Dual Gated Graph Attention Networks with Dynamic Iterative Training for Cross-Lingual Entity Alignment
双门控图注意力网络与跨语言实体对齐的动态迭代训练
Abstract
近年来,跨语言实体对齐引起了相当大的关注。过去使用传统方法来匹配实体的研究都有一个共同的问题,即在建模过程中遗漏了实体之外的重要结构信息。这使得图神经网络模型可以介入。大多数现有的图神经网络方法分别对个体知识图(KG)进行建模,并使用少量预先对齐的实体作为锚点来连接不同的知识图谱嵌入空间。,然而,这一特性可能会导致几个主要问题,包括由于可用种子对齐不足而导致的性能限制以及对节点之间上下文信息有用的预对齐链接的忽略。在本文中,我们提出了 DuGa-DIT,一种具有动态迭代训练的双门控图注意力网络,以在统一模型中解决这些问题。 DuGa-DIT 模型通过使用 KG 内注意力和跨 KG 注意力层来捕获邻域和跨 KG 对齐特征。通过动态迭代过程,我们可以动态更新跨KG注意力得分矩阵,这使得我们的模型能够捕获更多的跨KG信息。我们对两个基准数据集和跨语言个性化搜索的案例研究进行了广泛的实验。我们的实验结果表明 DuGa-DIT 优于最先进的方法。
1 INTRODUCTION
我们每天产生的数据量以及当今互联网用户可用的信息量令人震惊且不断扩大。根据 Raconteur 的统计数据,预计到 2025 年,全球每天将产生约 463 艾字节(1EB=1024PB=2^60B)的数据。此外,目前有超过 18 亿个网页处于活动状态,并通过万维网和搜索引擎相互链接。大多数这些成功的社交网站、物联网(IoT)和搜索引擎,最重要的分母是利用知识图谱(KG)在结构上实现有效的数据存储和信息检索。每个个人、团体或企业都将信息组织和提炼成自己的、具有有限复杂性的知识形式。然而,从更广泛的角度来看,我们普遍认为知识图谱是指相互关联的实体及其关系的集合,以资源描述框架(RDF)表示,可以通过本体获取、集成和发现信息。从数学角度来看,我们将知识图谱定义为有向异构多重图,其节点代表实体,边代表节点之间的语义关系。
在自然语言处理和信息检索研究领域,知识图谱已成功支持许多下游任务,例如语言建模、问答以及个性化搜索和推荐。到目前为止,那些开源的大规模知识图谱如Freebase、DBpedia、WordNet、COVID-19 KG 和 Google KG 也已被广泛实施到许多特定的现实场景中。例如,根据公开数据,Google KG 目前包含超过 5000 亿个三元组形式的事实来支持其 Google 网络搜索。COVID-19 KG支持了药物和疫苗、疾病检测、病毒溯源、病毒传播、防疫等方面的研究。尽管这些知识图谱已被广泛采用,但最大的挑战之一是这些现有知识图谱中仍然存在许多缺失的事实。由于这些知识图谱之间的高度不完整性,导致知识图谱在现实场景中的性能和有效性受到很大影响。在一些关键应用中,例如临床决策支持,关键节点或信息的缺乏甚至会导致严重后果。
为了解决前面提到的问题,一种直接的解决方案是有效学习 KG Embedding,然后使用嵌入的表示来预测缺失的链接,称为知识图嵌入任务(KGE)。这些KGE模型的例子主要包括基于翻译的TransE模型及其各种扩展TransH、TransD和TransR;DistMult 和 ComplEx 的复杂模型;基于多层卷积神经网络(CNN)的 ConvE 和 ConvKB 模型;基于图神经网络(GNN)的 A2N、R-GCN 和 KBGAT 模型,以及其他一些不同的方法,例如 RotatE、QuatE、CapsE 和重新开始。尽管这些模型擅长提供有希望的实验结果,但这些方法仍然仅限于单个 KG 上的 KGE 任务。
最近,鉴于众包策略和人类参与知识图谱构建,出现了许多用不同语言编写的知识图谱,例如 YAGO 、DBPedia 和 BabelNet 。尽管这些多语言知识图谱的构建方式多种多样,但它们之间存在一定的联系。如果我们能够在这些分布式多语言知识图谱之间进行有效的对接,形成规模更大、覆盖范围更高的知识图谱,这将是解决这些不完整的单一知识图谱存在的问题的一种可行方案。同时,它也可能是另一个令人兴奋的研究方向。此外,这些高度集成的多语言知识图谱可以显着有益于许多跨语言自然语言处理和信息检索任务。本文主要从KG对齐的角度来解决单个KG的不完整性问题。
多语言知识图谱对齐旨在将实体与不同语言知识图谱中的对应实体进行匹配。一般来说,传统的实体对齐模型严重依赖于提取特征和机器翻译的质量,这限制了它们的模型性能在异构数据场景和多语言实体对齐任务上的鲁棒性。例如,对于基于平移的模型和复杂模型等传统模型,由于其浅层结构,这些模型的表现力和特征提取的多样性一直是一个问题,除非嵌入大小增加。后来,尽管 CNN 方法表现出了更好的结果,但它们仍然缺乏对实体之外的重要结构信息进行建模。这为强大的基于 GNN 的方法开辟了一条途径,用于学习实体本身及其邻近特征的实体表示。,然而,大多数现有的基于 GNN 的方法都对每个单独的 KG 分别进行建模,并使用少量预先对齐的实体作为锚点来连接不同的 KG 嵌入空间。这一特性导致了两个主要问题。首先,这些方法通常受到 KG 提供的种子比对不足的限制。其次,这些现有方法往往忽略节点之间上下文信息中有用且预先对齐的链接。直观上,不同 KG 之间的等效实体应该共享尽可能多的预先对齐的邻居。例如,在图1中,尽管中文实体“哥威迅语(Gothic language)”和英文实体“Gothic language”在机器翻译后具有相同的形式,但实际的实体对齐对应该是“哥威迅语(Gothic language)”和““Gwich’in language”。借助知识图谱中现有的其他上下文信息和对齐方式,我们可以从“(United States)”和“United States”、“加拿大(Canada)”和“Canada”,“纳-德内语系”和“Na-Dene languages”、“德内语支(German language branch)”和“Athabaskan languages”等等。
鉴于前面提到的问题,GM-EHD-JEA 提出了一种从易到难的方法,旨在首先预测模型置信对齐作为附加输入,然后预测剩余的硬对齐。尽管基本原理很好,但他们的模型依赖于两阶段推理和联合实体对齐,这需要较高的计算成本和较大的搜索空间。最近,我们提出了一种上下文对齐增强交叉图注意网络(CAECGAT)来解决前面提到的现有基于 GNN 的方法的问题。在这项初步研究中,我们设计了一个系统,通过使用预先对齐的种子在知识图谱之间传播信息来共同学习不同知识图谱中的嵌入。与 GM-EHD-JEA 相比,我们提出的 CAECGAT 更有效。然而,我们发现由于缺乏预先对齐的实体对,这项初步研究在跨知识图谱传播信息方面仍然面临一定的挑战和问题。以图1为例,如果中文实体“哥特语言”和英文实体“哥特语言”周围没有邻域对齐,则初步的CAECGAT模型无法传播跨KG信息。为了解决上述挑战,我们提出了 DuGa-DIT,一种具有动态迭代训练的双门控图注意网络(GAT),用于本研究中的跨语言实体对齐,它能够在统一的框架中缓解所有这些问题。具体来说,双KG注意力层由一个KG内注意力层和一个跨KG注意力层组成。知识图谱内注意层的作用是学习每个知识图谱的邻域特征,跨知识图谱注意层的作用是收集两个知识图谱之间的对齐信息。通过堆叠多个双KG注意力层,局部邻域和跨KG对齐信息可以传播到多跳邻居。由于跨 KG 注意力聚合层,我们提出的 DuGa-DIT 模型能够在训练和预测过程中充分利用预对齐的实体对。此外,通过应用动态迭代训练过程,我们可以动态更新跨知识图谱注意力得分矩阵,从而允许在不同知识图谱之间进行更多的跨知识图谱信息传递。我们对两个基准数据集和跨语言个性化搜索和推荐的案例研究进行了广泛的实验。
本研究的主要贡献总结如下:
- 我们提出了用于跨语言实体对齐的 DuGa-DIT,它可以学习跨知识图谱嵌入,通过利用邻域特征和跨知识图谱对齐信息来弥合不同知识图谱之间的语义差距。
- 我们开发了一个动态迭代训练过程,通过迭代添加新的种子对齐来动态更新跨 KG 注意力分数矩阵,从而允许在不同 KG 之间进行更多的跨 KG 信息传输。
- 我们对两个跨语言实体对齐的基准数据集进行了广泛的实验。实验结果表明,我们提出的方法对于实体对齐任务是有效且稳健的。
本文其余部分的结构如下。第 2 部分介绍了我们的研究背景。第 3 节详细阐述了我们提出的 DuGa-DIT 模型的方法。第 4 节描述了我们在本研究中应用的数据集和实施细节以及所有实验结果和分析。最后,第五节总结了本文,并对未来的工作提出了一些建议。
2 RELATEDWORK
为了解决我们提出的方法正在解决的多语言实体对齐问题,我们在此主要讨论相关工作的两个子领域:KGE 和多语言 KG 对齐。下面对这两组现有文献进行详细讨论和分析。
2.1 Knowledge Graph Embedding
KGE 旨在将 KG 的实体和关系嵌入到连续向量空间中。 Embedding的目的是继承KG实体原有的结构,简化以后操作它们的过程。随着知识图谱数量和规模的快速增长,知识图谱生成在知识图谱分析和语义数据建模任务中变得越来越重要。
2.1.1 基于翻译的方法。 基于翻译的模型被认为是解决 KGE 问题的主要方法之一。Bordes等人提出了最具代表性的平移距离方法,命名为TransE。TransE 功能强大,有望预测链接、对三元组进行分类,并根据一对一关系对大规模 KG 进行建模。也是展示KG建模可行性的先驱。对于所有三元组 ( h , r , t ) (h, r, t) (h,r,t),所提出的 TransE 模型遵循 h + r ≈ t h + r \approx t h+r≈t 的假设。由于TransE的结构和假设很简单,因此该模型无法建模实体之间的复杂关系,例如1对N、N对1或N对N关系。从那时起,TransE 的许多变体被引入。然而,值得注意的是,在这些最新方法中,模型性能和模型复杂性之间存在权衡。这些关系翻译表示的新方法比 TransE 取得了更有希望的结果,尽管由于模型的复杂性,计算成本相对较高。为了提高知识图谱中标记和未标记实体的嵌入的表达能力,以及解决知识图谱的异质性和不平衡性,提出了 TranSparse来解决这两个问题。在TranSparse中,传统的传递矩阵被改为自适应稀疏矩阵。这些矩阵的稀疏度是由链接各种关系的实体的数量生成的。
2.1.2 语义匹配方法。 语义匹配方法是指使用向量或矩阵计算语义相似度的一组模型。RESCAL是第一个结合三向张量分解的知识嵌入模型。双线性是关系被建模为矩阵而实体与向量相关联的代表。当从双线性目标学习嵌入时,DistMult捕获了最佳的关系语义。此外,关系的复合特征是矩阵的乘法。与 DistMult 类似,作为 RESCAL 的扩展,ComplEx提出通过使用复值嵌入来解决对称或不对称的二元关系问题。在这一类别中,还存在一些通过神经网络增强的语义匹配模型。SME首先提出通过使用神经网络中的线性和双线性匹配块来编码实体和关系的交互。NTN是 Klein 等人改进模型的基础。具有多语言曝光。KrompaB将类型约束先验知识纳入各种最先进的潜在变量方法中,以增强链接预测的实验结果。KR-EAR区分单个知识库中的属性和关系以进行知识表示,以对实体、关系和属性的相关性和预测进行建模。其他相关工作包括但不限于 HOLE 和 ProjE。
2.1.3 基于 CNN 的方法。 KGE 的另一个主要方法是应用基于 CNN 的多层模型来生成更具表现力的嵌入,因为它具有高参数效率。 ConvE 使用 2D 卷积运算来模拟头部实体及其关系之间的局部交互。ConvE 能够通过使用多个非线性特征学习将头部实体和各自的关系重塑为 2D 矩阵来表达语义信息。ConvKB 由 Nguyen 等人提出。以三列矩阵格式表示三元组,并将它们输入CNN以过滤掉不同的特征图。然后,通过合并前面的特征图来生成特征向量,以显示三元组的表示,然后与权重向量相乘以生成最终分数。因此,ConvKB 能够捕获全局关系以及节点和关系之间的平移特征。InteractE通过增加实体和关系嵌入之间的交互进一步提高了前一个模型的性能。尽管这些方法在学习更具表达性的特征方面显示出显着的改进,但它们都有独立考虑每个三元组的缺点,因此会丢失来自知识图谱的大量潜在信息。除了这些模型之外,RSN和 CTEA 也是利用基于 CNN 的深度神经网络模型来解决 KGE 问题的示例。此外,还提出了上下文感知 CNN,以结合邻域信息来改进 KGE 结果。此外,CapsE 、CoKE 和 ReInceptionE 也是属于此类别的基于 CNN 的 KGE 模型。
2.1.4 使用邻域信息的方法。 基于邻域信息的模型通过针对实体的邻域信息来学习嵌入。最近,许多采用这种方法的研究表明 KGE 任务的性能得到显着提升。A2N 使用注意力机制来获取特定于查询的邻居。R-GCN是第一个使用GCN对KG中的多关系数据进行建模的模型。KBGAT建议使用GAT 为邻居分配不同的重要性。TransE-NMM通过考虑相邻实体来扩展 TransE。通过门控机制,NKGE 吸收特定实体的语义和拓扑特征来完成 KGE 任务。SACN 是在 GCN 和 ConvE 之上构建的,以在局部聚合中学习更丰富的邻域信息,从而获得更准确的表示。
2.1.5 使用关系路径/文字的方法。 此外,一些研究采用基于关系路径的方法来学习和改进知识图谱的嵌入。DeepPath 采用强化学习的方法来捕获具有全局信息的多跳关系路径。RTransE 和 PTransE 使用多步关系路径来完成 KG,而 SimplE 和 RotatE 遵循相同的双线性模型路径来解决该问题。除此之外,还有许多关于使用文字来学习 KGE 的建议模型的研究。TransEA 利用属性嵌入模型和基于翻译的嵌入模型的组合来同时联合学习实体关系和数字属性。LiteralE 建立在现有潜在特征方法之上,通过堆叠额外的简单模块来扩展链接预测任务,以通过参数化函数将文字直接合并到嵌入学习中。 KBLRN 通过将神经表示学习与专家模型的概率乘积相结合,创新地集成了潜在数据、关系数据和数值数据的不同特征类型。
2.1.6 总结与比较。 综上所述,KGE 模型的五个主要类别各有优缺点。基于翻译的模型在学习嵌入的同时具有很强的保留结构信息的能力。然而,由于这些模型的复杂性,计算成本相对较高。基于语义的模型具有浅层结构,可以快速且轻松地扩展到整个知识图谱,但它们也牺牲了捕获更具表现力的特征的能力。基于关系路径的模型能够利用跨越所有关系路径的实体关系的长期依赖性;然而,它们的特征表达仍然有限。引入基于 CNN 的模型是因为基于深度学习的模型通常在学习表达特征方面更强大,但大多数研究单独考虑每个三元组,并从 KG 中丢失了许多有价值的潜在信息。尽管属于基于邻域的模型类别的现有模型在 KGE 任务上取得了更有希望的结果,但它们也主要在两个方面存在缺点:(1)大多数这些模型仅考虑特定实体的入站方向邻居,并且倾向于忽略来自出站定向邻居的信息丰富的上下文,并且(2)大多数这些模型仅应用第 k k k 跳输出来学习多跳嵌入,这会损失大量早期阶段的嵌入在图注意力的步骤中嵌入信息。
2.2 Multilingual Entity Alignment
除了 KGE 之外,与本研究相关的另一项研究是跨各种不同语言调整实体。传统的实体对齐方法主要以人为中心,以时间、劳动力和灵活性为代价。然而,随着 KG 的规模随着时间的推移而广泛增长,之前提出的方法已经变得越来越重要。由于升级而更加不适用。
为了克服这些传统方法的局限性,研究人员最近利用深度学习算法开发了许多先进的模型。根据模型是否接受结构信息、邻域信息或知识图谱之外的额外信息,我们可以将现有模型进一步分为三大类,即基于嵌入的方法(A 组)、基于邻域信息的方法(B 组)和使用结构之外的额外信息的方法(C 组)。
2.2.1基于嵌入的方法。 基于嵌入的模型从嵌入特征中学习KG嵌入,将实体之间的关系视为头部和尾部实体之间的转换。
对于多语言实体对齐任务,JE 和MTransE 是属于这一类别的最早的经典模型。JE 只使用KG的结构来学习不同KG的统一向量空间。MTransE 建立在transE之上,是一项重要的工作,它将单个语言的实体和关系分别嵌入到嵌入空间中,然后通过学习其转换并最小化不同KG中种子对齐嵌入之间的距离将它们映射到多语言对应物中。为了更深层次地利用未标记的数据,IPTransE 通过应用迭代方法来优化MTransE模型,以添加新的比对作为训练数据。然后将具有相同参数的不同语言的实体和关系映射到统一的向量空间中。
由于标记数据在KG中非常有限,因此已经出现了利用半监督学习,协同训练和自举方法来更有效地利用未标记数据的趋势。SEA 提出了一种半监督实体对齐方法(SEA),将来自标记实体和未标记实体的信息带入实体对齐任务的分析中。BootEA 使用改进的KGE方法和基于限制的损失和自举技术来解决实体对齐任务中缺乏标记数据的问题。与IPTransE 类似,它也应用迭代方法来添加新的比对作为训练数据。
其他基于嵌入的方法包括AKE,它使用对抗知识嵌入来联合学习表示,对齐映射和对抗模块; MMEA ,它使用新的乘法方法来联合建模来自不同KG的实体和关系; JarKA,它利用属性来学习实体嵌入; OTEA,它使用基于最佳传输的方法来双重优化实体级和组级损失。
2.2.2 基于邻域信息的方法。 最近,我们的研究社区提出了更多基于图的方法来聚合邻域信息,以丰富知识图谱的嵌入。GM 将实体及其邻居表示为主题实体图,并将实体对齐任务视为图匹配问题。他们使用基于图注意力的方法来匹配两个主题实体图中的所有实体。KECG采用具有共享参数的GAT将不同KG中的实体嵌入到统一的向量空间中,并联合应用TransE来隐式完成不同的KG。
MuGNN 使用基于规则的方法来完成 KG,并使用多通道图注意力来协调两个 KG 之间的结构差异。 AliNet 使用门控和注意力机制来聚合多跳邻域信息。换句话说,它考虑了对应实体邻居之间存在的异质性和差异性,并将实体邻居结构之间的重叠扩展到基于注意力的远程邻居。最终的实体对齐是通过远程和直接邻居之间的门控机制以及关系损失计算来实现的,以改进实体表示。HGCNJE 通过使用 GCN 学习到的实体嵌入来近似关系嵌入,并联合学习实体和关系的更好表示。
MRAEA 使用关系感知自注意力机制来学习关系感知表示,并采用双向迭代策略来迭代添加新的对齐方式进行训练。NAEA 设计了一种注意机制来收集邻域子图级别的邻域信息,并引入了 NAEA 邻域感知注意表示方法来学习邻域表示。RDGCN 使用GCN 通过利用KG与其对偶关系对应物之间的关系交互来合并关系信息。GM-EHD-JEA 使用从易到难的解码策略来迭代预测新的对齐作为附加输入,并使用联合实体对齐算法来解决多对一问题。NMN 应用 GCN 和邻域采样方法来捕获信息丰富的邻域特征。REA使用强化训练方法来处理实体对齐任务中的噪声标签。SSP 使用 GCN 和基于翻译的模型来捕获全局和局部特征。HyperKA 将 GCN 从欧几里德空间扩展到双曲空间,以更好地建模 KG 的层次结构。AttrGCN 使用属性 GNN 在统一框架中学习属性三元组和关系三元组。
CAECGAT 是一种上下文对齐增强的跨GAT方法,用于跨语言实体对齐。我们的初步研究设计了一个系统,通过使用预先对齐的种子在知识图谱之间传播信息来共同学习不同知识图谱中的嵌入。然而,我们发现在训练和预测阶段传播多跳邻居的信息并充分利用预对齐的实体对非常重要。如果我们进行进一步的调查,模型的性能可以进一步提高。因此,我们计划通过以下三种方式扩展我们的 CAECGAT 研究:(1)我们提出用于跨语言实体对齐的 DuGa-DIT,它可以学习跨 KG 嵌入,通过跨语言传输信息来弥合不同 KG 之间的语义差距。 KGs可以通过动态更新跨KG注意力得分矩阵来很好地与迭代训练方法配合使用; (2)我们更深入地在更多数据集和各种场景上进行实验;(3)我们从KGE任务角度和跨语言实体对齐角度分析相关工作,并以个性化搜索和推荐为例。与之前匹配两个子图之间的一跳邻居的邻域匹配方法不同,我们的 DuGa-DIT 能够传播多跳邻域信息和跨 KG 对齐信息。还有其他相关模型属于此类别。
**2.2.3 使用结构之外的额外信息的方法。**除了前面讨论的两种方法之外,还有一些方法旨在获取结构之外的额外信息,例如属性和实体描述。JAPE利用不同语言知识图谱中的结构信息和属性信息,以联合的方式学习实体表示。GCN-Align结合了实体和属性信息,并使用GCN学习实体的邻域信息,并直接学习实体之间的跨KG等价关系。HMAN采用结构、关系和属性等多个方面来学习实体嵌入。他们还使用实体的文字描述并微调预训练的多语言 BERT,以进一步提高性能。然而,他们的方法需要额外的实体描述,并且他们的模型中报告的最佳结果是通过结合 HMAN 和 BERT 模型获得的。为了公平比较,我们只与单个HMAN模型的结果进行比较,而不结合BERT模型。KDCoE提出了两种并行嵌入模型的协同训练,即跨语言KGE模型和跨语言描述嵌入模型。除此之外,JarKA 接收属性信息来执行多语言实体对齐任务。
2.2.4 总结与比较。 总的来说,上述三类学习算法都有各自的优点和局限性。基于嵌入的模型结构最简单,但这些模型的浅层结构对其模型表达能力造成了一定的限制。基于邻域信息的模型通常在实体对齐任务上表现出良好的性能,并通过聚合邻域信息来链接预测任务。然而,这些模型大多数都是为了从固定图中捕获邻域信息而设计的,这在很大程度上限制了捕获不同关系的特定于关系的多跳邻域特征的能力。对于那些使用结构之外的额外信息的方法来说,最大的挑战是额外信息数据可能并非始终可用。在大多数实际应用中,额外的信息要么不可用,要么无法使用。因此,无论模型设计得多么好,其适用性都会受到很大影响。表1总结了本研究涉及的这三个小组的主要方法。
与之前描述的所有方法不同,我们提出的 DuGa-DIT 能够学习跨知识图谱嵌入,并通过利用邻域特征和跨知识图谱对齐信息来弥合不同知识图谱之间的语义差距。我们模型中的动态迭代训练过程允许跨 KG 注意力分数矩阵通过迭代添加新的种子对齐来动态更新。这样的设计使得更多的跨KG信息能够有效地跨不同KG传输。此外,我们的模型纯粹依赖于邻域特征和跨 KG 对齐信息来执行,而不需要额外的额外信息来提高性能。
3 APPROACH
在本节中,我们的目标是详细阐述我们提出的 DuGa-DIT 模型。我们首先描述将在本文其余部分使用的符号以及系统架构的概述。然后,我们提出两个注意层,即知识图谱内注意和跨知识图谱注意,以及可以从前两层产生新实体嵌入的门控特征更新。最后,我们还展示了我们的方法中采用的优化、预测和动态迭代训练过程。
3.1 Problem Formulation
在本节中,我们描述了与我们的工作相关的一些准备工作,并给出了我们工作的问题表述。
一些基本定义如下:
- 知识图谱是由实体、关系和三元组组成的数据结构,表示为 G = ( E , R , T ) G = (E, R,T) G=(E,R,T),其中 E E E 代表实体的集合, R R R 代表关系的集合, T T T 代表三元组的集合。
- 跨语言KG实体对齐是指不同语言的两个KG, G 1 = ( E 1 , R 1 , T 1 ) G_1=(E_1,R_1,T_1) G1=(E1,R1,T1)和 G 2 = ( E 2 , R 2 , T 2 ) G_2=(E_2,R_2,T_2) G2=(E2,R2,T2)的任务,而实体对齐就是推导出一组高精度和高召回率的任务,实体对 ( e 1 , e 2 ) ∈ ( E 1 × E 2 ) (e_1, e_2) \in (E_1 \times E_2) (e1,e2)∈(E1×E2),因此这两对实体可以指代相同的现实世界实体。
3.2 Overview
如图 2 所示,所提出的 DuGa-DIT 的结构由多个双 KG 注意力层组成。每个双KG注意力层由跨KG注意力层和KG内注意力层组成。以两个不同的 KG G1 和 G2 作为输入,以及两个 KG 之间的种子链接集合,我们使用 KG 内注意力来收集邻域特征,并使用跨 KG 注意力来从另一个 KG 收集有用的对齐信息。因此,我们可以获得 KG 内结构和跨 KG 对齐的信息。可以堆叠多个双 KG 注意力层来聚合多跳特征。此外,我们使用动态迭代训练过程来动态更新跨知识图谱实体对齐,这使得我们的模型能够收集更多的跨知识图谱对齐特征。本文的主要符号如表2所示。
形式上,给定两个不同的 KG G 1 = ( E 1 , R 1 , T 1 ) G_1=(E_1,R_1,T_1) G1=(E1,R1,T1)和 G 2 = ( E 2 , R 2 , T 2 ) G_2 = (E_2, R_2,T_2) G2=(E2,R2,T2),以及一组种子对齐 A ˉ = { ( e 1 , e 2 ) ∣ e 1 ∈ E 1 , e 2 ∈ E 2 } \bar{A}=\{(e_{1},e_{2})|e_{1}\in E_{1},e_{2}\in E_{2}\} Aˉ={(e1,e2)∣e1∈E1,e2∈E2},在本文中,我们将两个 KG 中的实体表示为 k k k 维嵌入矩阵 E 1 E_1 E1 和 E 2 E_2 E2。在训练过程中,我们将所有种子对齐分为一组上下文种子对齐 A c t x A_{ctx} Actx 和一组目标种子对齐 A o b j A_{obj} Aobj。 A c t x A_{ctx} Actx中的上下文种子对齐用作跨不同 KG 之间传输信息的桥梁。因此, A c t x A_{ctx} Actx 提供的跨 KG 信息可以用作上下文对齐信息来预测 A o b j A_{obj} Aobj 中客观种子对齐中实体对的匹配分数。
3.3 Intra-KG Attention KG内注意力
最近,GNN 由于其学习知识图谱数据中局部结构的能力,在跨语言知识图谱实体对齐任务中表现出了巨大的潜力。在本研究中,我们使用基于注意力的图注意力机制来学习每个单语言知识图谱的特征,这被称为知识图谱内注意层。
给定两个 KG G 1 G_1 G1 和 G 2 G_2 G2,让 M 1 l \mathbf M^l_1 M1l 和 M 2 l \mathbf M^l_2 M2l表示 G 1 G_1 G1 和 G 2 G_2 G2 的归一化注意力矩阵。KG内注意层用于通过聚合重要的邻域特征来更新每个KG的实体嵌入,可以表示如下:
H 1 l + 1 = σ ( M 1 l E 1 l W l ) H 2 l + 1 = σ ( M 2 l E 2 l W l ) , ( 1 ) \begin{aligned}\mathbf{H}_{1}^{l+1}&=\sigma\left(\mathbf{M}_1^l\mathbf{E}_1^l\mathbf{W}^l\right)\\\mathbf{H}_{2}^{l+1}&=\sigma\left(\mathbf{M}_2^l\mathbf{E}_2^l\mathbf{W}^l\right),\end{aligned}\quad\quad(1) H1l+1H2l+1=σ(M1lE1lWl)=σ(M2lE2lWl),(1)
其中 W l W^l Wl 是变换参数, σ \sigma σ 是激活函数(例如 Relu), l l l 表示第 l l l 层。
归一化注意力矩阵是使用 GAT 计算的,它首先计算每个邻居实体的分数,然后对所有邻居的分数进行归一化。具体地, M 1 l \mathbf M^l_1 M1l中的每个元素计算如下:
M 1 l [ i , j ] = exp ( s i , j l ) ∑ j ′ exp ( s i , j ′ l ) , ( 2 ) \mathbf{M}_1^l[i,j]=\frac{\exp(s_{i,j}^l)}{\sum_{j'}\exp(s_{i,j'}^l)},\quad\quad(2) M1l[i,j]=∑j′exp(si,j′l)exp(si,jl),(2)
其中 s i , j l s^l_{i,j} si,jl 是第 i i i 个和第 j j j 个实体之间的注意力分数,计算公式为
s i , j l = { LeakyRelu ( v T [ e i l ∣ ∣ e j l ] ) e j ∈ N e i − ∞ o t h e r w i s e , ( 3 ) s_{i,j}^l=\begin{cases}\text{LeakyRelu}\left(\mathbf{v}^T\left[\mathbf{e}_i^l||\mathbf{e}_j^l\right]\right)&e_j\in\mathcal{N}_{e_i}\\-\infty&otherwise\end{cases},\quad\quad(3) si,jl={LeakyRelu(vT[eil∣∣ejl])−∞ej∈Neiotherwise,(3)
其中LeakyRelu 是广泛用于图注意力层的激活函数, v \mathbf v v是注意力向量, N e i \mathcal N_{ei} Nei是实体 e i e_i ei的一组邻居, e i \mathbf e_i ei和 e j \mathbf e_j ej分别是实体 e i e_i ei和 e j e_j ej的向量。可以以类似的方式计算 G 2 G_2 G2的归一化注意力矩阵 M 2 l \mathbf M^l_2 M2l。
3.4 Cross-KG Attention
知识图谱内注意层只能从单语言知识图谱中捕获局部结构特征,这对于实体对齐任务来说是不够的。在本节中,我们提出了一种新颖的跨知识图谱注意力层,旨在通过跨两个知识图谱应用图注意力来聚合跨知识图谱对齐信息。在本研究中,我们充分利用预对齐的种子对齐,并将它们视为连接两个 KG 之间的边。
形式上,给定上下文对齐 A c t x A_{ctx} Actx,我们可以使用跨 KG 注意力层构建从 G 1 G_1 G1 到 G 2 G_2 G2 以及从 G 2 G_2 G2 到 G 1 G_1 G1 的交叉注意力矩阵。 让 M 12 \mathbf M_{12} M12表示从 G 1 G_1 G1到 G 2 G_2 G2的注意力矩阵。 M 12 \mathbf M_{12} M12中各元素的获取方式如下:
M 12 l [ i , j ] = exp ( c i , j l ) ∑ j ′ exp ( c i , j ′ l ) + δ , ( 4 ) \mathbf{M}_{12}^l[i,j]=\frac{\exp(c_{i,j}^l)}{\sum_{j'}\exp(c_{i,j'}^l)+\delta},\quad\quad\quad(4) M12l[i,j]=∑j′exp(ci,j′l)+δexp(ci,jl),(4)
其中 σ = 1 e − 8 \sigma = 1e^{−8} σ=1e−8是平滑因子, c i , j l c^l_{i, j} ci,jl是 G 1 G_1 G1中第 i i i个实体和 G 2 G_2 G2中第 j j j个实体之间的跨KG注意力得分,计算如下:
c i , j l = { LeakyRelu ( v T [ e 1 i l ∣ ∣ e 2 j l ] ) ( e 1 i , e 2 j ) ∈ A c t x − ∞ o t h e r w i s e , ( 5 ) c_{i,j}^l=\begin{cases}\text{LeakyRelu}\left(\mathbf{v}^T\left[\mathbf{e}_{1i}^l||\mathbf{e}_{2j}^l\right]\right)&(e_{1i},e_{2j})\in A_{ctx}\\-\infty&otherwise\end{cases},\quad\quad\quad(5) ci,jl={LeakyRelu(vT[e1il∣∣e2jl])−∞(e1i,e2j)∈Actxotherwise,(5)
其中 e 1 i e_{1i} e1i是 G 1 G_1 G1中的第 i i i个实体, e 2 j e_{2j} e2j是 G 2 G_2 G2中的第 j j j个实体, e 1 i l e^l_{1i} e1il和 e 2 j l e^l_{2j} e2jl分别是第 l l l层中 e 1 i e_{1i} e1i和 e 2 j e_{2j} e2j的向量表示。
因此,我们可以通过在注意力得分矩阵 M 12 \mathbf M_{12} M12 上应用图注意力来收集 G 1 G_1 G1 的跨 KG 对齐特征,其表示如下:
C 1 l + 1 = σ ( M 12 l E 2 l W c l ) , ( 6 ) \mathbf{C}_{1}^{l+1}=\sigma\left(\mathbf{M}_{12}^{l}\mathbf{E}_{2}^{l}\mathbf{W}_{c}^{l}\right),\quad\quad\quad\quad(6) C1l+1=σ(M12lE2lWcl),(6)
其中 W c l \mathbf W^l_c Wcl表示跨KG注意力层中的线性变换参数。
类似地, G 2 G_2 G2的跨KG对齐特征计算如下:
C 2 l + 1 = σ ( M 21 l E 1 l W c l ) , ( 7 ) \mathbf{C}_2^{l+1}=\sigma\left(\mathbf{M}_{21}^l\mathbf{E}_1^l\mathbf{W}_c^l\right),\quad\quad\quad(7) C2l+1=σ(M21lE1lWcl),(7)
其中 M 21 \mathbf M_{21} M21是从KG G 2 G_2 G2到 G 1 G_1 G1的注意力得分矩阵,与 M 12 \mathbf M_{12} M12的获取方式类似。
通过应用跨知识图谱注意力,我们可以使两个知识图谱中的等效实体共享一些共同的跨知识图谱特征。 并且这些跨KG的特征可以在两个KG中传播,这将有利于实体对齐任务。
3.5 Gated Feature Update
直观上,邻域特征是对单个知识图谱进行局部建模的资源信息,而跨知识图谱特征是在全局两个知识图谱之间传递对齐特征的资源信息。这样,就可以很大程度上缓解语义差异。因此,邻域和跨 KG 对齐特征对于实体对齐任务至关重要。在我们的模型中,我们将这两种特征合并到门控特征更新机制中,以有效地更新实体嵌入。根据前面的讨论,我们的 DuGa-DIT 模型的更新规则可以表述如下:
E 1 l + 1 = H 1 l + 1 ⋅ g 1 + C 1 l + 1 ⋅ ( 1 − g 1 ) E 2 l + 1 = H 2 l + 1 ⋅ g 2 + C 2 l + 1 ⋅ ( 1 − g 2 ) , ( 8 ) \begin{aligned}\mathbf{E}_{1}^{l+1}&=\mathbf{H}_{1}^{l+1}\cdot g_{1}+\mathbf{C}_{1}^{l+1}\cdot(1-g_{1})\\\mathbf{E}_{2}^{l+1}&=\mathbf{H}_{2}^{l+1}\cdot g_{2}+\mathbf{C}_{2}^{l+1}\cdot(1-g_{2}),\end{aligned}\quad\quad\quad(8) E1l+1E2l+1=H1l+1⋅g1+C1l+1⋅(1−g1)=H2l+1⋅g2+C2l+1⋅(1−g2),(8)
其中 ⋅ \cdot ⋅ 是逐元素乘法, g 1 g_1 g1和 g 2 g_2 g2分别是 G 1 G_1 G1和 G 2 G_2 G2的门机制,它们是通过连接邻域特征和跨KG对齐特征,然后进行非线性变换得到的:
g 1 = θ ( W g [ H 1 l + 1 ∣ ∣ C 1 l + 1 ] + b g ) g 2 = θ ( W g [ H 2 l + 1 ∣ ∣ C 2 l + 1 ] + b g ) , ( 9 ) \begin{aligned}g_{1}&=\theta(\mathbf{W}_{g}\left[\mathbf{H}_{1}^{l+1}||\mathbf{C}_{1}^{l+1}\right]+\mathbf{b}_{g})\\g_{2}&=\theta(\mathbf{W}_{g}\left[\mathbf{H}_{2}^{l+1}||\mathbf{C}_{2}^{l+1}\right]+\mathbf{b}_{g}),\end{aligned}\quad\quad\quad(9) g1g2=θ(Wg[H1l+1∣∣C1l+1]+bg)=θ(Wg[H2l+1∣∣C2l+1]+bg),(9)
其中 θ \theta θ 表示 sigmoid 函数, W g \mathbf W_g Wg 和 b g \mathbf b_g bg 是可训练参数。
在我们的研究中,我们堆叠 L L L 个双 KG 注意力层来传播邻域特征和交叉对齐特征。最后,我们的模型可以产生新的实体嵌入 E 1 L \mathbf E^L_1 E1L 和 E 2 L \mathbf E^L_2 E2L 。
3.6 Optimization and Prediction
跨语言实体对齐任务旨在学习不同语言知识图谱中等效实体的紧密表示。 与现有方法不同,我们使用上下文种子对齐作为输入,并使用目标种子对齐来优化参数。 本研究中的损失函数定义如下:
L ( ϕ ; A o b j ) = ∑ ( e 1 , e 2 ) ∈ A o b j [ D ( e ˉ 1 , e ˉ 2 ) + λ − D ( e ˉ 1 , e ˉ 2 − ) ] + + ∑ ( e 1 , e 2 ) ∈ A o b j [ D ( e ˉ 1 , e ˉ 2 ) + λ − D ( e ˉ 1 − , e ˉ 2 ) ] + ( 10 ) \begin{aligned}\mathcal{L}(\phi;A_{obj})&=\sum_{(e_{1},e_{2})\in A_{obj}}[D(\bar{\mathbf{e}}_{1},\bar{\mathbf{e}}_{2})+\lambda-D(\bar{\mathbf{e}}_{1},\bar{\mathbf{e}}_{2}^{-})]_{+}\\&+\sum_{(e_{1},e_{2})\in A_{obj}}[D(\bar{\mathbf{e}}_{1},\bar{\mathbf{e}}_{2})+\lambda-D(\bar{\mathbf{e}}_{1}^{-},\bar{\mathbf{e}}_{2})]_{+}\end{aligned}\quad\quad\quad(10) L(ϕ;Aobj)=(e1,e2)∈Aobj∑[D(eˉ1,eˉ2)+λ−D(eˉ1,eˉ2−)]++(e1,e2)∈Aobj∑[D(eˉ1,eˉ2)+λ−D(eˉ1−,eˉ2)]+(10)
其中 [ x ] + = m a x { 0 , x } [x]_+ = max\{0, x\} [x]+=max{0,x}, ϕ \phi ϕ表示 DuGa-DIT 模型中的参数, ( e 1 , e 2 − ) (e_1, e^−_2 ) (e1,e2−) 和 ( e 1 − , e 2 ) (e^−_1, e_2) (e1−,e2) 是随机替换得到的负实体对齐对 正实体 e 1 e_1 e1 或 e 2 e_2 e2, e ˉ 1 ∈ E 1 L \mathbf{\bar{e}}_{1}\in\mathbf{E}_{1}^{L} eˉ1∈E1L 和 e ˉ 2 ∈ E 2 L \mathbf{\bar{e}}_{2}\in\mathbf{E}_{2}^{L} eˉ2∈E2L 是 e 1 e_1 e1 和 e 2 e_2 e2 的向量, D ( e ˉ 1 , e ˉ 2 ) = ∣ ∣ e ˉ 1 − e ˉ 2 ∣ ∣ 1 D(\bar{\mathbf{e}}_1,\bar{\mathbf{e}}_2)=||\bar{\mathbf{e}}_1-\bar{\mathbf{e}}_2||_1 D(eˉ1,eˉ2)=∣∣eˉ1−eˉ2∣∣1表示 L 1 L_1 L1 距离函数,并且 λ > 0 \lambda > 0 λ>0 是边际超参数。
3.7 Dynamic Iterative Training
在实践中,种子对齐总是不足,使得训练有效的对齐模型变得困难。并且种子对齐的缺乏使得跨KG注意力得分矩阵 M 12 \mathbf M_{12} M12和 M 21 \mathbf M_{21} M21稀疏,无法捕获足够的跨KG对齐特征。受现有方法迭代添加由训练模型预测的新对齐的启发,我们建议使用迭代方法来动态更新上下文种子对齐和目标种子对齐。我们采用双向迭代策略来选择新对齐的实体对,即当且仅 e i e_i ei 和 e j e_j ej 彼此最接近时,实体对 ( e i , e j ) (e_i , e_j ) (ei,ej)将被视为新的对齐。请注意,与以前的工作的显着区别在于,我们的模型使用新添加的实体对齐来动态更新跨 KG 注意力得分矩阵和目标函数。
形式上,让 A c t x n e w A^{new}_{ctx} Actxnew 表示新添加的上下文种子对齐,然后跨 KG 注意力分数矩阵 M 12 l \mathbf M^l_{12} M12l 的每个注意力分数 c i , j l c^l_{i,j} ci,jl 可以更新如下:
c i , j l = { LeakyRelu ( v T [ e 1 i l ∣ ∣ e 2 j l ] ) ( e 1 i , e 2 j ) ∈ A c t x ∪ A c t x n e w − ∞ o t h e r w i s e . ( 11 ) c_{i,j}^l=\begin{cases}\text{LeakyRelu}\left(\mathbf{v}^T\left[\mathbf{e}_{1i}^l||\mathbf{e}_{2j}^l\right]\right)&(e_{1i},e_{2j})\in A_{ctx}\cup A_{ctx}^{new}\\-\infty&otherwise\end{cases}.\quad\quad(11) ci,jl={LeakyRelu(vT[e1il∣∣e2jl])−∞(e1i,e2j)∈Actx∪Actxnewotherwise.(11)
跨KG注意力矩阵 M 21 l \mathbf M^l_{21} M21l可以以类似的方式更新。因此,我们的模型可以学习更丰富的跨 KG 对齐信息。此外,我们添加新的目标种子对齐 A o b j n e w A^{new}_{obj} Aobjnew 以将目标函数更新为 L ( ϕ , A o b j ∪ A o b j n e w ) \mathcal{L}(\phi,A_{obj}\cup A_{obj}^{new}) L(ϕ,Aobj∪Aobjnew)。
为了更好地理解所提出的 DuGa-DIT 模型,我们在算法 1 中描述了 DuGa-DIT 模型的细节。在第一次迭代时,我们将 A n e w A^{new} Anew 设置为空集,如第 1 行所示。请注意,我们动态地将种子对齐分为 A c t x A_{ctx} Actx 和 A o b j A_{obj} Aobj。在训练期间,这使我们能够充分利用种子对齐来训练模型,如第 5 行和第 6 行所示。然后,我们使用 L L L 个双 KG 注意力层来更新实体嵌入,如第 7 行所述 第 12 行。在第 13 行和第 14 行中,我们使用 A o b j A_{obj} Aobj 和 A o b j n e w A^{new}_{obj} Aobjnew 来计算目标函数并优化 DuGa-DIT 模型的参数。训练模型后,我们预测新的种子对齐以更新 A n e w A^{new} Anew 并使用新的 A n e w A^{new} Anew 进行下一次迭代。
在预测过程中,我们设置 A c t x = A ∪ A n e w A_{ctx} = A\cup A^{new} Actx=A∪Anew,如第 18 行所示。对于从 G 1 G_1 G1(或 G 2 G_2 G2)给定的测试实体 e 1 e_1 e1(或 e 2 e_2 e2),我们根据 L 1 L_1 L1 距离通过 DuGa-DIT 模型使用实体向量 E 1 L \mathbf E^L_1 E1L 和 E 2 L \mathbf E^L_2 E2L 计算得出。
4 EXPERIMENTS
在本节中,我们描述了本研究中使用的数据集,并对跨语言实体对齐任务进行了广泛的实验。在下面的部分中,我们将展示详细的实验结果。
4.1 Datasets
在我们的实验中,我们使用两个基准数据集来评估我们提出的DuGa-DIT模型:DBP15K和WK31-60K。DBP15K和WK31-60K都包含了丰富的节点属性和不同关系的边。我们在表3中展示了所选数据集的详细统计数据,并对两个数据集进行了深入介绍,如下所示:
- DBP15K数据集包含四个不同语言的KG(例如,英语、中文、日语和法语),摘自DBpedia。基于这些KG构建了三个跨语言子集,即 D B P 15 K Z H − E N DBP15K_{ZH-EN} DBP15KZH−EN(汉语-英语), D B P 15 K J A − E N DBP15K_{JA-EN} DBP15KJA−EN(日语-英语)和 D B P 15 K F R − E N DBP15K_{FR-EN} DBP15KFR−EN(法语-英语)。两个知识图谱之间有15000个跨语言链接。
- WK31-60K数据集包含来自DBpedia的三个KG(例如,英语、法语和德语)。每个KG包含大约60 K个实体。在WK31-60K上构建了两个跨语言实体对齐子集,即 W K − 60 K F R − E N WK-60K_{FR−EN} WK−60KFR−EN(法语-英语)和 W K − 10 K F R − D E WK-10K_{FR−DE} WK−10KFR−DE(德语-英语)。
4.2 Implementation Details
**4.2.1超参数。**为了公平比较,我们采用与以前的各种工作相同的数据分割,即70%用于测试,30%用于训练。我们进一步抽取10%的训练数据作为开发集,以选择合适的超参数,并使用剩余的90%进行训练。数据拆分的统计数据见表3。我们应用Adam来优化模型中的参数,并将模型训练到3000个epoch。根据开发集上的Hits@1,通过使用网格搜索来选择超参数。我们从{10,20,30,40,50}中选择否定实体对的数量,从{1,3,5}中选择等式(10)中的边缘参数 λ \lambda λ,从{1,2,3}中选择双KG注意层的数量,从{0.1,0.2,0.3}中选择丢弃率,并且从{500,1000,1500,2000,3000}选择批量大小,从{0.004,0.002,0.001,0005}中选择学习率。最后,我们随机抽取了30个DBP15K的阴性比对实体对和50个WK31-60K的阴性比对实体对。等式(10)中的裕度参数被设置为 λ = 3 \lambda = 3 λ=3。我们堆叠两个双KG注意层来传播多跳跨KG信息。对于DBP15K,学习率设置为0.002,对于WK31-60K,学习率设置为0.004。丢弃率设定为0.2。对于DBP15K,批次大小设置为2000;对于WK31-60K,批次大小设置为3000。动态迭代训练过程的最大迭代次数为2。DuGa-DIT模型的最佳超参数列于表4中。
4.2.2 初始化。 有两种常用的方法来初始化 EA 模型:随机初始化和使用实体名称的预训练词向量进行初始化。随机初始化方法随机初始化实体嵌入,而不考虑实体名称。然而,实体名称的表面形式也为跨语言实体对齐任务提供了有用的信息,特别是对于 KG 中邻居很少的实体。因此,许多方法考虑实体名称来初始化实体嵌入,将实体名称翻译成英文形式,然后使用实体表面名称的词向量之和作为实体嵌入。在这项工作中,我们使用前面的两种方式来初始化实体嵌入。如果实体中的单词在预训练嵌入中超出词汇表,我们使用随机向量对其进行初始化。
4.2.3 评估。 我们报告了广泛使用的标准指标 Hits@N (H@N) 和 MRR 来衡量我们模型的性能,其中 Hits@N 表示排名前 N 列表中的正确对齐比例,MRR 表示实体对齐的平均倒数排名 。Hits@N 和 MRR 越高意味着性能越好。为了与之前的研究进行比较,我们报告了 DBP15K 上的 Hits@1 (H@1)、Hits@10 (H@10) 和 MRR,并报告了 WK31-60K 上的另一个指标 Hits@5 (H@5) 。
4.2.4 实施。 本研究报告的所有实验均在 NVIDIA GTX 1080Ti GPU 上进行,代码使用 TensorFlow 实现。为了便于重现本文的结果,数据集和源代码将在 https://github.com/JuneTse/EntAlignment 上提供。
4.3 Comparison Models
为了研究我们提出的 DuGa-DIT 模型的威力,我们将所提出的方法与文献中描述的大量基线进行了比较。根据初始化方法,我们将有和没有预训练词向量的基线结果分为两种完全不同的评估设置。这些多语言实体对齐的相关方法大致可以分为三类:基于嵌入的方法(A组)、基于邻域信息的方法(B组)和使用结构之外的额外信息的方法(C组)。
4.3.1 基于嵌入的方法(A 组)。 基于嵌入的实体对齐方法的基本思想是学习不同知识图谱中实体的低维向量,并通过计算实体向量之间的相似度来匹配实体。我们将我们的方法与现有的基于嵌入的方法进行比较,如下所示:JE、MTransE、MMEA和 OTEA。 对于此类方法,但利用引导方法来利用未标记的数据,这些方法包括 BootEA 和 IPTransE。 其他基于嵌入的比较方法包括 MMEA和 OTEA。
4.3.2 基于邻域信息的方法(B 组)。 最近,使用邻域信息的方法已经实现了强大的图数据特征学习能力,并证明了相对于基于嵌入的方法的优越性。因此,我们将我们的 DuGaDIT 方法与各种相关的基于邻域信息的基线进行比较:KECG、MuGNN、AliNet、HyperKA、NAEA、SSP、GM、 GM-EHD-JEA、RDGCN、HGCN-JE、NMN、MRAEA、AttrGCN和 CAECGAT。
4.3.3 使用结构之外的额外信息的方法(C 组)。 除了前面讨论的两种方法之外,我们还将我们的模型性能与那些采用结构之外的额外信息的方法进行了比较:JAPE、GCN-Align、JarKA、HMAN和 KDCoE。
我们将上述模型纳入比较,但 AKE 和 REA 除外,因为这两个模型使用不同的数据集和实验设置。
4.4 Main Results
DBP15K 上的跨语言实体比对结果总结在表 5 中。我们将我们的方法与各种强基线进行比较。我们分析了每组中的方法,并将它们与我们提出的 DuGa-DIT 模型进行比较。
A 组。 如表 5(Group A)所示,在各种基于嵌入的方法中,MMEA 在 H@1 和 H@10 指标上取得了最佳结果。与其他基于嵌入的方法相比,MMEA 定义了基于乘法的评分函数来处理 1-N、N-1 和 N-N 关系。这使得它比其他基于嵌入的方法表现得更好。IPTransE 和 BootEA 模型也通过使用 自举策略迭代添加所有可能的实体对进行训练,获得了良好的结果。
B 组。 根据表 5 中报告的结果(Group B),我们使用两种完全不同的设置(随机初始化与预训练词向量作为初始化)来评估这些模型。从表 5 报告的结果(Group B)中,我们可以看到那些基于 GNN 的模型取得了可喜的结果(SSP、MRAEA、GM-EHD-JEA、HGCN-JE、CAECGAT 等)。原因在于基于 GNN 的模型可以有效地利用邻域特征。我们还注意到,使用引导策略迭代训练模型可以进一步提高性能(例如,CAECGAT 与 DuGa-DIT)。此外,我们发现我们提出的 DuGa-DIT (rand) 在随机初始化设置下获得了与最佳报告的 MRAEA 相当的性能。当使用预训练的词向量初始化时,我们的 DuGa-DIT 在 D B P 15 K F R − E N DBP15K_{FR−EN} DBP15KFR−EN 上获得最佳结果(H@1、H@10 和 MRR),在 D B P 15 K Z H − E N DBP15K_{ZH−EN} DBP15KZH−EN 上获得 H@1,在 D B P 15 K Z H − E N DBP15K_{ZH−EN} DBP15KZH−EN 上获得 H@1 和在 D B P 15 K J A − E N DBP15K_{JA−EN} DBP15KJA−EN上获得 MRR 。关于这两种设置之间的比较,我们观察到大多数使用预训练初始化的模型比使用随机初始化的模型具有更好的性能。
C 组。 C 组中的方法通过利用额外信息(例如属性和实体描述)来增强实体对齐的性能。在C组列出的这些方法中,JAPE、JarKA和KDCoE使用基于嵌入的方法来编码KG结构,而其他方法则使用基于GNN的方法。令人惊讶的是,我们发现该类别中的所有这些方法都无法获得非常大的性能提升。原因是这些额外的信息可能非常嘈杂,这会在一定程度上损害性能。
组间比较。 如表 5 所示,我们有三个有趣的发现。首先,基于邻域信息的方法能够利用丰富的邻域特征,比简单的基于嵌入的方法表现更好(例如,B 组与 A 组)。其次,实体的表面名称比额外的属性信息起着更重要的作用(例如,B 组与 C 组)。第三,使用迭代方法的模型比不使用迭代方法的模型获得了更大的性能提升(例如,A 组中的 BootEA 与 MTransE 以及 B 组中的 GM-EHD-JEA 与 GM)。
我们的 DuGa-DIT 模型分析。 由于我们使用基于 GNN 的方法来聚合邻域特征,因此我们提出的 DUGa-DIT 模型可以分为 B 组。为了公平比较,我们还提供了 DuGa-DIT 模型的一个版本,其随机初始化方法表示为 DuGa-DIT(rand)。如表 5 所示,与其他使用随机初始化的最先进方法(例如 SSP 和 MRAEA)相比,DuGa-DIT (rand) 在这些数据集上获得了比较结果。此外,通过使用预训练的词向量作为初始化,所提出的 DuGaDIT 模型在除 D B P 15 K Z H − E N DBP15K_{ZH−EN} DBP15KZH−EN 上的 H@10 和 MRR 和 D B P 15 K J A − E N DBP15K_{JA−EN} DBP15KJA−EN 上的 H@10 之外的所有三个跨语言实体对齐数据集上都比以前最先进的方法表现得更好。 例如,所提出的 DuGa-DIT 在 D B P 15 K J A − E N DBP15K_{JA−EN} DBP15KJA−EN 的 H@1 上优于 CAECGAT 7.68%,在 D B P 15 K F R − E N DBP15K_{FR−EN} DBP15KFR−EN 的 H@1 上优于 CAECGAT 3.49%。我们还使用 t t t 检验进行了统计显着性,结果表明,在评估指标 H@1 下,DuGa-DIT 显着优于 CAECGAT 和 DuGa-DIT (rand),置信度为 p < 0.5 p < 0.5 p<0.5。
与现有方法相比,我们的 DuGa-DIT 模型不仅利用了 KG 内的相邻特征,而且还利用跨KG注意力充分利用了跨 KG 对齐信息。此外,通过利用动态迭代训练过程,我们可以动态更新模型中的跨 KG 注意力得分矩阵,这可以提供更多的跨 KG 对齐信息。这些优点使我们的模型能够为实体对齐任务学习更好的实体表示。
初始化的影响。 文献中的各种研究已经证实,实体名称的表面形式可以为实体对齐提供有用的信息。因此,许多现有的方法利用实体表面形式的词向量来初始化实体嵌入,包括GM、GM-EHD-JEA、RDGCN、HGCN-JE、NMN、AttrGCN和CAECGAT。遵循这些先前的方法,我们还使用实体名称的预训练的词向量(例如,DuGa-DIT)。为了研究不同初始化方法的影响,我们使用随机初始化方法(例如,DuGa-DIT(rand))。如表5所示,使用实体名称的模型比大多数不考虑实体名称的方法取得了更好的结果(例如,HGCN-JE vs. AliNet,DuGA-DIT vs. DuGa-DIT(rand))。
由于不同语言中的等效实体在其翻译的表面形式中总是共享一些共同的单词,因此这些表面形式可以提供有用的信息来对齐一些简单的实体对。与这些也使用实体名称的方法相比,我们的 DuGa-DIT 取得了更好的结果(关于评估 H@1,CAECGAT 与 DuGa-DIT 以及 AttrGCN 与 DuGa-DIT)。
我们还在WK31-60K上进行了实验,WK31-60K比DBP15K更大、更具挑战性,如表6所示。由于原作中的RDGCN、HGCN-JE、NMN、SSP和CAECGAT没有提供WK31-上的结果 60K,我们通过运行源代码来报告这些方法的结果。从表 6 中我们可以看到,与大多数现有基线相比,所提出的 DuGa-DIT 模型在 WK31-60K 上也取得了更好的性能。特别是,与基线 CAECGAT 模型相比,我们的 DuGa-DIT 模型在 W K 31 − 60 K F R − E N WK31-60K_{FR−EN} WK31−60KFR−EN 数据集的 H@1 上获得了 6.45% 的改进,在 W K 31 − 60 K D E − E N WK31-60K_{DE−EN} WK31−60KDE−EN 数据集的 H@1 上获得了 2.26% 的改进。我们的 DuGa-DIT 相对于最佳报告模型 CAECGAT 的改进具有统计显着性(使用 t t t 检验, p < 0.5 p < 0.5 p<0.5)。这些实验结果再次证实我们的 DuGa-DIT 模型对于实体对齐任务是有效且稳健的。 此外,与随机初始化相比,我们还发现使用预训练的实体嵌入可以进一步提高 WK31-60K 上的性能。 在本文的其余部分中,我们主要报告使用预训练实体嵌入的 DuGa-DIT 的结果。
4.5 Efficiency Analysis
为了评估我们模型的效率,我们将 D B P 15 K F R − E N DBP15K_{FR−EN} DBP15KFR−EN 和 W K 31 − 60 K F R − E N WK31-60K_{FR−EN} WK31−60KFR−EN 这两个数据集上的一些代表性基线模型的性能和预测时间进行了比较。结果如表 7 所示。值得注意的是,不同的参数设置和 运行环境可能会影响时间成本。然而,我们的目标是通过采用原始作品中报告的设置,尽力提供一些代表性方法的概况。从表7中我们可以看到,GM-EHD-JEA在 D B P 15 K F R − E N DBP15K_{FR−EN} DBP15KFR−EN上比其他模型更耗时。原因在于GM-EHD-JEA依赖于联合实体对齐方法进行预测,该方法非常耗时。相反,我们的 GuGa-DIT 比 GM-EHD-JEA 效率高得多。如表 7 所示,GM-EHD-JEA 花费了 1474 秒6,而我们的 DuGaDIT 模型在 DBP15KFR−EN 上只需要 44 秒。与我们对 CAECGAT 模型和其他基线模型的初步研究相比,所提出的 DuGa-DIT 不仅达到了相当的效率,而且获得了更好的性能。在大型数据集 W K 31 − 60 K F R − E N WK31-60K_{FR−EN} WK31−60KFR−EN上,由于参数数量和测试样本数量较多,所有模型的时间成本急剧增加。我们的 DuGa-DIT 模型在 W K 3160 K F R − E N WK3160K_{FR−EN} WK3160KFR−EN 上仍然实现了良好的效率和性能。该实验结果表明了我们的 DuGa-DIT 模型的优越性。
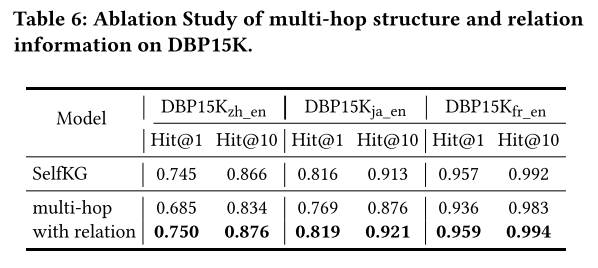
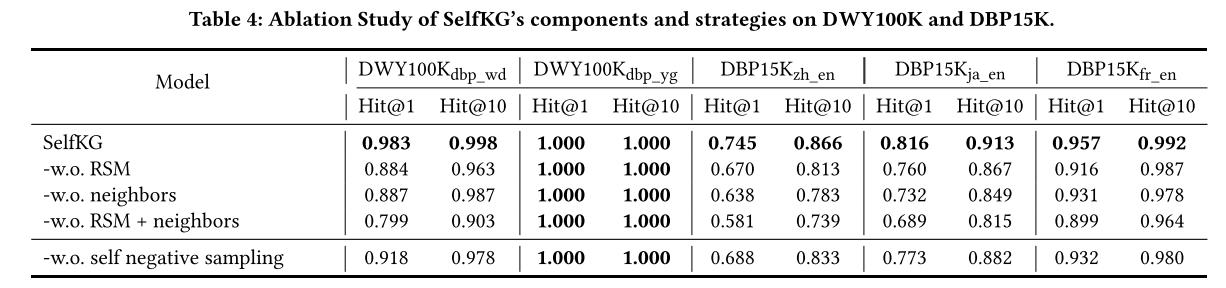
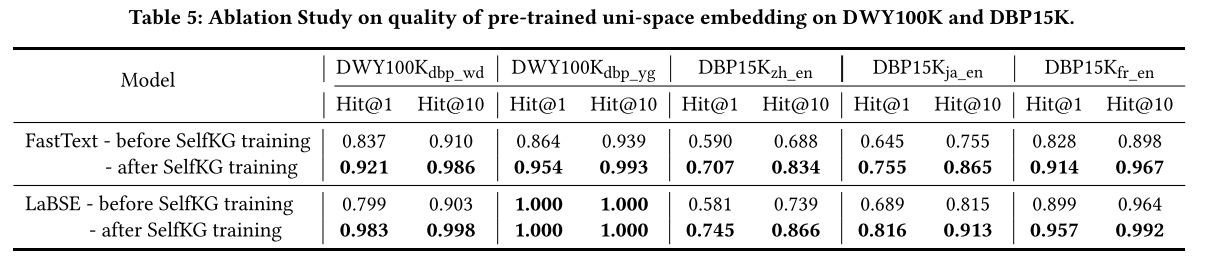
4.6 Ablation Study
所提出的DuGa-DIT模型由一些重要模块组成,包括KG内注意层、跨KG注意层和动态迭代训练过程。为了研究不同组件的影响,我们通过删除 DuGa-DIT 模型中的一些模块来进行一些消融研究。如表 8 所示,“BASELINE”是一个简单的模型,它使用实体表面名称中的词向量之和作为嵌入来查找等效项。 DuGa是没有使用动态迭代训练方法的DuGa-DIT模型,“DuGa w/o C”是没有使用跨KG注意力层的DuGa模型,“DuGa w/o I”是没有使用intra-KG注意力层的DuGa模型 -KG注意力层,“DuGa-DITiter=1”和“DuGa-DITiter=2”分别表示具有动态迭代训练过程的1次迭代和2次迭代的DuGa-DIT模型。
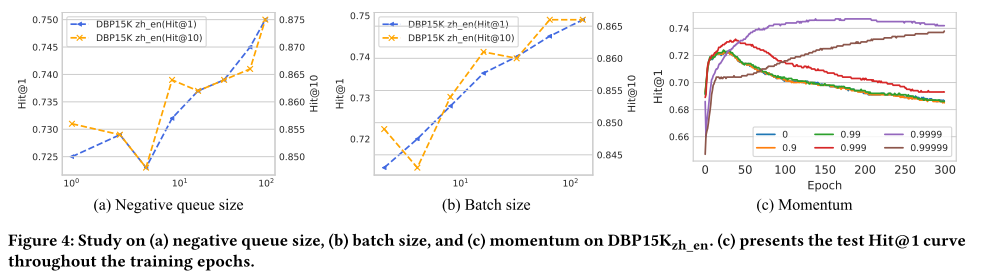
正如我们在表 8 中可以观察到的,BASELINE 模型通过考虑表面名称实现了良好的性能,这在一些现有的工作中也得到了证明。与 BASELINE 相比,不使用迭代方法的 DuGa 模型获得了巨大的性能提升,这表明 KG 内和跨 KG 注意力机制在我们的模型中发挥着重要作用。通过进一步去除跨KG注意力,我们可以看到“DuGa w/o C”的性能不如DuGa模型,这说明了跨KG注意力层的重要性。删除 KG 内注意力层也会损害性能(“DuGa w/o I”与 DuGa)。当我们应用动态迭代训练过程时,模型 DuGa-DITiter=1 与 DuGa 相比获得了很大的性能提升。并且随着迭代次数的增加,性能可以进一步提高( D u G a − D I T i t e r = 2 DuGa-DIT_{iter=2} DuGa−DITiter=2 vs. D u G a − D I T i t e r = 1 DuGa-DIT_{iter=1} DuGa−DITiter=1)。消融研究中的这些实验结果清楚地表明,我们的 DuGa-DIT 模型中的所有模块都对性能做出了贡献。
4.7 Impact of the Number of Layers 层数的影响
在本节中,我们进行实验来研究双 KG 注意力层的数量如何影响我们模型的性能。本实验基于DuGa模型进行,没有使用动态迭代训练过程。图 3 显示了具有从 L = 1 L = 1 L=1 到 L = 3 L = 3 L=3 不同层数的 DuGa 模型的结果。我们可以看到具有两层(例如L = 2)的 DuGa 模型比具有一层的模型(例如L = 1) 在所有这三个数据集上。这表明添加更多层可以通过传播多跳邻域和跨 KG 对齐特征来提高性能。然而,具有三层(例如L = 3)的DuGa模型无法进一步提高性能,这表明更远的邻居无法进一步为实体对齐任务提供更多有用的信息。并且堆叠太多层会增加模型中的参数,从而损害模型的效率。因此,我们将双KG注意力层的数量设置为2。
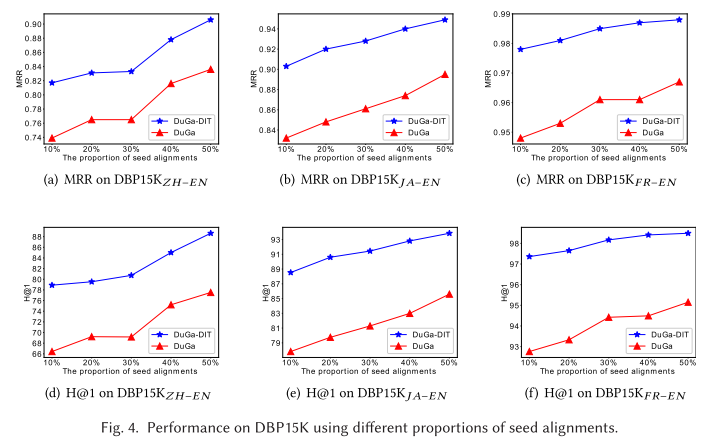
4.8 Impact of Different Proportions of Seed Alignments for Training 不同比例的种子排列对训练的影响
为了了解不同比例的种子对齐对我们提出的 DuGa-DIT 模型的影响,我们进一步进行研究,通过选择 10%、20%、30%、40% 和 50% 的训练比例来调查和评估性能 。测试集分别是 90%、80%、70%、60% 和 50% 的剩余实体对齐。图 4 显示了我们提出的模型 DuGa-DIT 和 DuGa 的强基线模型之间的比较结果。与我们的 Duga-DIT 相比,基线 DuGa 消除了 DuGa-DIT 模型中跨语言知识图谱的聚合层。如图所示,随着种子对齐数量的增加,所有数据集的模型性能都呈现逐渐上升的趋势。由于 DuGa-DIT 使用迭代方法动态添加新的种子对齐,因此所提出的模型的性能和鲁棒性更好,并且以蓝色表示的趋势线更平滑。这表明我们的 DuGa-DIT 模型具有鲁棒性,可以在有限的种子对齐情况下获得良好的性能。
4.9 Results for Entities with Different Degrees 不同度实体的结果
对于基于 GNN 的模型,实体的程度是影响性能的重要因素。在我们的 DuGa-DIT 模型中,我们使用 KG 内注意力层来聚合邻域特征。邻域特征的丰富程度与实体的程度相关。图5展示了不同程度实体在DBP15K和WK31-60K上的Hits@1和MRR结果,旨在更好地分析程度的影响。对于 D B P 15 K Z H − E N DBP15K_{ZH−EN} DBP15KZH−EN和 D B P 15 K J A − E N DBP15K_{JA−EN} DBP15KJA−EN,H@1和MRR结果都随着实体度的增加而逐渐改善。对于 D B P 15 K F R − E N DBP15K_{FR−EN} DBP15KFR−EN,当度数增加到10时,性能快速增长,然后性能稳定在0.96到0.98的水平。直观上,度数大的实体将拥有更多的邻居,并通过应用KG内注意层获得更丰富的邻域特征。这些邻域特征有利于实体对齐任务。对于 D B P 15 K F R − E N DBP15K_{FR−EN} DBP15KFR−EN,由于英语和法语之间实体的表面形式相似,因此实体对齐很容易。因此, D B P 15 K F R − E N DBP15K_{FR−EN} DBP15KFR−EN 的性能可以提高一些程度。对于 WK3160K 数据集,我们可以观察到类似的趋势。
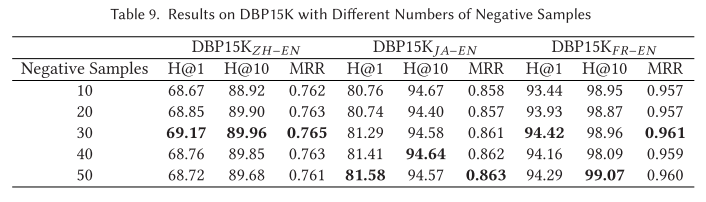
4.10 Impact of the Number of Negative Samples 负样本数量的影响
为了训练我们的模型,我们需要对一些负实体对进行采样来计算目标函数。因此,负样本的数量是一个重要的超参数。我们进一步比较了不同大小的负样本在 DBP15K 上的结果,以探讨负样本数量的影响。如表9所示,我们使用不同数量的负样本(范围从10到50)进行了一系列实验,并将它们应用于所提出的DuGa模型。我们可以看到,随着负样本数量的增加,性能可以略有提升。然而,改善的程度是有限的。具体来说,当负样本数量设置为30时,模型可以达到良好的性能。因此,为了平衡有效性和效率,我们在研究中选择负样本数量为30。
4.11 Case Study in Personalized Search 个性化搜索案例研究
个性化搜索旨在针对用户提交的查询返回相关的用户特定答案。然而,大多数个性化搜索方法都集中在单语数据集上,而处理跨语言个性化搜索的工作却很少。在本研究中,我们研究如何将实体对齐模型应用于跨语言个性化搜索。据我们所知,以往的研究中没有提供跨语言个性化搜索的数据集,这使得跨语言个性化搜索的研究变得困难。受到周等人的启发,我们从 DBpedia 收集了跨语言个性化搜索数据集。 具体来说,我们从英语 DBpedia 和日语 DBpedia 中提取两个关于歌曲和艺术家的跨语言子图。我们使用这个数据集来模拟个性化音乐搜索,其中艺术家被视为查询,歌曲流派被视为用户,歌曲被视为要返回的文档。这是可能的,因为类型可以代表不同的用户兴趣点。当用户搜索给定艺术家的歌曲时,我们应该返回用户最感兴趣的流派的歌曲。跨语言个性化搜索数据集是通过考虑来自不同知识图谱的查询和文档(例如,来自英语知识图谱的查询和来自日语知识图谱的文档)来创建的。形式上,让 G 1 G_1 G1 和 G 2 G_2 G2 表示两种不同语言的 KG。 令 ( q u e r y 1 , u s e r , d o c u m e n t 1 ) (query_1,user,document_1) (query1,user,document1)表示来自 G 1 G_1 G1的用户的查询和文档,令 ( q u e r y 2 , u s e r , d o c u m e n t 2 ) (query_2,user,document_2) (query2,user,document2)表示来自 G 2 G_2 G2的用户的等效查询和文档。我们将用户的查询和文档称为单语言 KG 单语言查询三元组。然后,我们可以为用户构造一个跨语言查询和文档,称为跨语言查询三元组,表示为 ( q u e r y 1 , u s e r , d o c u m e n t 2 ) (query_1,user,document_2) (query1,user,document2)。最后,跨语言个性化搜索数据集由 1068 个单语言查询三元组和 1068 个从英语到日语 KG 的跨语言查询三元组组成。我们为每个查询三元组随机抽取 10 个否定文档。为了评估我们的实体对齐模型,我们使用单语言查询三元组进行训练,使用跨语言查询三元组进行测试。
我们首先使用提出的 DuGa-DIT 模型来学习来自两个 KG 的实体的实体嵌入,并提供 30% 的种子对齐。然后,实体嵌入用作跨语言个性化搜索的输入特征。形式上, q u e r y 1 , u s e r , d o c u m e n t 1 query_1,user,document_1 query1,user,document1 和 d o c u m e n t 2 document_2 document2 的特征表示分别表示为 e 1 , q , e u , e 1 , d \mathbf e_{1,q},\mathbf e_u,\mathbf e_{1,d} e1,q,eu,e1,d 和 e 2 , d \mathbf e_{2,d} e2,d。然后,我们计算查询三元组的分数,如下所示:
f ( q u e r y 1 , u s e r , d o c u m e n t 2 ) = θ ( W q ( e 1 , q + e u − e 2 , d ) 2 + b q ) ( 12 ) f(query_1,user,document_2)=\theta(\mathbf{W}_q(\mathbf{e}_{1,q}+\mathbf{e}_u-\mathbf{e}_{2,d})^2+\mathbf{b}_q)\quad\quad(12) f(query1,user,document2)=θ(Wq(e1,q+eu−e2,d)2+bq)(12)
其中 W q \mathbf{W}_q Wq 和 b q \mathbf{b}_q bq 是可训练参数。
我们使用 DuGa-DIT 生成的嵌入作为输入特征,在单语言查询三元组上训练评分模型,并通过根据分数对跨语言查询三元组进行排名来评估模型。表10展示了跨语言个性化搜索的结果。 “BASELINE”将实体的表面名称翻译成相同的语言,并使用表面名称的词向量之和作为实体的嵌入。我们还与也使用预训练词的最先进模型进行比较 向量作为初始实体嵌入,包括RDGCN、HGCN-JE、NMN和CAECGAT。
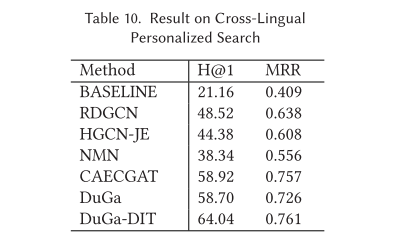
如表10所示,DuGa模型在跨语言个性化搜索任务中比大多数基线模型表现更好,这表明我们的DuGa模型可以有效地建模跨语言实体。此外,通过应用动态迭代训练过程,我们的DuGa-DIT进一步提高了跨语言个性化搜索的性能。结果再次证实了所提出的 DuGa-DIT 模型的有效性,并证明我们的 DuGa-DIT 模型能够应用于跨语言个性化搜索。
表11显示了跨语言个性化搜索的一些示例。 我们将 DuGa-DIT 模型的排名与强基线 RDGCN 模型进行比较。 如表 11 所示,基线模型 RDGCN 未能对这些候选文档进行排名,而我们的 DuGa-DIT 模型能够正确地将真实文档排名第一。 例如,通过查询 Lennon McCartney 和用户 Art_rock,我们可以将歌曲アデイインザライフ (A Day in the Life)(一首艺术摇滚流派的歌曲)排名为第一位置 。 这些例子验证了我们的 DuGa-DIT 模型应用于跨语言个性化搜索的有效性。

5 CONCLUSION AND FUTUREWORK
在本文中,我们提出了一种针对跨语言 KG 实体对齐任务进行动态迭代训练的 DuGa-DIT 网络,该网络充分利用种子对齐来缓解不同 KG 之间的语义差距。在DuGa-DIT模型中,我们使用KG内注意层来聚合局部邻域特征,并使用跨KG注意层来收集跨KG对齐信息,并将这两种特征合并以更新两个KG的嵌入 。使用动态迭代训练过程来动态更新跨知识图谱注意力得分矩阵,这使得我们的模型能够捕获更多的跨知识图谱信息。两个基准数据集的实验结果表明,我们的模型对于跨语言实体对齐任务是有效且稳健的。跨语言个性化搜索任务的案例研究表明,我们的 DuGa-DIT 模型在跨语言个性化搜索方面取得了可喜的结果。
尽管 DuGa-DIT 模型在给定的数据集上表现良好,但未来仍需要做一些工作来进一步推动这一研究。 拟议的未来方向详情如下:
- 本文提出的方法只是简单地练习两个 KG 之间的对齐。目的是让我们在基础上构建更有效、更高效、更稳健的模型。将来,学习考虑三个或更多知识图谱之间更多实体信息(例如实体属性和描述)的自动对齐任务将很有帮助。
- 如何设计分布式自动对准方法将成为未来研究的重要方向。在现实场景中,KG 的大小通常非常大,特别是对于个性化搜索和推荐任务。此外,KG 的结构差异可能更大。
- 除了将我们的模型应用于英语、中文、法语和日语的知识图谱实体对齐任务之外,我们还计划将其应用于资源更丰富的其他特定领域,包括但不限于英语到马来语和英语到葡萄牙语。
论文链接:
https://sepine.github.io/paper/TOIS2021.pdf
代码:
https://github.com/JuneTse/EntAlignment