前言:
前面整理了hadoop概念内容,写了一些概念和本地部署和伪分布式两种,比较偏向概念或实验,今天来整理一下在项目中实际使用的一些知识点。
1、基础概念
1.1、完全分布式
Hadoop是一个开源的分布式存储和计算框架,主要用于处理大规模数据集。完全分布式是指Hadoop集群中的所有节点都担任特定角色,包括数据存储节点(DataNode)、计算节点(TaskTracker)和主控节点(NameNode和JobTracker)。在完全分布式架构中,数据被分散存储在多个数据节点上,同时计算任务也可以分发到不同的计算节点上并行执行,从而实现高性能的数据处理能力。完全分布式架构还具备高可靠性,因为数据会被复制到多个节点上,一旦某个节点发生故障,数据仍然可通过其他节点获取。 Hadoop的完全分布式架构使其成为处理大规模数据的理想选择,能够提供高性能、高可靠性和高扩展性。
特点:
- 高可靠性:数据被复制到多个节点,即使某个节点发生故障,数据仍然可用。
- 高扩展性:可以简单地通过增加节点来扩展集群的处理能力。
- 并行处理:能够将计算任务分发到多个节点上并行执行,加快数据处理速度。
- 分布式存储:数据被分散存储在多个节点上,避免了单点故障。
大概是下面这个意思:
可以把Hadoop的完全分布式特点形象地比喻为这座工厂的运作方式。
在这座工厂中,原材料被分散储存在不同的仓库里。
生产线上的每台机器都能够独立地进行加工和生产。
即使某个仓库出现问题或者某台机器需要维修,整个工厂的生产仍然可以继续进行,因为其他仓库和机器仍然可以独立运作。这种分布式的生产方式使得工厂具有高可靠性和高效率,能够应对各种突发情况并保持持续的生产能力。
1.2、HA高可用
HA(High Availability,高可用性)是系统能够在不间断地提供服务的情况下,解决硬件故障、软件故障等各种问题,让用户始终能够正常地使用系统。在Hadoop中,HA主要指的是NameNode节点和ResourceManager节点的高可用。
对于NameNode节点,Hadoop通过运行两个或多个NameNode节点来实现故障转移,保证HDFS的高可用性。常见的实现方式包括Active-Standby模式和Active-Active模式,确保在一个NameNode出现故障时能够无缝切换到其他节点,维持系统连续性和可用性。
对于ResourceManager节点,在YARN中实现RMHA同样采用Active-Standby模式或Active-Active模式,以确保整个YARN集群在ResourceManager节点发生故障时能够自动切换,并保持应用程序的正常执行和集群资源的有效利用。
datanamehe和nodemanager本身就是高可用的,使用默认配置即可
hadoop HA是2.0版本后新添加的特性,在Hadoop 1.x 中,Namenode是集群的单点故障,一旦Namenode出现故障,整个集群将不可用,重启或者开启一个新的Namenode才能够从中恢复。值得一提的是,Secondary Namenode并没有提供故障转移的能力。集群的可用性受到影响表现在:
- 当机器发生故障,如断电时,管理员必须重启Namenode才能恢复可用。
- 在日常的维护升级中,需要停止Namenode,也会导致集群一段时间不可用。
1.3、NameNode HA实现方法
1. 元数据管理方式需要改变
内存中各自保存一份元数据;
Edits日志只有Active状态的NameNode节点可以做写操作;
两个NameNode都可以读取Edits;
共享的Edits放在一个共享存储中管理(qjournal和NFS两个主流实现);
2. 需要一个状态管理功能模块
实现了一个zkfailover,常驻在每一个namenode所在的节点,每一个zkfailover负责监控自己所在NameNode节点,利用zk进行状态标识,当需要进行状态切换时,由zkfailover来负责切换,切换时需要防止brain split(脑裂)现象的发生。
3. 必须保证两个NameNode之间能够ssh无密码登录
4. 隔离(Fence),即同一时刻仅仅有一个NameNode对外提供服务
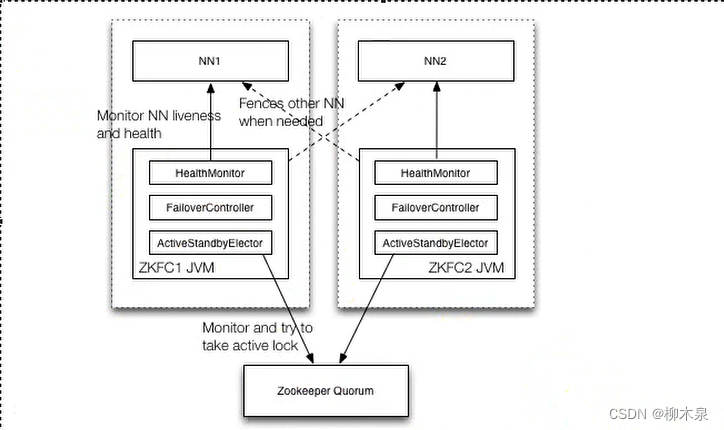
HDFS-HA自动故障转移工作机制(下面红字更形象一些):
下面如何配置部署HA自动进行故障转移。自动故障转移为HDFS部署增加了两个新组件:ZooKeeper和ZKFailoverController(ZKFC)进程,ZooKeeper是维护少量协调数据,通知客户端这些数据的改变和监视客户端故障的高可用服务。HA的自动故障转移依赖于ZooKeeper的以下功能:
1)故障检测:集群中的每个NameNode在ZooKeeper中维护了一个持久会话,如果机器崩溃,ZooKeeper中的会话将终止,ZooKeeper通知另一个NameNode需要触发故障转移。
2)现役NameNode选择:ZooKeeper提供了一个简单的机制用于唯一的选择一个节点为active状态。如果目前现役NameNode崩溃,另一个节点可能从ZooKeeper获得特殊的排外锁以表明它应该成为现役NameNode。
ZKFC是自动故障转移中的另一个新组件,是ZooKeeper的客户端,也监视和管理NameNode的状态。每个运行NameNode的主机也运行了一个ZKFC进程。
ZKFC负责:
1)健康监测:ZKFC使用一个健康检查命令定期地ping与之在相同主机的NameNode,只要该NameNode及时地回复健康状态,ZKFC认为该节点是健康的。如果该节点崩溃,冻结或进入不健康状态,健康监测器标识该节点为非健康的。
2)ZooKeeper会话管理:当本地NameNode是健康的,ZKFC保持一个在ZooKeeper中打开的会话。如果本地NameNode处于active状态,ZKFC也保持一个特殊的znode锁,该锁使用了ZooKeeper对短暂节点的支持,如果会话终止,锁节点将自动删除。
3)基于ZooKeeper的选择:如果本地NameNode是健康的,且ZKFC发现没有其它的节点当前持有znode锁,它将为自己获取该锁。如果成功,则它已经赢得了选择,并负责运行故障转移进程以使它的本地NameNode为Active。故障转移进程与前面描述的手动故障转移相似,首先如果必要保护之前的现役NameNode,然后本地NameNode转换为Active状态。
下面是一个形象的解释:
想象一下,你有一个家庭电器系统,其中有两个主要的电源控制盒,分别是A和B。每个电源控制盒都能够提供电力给整个家庭。但是,你希望始终有一个电源控制盒处于活动状态,以确保家庭电器的连续供电。
在这个例子中,家庭电器系统的两个电源控制盒就类似于Hadoop集群中的两个NameNode节点,在HA模式下工作。而ZKFC则扮演着一个类似于管理电源切换的角色。
现在,我们引入ZooKeeper,它就像是一个智能的电源监控器。ZooKeeper负责监视两个电源控制盒的状态,并确保只有一个电源控制盒处于活动状态。
具体地,ZooKeeper通过与所有电源控制盒进行通信,监控它们的健康状况。如果某个电源控制盒发生故障或无法正常工作,ZooKeeper会接收到相应的消息并发出警报。然后,ZooKeeper会与其他正常工作的电源控制盒协商,并最终选择一个新的活动电源控制盒。
ZooKeeper使用共享的存储来存储集群中的状态信息,类似于记录电源控制盒的状态和切换信息的日志。这样,当电源控制盒发生故障时,新的活动电源控制盒可以从共享的存储中获取最新的状态信息,并继续提供服务。
通过ZooKeeper的运行方式,Hadoop集群中的NameNode HA机制得以实现。ZKFC作为ZooKeeper的客户端,通过监控NameNode的健康状态并协调故障转移过程,确保在NameNode发生故障时能够自动切换到备用的NameNode节点,从而保证Hadoop集群的高可用性和数据的一致性。
1.4、NameNode HA数据共享方法
在Hadoop分布式文件系统(HDFS)中,fsimage和editlog是两个关键的元数据文件,用于存储文件系统的状态和变更记录。
fsimage(文件系统镜像):
fsimage是HDFS中的静态映像文件,它记录了整个文件系统的命名空间和文件块的映射关系。fsimage文件包含了文件和目录的元数据信息,如文件路径、权限、属性等,以及每个文件块所在的数据节点等信息。fsimage文件在NameNode启动时加载到内存中,用于恢复文件系统的初始状态。
editlog(编辑日志):
editlog是HDFS中的动态日志文件,它记录了对文件系统的所有修改操作。每当有文件创建、重命名、删除或修改时,对应的编辑操作都会被追加到editlog中。editlog文件按照顺序记录这些修改操作,它是一个追加写入的日志文件,不支持修改或删除已写入的记录。通过读取和应用editlog中的操作记录,可以将文件系统从初始状态(fsimage)逐步恢复到当前状态。
具体的工作流程如下:
- 当HDFS启动时,NameNode首先加载fsimage文件到内存,将文件系统恢复到最近一次保存的状态。
- NameNode开始读取editlog文件,并将其中的操作逐个应用到内存中的文件系统状态,以更新文件系统的元数据信息。
- 在正常运行期间,每当有文件系统的修改操作发生,对应的操作会被追加到editlog文件,确保数据的持久化和可恢复性。
- 定期或手动触发的检查点操作会将当前的内存中的文件系统状态保存为新的fsimage文件,并清空旧的editlog文件,从而限制editlog的大小并加速恢复过程。
通过fsimage和editlog的结合使用,HDFS能够实现高效的元数据管理和快速的系统恢复能力,保证了文件系统的可靠性和可用性。
类似于mysql的binlog和中继日志的结合体
补充一下:
JournalNode和editlog:
- JournalNode负责存储NameNode的编辑日志(editlog)。
- 当NameNode接收到文件系统的修改操作时,会将这些操作写入本地的editlog文件,并通过JournalNode进行复制。这样,即使某个JournalNode节点发生故障,其他正常运行的JournalNode节点仍然可以提供服务。而且,如果某个JournalNode节点丢失了数据(例如节点损坏),其他节点上的数据副本可以被用来进行数据恢复,JournalNode可以运行在每一个 dn节点
1.5、zookeeper
ZooKeeper 是一个开源的分布式协调服务,可以用于构建可靠的分布式系统。它提供了一个简单且高效的分布式协调基础,用于协调和管理分布式应用程序的配置、命名服务、分布式锁、分布式队列等。
ZooKeeper 的主要作用如下:
-
配置管理:ZooKeeper 可以存储和管理分布式系统的配置信息,应用程序可以通过监听 ZooKeeper 上的配置节点来感知配置的变化并做出相应的调整。
-
命名服务:ZooKeeper 提供了一个层次化的命名空间,应用程序可以在其中创建和维护有序的节点结构,用于表示命名服务,例如存储集群中各个节点的地址或其他重要信息。
-
分布式锁:ZooKeeper 提供了分布式锁的实现,多个进程可以使用 ZooKeeper 来协调访问共享资源的顺序,从而实现分布式锁。
-
分布式队列:ZooKeeper 的顺序节点特性可以用于实现分布式队列,多个进程可以将数据写入 ZooKeeper 上的顺序节点,然后按照节点的顺序读取数据,实现简单的消息队列。
-
集群管理:ZooKeeper 可以用于监控和管理分布式系统中各个节点的状态,检测节点的故障并进行故障恢复,从而提高系统的可用性和稳定性。
总之,ZooKeeper 提供了一种可靠的分布式协调机制,帮助开发人员构建可靠、高效、分布式的应用程序,并解决分布式系统中的一致性、协调和管理问题。
zookeeper集群中服务器角色划分
| 角色 | 描述 | |
|---|---|---|
| 领导者(leader) | 领导者负责投票的发起和决议,更新系统状态 | |
| 学习者(learner) | 跟随者(follower) | Follower 用于接收客户端请求并向客户端返回结果,在选主过程中参与投票 |
| 观察者(observer) | Observer可以接收客户端连接,它不参与 Leader 选举过程,相反,Observer 只同步 Leader 的状态,以便能够更快地响应客户端的读请求。Observer 节点通常用于扩展集群的读能力,而不会增加集群的写负载。 | |
| 客户端(client) | 请求发起方 | |
1.6、个人总结部分
HA的必要性,是做什么的
HA实现
每一个node上部署zkfc监控NN状态
zookeeper参与选举至少三个节点,必须是单数
HA数据交换方法
通过journalnode进行交换,“快照”保存在 fsimage,操作保存在editlog,恢复时先恢复快照,再加载操作
2、部署规划
2.1、网络环境
| ip | 角色 | 所需软件 |
| 192.168.189.137 | NameNode ZKFC hd1 | jdk hadoop2 |
| 192.168.189.138 | NameNode ZKFC hd2 | jdk hadoop2 |
| 192.168.189.139 | ResourceManager hd3 | jdk hadoop2 |
| 192.168.189.140 | DataNode NodeManager JournalNode(数据交换用) QuorrumPeerMain(选举,zookeeper) hd4 | jdk hadoop2 zookeeper3.4 |
| 192.168.189.141 | DataNode NodeManager JournalNode(数据交换用) QuorrumPeerMain(选举,zookeeper) hd5 | jdk hadoop2 zookeeper3.4 |
| 192.168.189.142 | DataNode NodeManager JournalNode(数据交换用) QuorrumPeerMain(选举zookeeper) hd6 | jdk hadoop2 zookeeper3.4 |
基础网络环境需要配置:静态ip,主机名,域名解析,ssh免密登录(配置方式)
2.2、jdk部署
[root@hd1 ~]# tar xf jdk-8u202-linux-x64.tar.gz
[root@hd1 ~]# mv jdk1.8.0_202 /usr/local/jdk
[root@hd1 ~]# vim /etc/profile2.3、zookeeper部署
hd{4..6}上安装zookeeper
zookeeper下载地址
[root@hd4 ~]# tar xf apache-zookeeper-3.7.2-bin.tar.gz
[root@hd4 ~]# ls
anaconda-ks.cfg
apache-zookeeper-3.7.2-bin
apache-zookeeper-3.7.2-bin.tar.gz
hadoop-2.10.2.tar.gz
jdk-8u202-linux-x64.tar.gz
mysql80-community-release-el9-5.noarch.rpm
[root@hd4 ~]# mv apache-zookeeper-3.7.2-bin /usr/local/zookeeper
[root@hd4 ~]# cd /usr/local/zookeeper/
[root@hd4 zookeeper]# ls
bin docs LICENSE.txt README.md
conf lib NOTICE.txt README_packaging.md
[root@hd4 zookeeper]# cd conf/
[root@hd4 conf]# ls
configuration.xsl log4j.properties zoo_sample.cfg
[root@hd4 conf]# cp zoo_sample.cfg zoo.cfg
[root@hd4 conf]# vim zoo.cfg
[root@hd4 conf]# vim zoo.cfg
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/opt/data
dataLogDir=/opt/data/log
# the port at which the clients will connect
clientPort=2181
server.1=hd4:2888:3888
server.2=hd5:2888:3888
server.3=hd6:2888:3888
保存退出,向本机写入zookeeper的id编号
[root@hd4 conf]# mkdir /opt/data
[root@hd4 conf]# echo "1" > /opt/data/myid
#hd4写1,hd5写2,以此类推这里直接使用scp将已配置的zookeeper拷贝到hd5与hd6里面
[root@hd4 ~]# scp -r /usr/local/zookeeper hd6:/usr/local修改/etc/profile文件,添加zookeeper
export JAVA_HOME=/usr/local/jdk
export HADOOP_HOME=/opt/hadoop
export ZOOKEEPER_HOME=/usr/local/zookeeper
export PATH=${JAVA_HOME}/bin:${HADOOP_HOME}/bin:${ZOOKEEPER_HOME}/bin:$PATH
这里直接使用scp将已配置的环境变量拷贝到hd5与hd6里面
[root@hd4 bin]# scp /etc/profile hd5:/etc/profile
profile 100% 2083 2.0MB/s 00:00
[root@hd4 bin]# scp /etc/profile hd6:/etc/profile
profile 100% 2083 1.2MB/s 00:00 source应用一下三个环境变量,启动三台服务器的zookeeper
[root@hd4 ~]# zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED查看zookeeper状态
hd4:
[root@hd4 data]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower
hd5:
[root@hd5 ~]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: leader
hd6:
[root@hd6 ~]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower2.4、Hadoop部署
参考上一篇文章,需要注意的是,同步变量文件时需要保证前面配置的zookeeper变量不要受到影响,同时添加hadoop的/sbin目录
hd{4..6}
export JAVA_HOME=/usr/local/jdk
export HADOOP_HOME=/opt/hadoop
export ZOOKEEPER_HOME=/usr/local/zookeeper
export PATH=${JAVA_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:${ZOOKEEPER_HOME}/bin:$PATH
hd{1..3}
export JAVA_HOME=/usr/local/jdk
export HADOOP_HOME=/opt/hadoop
export PATH=${JAVA_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:$PATH
3、完全分布式配置文件修改
3.1、hadoop-env.sh
[root@hd1 ~]# cd /opt/hadoop/etc/hadoop/
[root@hd1 hadoop]# vim hadoop-env.sh
export JAVA_HOME=/usr/local/jdk
#此处建议修改为路径模式,原为变量模式启动可能报错3.2、core-site.xml
<configuration>
<!-- 指定hdfs的nameservice为ns1 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns1</value>
</property>
<!-- 指定hadoop临时目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/data/tmp</value>
</property>
<!-- 作为zookeeper客户端,指定zookeeper地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>ha4:2181,hd5:2181,hd6:2181</value>
</property>
</configuration>
3.3、hdfs-site.xml
<configuration>
<!-- 指定hdfs的nameservice为ns1,需要和core-site.xml中保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>ns1</value>
</property>
<!-- ns1里面有两个namenode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.ns1</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn1</name>
<value>hd1:9000</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns1.nn1</name>
<value>hd1:50070</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn2</name>
<value>hd2:9000</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns1.nn2</name>
<value>hd2:50070</value>
</property>
<!-- 指定namenode的元数据在journalnode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hd4:8485;hd5:8485;hd6:8485/ns1</value>
</property>
<!-- 指定journalnode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/data/journal</value>
</property>
<!-- 开启namenode失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.ns1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用隔离机制时需要ssh免登录 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
</configuration>
3.4、slaves
配置datanode节点的记录文件
[root@hd1 hadoop]# vim slaves
清空原文件内容,写入三个节点名
hd4
hd5
hd63.5、mapred-site.xml
<configuration>
<!-- 指定mr框架为yarn方式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
3.6、yarn-site.xml
<configuration>
<!-- 指定resourcemanager地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hd3</value>
</property>
<!-- 指定nodemanager启动时加载server的方式为shuffle server -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- Site specific YARN configuration properties -->
</configuration>
3.7、mapred-env.sh
export JAVA_HOME=/usr/local/jdk3.8、yarn-env.sh
export JAVA_HOME=/usr/local/jdk3.9、统一配置
使用for循环将配置好的文件分发到所有节点
for i in hd{2..6}
do
scp -r /opt/hadoop $i:/opt
done4、启动集群
4.1、在datanode节点(3台)启动zookeeper
[root@hd5 ~]# zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
#所有zookeeper启动后检查启动状态
[root@hd5 ~]# zkServer.sh status
#使用jps可以看到选举进程
[root@hd4 ~]# jps
1804 QuorumPeerMain
4.2、启动journalnode
在namenode上操作,例如hd1
[root@hd1 ~]# hadoop-daemons.sh start journalnode
hd4: starting journalnode, logging to /opt/hadoop/logs/hadoop-root-journalnode-hd4.out
hd5: starting journalnode, logging to /opt/hadoop/logs/hadoop-root-journalnode-hd5.out
hd6: starting journalnode, logging to /opt/hadoop/logs/hadoop-root-journalnode-hd6.out
在hd4上查看可以看到如下图所示

使用jps可以看到守护进程启动
[root@hd4 ~]# jps
1804 QuorumPeerMain
1965 JournalNode
2047 Jps4.3、格式化hdfs文件系统
在namenode上操作,例如hd1
[root@hd1 ~]# hdfs namenode -format然后将临时文件夹拷贝到nn2
[root@hd1 hadoop]# scp -r /opt/data hd2:/opt
4.4、格式化zk
在namenode上操作,例如hd1
注意最后的ZK为大写,写错后不产生报错,但是会影响后续运行
[root@hd1 hadoop]# hdfs zkfc -formatZK4.5、启动hdfs
在namenode上操作,例如hd1
[root@hd1 hadoop]# start-dfs.sh hd1,hd2如下所示
[root@hd2 ~]# jps
2100 Jps
1724 NameNode
2029 DFSZKFailoverController
hd3
[root@hd3 ~]# jps
1673 Jps
hd4,5,6
[root@hd6 ~]# jps
2118 Jps
1611 QuorumPeerMain
1916 DataNode
1726 JournalNode
4.6、启动yarn
在nodename上操作,例如想让hd3成为resourcemanager,则在hd3上启动
[root@hd3 ~]# start-yarn.sh
下面按照需求输入yes执行操作hd3
[root@hd3 ~]# jps
2112 Jps
1719 ResourceManagerhd4,5,6
[root@hd4 ~]# jps
1911 DataNode
1609 QuorumPeerMain
2393 Jps
2171 NodeManager
1725 JournalNode5、集群验证及使用
5.1、操作步骤
[root@hd1 ~]# vim test.txt
[root@hd1 ~]# cat test.txt
tom
jerry
tom
tom
tom
jerry
spike
spike
#。。。。。。部分略。。。。。。。。。
[root@hd1 ~]# hdfs dfs -ls /
[root@hd1 ~]# hdfs dfs -mkdir /input
[root@hd1 ~]# hdfs dfs -ls /
Found 1 items
drwxr-xr-x - root supergroup 0 2024-05-23 20:06 /input
[root@hd1 ~]# hdfs dfs -put test.txt /input
[root@hd1 ~]# hdfs dfs -ls /input
Found 1 items
-rw-r--r-- 3 root supergroup 167 2024-05-23 20:07 /input/test.txt
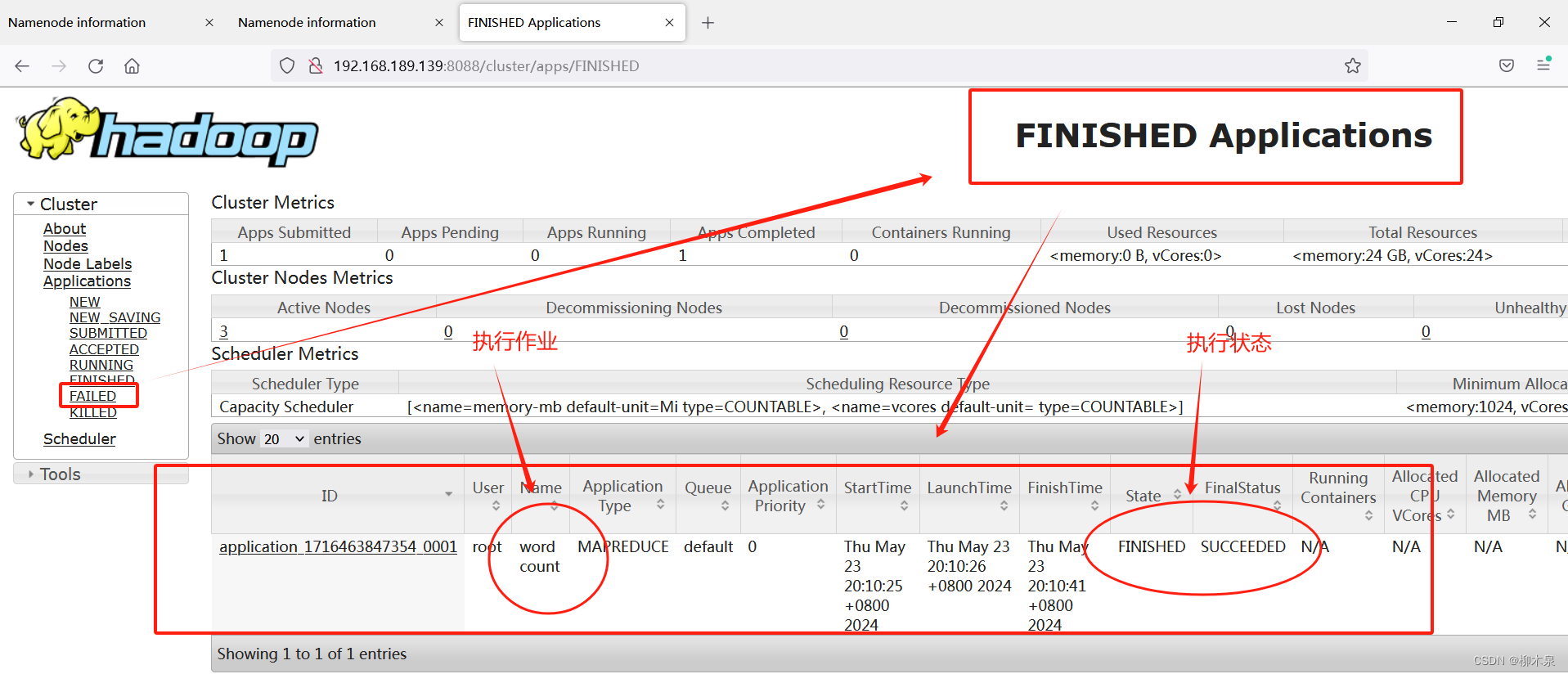
[root@hd1 ~]# yarn jar /opt/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.10.2.jar wordcount /input /output/00
#输出信息略
[root@hd1 ~]# hdfs dfs -ls /output/00
Found 2 items
-rw-r--r-- 3 root supergroup 0 2024-05-23 20:10 /output/00/_SUCCESS
-rw-r--r-- 3 root supergroup 139 2024-05-23 20:10 /output/00/part-r-00000
[root@hd1 ~]# hdfs dfs -cat /output/00/part-r-00000
10.0.0.0 1
126.0.0.0 1
127.0.0.1 1
128.0.0.0 1
191.255.0.0 1
192.0.0.0 1
192.168.1.1 2
192.168.2.1 1
233.255.255.0 1
jerry 2
spike 2
tom 85.2、浏览器访问
hd1
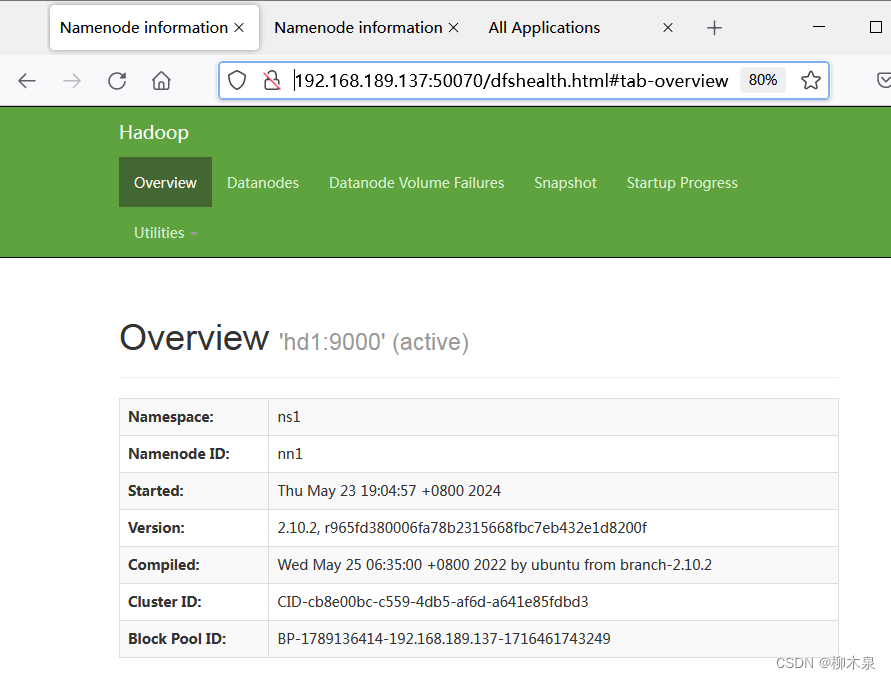
hd2

hd3
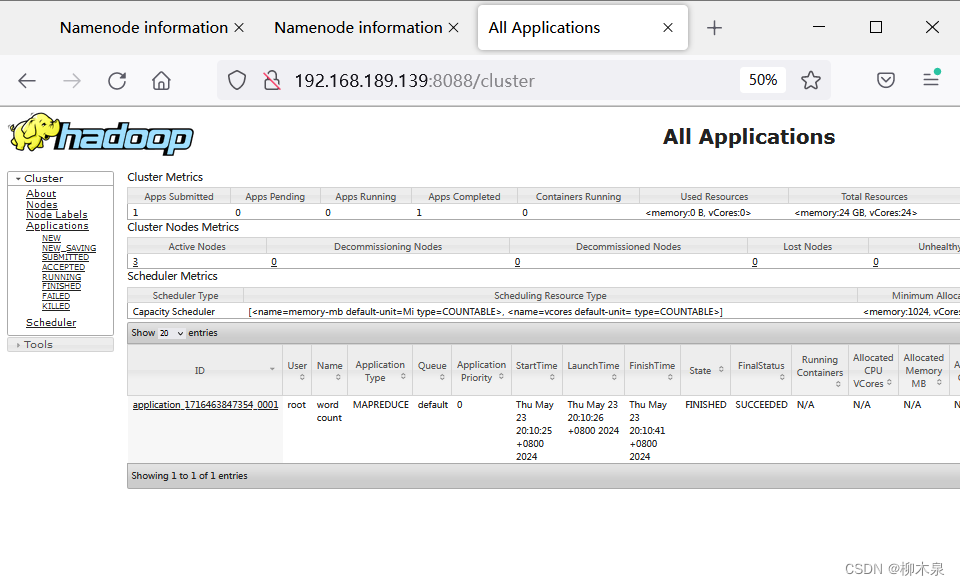
历史作业记录