种呼吁
编译 李升伟
人工智能(AI)推动整个社会、经济和科学的创新。我们认为,必须根据开源原则建立人工智能技术,以促进人工智能技术的可访问性、协作性、责任性和互操作性。
计算机科学界有着接受开源原则的悠久传统。然而,公司越来越多地限制人们获得人工智能创新。OpenAI公司就是一个例子,它的成立是为了使科学研究公开化获取,但最终限制了人们获得研究成果。虽然这种战略反映了公司获得经济回报的合理动机,但这种保护增加了权力的集中,限制了对人工智能技术的获取利用。更进一步说,权力集中可能导致人工智能研究、教育和公共使用方面的不平等日益加剧。在这里,我们讨论为什么在构建人工智能技术的重要组件--数据集、源代码和模型--中,专有人工智能技术应该得到开源人工智能的补充。
为什么独家专有人工智能技术是个问题?
人工智能是推动社会、经济和科学创新的关键技术。例如,大语言模型如GPT-4,最近已成为许多领域如教育、娱乐、媒体和管理中的文本处理的主干。因此,当广泛使用人工智能受到限制时,包括新的商业模式、产品和服务在内的下游创新可能面临风险。不足为奇的是,权力集中在技术之上,众所周知会妨碍未来的创新、公平竞争、科技进步,从而妨碍人类福祉和未被限制的发展[1]。
专有人工智能技术也可能危及包容性和责任。当大语言模型等新的人工智能技术完全由少数公司开发时,这些公司还可能任意决定在其系统中支持哪些国家和语言,从而可能排除一些用户,例如来自小型市场的用户(例如全球南方和稀有语种)。人工智能技术的一定程度的开放性对于研究人员确定人工智能系统运行中固有的安全性、安全感和公平性是更加必要的。专有人工智能系统很难被公众所评价,因此很难识别和修正其中的错误。
开源原则在软件开发中的益处
开源软件(OSS)的基本思想是:一个组织不仅依靠其内部知识来源和资源进行创新,而且还利用多种外部技术来源,如软件包、缺陷报告、客户反馈、公布的专利或社区[2]。取决于所选择的许可证,开源软件可能不排除商业化:公司可以将开源软件与其他产品和服务结合起来,以创造收入(例如,RedHat免费提供Linux,但在高品质服务支持中收费,Amazon免费提供Apache服务,但为云托管服务收费,等等)。目前,开源模式保障了软件开发的有效性和效率。然而,这一模式花了几十年的时间才成熟,企业才实现并充分利用其潜力[3]。此外,开源软件的一个重要教训是,政府在促进采用开源软件方面发挥了重要作用[4]。这意味着许多促进开源人工智能的方法将受益于政府发挥的积极作用。
从可访问性、协作性、责任性和互操作性方面来看,开源软件在专有软件方面提供了若干好处[5]。首先,专有软件大多在支付许可费下提供使用。相比之下,开源软件是免费的,在使用、检查和修改方面没有任何的或有限的限制。第二,开源软件往往由一个社区开发和维护。开源软件社区的多样性促进软件质量的提高、更快的创新和开源软件开发相对于专有替代品的创造性的提高[6]。第三,观测系统中的错误是通过日常使用来检测和纠正的,而且比闭路软件中的错误快得多[7],从而使开源软件适用于关键和高度可靠的技术系统。第四,开源软件通常依靠开放标准和模块化,这使软件组件之间的依赖性脱钩,并导致更多的可重用性和互操作性[6]。
除了节省成本外,公司还以多种方式从开源软件中获益。公司可将低成本的开源软件作为其支柱,然后围绕互补性货物和服务建立业务模式[8]。此外,公司可以通过为开源软件作出贡献获得信任和声誉,开源软件吸引顶级人才,并促进其自身技术和产品的传播。通过参与开源软件活动,公司还可以指导创新的方向,并控制其所依赖的技术的进一步发展(例如,通过采用有助于公司更有效竞争的标准)。通过对开源软件作出贡献,公司还获得了关于其技术的宝贵反馈,并能够在产品的早期发现潜在问题。最后,开源软件的存在推动了商业解决方案的创新和竞争力。
推广开源人工智能技术
开源人工智能的发展与开源软件的发展有着若干相似之处。然而,也有一些重要的差异,需要有针对性的方法来构建开源人工智能。传统软件的编程有明确的规则来执行任务,而人工智能则被编程来学习执行任务。因此,人工智能技术有三个基本组成部分:用于培训的数据集、用于正式确定培训任务的源代码,以及最终存储经过培训的权重的模型。此外,培训人工智能模型需要大量的硬件资源,带来了很高的运行成本。此外,使用人工智能可能使社会面临巨大风险(例如恶意使用人工智能制造错误信息),这就要求对开源人工智能技术采取负责任的社会方法。下面我们讨论一个针对开源人工智能的定制方法,通过促进(1)可访问性,(2)协作性,(3)责任性和(4)互操作性来补充专有人工智能(见图1)。
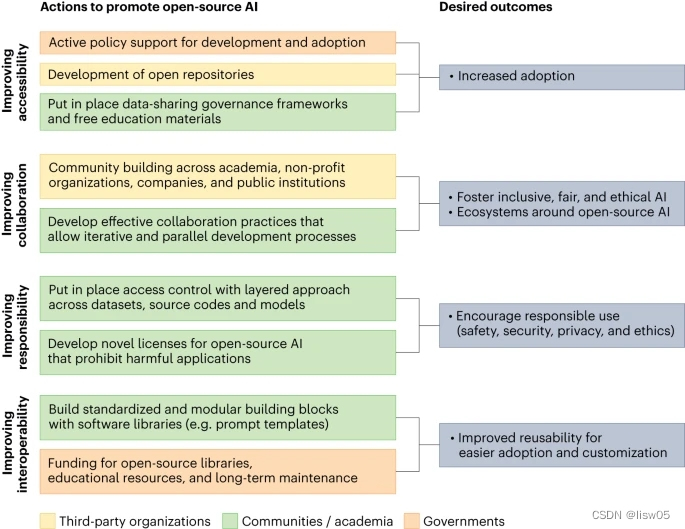
图1 建立开源人工智能的关键方法:建议相关行动应促进可访问性、协作性、责任性和互操作性。
改善可访问性
为了促进可访问性,政策制定者应积极鼓励开发和采用开源人工智能。由于人工智能创新的资本密集程度远远高于常规软件开发,鉴于建立当代人工智能模型对数据和基础设施的需求,需要额外资源(如资金和获取大规模基础设施和数据)来启动和扩大开源人工智能技术。重要的是,现有的计算资源往往不够大,无法建立与营利性公司相当的最先进的人工智能技术。例如,据估计,发展大语言模型的工作费用在3亿至4亿欧元之间。另一个限制因素是,即使提供了资源,但这些资源往往与学术界有关,因此其他利益相关者,如寻求利用人工智能实现社会福利的机会的非营利组织,也无法利用这些资源。一个有前途的反例是美国路线图,它提供了更广泛的使用计算资源的机会,包括公私伙伴关系。由于缺乏资源,科学家目前往往无法复制从公司获得的人工智能技术,因此这些路线图有助于促进重复性(例如,通过机器学习重复性挑战)。
为了扩大获取数据和模型的渠道,政策制定者可以支持开发开放的数据仓库,以便在可信和负责任的治理模式下提供托管服务。重要的是,公共机构的开放数据集往往规模很大,来源多样,对实践有益。此外,公共机构可以积极鼓励数据共享伙伴关系,这种伙伴关系与联邦学习相结合,可以跨机构促进人工智能,同时保护数据隐私。例如,德国政府最近成立了一个《流动数据空间》,使汽车产业的不同利益相关者(例如公共交通公司、私人汽车共享提供商和汽车制造商)能够获得共享数据,甚至竞争对手的数据。
然而,数据共享带来了挑战。首先,开放数据集增加了侵犯隐私的可能性,并提出了与保密、数据虚假陈述和知情同意有关的道德问题。第二,组织公开数据,在分发权和确认捐助人方面保持公平,是一项挑战。幸运的是,最近在制定治理框架以应对这些挑战方面取得了进展,例如《FOT-Net数据共享框架》,根据《欧盟一般数据保护条例》、专为连接式自动驾驶而设计。这些框架可以成为在应对道德、法律和组织挑战的同时改善可访问性的有益起点。
最后,许多关于最先进的人工智能的教育材料由营利性公司(如Coursera和Udemy)管理,往往隐藏在付费墙后面。因此,为了促进采用开源人工智能,需要作出更大的努力,改善获得高质量教育材料的机会。由于上述原因,进入贡献和获取人工智能应用程序的障碍将大幅减少。
改进协作性
人工智能技术可由开发者、用户和利益相关者组成的多元化和包容性社区共同开发和维护。这种协作方法可以大大降低开发成本,并有助于解决规模扩大问题。这将使利益相关者广泛参与,使人工智能的未来更具包容性和更公平。
为了促进开源人工智能技术的合作,应采取明确步骤,在学术界、非营利组织、公司和公共机构中建立社区。鉴于开发人工智能模型不太容易分解为较小的任务,而且任务划分比标准软件开发更困难,需要进一步努力开发合适的协作实践,以便能够进行更多的迭代和并行开发流程。在这里,《大科学项目(BigScience)》的经验教训[9]--在其中有超过一千名志愿科学家聚集在一起,开发一个名为“BLOOM”的大语言模型[10]--应该是有价值的。此外,政策制定者应资助大规模的科学计划项目,以生产开源的大语言模型,作为专有大数据模型的补充。
在大学、研究中心、政府和工业之间建立协同增效工作和网络,可能会在开源人工智能周围建立新的生态系统,成为未来创新的推动力。建立这种生态系统对初创公司和中小型企业特别重要[11],因为他们通常缺乏促进人工智能技术的专用基础设施和能力。
改进责任性
必须对人工智能技术的滥用设置明确的障碍。为此目的,需要类似于开放数据的现有规范的访问控制,以强制在实践中负责任地使用开源人工智能。这方面的例子是MIMIC-III:一个大型、免费提供的与健康有关的数据集。鉴于医学数据的敏感性,只有在研究人员接受了强制性的道德培训之后,MIMIC-III才对他们开放。同样,开源人工智能的访问控制应包括一种分层的方法,在数据集、源代码和模型之间有适当的差异,以确保负责任的使用,同时将安全、安保和隐私考虑在内。
此外,还需要新的许可证--这是受开源软件的启发而设计的,但却是针对开源人工智能精心设计的[12]。这种许可证必须确保广泛的用户访问,同时执行禁止恶意做法的准则(例如通过自动开展宣传运动滥用大语言模型)。此外,这类开源人工智能的许可证应包括界定许可和限制性使用以及技术如何能够或不能被重新使用的分条款。最显著的例子是RAIL许可证,为了防止人工智能技术的不负责任和有害的应用,它只对某些用例给予许可。随着时间的推移,可以开发开源人工智能许可证的定制变体,从而更加限制人工智能技术的高风险应用。
与开源软件类似,根据开源原则开发和使用人工智能技术将特别有效地解决人工智能系统中的偏见,并引导创新朝着公平、符合道德和值得信赖的方向发展。首先,由于世界各地利益相关者投入的多样性,将更加重视消除偏见。在管理数据集时,消除偏见与培训模型时一样重要。其次,一个共同的担忧是,开源人工智能可能没有与专有解决方案一样的质量控制和测试水平,导致其开发人员意外引入潜在的错误。为此,协作非常重要,因为它会自然导致广泛的测试。
此外,在开放社区发展人工智能可能会引入分权组织(即没有基于雇用合同的权力等级体系)。许多开放社区已经建立了有效的组织结构,其基础是能力、努力和专门知识,能够有效地解决协调与合作问题,包括如何管理冲突。例如,Debian社区构成了决定捐助者的决策权、以及社区在发生冲突或责任问题时可以参考的一套规则。可以将Debian等社区的经验教训纳入开源人工智能社区的职能组织结构和有效治理。同样,鉴于通常没有指定机构来维持对法律框架的遵守,而且有关问责的问题往往不明确,因此可能存在来自于遵守监管的法律挑战。尽管如此,开源人工智能技术带来了重要的原则,超出了现有的监管框架,以负责任和值得信赖的方式使用人工智能。
还值得注意的是,与使用开源人工智能有关的隐私和安全威胁。例如,恶意行为者可以执行后门攻击,其中他们操纵一小部分培训数据,使人工智能模型学习额外的隐藏功能[13]。一般而言,开源人工智能中的漏洞往往是公共知识,这使得不仅容易攻击,也更容易识别攻击。此外,如果开源人工智能被用于邪恶目的,社会也会面临风险。这方面的例子包括利用公开来源的人工智能技术发展武器和人工智能制造的宣传运动[14]。尽管如此,其好处很可能超过开源人工智能的缺点,特别是如果如上文所述,采取负责任的开源方法,对滥用设置明确的障碍。
提高互操作性
随着时间的推移,人工智能技术将需要建立在软件库中更标准化和模块化的构建模块(例如提示词模板和大语言模型情况下的标准化提示词优化器)之上,以便能够在下游应用程序中更容易地采用和客户化定制。预培训模型跨平台的互操作性也将大大减少重新培训大模型的必要性。结果将是人工智能技术有更大的可重用性,从而减少了在开发过程中“重新发明车轮”和促进更快迭代的必要性。互操作性不仅对快速构建人工智能应用程序非常重要,而且还可以使高质量的源代码和模型能够以一种负责任和稳健的方式被重用。
在标准化方面,国际标准化组织等各种监管机构正在起草若干旨在使人工智能技术统一协调的标准。当前的举措涵盖生命周期管理、数据质量、风险管理和审计等各个方面。这种标准化路线图有助于在高风险应用中开发可靠的人工智能系统(例如,通过标准化一致性检查)。至关重要的是,必须通过开发人工智能技术的软件库实现标准化。在这方面,可能需要公共资金支持发展开放源代码库,以及相应的教育资源和长期维护。
由于与日俱增的协调化,对特定人工智能技术的依赖将会减少,从而使最终用户能够避免“锁定”效应,并从减少的转换成本中获益(例如,从A公司的大语言模型改为B公司的大语言模型)。对开发人员而言,互操作性最终有助于消除在开发、获取和使用人工智能技术方面日益严重的不平等现象,同时促进有效的竞争。在这方面,从企业的角度来看,一个令人关切的问题可能是,如果人工智能研究被迫开放,那么公司就可能看不到投资于研究和开发的价值,因为它们本来会这样做。例如,公司开发新的人工智能技术的动机可能会在有开源替代品的情况下降低,这可能会阻碍更广泛的创新,并最终导致老牌公司的守门行为。然而,我们认为,开源人工智能对专有替代品的补充可能增加健康的竞争,还能带来更好的商业产品。
对开源人工智能技术的一种呼吁
我们认为,公司和社会可以从发展开源人工智能技术来补充专有替代物中获得巨大的利益。在数据集、模型和源代码之间广泛采用开源原则,将促进人工智能技术的可访问性、协作性、责任性和互操作性,并将有助于扭转人工智能研究中日益严重的不平等现象,从而降低今后创新的困难度。
文献引用:Shrestha, Y.R., von Krogh, G. & Feuerriegel, S. Building open-source AI. Nat Comput Sci 3, 908–911 (2023). Building open-source AI | Nature Computational Science
参考文献
- Aghion, P., Harris, C., Howitt, P. & Vickers, J. Rev. Econ. Stud. 68, 467–492 (2001).
[2]Chesbrough, H. W. Open Innovation: the New Imperative for Creating and Profiting from Technology (Harvard Business Press, 2003).
[3]Fitzgerald, B. MIS Q. 30, 587–598 (2006).
[4]Lerner, J. & Schankerman, M. The Comingled Code: Open Source and Economic Development (MIT Press, 2013).
[5]Haefliger, S., Von Krogh, G. & Spaeth, S. Manage. Sci. 54, 180–193 (2008).
[6]Von Krogh, G. & Von Hippel, E. Manage. Sci. 52, 975–983 (2006).
[7]Paulson, J. W., Succi, G. & Eberlein, A. IEEE Trans. Softw. Eng. 30, 246–256 (2004).
[8]Golden, B. Succeeding with Open-Source (Addison-Wesley Professional, 2005).
[9]Akiki, C. et al. BigScience: a case study in the social construction of a multilingual large language model. In NeurIPS Worksh. on Broadening Research Collaborations in ML (NeurIPS, 2022).
[10]BigScience Workshop (Scao, T. L. et al.) BLOOM: A 176B-parameter open-access multilingual language model. Preprint at https://arxiv.org/abs/2211.05100 (2022).
[11]Jacobides, M. G., Brusoni, S. & Candelon, F. Strat. Sci. 6, 412–435 (2021).
[12]Contractor, D. et al. Behavioral use licensing for responsible AI. In ACM Conf. on Fairness, Accountability, and Transparency (FAccT) (ACM, 2022).
[13]Saha, A., Subramanya, A. & Pirsiavash, H. Hidden trigger backdoor attacks. In AAAI Conf. on Artificial Intelligence (AAAI, 2020).
[14]Feuerriegel, S. et al. Nat. Human Behav. (in the press).