本实战主要目标是讲解如何使用sklearn库来构造决策树,包括其中的一些参数的使用,以及参数调优对模型精确度的影响。
1. 数据处理
导入Pandas和Matplotlib两个库。
# 导入Pandas和Matplotlib两个库
%matplotlib inline
import matplotlib.pyplot as plt
import pandas as pd此次实验没有CSV数据文件,我们采用sklearn模块中的内置数据集,直接加载内置的房价数据集,根据房子的价格和一些影响因素,来预测最终的结果。
from sklearn.datasets.california_housing import fetch_california_housing
housing = fetch_california_housing()
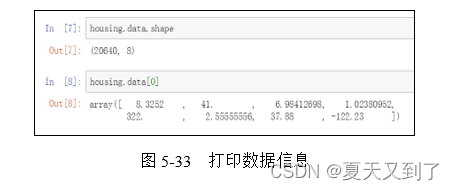
print(housing.DESCR)# 内置数据集可以简单打印一下数据信息,具体代码与结果如图5-33所示。第一条代码中.shape表示数据的维度,输出的信息表示整个文件有8个特征及20640条数据。第二条代码表示打印数据集中的第一行数据信息。
2. 模型的建立
从sklearn中导入tree模块,在tree模块里可以用决策树分类或者回归,预测类别值或连续值都是可以的。使用sklearn分两步,第一步是将树模型实例化出来,传入参数max_depth控制树的最大深度。第二步是用实例出来的变量来进行训练,相当于构造一个树模型。其中,传入两个参数x,y,这里的x取数据集中的第6列和第7列,相当于指定某些特征来建模;y相当于label,即结果值。
# 实例化树模型
from sklearn import tree
print(housing.target)
dtr = tree.DecisionTreeRegressor(max_depth=2) # 控制深度
dtr.fit(housing.data[:,[6,7]],housing.target) # 取第6列和第7列执行语句输出模型的参数,如图5-34所示,除了设定的参数,有些参数是默认的,一般情况下我们只需要调整部分参数即可。

3. 模型可视化
模型可视化显示需要借助第三方工具。首先要安装graphiviz,其官方网站地址是http://www.graphviz.org/,进入页面后单击Download按钮,根据计算机版本选择安装文件,安装后将bin目录下的路径添加到环境变量即可使用。
接下来要构造可视化树模型,代码结构差不多,唯一需要调整的是构造对象的变量名字,以及图中的特征名字,就是dataframe中用什么名字就指定那个名字,代码如下:
# 可视化构造树模型
dot_data = \
tree.export_graphviz(
dtr,# 变量名
out_file=None,
feature_names=housing.feature_names[6:8],# 名字
filled=True,
impurity=False,
rounded=True
)
另外,还需要安装一个pydotplus库,使用pip install pydotplus命令即可安装。把数据参数传进去并指定画图的颜色,代码如下:
import pydotplus
graph = pydotplus.graph_from_dot_data(dot_data)
graph.get_nodes()[7].set_fillcolor("#FFF2DD")
from IPython.display import Image
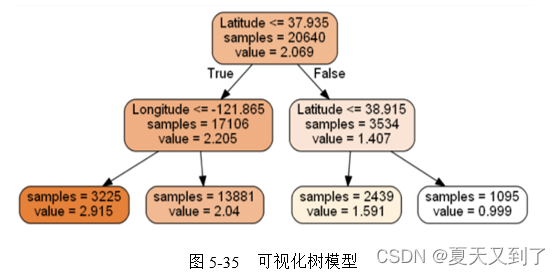
Image(graph.create_png())结果如图5-35所示。如此就完成了决策树的可视化的过程。
所以说,调用Python的内置模块还是很方便的,不需要在cmd命令窗口上去进行一些操作,构造好的决策树图还可以保存到本地,方便查看,操作也很简单。
graph.write_png("dtr_white_backgroud.png")本文节选自《机器学习实战(视频教学版)》,获出版社和作者授权发布。
《图神经网络基础、模型与应用实战(人工智能技术丛书)》(兰伟,叶进,朱晓姝)【摘要 书评 试读】- 京东图书 (jd.com)