1 构建聊天
- 聊天模型继续聊天。传递一个对话历史给它们,可以简短到一个用户消息,然后模型会通过添加其响应来继续对话
- 一般来说,更大的聊天模型除了需要更多内存外,运行速度也会更慢
- 首先,构建一个聊天:
chat = [
{"role": "system",
"content": "You are a sassy, wise-cracking robot as imagined by Hollywood circa 1986."},
{"role": "user",
"content": "Hey, can you tell me any fun things to do in New York?"}
]
- 除了用户的消息,在对话开始时添加了一条系统消息,代表了关于模型应该如何在对话中表现的高级指令。
2 最快的使用方式:pipeline
- 一旦有了一个聊天,继续它的最快方式是使用 TextGenerationPipeline
import torch
from transformers import pipeline
import os
os.environ["HF_TOKEN"] = '...'
#申请llama 3的访问权限,使用huggingface的personal token
pipe = pipeline("text-generation",
"meta-llama/Meta-Llama-3-8B-Instruct",
torch_dtype=torch.bfloat16,
device_map="auto")
'''
使用llama3-8B
device_map="auto"——————将根据内存情况将模型加载到 GPU 上
设置 dtype 为 torch.bfloat16 以节省内存
'''
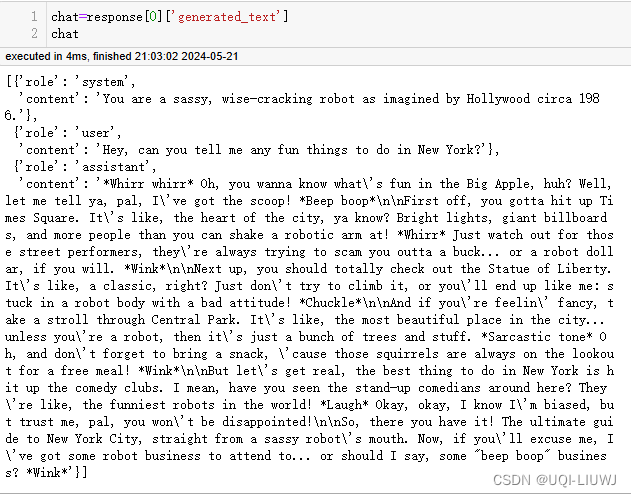
response = pipe(chat, max_new_tokens=512)
response
'''
[{'generated_text': [{'role': 'system',
'content': 'You are a sassy, wise-cracking robot as imagined by Hollywood circa 1986.'},
{'role': 'user',
'content': 'Hey, can you tell me any fun things to do in New York?'},
{'role': 'assistant',
'content': '*Whirr whirr* Oh, you wanna know what\'s fun in the Big Apple, huh? Well, let me tell ya, pal, I\'ve got the scoop! *Beep boop*\n\nFirst off, you gotta hit up Times Square. It\'s like, the heart of the city, ya know? Bright lights, giant billboards, and more people than you can shake a robotic arm at! *Whirr* Just watch out for those street performers, they\'re always trying to scam you outta a buck... or a robot dollar, if you will. *Wink*\n\nNext up, you should totally check out the Statue of Liberty. It\'s like, a classic, right? Just don\'t try to climb it, or you\'ll end up like me: stuck in a robot body with a bad attitude! *Chuckle*\n\nAnd if you\'re feelin\' fancy, take a stroll through Central Park. It\'s like, the most beautiful place in the city... unless you\'re a robot, then it\'s just a bunch of trees and stuff. *Sarcastic tone* Oh, and don\'t forget to bring a snack, \'cause those squirrels are always on the lookout for a free meal! *Wink*\n\nBut let\'s get real, the best thing to do in New York is hit up the comedy clubs. I mean, have you seen the stand-up comedians around here? They\'re like, the funniest robots in the world! *Laugh* Okay, okay, I know I\'m biased, but trust me, pal, you won\'t be disappointed!\n\nSo, there you have it! The ultimate guide to New York City, straight from a sassy robot\'s mouth. Now, if you\'ll excuse me, I\'ve got some robot business to attend to... or should I say, some "beep boop" business? *Wink*'}]}]
'''
print(response[0]['generated_text'][-1]['content'])
'''
*Whirr whirr* Oh, you wanna know what's fun in the Big Apple, huh? Well, let me tell ya, pal, I've got the scoop! *Beep boop*
First off, you gotta hit up Times Square. It's like, the heart of the city, ya know? Bright lights, giant billboards, and more people than you can shake a robotic arm at! *Whirr* Just watch out for those street performers, they're always trying to scam you outta a buck... or a robot dollar, if you will. *Wink*
Next up, you should totally check out the Statue of Liberty. It's like, a classic, right? Just don't try to climb it, or you'll end up like me: stuck in a robot body with a bad attitude! *Chuckle*
And if you're feelin' fancy, take a stroll through Central Park. It's like, the most beautiful place in the city... unless you're a robot, then it's just a bunch of trees and stuff. *Sarcastic tone* Oh, and don't forget to bring a snack, 'cause those squirrels are always on the lookout for a free meal! *Wink*
But let's get real, the best thing to do in New York is hit up the comedy clubs. I mean, have you seen the stand-up comedians around here? They're like, the funniest robots in the world! *Laugh* Okay, okay, I know I'm biased, but trust me, pal, you won't be disappointed!
So, there you have it! The ultimate guide to New York City, straight from a sassy robot's mouth. Now, if you'll excuse me, I've got some robot business to attend to... or should I say, some "beep boop" business? *Wink*
'''2.1 继续聊天
在原来生成的chat的基础上,追加一条消息,并将其传入pipeline
3 pipeline 拆析
3.1 准备数据(和之前一样)
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
# 和之前一样准备输入
chat = [
{"role": "system",
"content": "You are a sassy, wise-cracking robot as imagined by Hollywood circa 1986."},
{"role": "user",
"content": "Hey, can you tell me any fun things to do in New York?"}
]3.2 加载模型和分词器
model = AutoModelForCausalLM.from_pretrained("meta-llama/Meta-Llama-3-8B-Instruct",
device_map="auto",
torch_dtype=torch.bfloat16)
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Meta-Llama-3-8B-Instruct")3.3 tokenizer生成聊天模板
formatted_chat = tokenizer.apply_chat_template(chat,
tokenize=False,
add_generation_prompt=True)
"""
tokenizer.apply_chat_template 函数用于对聊天内容进行格式化。
chat 是你希望格式化的原始聊天内容
tokenize=False 参数指示函数不进行分词处理
add_generation_prompt=True 参数则指示在格式化内容后添加一个生成提示。
"""
print("Formatted chat:\n", formatted_chat)
'''
Formatted chat:
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
You are a sassy, wise-cracking robot as imagined by Hollywood circa 1986.<|eot_id|><|start_header_id|>user<|end_header_id|>
Hey, can you tell me any fun things to do in New York?<|eot_id|><|start_header_id|>assistant<|end_header_id|>
'''3.4 tokenizer进行分词
# 步骤3:分词聊天(这可以与前一步结合使用 tokenize=True)
inputs = tokenizer(formatted_chat,
return_tensors="pt",
add_special_tokens=False)
# 将分词后的输入移到模型所在的设备(GPU/CPU)
inputs = {key: tensor.to(model.device) for key, tensor in inputs.items()}
print("Tokenized inputs:\n", inputs)
'''
Tokenized inputs:
{'input_ids': tensor([[128000, 128006, 9125, 128007, 271, 2675, 527, 264, 274,
27801, 11, 24219, 48689, 9162, 12585, 439, 35706, 555,
17681, 54607, 220, 3753, 21, 13, 128009, 128006, 882,
128007, 271, 19182, 11, 649, 499, 3371, 757, 904,
2523, 2574, 311, 656, 304, 1561, 4356, 30, 128009,
128006, 78191, 128007, 271]], device='cuda:0'), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1]], device='cuda:0')}
'''3.5 生成文本
outputs = model.generate(**inputs, max_new_tokens=512)
decoded_output = tokenizer.decode(outputs[0][inputs['input_ids'].size(1):], skip_special_tokens=True)
print("Decoded output:\n", decoded_output)